






费曼说:学习一件事情最好的方式是做它的老师,这也是写这篇博文的目的,写这篇博文,即便有其他原因,但更多的还是写给自己,话不多说,让我们开始进入NLP吧
经过上次任务的作业后,我们对于python和本次任务的数据有了一定的了解,现在,我们用最传统的机器学习的方式来对数据进行分类
任务说明:任务task03
基座课程:基座课程
1.学习目标
学习目标已经确定为两个方面:
1. 学会TF-IDF的原理和使用:TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征表示方法,用于衡量一个词在文本中的重要程度。学习TF-IDF的原理将帮助理解它如何计算和表示文本特征,以及如何使用它来提取关键词和特征向量。
2. 使用scikit-learn的机器学习模型完成文本分类:scikit-learn是一个流行的Python机器学习库,提供了丰富的机器学习算法和工具。通过学习如何使用scikit-learn中的机器学习模型能够构建文本分类器,并使用TF-IDF表示的特征对文本进行分类。
掌握TF-IDF的基本原理和使用方法,以及使用常见的机器学习算法构建文本分类器的技能。这将提供一种基于传统机器学习的文本分类方法,并为解决赛题提供一个基础解决方案。
2.方法理解
1.Tf-IDF(Term Frequency-Inverse Document Frequency):TF-IDF的主要思想就是根据关键词及在不同文本中的词频作为特征来进行的分类的工作,实际上是统计学在文本分析中的应用,它由两部分组成。第一部分是TF(词语频率,Term Frequency),用于衡量一个词在文本中的出现频率。TF表示某个词在文本中出现的次数除以文本的总词数,它反映了一个词在文本中的重要程度。
第二部分是IDF(逆文档频率,Inverse Document Frequency),用于衡量一个词在整个语料库中的重要程度。IDF计算的是语料库中文档总数除以含有该词语的文档数量加一(为了避免分母为零的情况),然后取对数。这样计算得到的值越大,表示该词在语料库中越不常见,具有较高的区分度。
逆文档频率:为什么要有IDF呢?如果只用TF会有什么问题呢?比如“的”在一个文档中出现128次,是整个文档中出现次数最多的词。但是这个词并没有什么意义。所以要求有意义的词在这篇文档中出现的次数多,但是在其它的文档中出现的少。我们理解的频率的概念是频数除以总数。“逆”就是倒过来的意思,为了防止分母为0,在分母上了个1,再做log处理。
