






MySQL数据库
1、MySQL和Oracle的区别
1.Oracle是大型数据库,而MySQL是中小型数据库。但是MySQL是开源的,但是Oracle是收费的,而且比较贵。
2. Oracle的内存占有量非常大,而mysql非常小
3. MySQL支持主键自增长,指定主键为auto increment,插入时会自动增长。Oracle主键一般使用序列。
4. MySQL字符串可以使用双引号包起来,而Oracle只可以单引号
5. Mysql分页用limit关键字,而Oracle使用rownum字段表明位置,而且只能使用小于,不能使用大于。
6. MySQL中0、1判断真假,Oracle中true false
7. MySQL中命令默认commit,但是Oracle需要手动提交
2、MySQL的约束条件有多少种?
1、主键:每张表里只能有一个主键,不能为空,而且唯一。
2、auto_insrement自增:自动编号,必须与主键组合使用,默认起始值为1,每次增量为1。
3、unique key:字段添加唯一约束之后,该字段的值不能重复。
4、null与not null:是否允许为空,默认null,可设置为not null。
5、字符集:在创建表的时候最后可以指定字符集,default charset=utf8 指定中文字符集。
6、外键:外键约束可以使两张表紧密的结合起来,保证数据的完整性。
3、MySQL5.7版本和MySQL8.0版本的区别?
1、在版本功能方面,MySQL8.0版本是一个全新的版本,在一些高级功能方面是优于MySQL5.7的,如高并发查询、数据库的复杂查询,在线备份恢复功能等。而且MySQL8.0还有一些新的功能。如窗口函数,隐藏索引等。
2、性能方面,MySQL8.0版本在读写工作负载,IO密集型工作负载方面比MySQL5.7更为出色。
3、安全性,MySQL8.0版本支持多种安全策略,强化了用户权限管理,比如MySQL5.7版本在创建用户的时候可以直接给予权限,而8.0版本必须先创建用户在给予权限。
4、数据库架构区别,8.0版本对数据库架构进行了大幅度的调整,包括表的结构、索引的调整等。
5、MySQL8.0使用utf8mb4作为MySQL的默认字符集
4、MySQL的日志类型?
常用的日志
1、binlog日志:实现备份,增量备份。只记录改变数据,除了select都记。
2、慢查询日志:慢查询日志,指导调优,定义某一个查询语句,执行时间过长,通过日志提供调优建议给开发人员。
3、错误日志:启动,停止,关闭失败报错。rpm安装日志位置 /var/log/mysqld.log
4、中继日志:读取主服务器的binlog,在slave机器本地回放。保持与主服务器数据一致。
5、通用查询日志:所有的查询都记下来。 默认关闭,一般不开启
5、MySQL的binlog日志类型有什么?
1、statement 记录的是执行的SQL语句
优点:日志记录量相对较小,节约磁盘空间
缺点:可能会导致主从不一致,对于特定函数如UUID这种非确定性函数是无法正确复制的。
2、row 记录的时每一行数据的修改,MySQL5.7+版本默认row格式
优点:可以避免MySQL主从复制出现主从不一致的问题,比statement更高效。
缺点:由于记录每一行数据的修改,所以日志量比较大。
3、mixd 混合statement和row两种格式,MySQL会根据执行的SQL语句自行选择,
6、MySQL数据库优化
安全方面:修改默认端口号,禁止root用户远程登录,对用户降权,以普通用户运行mysql
性能方面:升级硬件、内存、磁盘,优化sql语句(开启慢查询),设置索引
参数优化:innodb的buffer缓冲参数调大,连接数调大,缓存的参数优化
架构方面:读写分离,一主多从,高可用集群等
7、MySQL的SQL语句的优化
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num is null 可以在num上设置默认值0 select id from t where num=0
3. 任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
4.避免频繁创建和删除临时表,以减少系统表资源的消耗。
8、MySQL数据备份方式
MySQL有物理备份和逻辑备份
逻辑备份:备份的是建表、建库、插入等操作所执行SQL语句,适用于中小型数据库。速度慢,恢复也慢,需要一条一条执行sql语句
物理备份:
1、完全备份:备份数据库中所有数据,即对整个数据库,数据库结构和文件结构的备份,是增量备份与差异备份的基础。
优点:备份和恢复操作简单,恢复时一次到位。
缺点:占用空间大,备份速度慢。
2、增量备份:增量备份是指在一次全备或上一次增量备份后,以后每次的备份只需要备份与前一次相比增加和被修改的文件
优点:备份数据量小,占用空间少,备份速度快.
缺点:恢复时需要从上一次完整的备份起按照增量备份时间顺序,逐个进行恢复,恢复时间长,操作繁琐,而且,如果中间某次备份数据损坏,则数据会丢失
3、差异备份:差异备份是指在一次完全备份后到进行差异备份的这段时间内,对那些增加或者修改的文间进行备份,差异备份避免了全备份和增量备份的缺陷的同时,又具备了它们各自的优点
9、MySQLbinlog日志里存放了什么内容
事件的起点和事件的结束节点,事件发生的时间,服务器的标识id,事件执行花费的时间,错误码,执行过的MySQL语句
10、数据库的引擎都了解什么
innodb:支持事务,支持行锁定
myisam:有较高的查询速度,但是不支持事务
memory:需要很快的读写速度但是对安全性要求不高的话可以使用,但是对表的大小有要求。支持锁表不支持行锁定。
11、MySQL事务的四个特性
原子性:指事务是不可拆分的最小单元
一致性:事务中的sql语句,要么全部成功,要么全部失败。
隔离性:允许多个事务同时对数据库的数据进行读写和修改的能力,隔离性为了防止多个事务并发执行由于交叉执行导致的数据不一致。隔离级别分为读未提交、读提交、可重复读、串行化。隔离等级越高,数据越安全,但是消耗的资源就越多。
持久性:事务结束后,对数据的修改是永久写入到磁盘的,即使系统故障也不会丢失
12、脏读、不可重复读,幻读是什么
脏读:事务A读取了事务B更新的数据,然后事务B回滚操作,那么事务A读取到的数据就是脏数据
不可重复读:事务A多次读取同一数据,事务B在事务A多次读取过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。
幻读:系统管理员A在数据库中修改数据时,系统管理员B在这个时候插入了一条数据,当系统管理员A修改结束后突然发现了还有一条记录还没有修改过来,就像发生了幻觉一样,这就像幻读。
13、MySQL主从复制的原理
master主要负责主服务器数据库中有数据更新时,把执行的命令放入到binlog日志中,所以,主库的binlog日志一定要开启。
i/o线程在从slave从数据库中创建,用于请求master,master会返回binlog日志里的内容,然后将binlog保存在relay log(中继日志)中,然后sql线程就会同步中继日志中的内容到数据库然后执行其中的语句
基于binlog日志的主从复制怎么做
两台机器安装相同版本的MySQL
1.配置主节点的配置文件,必须要开启binlog日志,我们专门创建一个存放日志的目录,重启服务
2.登录主机的MySQL,查看binlog日志的文件名的position
3.修改从节点的配置文件,把server-id设置成和主机的不一致即可,重启服务,登录MySQL,执行sql命令,主机的的ip,主节点创建的用户,主节点的binlog的文件名,还有position
4.开启slave查看主从状态,sql和io都是yes即部署完成
14、MySQL主从方式有哪些
两种做法:
binlog日志方式:从节点需要手动指定binlog日志的名称、位置
