






1.环境配置,将下载好压缩包(资源里有)的进行解压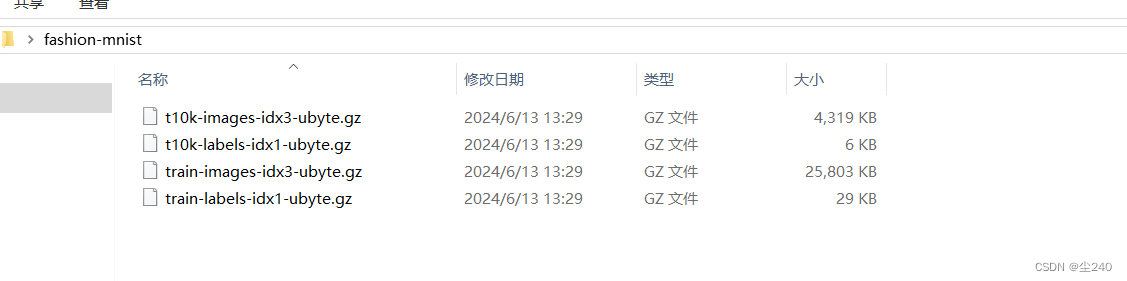 2.复制文件夹至C:\Users\当前用户\.keras\datasets目录下
2.复制文件夹至C:\Users\当前用户\.keras\datasets目录下
 3.找到并修改fashion_mnist.py中的文件路径
3.找到并修改fashion_mnist.py中的文件路径
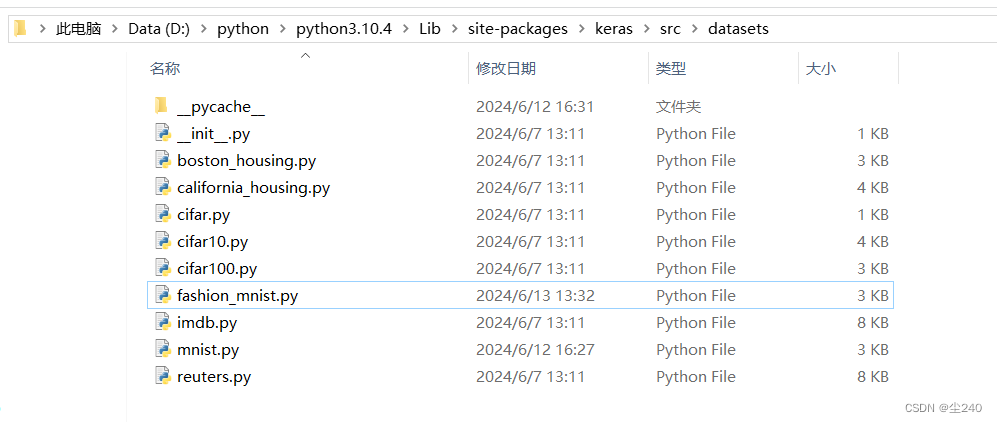
找到base,更改路径到之前保存的fashion_mnist文件夹路径,保存修改
4.编写代码运行
import os
# TF_CPP_MIN_LOG_LEVEL='2' 表示只显示错误信息和警告
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 导入TensorFlow的Fashion MNIST数据集
fashion_mnist = tf.keras.datasets.fashion_mnist
# 加载Fashion MNIST数据集,并将其分为训练集和测试集
# 这里取前10000张图片和对应的标签用于训练
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# 调整训练数据的形状,使其从28x28像素的二维数组变为784个元素的一维数组
train_images = train_images[:10000].reshape(-1, 784)
# 将训练标签转换为one-hot编码,即10个类别的one-hot向量
train_labels = tf.one_hot(train_labels[:10000], 10).numpy()
# 构建一个顺序模型,这是一个简单的多层感知机
model = tf.keras.Sequential([
# 第一层是Flatten层,将输入展平为一维数组
tf.keras.layers.Flatten(),
# 接下来是四个Dense层,即全连接层,每个层有不同数量的神经元
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(32, activation="relu"),
# 最后一个Dense层是输出层,有10个神经元对应10个类别,使用softmax激活函数
tf.keras.layers.Dense(10, activation="softmax")
])
# 为模型指定输入数据的形状,None表示批次大小可以是任意值,28x28表示每个输入图像的尺寸
model.build(input_shape=[None, 28, 28])