红色为TF-IDF,蓝色为TF,可以看到,红色曲线增长更加平滑
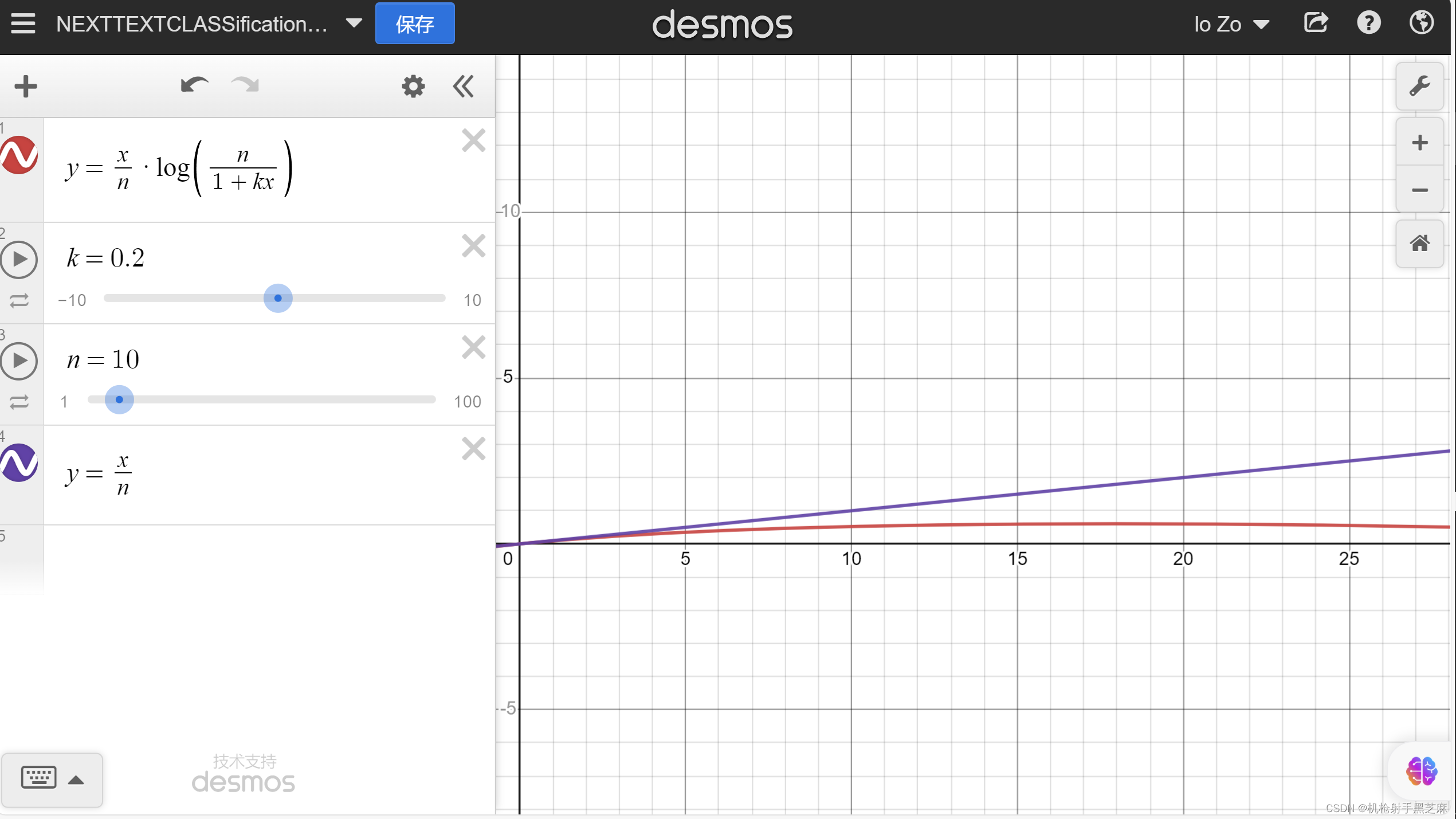
TF-IDF的思想是将一个词的重要性同时考虑它在当前文本中的频率以及在整个语料库中的普遍程度。如果一个词在当前文本中频率较高,同时在整个语料库中较少出现,那么它很可能是具有特定含义或特定分类的关键词。
通过计算TF-IDF,我们可以得到每个词在文本中的重要性权重,从而形成特征向量。这些特征向量可以用于构建机器学习模型,如分类器,以进行文本分类任务。
2.Count Vectors:统计语句中每个字符出现的次数
3.词嵌入(Word Embedding)方法:词嵌入将不定长的文本转换到定长的空间内,是文本分类的第一步。
4.One-hot:
里的One-hot与数据挖掘任务中的操作是一致的,即将每一个单词使用一个离散的向量表示。具体将每个字/词编码一个索引,然后根据索引进行赋值。
One-hot表示方法的例子如下:
句子1:我 爱 北 京 天 安 门
句子2:我 喜 欢 上 海
首先对所有句子的字进行索引,即将每个字确定一个编号:
{
‘我’: 1, ‘爱’: 2, ‘北’: 3, ‘京’: 4, ‘天’: 5,
‘安’: 6, ‘门’: 7, ‘喜’: 8, ‘欢’: 9, ‘上’: 10, ‘海’: 11
}
在这里共包括11个字,因此每个字可以转换为一个11维度稀疏向量:
我:[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
爱:[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
…
海:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
Bag of Words
Bag of Words(词袋表示),也称为Count Vectors,每个文档的字/词可以使用其出现次数来进行表示。
句子1:我 爱 北 京 天 安 门
句子2:我 喜 欢 上 海
直接统计每个字出现的次数,并进行赋值:
句子1:我 爱 北 京 天 安 门