gtid方式:从节点不需要手动指定binlog日志的名称、位置;会自动锁定
15、MySQL主从同步模式有几种
异步复制:MySQL 默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给客户端,并不关心从库是否已经接收并处理。这样就会有一个问题,一旦主库宕机,此时主库上已经提交的事务可能因为网络原因并没有传到从库上,如果此时执行故障转移,强行将从提升为主,可能导致新主上的数据不完整。
全同步复制:指当主库执行完一个事务,并且所有的从库都执行了该事务,主库才提交事务并返回结果给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
半同步复制:是介于全同步复制与全异步复制之间的一种,主库只需要等待至少一个从库接收到并写到 Relay Log 文件即可,主库不需要等待所有从库给主库返回 ACK。主库收到这个 ACK 以后,才能给客户端返回 “事务完成” 的确认。
16、MySQL主从数据不一致的原因
网络延迟,主从复制是基于binlog的异步复制,通过网络传送binlog文件,网络延迟是大多数引起数据不一致的原因
主从机器的负载不一致:mysql主从复制是主库开启dump线程,从库开启io和sql线程。当任何一台服务器负载过高,导致其中一个线程资源不足,会出现主从不一致的情况
版本不一致
max_allowed_packet设置不一致:主库设置的max_allowed_packet设置的比从库大,一条大的sql语句在主库能执行完毕,但在从库上无法执行,导致主从不一致。
解决方法:1、stop slave set global sql_slave_skip_counter=1 跳过这一步错误;2、重新做主从:先锁表,导入数据数据+同步,重新做主从
17、MySQL主从失效了怎么解决
1.查找问题
通过查找/etc/mysql/data/error.log日志,定位错误原因
show slave status\G; 查看i/o线程和sql线程状态
20
2.解决故障问题
# 先停止同步
mysql> stop slave;
3.跳过一个事务,
mysql> set global sql_slave_skip_counter=1;
Query OK, 0 rows affected (0.00 sec)
4.重新开启同步,再次查看同步状态
18、主从延迟怎么解决
原因
主库和从库在执行同一个事务的时候出现时间差的问题,主要原因包括但不限于以下几种情况:
有些部署条件下,从库所在机器的性能要比主库性能差。
从库的压力较大,即从库承受了大量的请求。
执行大事务。因为主库上必须等事务执行完成才会写入 binlog,再传给备库。如果一个主库上语句执行 10 分钟,那么这个事务可能会导致从库延迟 10 分钟。
从库的并行复制能力。
解决方法
配合 semi-sync 半同步复制;
一主多从,分摊从库压力;
强制走主库方案(强一致性);
sleep 方案:主库更新后,读从库之前先 sleep 一下;
判断主备无延迟方案(例如判断 seconds_behind_master 参数是否已经等于 0、对比位点);
并行复制 — 解决从库复制延迟的问题;
19、MySQL读写分离-Mycat 1.6.5版本
在数据库集群架构中,让主库负责处理写入操作,而从库只负责处理select查询,让两者分工明确达到提高数据库整体读写性能。当然,主数据库另外一个功能就是负责将数据变更同步到从库中,也就是写操作。
读写分离的好处:
1. 分摊服务器压力,提高机器的系统处理效率。
2. 在写入不变,大大分摊了读取,提高了系统性能。另外,当读取被分摊后,又间接提高了写入的性能。所以,总体性能提高了。
3. 增加冗余,提高服务可用性,当一台数据库服务器宕机后可以调整另外一台从库以最快速度恢复服务。
部署过程:
Mycat 是数据库中间件,就是介于数据库与应用之间,进行数据处理与交互的中间服务是实现对主从数据库的读写分离、读的负载均衡。
MyCAT 是使用 JAVA 语言进行编写开发,使用前需要先安装 JAVA 运行环境(JRE),由于 MyCAT 中使用了 JDK7 中的一些特性,所以要求必须在 JDK7 以上的版本上运行。
在主从复制实现的基础上做的读写分离,主节点进行写操作,从节点进行读操作
1.我们首先给mycat部署安装环境,安装jdk,设置环境变量,然后再下载安装mycat
2.配置mycat,先修改mycat的server.xml的配置文件,要注意添加的逻辑库和用到的用户,然后配置另一个文件schema.xml,要注意逻辑虚拟库一定要一致,然后要开启读写分离模式,
3.在真实的数据库上给你使用到的用户授权,然后我们可以在mycat机器上测试mycat用户登录
4.启动mycat测试mycat,我们在登录设置好的用户,插入一条数据,然后再mycat上查看,再去主节点和从节点查看即可
20、MySQL数据库占用内存过高怎么解决?
找到/etc/my.cnf 配置文件,如果有修改就用修改过的文件
找到并修改:table_definition_cache 存储在定义缓存中的表定义数,可以修改为400;
table_open_cache 所有线程的打开表数,增加这个值会增加MySQL所需的文件描述符的数量,可以修改为256M;
performance_schema 修改为 off ,用于监控MySQL server在一个较低级别的运行过程中的资源消耗、资源等待情况,关闭之后可以节省开销。
再重启MySQL服务就可以了
常用MySQL命令
GRANT privileges ON databasename.tablename TO 'username'@'host';
GRANT SELECT, INSERT ,updata ON test.user TO 'javacui'@'%';
alter table t3 add math int(10);-------添加的字段
insert into t3(id,name,sex,age) values(1,"tom","m",18); 插入数据
update 表名 set 修改的字段 where 给谁修改; 更新数据
from 表1 inner join 表2 on 条件 内连接多表查询
revoke select,delete on *.* from jack@'%'; #回收指定权限
mysqladmin -uroot -p'123' password 'new_password' 修改密码
DROP USER 'user3'@'localhost'; 删除用户
Redis总结
1、关系型数据库与非关系型数据库的区别
关系型数据库有:MySQL、SQLserver、Oracle、MariaDB
非关系型数据库有:Redis、MongoDB、HBase、Memcached
关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织。
优点:
1、易于维护:都是使用表结构,格式一致;
2、使用方便:支持SQL语言通用,使用方便;
3、复杂操作:可用于一个表以及多个表之间非常复杂的查询。缺点:
1、读写性能比较差,尤其是海量数据的高效率读写;
2、固定的表结构,灵活度稍欠;
3、高并发读写需求,传统关系型数据库来说,硬盘I/O是一个很大的瓶颈;
非关系型数据是一种数据结构化存储方法的集合,可以是文档或者键值对等
优点:
1、格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
2、速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘;
3、成本低:nosql数据库部署简单,基本都是开源软件。
缺点:
1、不提供sql支持,学习和使用成本较高;
2、无事务处理;但是Redis支持事务
3、数据结构相对复杂,复杂查询方面稍欠。
2、Redis相比较其他非关系型数据库的优点?
