







这也是一篇对于voterank的改编,属于改进算法,功能是识别复杂网络中的一系列最有影响的点。本篇论文主要在应用在无向,无权值的图。同时对于有向的或者有权值的图,我们可以使用WVoterank,或者Voterank Plus这在之前也实现过了,再次就不多提了。下面叙述一下我对本篇论文的思考以及疑问。
首先,必须先提一下经典voterank,主要认为有三个方面的不合理。
1.将所有节点的能力视为相同的,没有区分不同节点能力不同的问题。
2.投票过程中,节点的得分仅通过汇总邻居的投票能力来的,没有反映不同邻居的贡献不同。
3.削弱方面,只削弱了最近邻居的投票能力,抑制不足。
DIL算法主要改进上述的问题,下面也相对上面问题总结一下DIL。
1.利用度值重新定义各节点的初始投票能力。(和plus的定义类似)
2.引用DIL方法,主要改进算法在scores方面的计算,更好的反映节点的重要性。
3.优化弱化机制,弱化每轮的1阶邻居和2阶邻居的投票能力。
下面根据该算法的流程,介绍一些重要概念。
目录
4.Update node attribute values.
1.DIL Method

这个是先定义一条边的重要程度,imporance of vertex定义为Imn,这个数值就相当于这个边的一个性质了。在这个公式里面有一个系数p,比较的有意思,代表的是以mn为一个边所围成的三角形的个数。所以这对每一条边而言,都是各不相同的。特此,我去找了相关的资料,发现这个思想比较重要,这个算法主要更好识别的是桥节点的重要性,我也认为这在复杂网络中很重要。

基于次,将一个节点的重要性和这个节点的度和边的重要性相结合。下面我想着重说一下系数p,我在前几次阅读文献的时候,以为这就是一个普通的系数,后面才发现其重要性。

对于这两幅无向图,根据上面公式,我们分别计算Ie45的值。
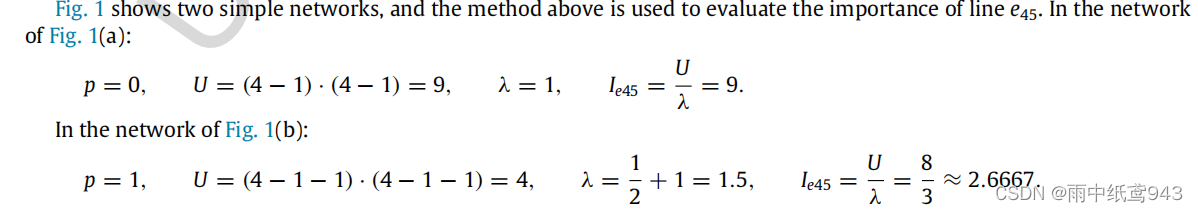
在这里,我也就直接引用结果了,可以看出,因为节点3和5之间有另一条边,导致他们的边重要性差异特别大,这也就是p的作用,p算的是以edge45为边的三角形的个数,图a中,p为0,图b中,存在一个以edge45为边的三角形,所以p为1,这会导致edge45的重要程度严重下降。原因也很明显,在a中V4到V5只有一条路,属于必通关键桥,而在图b中,有另外一条可以中转的路,直达的那条路也就显得不是非常重要了。 对于p的计算,实际上也很简单,就是算该边的两个节点的共同邻居节点的数量。

所以,我们就可以度量出来一条边的重要程度。但是假如我们根据一个节点连接的所有边的重要程度的和来度量一个节点的重要性,这是合理的吗。下面也有一个例子,可以说明,我们不能只根据边的重要性来度量一个节点的重要程度。
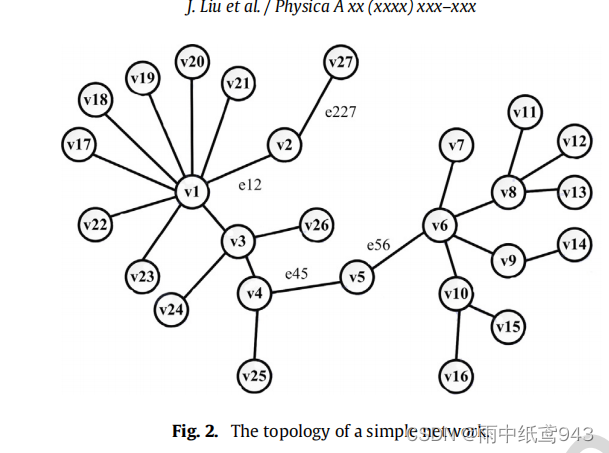
对于这个图,我们计算节点V2和V5的临边的重要性。

根据公式3计算,我们通过累加,得出节点v2和v5的累计和。发现v2的重要程度大于v5??这显然是不符合逻辑的,因为感觉v2那里都属于边界了,v5那里相当于中心繁华地带,怎么可能重要程度反而更低嘛。因此,我们不能简单的累加边的权来作为节点的重要评价标准。因而我们下面又引出了一个新的概念。

至此,我们就将DIL计算节点重要程度就完美解决了,而且对比于其他算法,有着更优和更合理的表现。同时我们得到了Lv数据结构,里面表示的local importance of vertex也就是节点的一个重要性度量。后续我们还会再用到


在后面,还会根据目前的Lv进行一个数据处理。得到的是最终的Lv结果。
2.Initialize voting ability.
在传统voterank中,都暴力的设置为1,显然不合理,在本篇文章中,根据当前度和最大度的比值来作为本节点的能力体现。

3.Voting phase.
我们做了这么多的准备工作,下面就要进行节点的分数计算了。属于核心的计算了。

对于每一轮的计算,一个节点的分数为,累加所有邻居节点的投票能力和重要性的乘积,最后在除以所有当前节点的重要性平方和的开根。感觉叙述起来很麻烦,但是按照公式写,还是很好写出来的。对于下面的平方和开根,实际上,从数学角度分析,这个结果就是一系列的ability相加,因为后面的量级为0,只提供一个系数作用。这个算法运行完,就可以得到相应节点的得分了,也可以挑选得分最大节点了。
4.Update node attribute values.

正如上面所讲,对一阶邻居和二阶邻居分别进行抑制。抑制元素k为平均度数,根据邻近阶数不同,抑制的程度也不同,这样相比经典voterank,可以更利于分散挑选下一个重要节点。
5.伪代码的实现和理解

这是相关伪代码部分,和我上面讲解的相差不多。 但是实现起来,我发现有几个小问题,在17,20行,伪代码解释的是更新scores里面的分数,但是一个循环过后第12行的操作不会覆盖结果吗?那17,20的作用在哪里。

然后下图是对于第一次计算scores后的详细数据。(论文数据)

下面这个是我代码跑出来的结果,和论文方面还是有点差距的,比如对于node2的Lv计算,但是大部分的差距在0.1左右,不知道是不是在哪个细节没处理好。


还有一个问题就是,在上面的图当中,依据我的代码运行,我选取了前5个最高分数的节点。

但是依据论文里面,第二个被选择的节点应该为17号,而不是1号。
可能是我编写的代码有问题。 先在这记录一下,等我找出来了原因,再来更新本文吧。















 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