转换为 [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
句子2:我 喜 欢 上 海
转换为 [1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
在sklearn中可以直接CountVectorizer来实现这一步骤:
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
vectorizer.fit_transform(corpus).toarray()3.方法实践
1.Count Vectors + RidgeClassifier
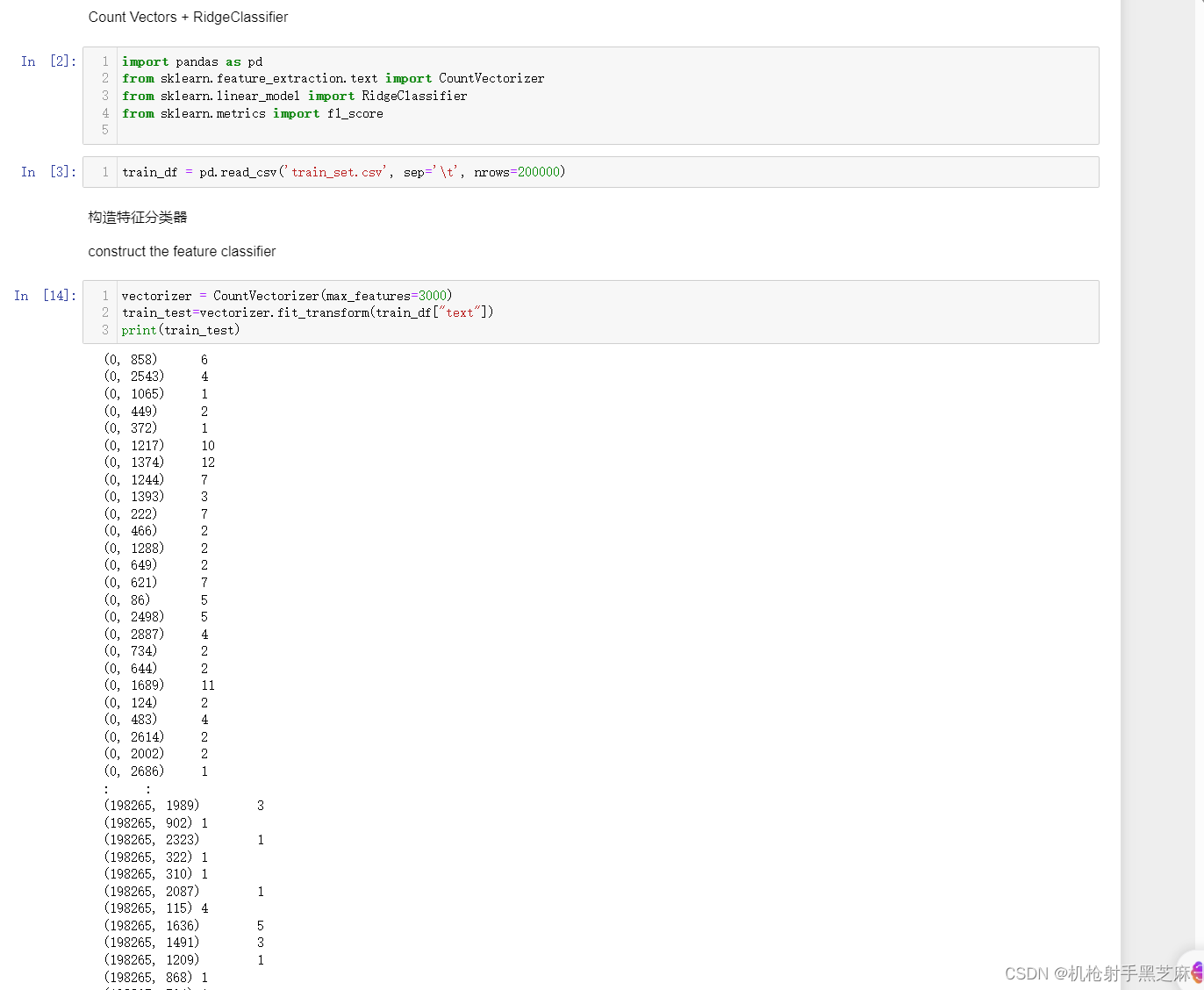
 代码解释:
代码解释:
val_true:表示真实的验证集标签。
val_pred:表示分类器在验证集上的预测结果。
labels:用于指定计算 F1 分数的类别标签,默认为 None,表示计算所有类别的 F1 分数。
pos_label:用于指定正类别的标签,默认为 1。
average:用于指定计算 F1 分数的方式,默认为 'binary',表示计算二分类问题的 F1 分数。其他可选值包括 'micro'、'macro'、'weighted' 和 None。
sample_weight:用于指定样本权重的数组,默认为 None,表示所有样本的权重都相等。F1 是 精确率和召回率的调和平均数 F1= 2 x(precision x recall)/precision+recall f1_score(val_true, val_pred, labels=None, pos_label=1, average=‘binary’, sample_weight=None) 函数详情:f1_score(val_true, val_pred, labels=None, pos_label=1, average='binary', sample_weight=None)是一个用于计算 F1 分数的函数调用,其中包含了不同的参数选项。
最终结果: 2.第二种方法
2.第二种方法
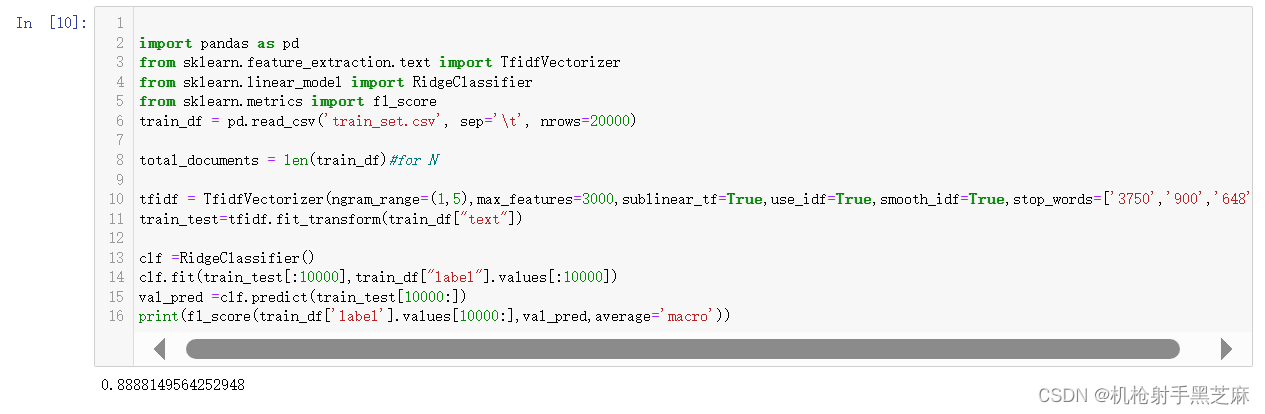
second:TF-IDF+RidgeClassifier