优点
1. 数据存储在内存, 读写速度快,性能优异
2. 支持数据持久化,便于数据备份、恢复
3. 支持简单的事务,操作满足原子性
4. 支持String、List、Hash、Set、Zset五种数据类型,满足多场景需求
5. 支持主从复制,实现读写分离,分担读的压力
6. 支持哨兵机制,实现自动故障转移
缺点:
1. 数据存储在内存,主机断电则数据丢失
2. 存储容量受到物理内存的限制,只能用于小数据量的高性能操作
3. 在线扩容比较困难,系统上线时必须确保有足够的空间
4. 用于缓存时,易出现’缓存雪崩‘,’缓存击穿‘等问题
3、Redis数据持久化的方式
RDB:是在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上;
RDB 特点:周期性、不影响数据写入、高效但是完整性较差(故障点到上一次备份,之间的数据无法修复)
AOF:将redis执行过的所有写指令记录下来,在下次redis重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。
特点:实时性、完整性较好、体积大占用内存相对会较多
AOF存储的是执行的命令,RDB存储的是二进制格式数据
我们一般使用的是RDB方式,AOF视情况开启,一般只会选择一种,因为开启两种的话,可能会对redis造成一定的压力。只用RDB的话虽然数据完整性不高,但是影响也不大,因为数据库中还有一份,只需要同步到redis就行。
4、Redis主从同步的原理
从服务器会向主服务器发出SYNC指令,当主服务器接到此命令后,就会调用BGSAVE指令来创建一个子进程专门进行数据持久化工作,也就是将主服务器的数据写入RDB文件中。在数据持久化期间,主服务器将执行的写指令都缓存在内存中。
在BGSAVE指令执行完成后,主服务器会将持久化好的RDB文件发送给从服务器,从服务器接到此文件后会将其存储到磁盘上,然后再将其读取到内存中。这个动作完成后,主服务器会将这段时间缓存的写指令再以redis协议的格式发送给从服务器。
5、Redis有几种集群方式
- redis有三种集群模式,其中主从是最常见的模式。
- Sentinel 哨兵模式是为了弥补主从复制集群中主机宕机后,主备切换的复杂性而演变出来的。哨兵顾名思义,就是用来监控的,主要作用就是监控主从集群,自动切换主备,完成集群故障转移。
- cluster 模式是redis官方提供的集群模式,使用了Sharding 技术,不仅实现了高可用、读写分离、也实现了真正的分布式存储。
- 注意Redis不用Keepalived做高可用,Redis自带高可用,哨兵模式
6、哨兵模式的工作原理
每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令。
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。
如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 。
master服务器宕机之后,哨兵自动会在从redis的slave服务器里面 选举一个master主服务器出来
如果之前宕机的主服务器已经修好,可以正式运行了,自动成为slave,然后哨兵监控的master也会进行切换。
7、Redis Cluster去中心化集群部署
集群为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或者多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当主节点挂掉后,就会在从节点中选取一个来当主节点,保证集群不会挂掉,保证每个主节点都要有从节点
1、我们一般配置三主三从,这里我们准备三台机器,每台机器上部署两个redis,修改配置文件里改一下端口号、ip、pid、日志文件名等,然后要把cluster集群开启,设置集群主节点的最小从节点数量,然后配置哈希槽的分配规则,要哈希槽全覆盖才能提供服务。
2、创建cluster集群,在任意一个节点创建即可,使用redis-cli --cluster create模块创建集群,前面三个写主节点,后三个写从节点,我们要注意避免主节点在同一个机器,创建之后系统自动分配从节点,
集群添加节点
我们准备一台新机器,安装两个redis,端口号为7006 7007,然后还是修改ip 端口号 pid等
我们先把主节点添加到集群中,就是把你要添加的主节点加入到任意一个主节点上即可,然后我们要给新添加的主节点分配hash槽,这样主节点才能保存数据,如果有数据记得提前将数据同步然后迁移到其他节点,分配好了之后,我们给这个主节点添加从节点,然后平衡各个主节点的槽
删除节点
如果要下线节点,要先删除从节点,我们这里也是先删除从节点,然后先查看主节点有多少hash槽,将主节点的hash槽迁移到其他节点,尽量分配平均,确保主节点上没有hash槽了然后删除主节点即可。
8、做Redis集群时遇到的问题
一、如何解决redis,mysql双写一致性?
1.最典型的缓存+数据库读写模式
读的时候,先读缓存,缓存没有的话,就读数据库,然后去除数据后放入缓存,同时返回响应。更新的时候,先更新数据库,然后删除缓存。
2.给缓存设置过期时间,这种方案下,可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存
二、缓存雪崩及解决办法
缓存在同一时间大面积失效,从而导致所有的请求都去查数据库,导致数据库和CPU负载过高,甚至宕机
解决方法:缓存高可用,缓存层设计高可用,防止缓存大面积故障,即使一个宕机掉依然可以提供服务,redis数据备份
三、缓存穿透
缓存穿透是指查询一个不存在的数据,缓存中没有,需要去数据库中查询,然后大量的请求会到达数据库,从而压垮数据库
解决方法:如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库。设置一个过期时间或者当有值的时候将缓存中的值替换掉即可。
9、你们有对Redis做读写分离吗
正常:没有做
集群:不做读写分离。我们用的是Redis Cluster的架构,是属于分片集群的架构。而redis本身在内存上操作,不会涉及IO吞吐,即使读写分离也不会提升太多性能,Redis在生产上的主要问题是考虑容量,单机最多10-20G,key太多降低redis性能.因此采用分片集群结构,已经能保证了我们的性能。其次,用上了读写分离后,还要考虑主从一致性,主从延迟等问题,徒增业务复杂度。
10、Redis优化思路
1.分库;
多数人并不推荐分库,但是有些场景分库是能够提到立竿见影的效果的;如果代码中不得不用较多的keys操作,而业务又可以隔离,能显著提升性能;其底层优化逻辑在于keys操作无法通过哈希表来定位元素,这时定位元素的时间复杂度便不是0(1),而是0(n); 分库对于删除redis中的数据也是比较友好的;
2.集群+哈希;多线程版本分支keydb;
redis是单线程也便意味着不能使用多核;当单核不能满足性能要求是便需要考虑使用上多核,毕竟当redis成为系统的瓶颈时,业务一定程度上串行了;多redis需要在业务层上对数据进行分离,如根据key哈希到不同的redis中存储;如果业务数据无法进行拆分,keydb也是不错的选择(其作者更愿意为了性能提高实现的复杂性),其本身做多线程处理,其使用了reuseport特性,多个worker线程处理;
3.可靠性没特别高要求的不要持久化;
4.使用redis的lazy-free功能延迟删除;
lazy-free时redis4以后的功能,其将删除操作放到非主线程进行操作,这样可以避免大量删除造成的性能波动;
5.redis多实例;
某些情况下多个redis或者将redis编译为动态库链接到系统中未尝不可进行考虑;使用系统多个程序使用不同的redis,并且对性能有极高要求;
6.排查数据是否合适放在redis中
如数据使用频繁而不会变动是否可以写在共享内存中,共享内存是最快的进程通信方式,不会触发系统调用;只读不写是最适合共享内存的应用场景了;
7.避免使用keys操作;
keys会导致查找的时间复杂度为0(n);
其它复杂度命令也要少用;Redis 命令参考 — Redis 命令参考有给出每个命令的时间复杂度;
8.本地使用UNIX套接字而非TCP;
9.使用DPDK优化通信;
DPDK是对通信的优化,加上用户态协议栈,直接在用户态完成通信,不过需要代码进行改动调用DPDK接口;目前腾讯云的f-stack已经将redis的DPDK版本实现;
10.key尽可能短;
降低内存,减少哈希表的算法执行时间;
11.新版本的redis开启多线程(redis自身的多线程是主线程处理命令,其它几个线程处理IO);
12.不要存过大的数据;
过大的数据存取和删除都会更为耗时;
13.使用pipline批量操作数据;
14.设置数据过期时间;
设置过期时间,减少redis中的数据量,但要注意避免大量数据同时失效;
15.减少不必要的连接;
能用连接池的情况下使用连接池;
11、Redis和MySQL的区别
mysql支持事务,redis不支持。mysql支持通用sql语句,redis不支持。mysql使用固定表结构,可用复杂查询。mysql的数据存储方式单一,redis数据存储比较灵活。mysql数据存储于磁盘,对于高并发的读写请求,磁盘io是很大的瓶颈。redis的数据存储于磁盘或者内存中,读写效率更高。
12、Redis针对内存过高,有其他操作吗?