# 编译模型,设置优化器、损失函数和评估指标
# 使用Adam优化器,这是一个常用的优化算法
model.compile(optimizer=tf.keras.optimizers.Adam(),
# 使用CategoricalCrossentropy作为损失函数,适用于多分类问题
loss=tf.keras.losses.CategoricalCrossentropy(),
# 使用CategoricalAccuracy作为评估指标
metrics=[tf.keras.metrics.CategoricalAccuracy()])
# 训练模型,传入训练数据和标签,设置训练的轮数(epoch)
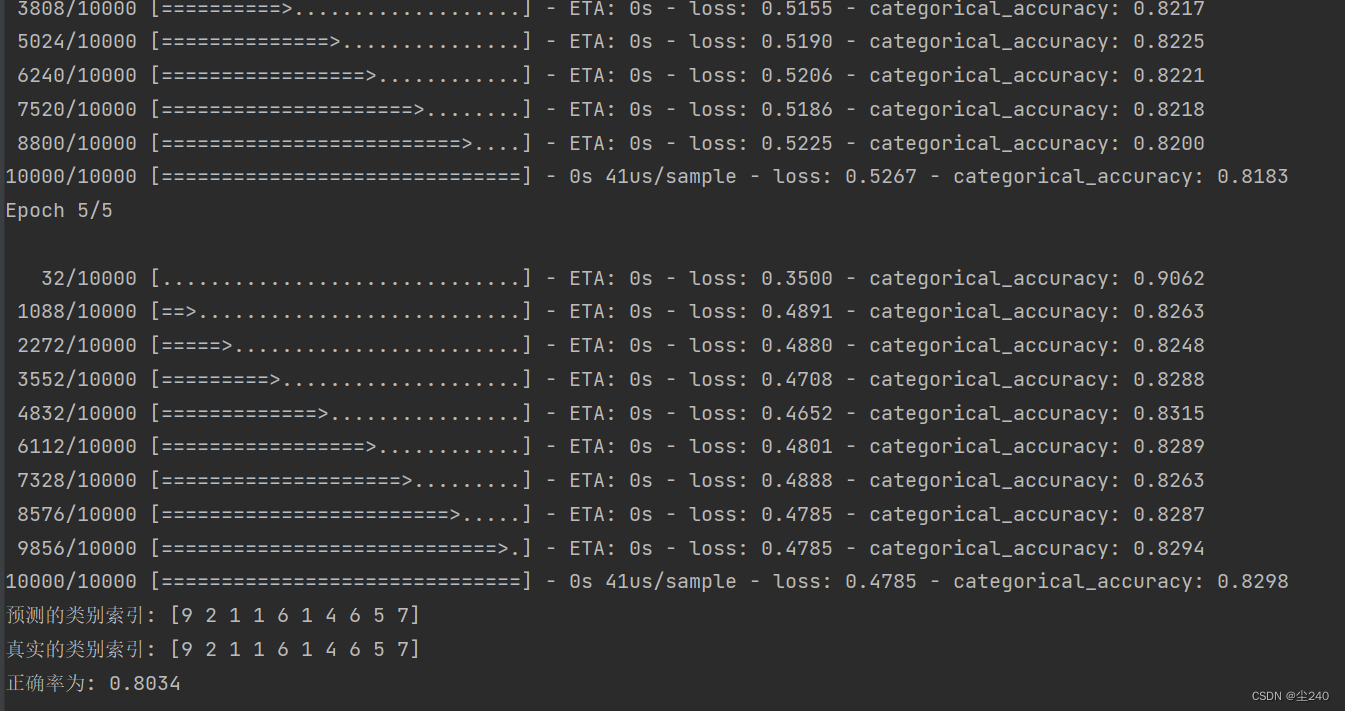
history = model.fit(train_images, train_labels, epochs=5)
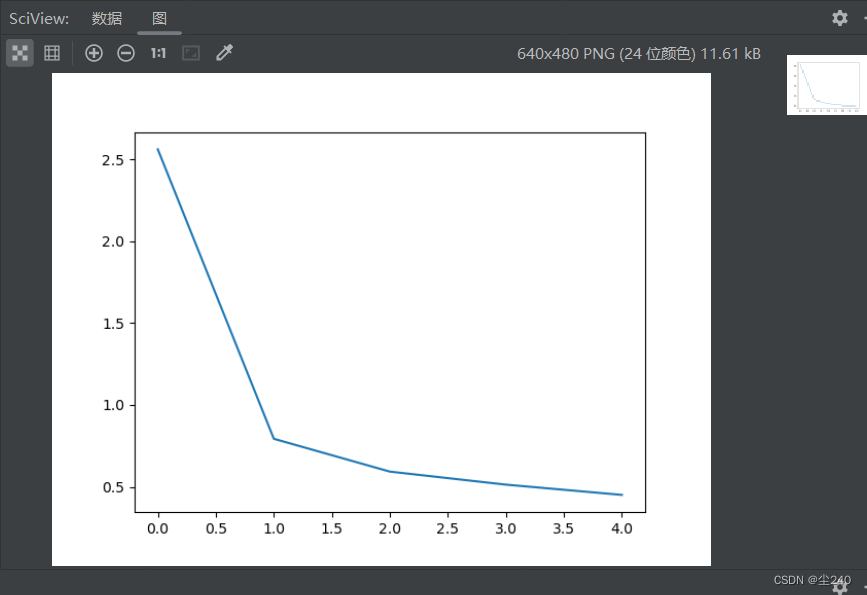
# 从训练历史中获取损失值,并使用Matplotlib绘制损失值随训练轮数变化的图表
LOSS = history.history["loss"]
plt.plot(LOSS)
plt.show()
# 预测测试集的结果,首先将测试图像展平为一维数组
test_images_flattened = test_images.reshape(-1, 784)
# 使用模型进行预测
predictions = model.predict(test_images_flattened)
# 将预测结果转换为最可能的类别索引,即选择概率最高的类别
predicted_labels = np.argmax(predictions, axis=1)
# 获取测试集的真实标签
true_labels = test_labels
# 打印前10个预测结果的类别索引和真实标签,用于检查模型的预测效果
print("预测的类别索引:", predicted_labels[:10])
print("真实的类别索引:", true_labels[:10])
# 计算正确率,即预测正确的样本数占总样本数的比例
accuracy = np.mean(predicted_labels == true_labels)
# 打印正确率,保留四位小数
print(f"正确率为: {accuracy:.4f}")最后运行结果















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