 最终结果:
最终结果: 4.作业
4.作业
作业1:尝试改变TF-IDF的参数,并验证精度
常用参数:
input:指定输入的数据类型,可选值为 'content'(文本数据)或 'filename'(文件路径)。
encoding:指定文本数据的编码方式,默认为 'utf-8'。
decode_error:指定编码错误处理方式,默认为 'strict'。
strip_accents:指定是否移除文本中的重音符号,默认为 None。可选值为 'ascii'、'unicode' 或 False。
lowercase:指定是否将文本转换为小写,默认为 True。
preprocessor:指定预处理函数,用于在 tokenization 和向量化之前对原始文本进行预处理。
tokenizer:指定分词函数,用于将文本划分为单词或其他单元。
analyzer:指定要使用的分析器,可选值为 'word'(基于单词的分析器)或 'char'(基于字符的分析器)。
stop_words:指定要删除的停用词列表,可选值为 'english'(使用内置的英文停用词列表)或自定义停用词列表。
token_pattern:指定用于提取单词的正则表达式模式,默认为 r"(?u)\b\w\w+\b"(匹配至少包含两个或更多字母/数字字符的单词)。
ngram_range:指定要考虑的 n-gram 的范围,默认为 (1, 1)(只考虑单个词)。
max_df:指定词语在文档中的最大出现频率,超过该频率将被忽略,默认为 1.0(表示不忽略任何词语)。
min_df:指定词语在文档中的最小出现频率,低于该频率将被忽略,默认为 1(表示不忽略任何词语)。
max_features:指定要保留的最大特征数量,默认为 None(表示保留所有特征)。
vocabulary:指定自定义的词汇表,用于将特定词语映射到特征索引。
binary:指定是否将词语的 TF-IDF 值转换为二进制表示,默认为 False。
dtype:指定特征矩阵的数据类型,默认为 numpy.float64。
norm:指定特征向量的归一化方式,默认为 'l2'(按照欧几里德范数进行归一化)。
use_idf:指定是否使用 IDF(Inverse Document Frequency)来加权词语的 TF-IDF 值,默认为 True。
smooth_idf:指定是否对 IDF 进行平滑操作,默认为 True。
sublinear_tf:指定是否对 TF 进行子线性缩放操作,默认为 False。
常用方法: -fit_transform(raw_documents[, y]): 用于拟合并转换原始文本数据,返回 TF-IDF 特征矩阵。raw_documents 是一个可迭代的文本数据集,y 是可选的目标变量。该方法将对文本数据进行分词、计算词频和逆文档频率(IDF),并返回 TF-IDF 特征矩阵。
1.we use Grid search strategies网格化搜索的策略(ngram_range()),来对参数进行搜集