设置key的过期时间,对于不经常使用的key过期时间可以设置的小一点。redis会将所有设置了过期时间的key放入一个字典中,然后每隔一段时间从字典中随机取一些key检查过期时间,并删除已过期的key。
13、哈希槽什么概念,如何进行分配
Redis-cluster集群中有16384(0-16383)个哈希槽,每个redis实例负责一部分slot,集群中的所有信息通过节点数据交换而更新。一个hash slot中会有很多key和value。
每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。
Nginx相关
nginx的优缺点
优点:
1.工作在OSI第7层,可以针对http应用做一些分流的策略。比如针对域名、目录 结构。它的正则比HAProxy更为强大和灵活;
2. Nginx对网络的依赖非常小,理论上能ping通就就能进行负载功能,这个也是它的优势所在;
3. Nginx安装和配置比较简单,测试起来比较方便
4.可以承担高的负载压力且稳定,一般能支撑超过几万次的并发量;
5.Nginx可以通过端口检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点
6.Nginx不仅仅是一款优秀的负载均衡器/反向代理软件,它同时也是功能强大的Web应用服务器。
缺点:
1. 对后端服务器的健康检查,只支持通过端口来检测,不支持通过url来检测,不支持Session的直接保持,但能通过ip_hash来解决
2.Nginx仅能支持http、https和Email协议,这个它的弱势。
3. 处理不了动态请求,单进程多线程模式,进程死掉会影响很多用户
1、介绍一下Nginx
nginx是一款轻量级、高性能、稳定性高、并发性好的http和反向代理服务器(支持https),同时也是一款负载均衡软件,可以做7层和四层负载均衡。可以做动静分离,nginx解析静态页面的效率非常高,nginx功能非常强大,常用的比如地址重写,防盗链,会话保持,访问控制流量控制等
2、http协议的三大特性是什么?
1.http是无状态。
指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
2.HTTP是无连接。
无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
3.灵活
HTTP协议允许传输任意类型的数据,如json格式数据、表单数据、xml、文件流等等,需要在HTTP报文中指明Content-Type的类型
3、传输层有几种协议?有什么区别
1、TCP协议
TCP是一种面向连接的协议,它在传输数据之前会建立一条专用的通信连接。这意味着在数据传输过程中,两台计算机之间会有一条稳定的数据传输通道。因此,TCP可以保证数据传输的可靠性,但会带来一定的延迟。
面向连接,速度慢,可靠传输
2、UDP协议
UDP是一种无连接的协议,它不会建立专用的通信连接。每个数据包都是独立的,可以直接传输。因此,UDP的传输速度比TCP快,但不能保证数据传输的可靠性。
无连接,速度快,不可靠传输
3、区别
TCP是面向连接的传输层协议,传输前先要建立连接。UDP是不需要连接的,即刻传输数据。
TCP是一对一的两点式服务,一条连接只能有两个端点。UDP支持一对一,一对多,多对多交互通信。
TCP是可靠交付数据,数据可以无差错、不丢失、不重复、按需到达。UDP是尽最大努力交付,不保证可靠交付数据。
TCP是流式传输,没有边界,但保证顺序和可靠。UDP是一个包一个包的发送,是没有边界的,但可能会丢包和乱序。
4、http请求头。响应头里面都包含什么?
请求头
- Accept:浏览器能够处理的内容类型
- Accept-Charset:浏览器能够显示的字符集
- Accept-Encoding:浏览器能够处理的压缩编码
- Accept-Language:浏览器当前设置的语言
- Connection:浏览器与服务器之间连接的类型
- Cookie:当前页面设置的任何Cookie
- Host:发出请求的页面所在的域
- Referer:发出请求的页面的URL
- User-Agent:浏览器的用户代理字符串
响应头
- Accept-Ranges:表明服务器是否支持指定范围请求及哪种类型的分段请求
- Content-Encoding:web服务器支持的返回内容压缩编码类型。
- Content-Language:响应体的语言
- Content-Length:响应体的长度
5、http常用的状态码
常见的 HTTP 状态码:
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 403 - 服务器理解请求客户端的请求,但是拒绝执行此请求
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
- 502 - 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应
- 503 - 由于超载或系统维护,服务器暂时的无法处理客户端的请求。
6、什么是虚拟主机
虚拟主机,就是把一台物理服务器划分成多个虚拟的服务器,这样我们的一台物理服务器就可以做多个服务器来使用,从而可以配置多个网站。nginx提供虚拟主机的功能,就是为了让我们不需要安装多个nginx,就可以运行多个域名不同的网站。
配置虚拟主机的方式:基于域名的虚拟主机,基于ip的虚拟主机,基于端口的虚拟主机
7、Nginx都可以做什么?
1.负载均衡
负载均衡多用在高并发情况下使用的。其原理就是将数据流量分摊到多个服务器执行,减轻每台服务器的压力,多台服务器共同完成工作任务,从而提高了数据的吞吐量。
2.反向代理
反向代理是用来代理服务器的,代理我们要访问的目标服务器,代理服务器接受请求,然后将请求转发给内部网络的服务器,并将从服务器上得到的结果返回给客户端,此时代理服务器对外就表现为一个服务器,
3.动静分离
nginx提供的动静分离是把动态请求和静态请求分离开,合适的服务器处理相应的请求,是整个服务器系统的性能、效率更高。
nginx可以根据配置对不同的请求做不同转发,这是动静分离的基础,静态请求对应的静态资源可以直接放在nginx上做缓冲,更好的做法是放在相应的缓冲服务器上,动态请求由相应的后端服务器处理。
4、还可以做防盗链、图片压缩、访问控制,地址重写等
8、反向代理和正向代理的区别
反向代理的过程隐藏了真实的服务器,客户不知道真正提供服务的机器是哪台,客户端请求的服务都被代理服务器处理。我们请求www.baidu.com时,这www.baidu.com就是反向代理服务器,真实提供服务的服务器有很多台,反向代理服务器会把我们的请求转发到真实提供服务的各台服务器。
正向代理:正向代理的过程隐藏了真实的请求客户端,服务器不知道真实的客户端是谁,客户端请求的服务都被代理服务器代替请求,我们常说的代理也就是正向代理,正向代理代理的是请求方,也就是客户端;比如我们要访问YouTube,可是不能访问,只能先安装个VPN软件代你去访问,这就叫正向代理。
区别:
正向代理即是客户端代理,代理客户端,服务端不知道实际发起请求的客户端是谁。
反向代理即是服务端代理,代理服务端,客户端不知道实际提供服务的服务端是谁。
9、负载均衡的算法有几种?
1.轮询 2.权重3.ip_hash 4.url_hash 5.fair智能模块算法
轮询:将每个请求按时间顺序分配到不同的后端服务器
ip_hash:将同一个IP客户端通过hash算法固定到一个后端服务器
url——hash:将访问的url定向到同一个后端服务器
10、Nginx会话保持的方式
1.ip_hash
ip_hash使用源地址哈希算法,将同一客户端的请求总是发往同一个后端服务器,除非该服务器不可用。
2.sticky_cookie_insert
使用sticky_cookie_insert启用会话亲缘关系,这会导致来自同一客户端的请求被传递到一组服务器的同一台服务器。与ip_hash不同之处在于,它不是基于IP来判断客户端的,而是基于cookie来判断。因此可以避免上述ip_hash中来自同一客户端导致负载失衡的情况。(需要引入第三方模块才能实现)
3.jvm_route
11、为什么要做会话保持?