由于训练时间较短,下面是几次不同参数的尝试:
2.利用线性缩放(sublinear_tf) we take the advantage of linear scaling

3.标准化解决长文档、短文档问题差距悬殊 through the medhod normalize the documents to solve the length of documents are in great disparity

4.对数函数处理IDF(默认)
use the logarithmic function processing the IDF
Logarithmic function processing IDF
公式:IDF = log(N/N(w)+1)


5.试一下不取对数的方法 try in no logarith,效果基本没有变化

6.设置忽略词
stopping_words which means terms that were ignored becanuse they either:occurred in too much or too few or be ignored.
There we chose 3750,648 and 900 because it's punctuation。
准确度达到了最高值0.888
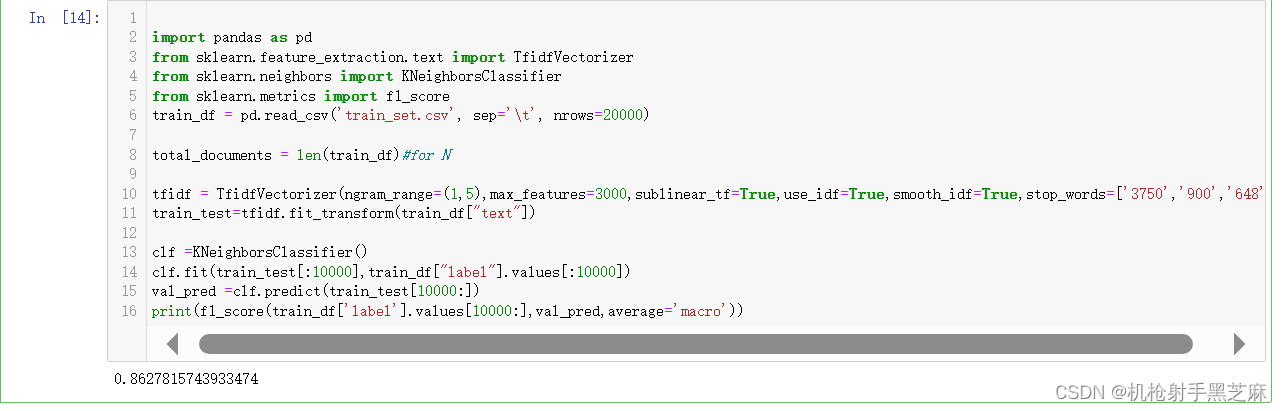
 作业2:试使用其他机器学习模型,完成训练和验证
作业2:试使用其他机器学习模型,完成训练和验证
准确度逐级上升
we use the KNN and other classifier:
RadiusNeighborsClassifier:

SGD:
 还有xgb:
还有xgb:
 测试结果约为:0.9344
测试结果约为:0.9344
MLP:下面也是主要参考的一些代码,非常具有借鉴价值
1.导包:

2.导入数据:

3.导入数据和模型:


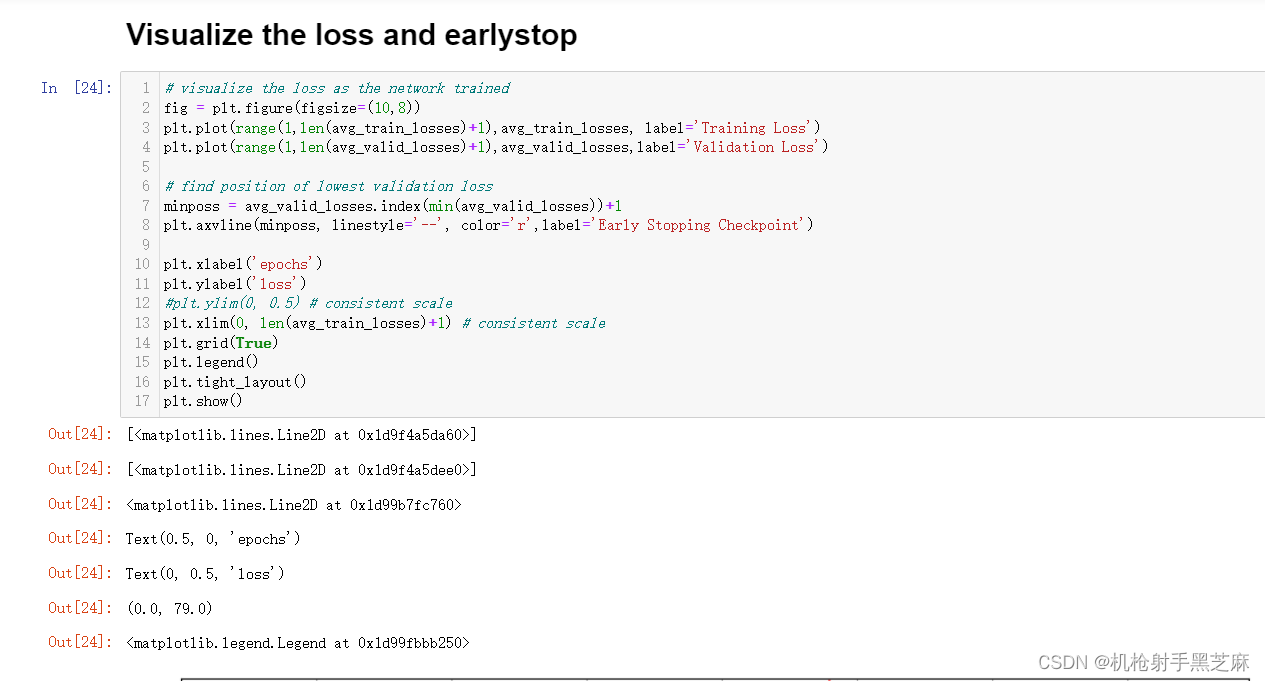
早停机制:此前在图像识别中曾经实践过,代码逻辑比较简单,可以通过导包或者自己手写来解决

 5.总结
5.总结
本次学习对于TF-IDF的词频统计及一些分类方法有所学习,如KNN、RadiusNeighborsClassifier、SGD、XGB、 MLP等分类器模型,学到了很多,还是很有收获的。















 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