- 通过会话保持,用户请求可以被路由到同一台服务器处理,避免了多个服务器之间的数据传输和处理,减少了额外的计算开销,提高了系统的处理效率。
- 在一些复杂的交互场景中,用户可能需要执行多步骤的事务操作,例如填写表单、购物结算等。通过会话保持,多个相关的请求可以被路由到同一个后端服务器处理,保证了事务的完整性,提高了用户体验。
12、为什么要做动静分离?
为了加快网站的解析速度,可以把动态页面和静态页面由不同的服务器来解析,加快解析速度。降低原来单个服务器的压力。 在动静分离的tomcat的时候比较明显,因为tomcat解析静态很慢,其实这些原理的话都很好理解,简单来说,就是使用正则表达式匹配过滤,然后交给不同的服务器。
13、Nginx与Apache的区别?
nginx是轻量级,作为web服务器,相比apache来说,nginx使用更少的资源,支持更多的并发连接,体现更高的效率
nginx配置简洁,apache更复杂,nginx的静态处理性能比apache高3倍以上但是nginx的动态处理性能则比较弱
最核心的区别在于apache是同步多进程模型,一个连接对应一个进程;nginx是异步的,多个连接可以对应一个进程
nginx可以作为负载均衡服务器,支持7层负载均衡
14、https与http的区别
1.https协议需要申请证书,一般免费的证书比较少,因此需要一定的费用
2.http是超文本传输协议,信息是明文传输的,https则是具有安全性的ssl加密传输协议。
3.http和https使用的是完全不同的连接方式,用的端口也不一样,http用的是80端口,https用的是443端口。
15、https的加密算法
1.对称加密
A要给B发送数据
1、A做一个对称密钥
2、使用密钥给文件加密
3、发送加密以后的文件和密钥
4、B拿密钥解密
加密和解密都是使用的同一个密钥。2.非对称加密
A要给B发送数据
1、B做一对非对称的密钥(公钥、私钥)
2、发送公钥给A
3、A拿公钥对数据进行加密
4、发送加密后的数据给B
5、B拿私钥解密3.哈希算法
将任意长度的信息转换为较短的固定长度的值,通常其长度要比信息小得多。
例如:MD5、SHA-1、SHA-2、SHA-256 等4.数字签名
签名就是在信息的后面再加上一段内容(信息经过hash后的值),可以证明信息没有被修改过。
16、Nginx如何优化
1、配置worker_processes
worker_processes的数量并不是越多越好,要看自己的处理器cpu有多少,也可以设置为auto,自动绑定cpu
2.日志配置成warn
这样错误日志里面就会记载了更少的记录
3.针对 nginx 的访问文件限制 worker_rlimit_nofile
我们可以限制用户的访问文件数量,来降低负载
4.worker_connections
每一个进程可以处理多少个连接,增加该值可以提高系统的并发能力
5.keepalive_timeout 65
长连接的等待时间,可以根据需求进行优化
6.gzip on;
可以打开压缩,压缩访问页面的图片等一些资源提高访问速度, 进而优化Nginx性能
17、Nginx怎么做反向代理?
Nginx 需要配置文件里面定义,如果后端地址比较多,需要用upstream 模块定义后端服务器地址池,然后再server模块中,定义location模块,用Proxy_pass 转发到此地址池。这样的效果,其实还起到了七层负载均衡的作用。
18、Nginx的优缺点
1.工作在OSI第7层,可以针对http应用做一些分流的策略。比如针对域名、目录 结构。它的正则比HAProxy更为强大和灵活;
2. Nginx对网络的依赖非常小,理论上能ping通就就能进行负载功能,这个也是它的优势所在;
3. Nginx安装和配置比较简单,测试起来比较方便
4.可以承担高的负载压力且稳定,一般能支撑超过几万次的并发量;
5.Nginx可以通过端口检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点
6.Nginx不仅仅是一款优秀的负载均衡器/反向代理软件,它同时也是功能强大的Web应用服务器。LNMP现在也是非常流行的web环境,大有和LAMP环境分庭抗礼之势,Nginx在处理静态页面、特别是抗高并发方面相对apache有优势;
7.Nginx现在作为Web反向加速缓存越来越成熟了,速度比传统的Squid服务器更快,有需求的朋友可以考虑用其作为反向代理加速器;
缺点:
1. 对后端服务器的健康检查,只支持通过端口来检测,不支持通过url来检测
,不支持Session的直接保持,但能通过ip_hash来解决
2.Nginx仅能支持http、https和Email协议,这个它的弱势。
3. 处理不了动态请求,单进程多线程模式,进程死掉会影响很多用户
19、Nginx怎么做七层负载均衡
Nginx 需要配置文件里面定义,如果后端地址比较多,需要用upstream 模块定义后端服务器地址池,然后再server模块中,定义location模块,用Proxy_pass 转发到此地址池。这样的效果,其实还起到了反向代理的作用。
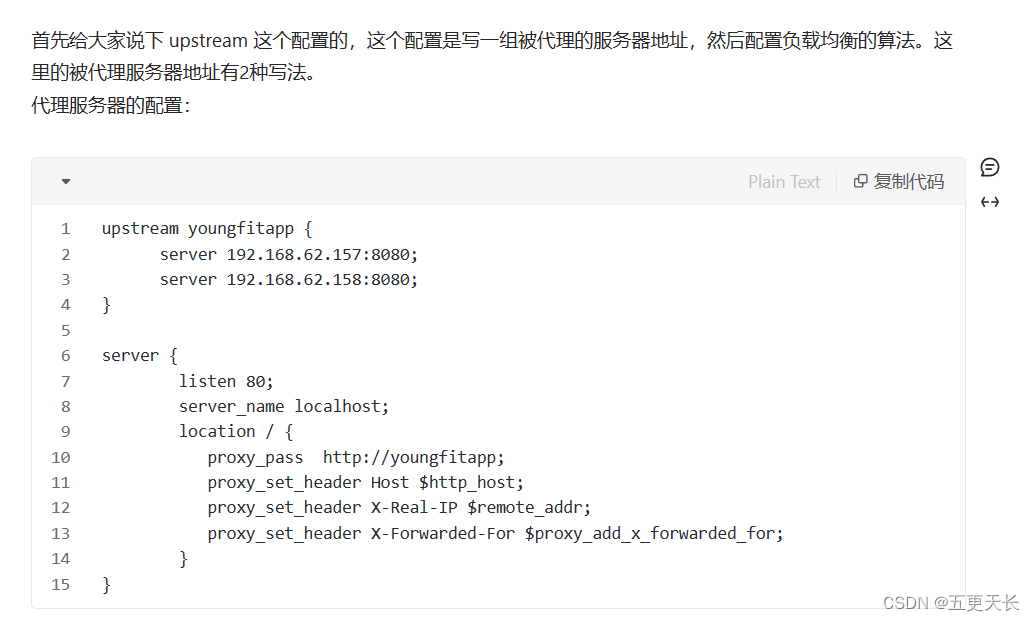
Nginx怎么做负载均衡
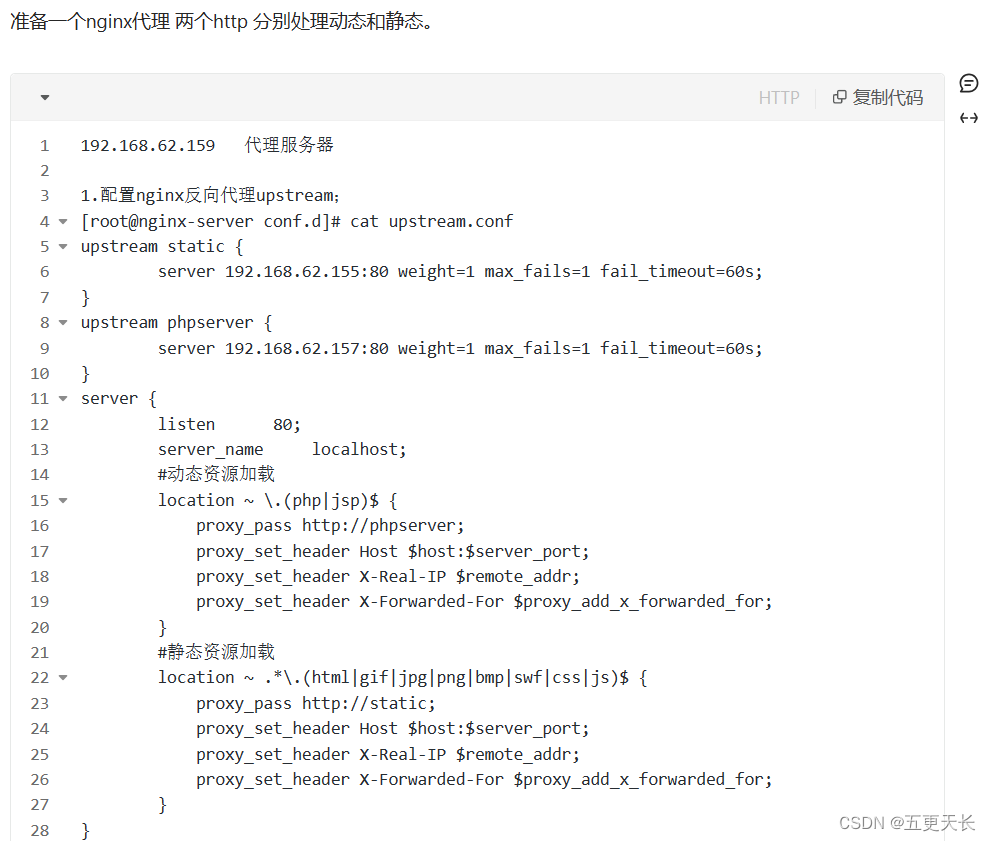
Nginx怎么做动静分离
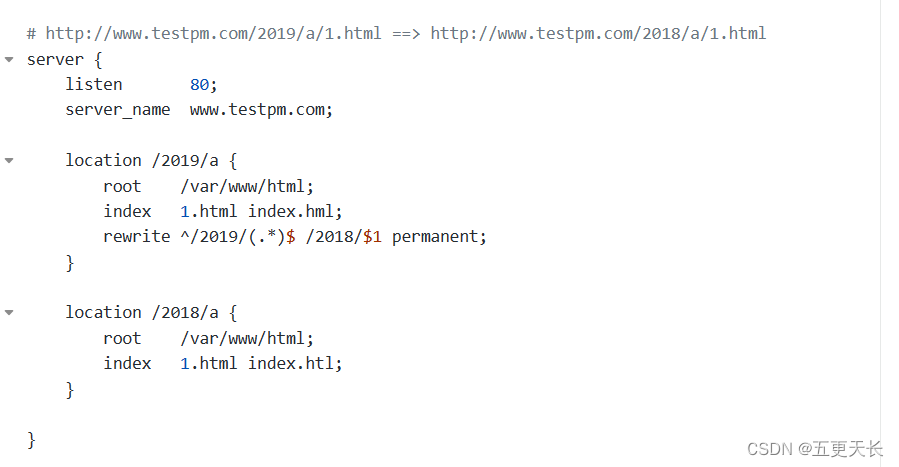
怎么做地址重写
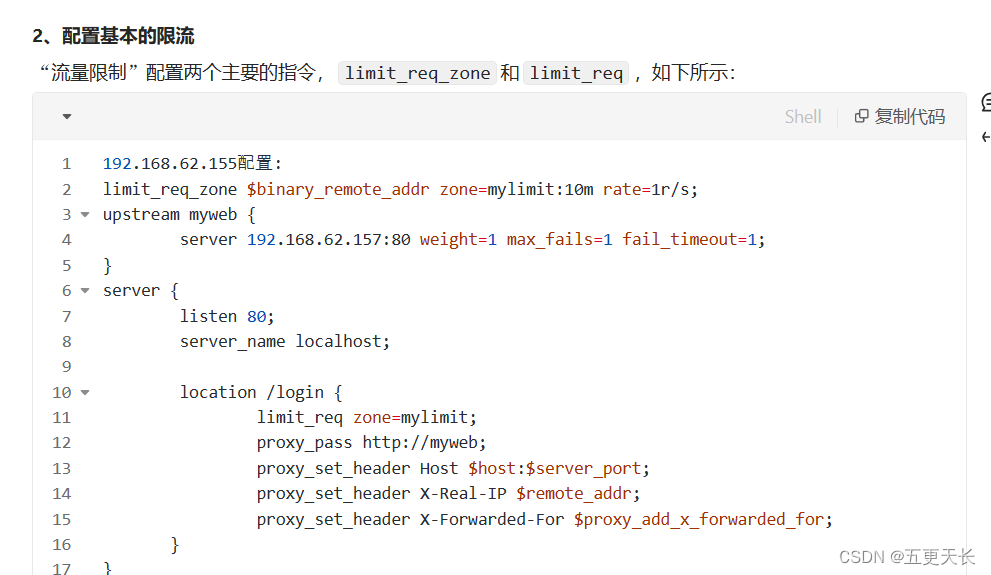
Nginx怎么做流量限制

Nginx怎么做访问控制
20、Nginx怎么做防盗链
防盗链(ngx_http_referer_module)是为了防止非法盗链影响站点的正常访问。
配置 vaild_referers 的参数,如 none | blocked | server_names | string字符串等, valid_referers 指令用于设置允许访问资源的网站白名单,允许一些网站合法盗链使用我们的资源;
21、Nginx怎么做平滑升级
- 先下载并解压一个新版本的nginx
- 删除软连接
- 我们可以先查看当前nginx的已有的模块,然后我们在解压目录里进行预编译执行/configure 在后面添加之前的模块。
- 使用make进行编译,一定不要make install
- 我们可以把之前的nginx二进制文件进行备份
- 把新的nginx、二进制文件复制到源码包中
- 我们用usr2发送平滑迁移信号,产生pid
- 用WINCH逐步关闭work进程
- 用HUP重新加载配置文件,使用新的配置启动进程,逐步关闭旧进程
- 用QUIT等待请求处理结束后在退出,完成升级
22、gzip压缩怎么配置,
Gzip压缩是nginx中的一个module模块,文件压缩模块:ngx_http_gzip_module
配置:
gzip on / off 开启或关闭压缩功能;
gzip_comp_level level 压缩级别设置,可以1~9,默认为1;
gzip_http_version 1.0 / 1.1 设置压缩版本,默认为1.1;
gzip_buffers 4 8k 设置压缩缓冲区大小,如4个8k内存作为压缩结果流缓存;
gzip_types 压缩的文件格式,如scc、html ;
gzip_min_length 1k 压缩的最小文件,小于此值的文件不压缩。
( gzip_vary on 给响应头加个vary,告知客户端能否缓存;)
------------------------------------------------------------------------------------------------
一般在传输文件的时候,数据过大,带宽占用过高,可以通过设置压缩的最小文件值,控制大小达到一定值就可以进行文件压缩,减少传输数据的大小;
在使用gzip去压缩图片时,一般不使用Gzip压缩,因此需要设置需要压缩的文件类型。因为图片本身已经是被压缩过了,所以再使用GZIP去压缩,反而在其中增添了校验的字节、增大的图片体积,适得其反,不仅无法降低传输大小,还浪费了服务器和客户端的CPU资源去做这个处理。
缺点:
会增加相当大的处理开销,增大延时,对性能产生负面影响
23、访问网站页面处理速度比较慢怎么优化
可能原因:服务器出口带宽不够用、服务器负载过大、数据库瓶颈、网站开发代码没有优化好
排查与解决:
首先要确定是客户端还是服务端的问题。可以先自己访问进行测试一下访问处理速度,
如果访问的快,就基本是客户端问题,就和客户沟通解释;
如果自己访问也慢,可以利用浏览器的调试功能,看是哪一项数据消耗时间过多,可以设置nginx的Gzip压缩功能
1.如果是出口带宽问题,就申请加大出口带宽
2.针对服务器负载情况。查看服务器网络、CPU、内存等硬件的消耗情况。如果是购买的云主机,比如阿里云就登录阿里云查看各方面的监控。
3.如果发现硬件资源消耗都不高,就通过查日志,比如MySQL慢查询日志,看看是不是某条SQL语句查询慢
一般需要开发人员或DBA数据库管理员协助进行SQL语句的优化
4.如果是数据库响应慢,可以考虑使用redis缓存数据库,也可以扩展一下MySQL的主从数量,或者利用MyCat做读写分离,一主写,多从读
24、如何配置ssl证书
第一步下载证书到本地电脑中
在阿里云控制台中的SSL操作界面中找到刚申请成功的免费SSL证书,点击右侧的下载链接,弹出下载页面,然后点击Nginx右侧的下载按钮,下载证书文件。
下载完是一个zip压缩包文件,需要进行解压,解压下来是两个文件:
以.key为后缀的文件是密钥文件
以.pem为后缀的文件是证书文件
第二步上传到服务器中的特定文件夹目录下
将第1步中的证书文件(.pem结尾)和密钥文件(.key)文件上传到Nginx服务器中,这两个文件具体的放置路径是在Nginx安装目录下的conf/cert文件夹中。
第三步配置nginx.conf,使证书生效
修改nginx的配置文件/usr/local/nginx/conf/nginx.conf,修改之前最好通过复制命令将该配置文件备份一份,在配置文件里添加一些配置即可,完成后重新启动即可
25、Nginx如何获取客户端地址
在nginx代理的配置文件中添加,proxy_set_hearder X-Forwarded-For $remode_addr
在nginx的真实web服务器上,也需要相同的配置。
26、Nginx-http请求方法
HTTP1.0定义了3种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了5种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
重点方法:
GET:单纯获取数据(获取一个index.html页面)
POST:上传/创建文件(会产生新的数据)
PUT:保存数据(覆盖/更新文件、图片等,不会产生新的数据)
DELETE:删除
1、GET是获取数据,POST是提交数据的。
2、GET参数通过URL传递,POST放在Request body中
3. GET请求只能进行url编码,而POST支持多种编码方式。
4. GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
Tomcat相关
1、Tomcat如何优化
1.服务器资源
增加cpu,内存,硬盘
2.采用集群
单个服务器性能总是有限的,最好的办法自然是实现横向扩展,那么组建tomcat集群是有效提升性能的手段。我们还是采用了Nginx来作为请求分流的服务器。
3.优化tomcat参数
调优Tomcat线程池:增加线程池中最大的线程数量等
调优tomcat的连接器Connector:关闭DNS解析,减少性能损耗,修改最少最大可以创建的线程数,等
4.jvm优化
Tomcat 是运行在 JVM 上的,所以对 JVM 的调优也是非常有必要的。
找到 catalina.sh;调整堆大小的的目的是最小化垃圾收集的时间,以在特定的时间内最大化处理客户的请求。
5.定时重启tomcat
性能优化:
内存优化:-Xms java虚拟机初始化时的最小内存、-Xmx java虚拟机可使用的最大内存
并发优化:maxThreads 客户请求最大线程数、minSpareThreads tomcat初始化时创建的socket线程数、maxSpareThreads tomcat连接器的最大空闲socket线程数、enableLookups 若设置为true,则支持域名解析,可把ip地址解析为主机名、redirectPort 在需要基于安全通道的场合,把客户请求转发到基于ssl的redirectPort端口、acceptAccount 监听端口队列最大数,满了之后客户请求会被拒绝(不能小于maxSpareThreads)、connectionTimeout 连接超时
缓存优化:compression 打开压缩功能、
compressionMinSize 启用压缩的输出内容大小,默认为2kb、compressableMimeType 压缩类型、connectionTimeout定义建立客户连接超时的时间,如果为-1,表示不限制建立客户连接的时间
安全方面优化
降权启动,防止不法分子通过tomcat获得root权限
修改端口号:修改tomcat配置文件server.xml中的http连接器端口号,防止黑客攻击
更改tomcat的关闭指令:
隐藏服务类型:在server.xml文件中,为connector元素添加server=” ”,注意不是空字符串,是空格组成的长度为1的字符串,或者输入其他的服务类型,在response header中不显示server的信息
LVS相关&&haproxy
1、LVS的四种工作模式
nat模式:
原理:把客户端发来的数据包的ip头的目的地址,在负载均衡器上换成其中一台的rs的ip地址,并发至次rs进行处理,处理完之后,将数据包交给负载均衡器,负载均衡器将源ip改为自己的vip,把目的ip改为客户端的ip。期间不论进来的流量和出去的流量都经过负载均衡器。
优点:集群中的物理服务器可以使用任何支持tcp/ip操作系统,仅负载均衡器需要一个合法ip
缺点:扩展性有限,当服务器节点增长过多时,负载均衡器将成为整个系统的瓶颈,因为所有的请求包和应答包都要经过负载均衡器。当服务器节点过多时,大量的数据包都交汇在负载均衡器那,速度就会变得很慢
DR模式
负载均衡器和rs使用同一个ip对外服务,但只有dr对ARP请求进行响应,所有的rs对本身这个ip的arp请求保持静默,也就是说网关会把对这个服务ip的请求全部定向给dr,dr根据调度算法找出对应的rs,把目的MAC地址改为rs的MAC地址(因为ip一致),并将请求转发到这台rs,rs收到数据包,处理完成后由于ip一致,直接将数据返给客户端,等于直接从客户端收到数据包无异,处理完直接返回给客户端。由于负载均衡器要对二层包头进行改换,所以负载均衡器和rs之间必须在同一个广播域,也可以理解为在同一台交换机上。
优点:和tun模式一样,负载均衡器只负责转发请求,应答包通过单独的路由方法返回给客户端,与tun模式相比,dr模式不需要隧道结构,因此可以使用大多数操作系统作为物理服务器
缺点:(不能说缺点,只能说是不足)要求负载均衡器的网卡必须与物理网卡在一个物理段上。
tun模式(隧道模式)
原理:首先要知道,互联网上的请求包一般都很小,而应答包却很大。那么隧道模式就是把客户端发来的数据包,封装一个新的ip头标记(仅目的ip)发送给rs,rs收到后先把数据包的头解开,还原数据包,处理后直接返回给客户端,不需要再经过负载均衡器,注意,由于rs需要对数据包进行还原,所以必须支持Iptunnel协议,所以在rs的内核中,必须编译支持Iptunnel这个选项
优点:负载均衡器只负责分发请求包,而rs直接返回给客户,减少了负载均衡器的大量数据流量,负载均衡器就能处理很大量的请求,这种方式一台负载均衡器能够为很多rs进行分发,而且跑在公网上就能对不同地域进行分发。
缺点:隧道模式的rs节点都需要合法ip,这种方式需要所有服务器支持IP tunneling协议,服务器可能只局限在部分linux系统上。
2、LVS和Nginx和haproxy的区别
1.nginx工作在网络的第7层,所以它可以针对http应用本身来做分流策略,相比之下lvs并不具备这样的功能,
2.nginx对网络的依赖较小,理论上只要ping得通,网页访问正常,nginx就能连得通,lvs就比较依赖于网络环境,目前来看服务器在同一网段内并且lvs使用direct方式分流,效果较能得到保证。
3.nginx安装和配置比较简单,测试起来也很方便,因为它基本能把错误用日志打印出来。lvs的安装和配置、测试就要花比较长的时间,
4.nginx也同样能承受很高负载且稳定,但负载度很稳定度差lvs还有几个等级
5.nginx可以检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,
6.nginx 工作在网络的第 7 层,可以作为网页静态服务器,支持 Rewrite 重写规则;支持 GZIP 压缩,节省带宽;可以做缓存;可以针对 http 应用本身来做分流策略,静态分离,针对域名、目录结构等相比之下 LVS 并不具备这样的功能,
lvs基于系统内核实现软负载均衡,而haproxy和nginx是基于第三方应用实现的软负载均衡。
lvs是基于四层的负载均衡,所以做不了基于url和目录的转发
haproxy是基于四层和七层的转发,是专业的负载均衡软件
nginx既是web服务器、缓存服务器、又是反向代理服务器,可以做七层和四层的转发
3、LVS的算法
静态算法:rr轮询,按顺序一个一个来,均等对待每一台服务器,不考虑服务器的实际连接数和系统负载
wrr:根据节点权重和顺序分发请求
sh:匹配客户端最近一次访问的服务器节点,将请求交给这个服务器
动态算法:
lc:动态将请求调度到已建立连接数最少的服务器
wlc:调度器自动问询服务器的负载情况,动态调整权值
4、四层负载均衡和七层负载均衡的区别
| 四层负载均衡 | 七层负载均衡 | |
| 基于 | 基于IP+端口 | 基于URL或主机IP |
| 类似于 | 路由器 | 代理服务器 |
| 复杂度 | 低 | 高 |
| 性能 | 高:无需解析内容 | 中:需要算法识别URL和HTTP head等 |
| 安全性 | 低 | 高 |
| 额外功能 | 无 | 会话保持,图片压缩,防盗链,地址重写,流量限制 |
从上面的对比看来四层负载与七层负载最大的区别就是效率与功能的区别。四层负载架构设计比较简单,无需解析具体的消息内容,在网络吞吐量及处理能力上会相对比较高,而七层负载均衡的优势则体现在功能多,控制灵活强大。在具体业务架构设计时,使用七层负载或者四层负载还得根据具体的情况综合考虑。
5、介绍一下haproxy
haproxy是支持虚拟主机的,可以工作在四层、七层(支持多网段)
haproxy能够补充nginx的一些缺点,比如会话保持、cookie的引导,同时支持通过获取指定的url检测后端服务器的状态
haproxy跟lvs类似,本身就是一款负载均衡软件,单纯从效率上讲haproxy比nginx有更出色的负载均衡速度,在并发处理上也优于nginx
haproxy支持tcp协议的负载均衡转发,可以对mysql读进行负载均衡
6、什么时候用Nginx什么时候用haproxy什么时候用LVS
在并发量大得时候可以用lvs,中小型公司可用nginx或者haproxy,如果只是单纯的负载均衡可以用haproxy。
但如果是web服务器的话,建议使用nginx,这也是nginx用的多的原因。还用一种情况可以使用lvs和haproxy,比如RabbitMQ集群,有三台RabbitMQ,我们都知道RabbitMQ镜像模式使用还是比较多的,每个节点都提供服务,但我们总不能给开发提供三个RabbitMQ的节点吧,也不能只提供一个节点的ip,所以就可以使用lvs或者haproxy给三个RabbitMQ提供一个VIP,这样开发老铁可以用这个vip写进前端的配置中。不至于所有数据都往一个RabbitMQ上发送
Keepalived相关
1、你们都用什么做高可用,什么原理?
高可用我们用的是keepalived
工作原理:keepalived是集群管理中保证集群高可用的一个服务软件,用来防止单节点故障,keepalived是一VRRP协议来实现的,VRRP是虚拟路由冗余协议,在keepalived服务正常时,主master节点会不断的向备用节点发送心跳消息,用以告诉备用节点自己还活着,当主master节点发生故障时,就无法发送心跳消息,备用节点也就无法检测master的心跳了,于是就调用自身的接管程序,接管master节点的vip以及当前的服务,当master节点恢复时,因为master节点的优先级比较高,所以vip就会重新回到master,继续工作
2、都给什么做过高可用?
高可用我们用的是keepalived
工作原理:keepalived是集群管理中保证集群高可用的一个服务软件,用来防止单节点故障,keepalived是一VRRP协议来实现的,VRRP是虚拟路由冗余协议,在keepalived服务正常时,主master节点会不断的向备用节点发送心跳消息,用以告诉备用节点自己还活着,当主master节点发生故障时,就无法发送心跳消息,备用节点也就无法检测master的心跳了,于是就调用自身的接管程序,接管master节点的vip以及当前的服务,当master节点恢复时,因为master节点的优先级比较高,所以vip就会重新回到master,继续工作。
我们做高可用时使用到keepalived,做的是七层的负载均衡,我们用两台机器作为代理服务器,一台作为主服务器,一台备用,我们先给主代理服务器做负载均衡,在nginx的配置文件里进行配置即可,配置成功后直接将配置文件拷贝到另一台备用机器上,然后再测试一下备用机器能用负载均衡不能,然后我们对主服务器做高可用,两台机器都先下载keepalived服务,然后我们修改主服务器的keepalived的配置文件,主要是配置心跳检测,创建一个虚拟的vip,还有就是主服务器和备用的优先级不一样,主服务器的优先级会比较高,配置完启动即可;然后还可以加入检测服务脚本,检测nginx是否可以使用,如果nginx不可用,keepalived的会停止服务,然后备用服务器就会使用vip继续进行服务。
给lvs做高可用,做过lvs/dr lvs/nat,我们用到的高可用软件是keepalived,因为lvs和keepalived的适配度很高,所以我们不用单独对lvs做分配规则和负载均衡,我们可以直接在keepalived的配置文件里做,安装好keepalived之后,修改配置文件,配置文件里先进性集群配置,还是设置一个vip进行访问,然后对lvs进行配置,比如启用几个进程,用什么调度算法,用什么协议等,备用机器的配置文件基本一致,然后配置后端的服务器,我们要把用到的vip添加到lo网卡上,然后忽略arp广播,匹配精确ip地址回包,然后进行测试即可
lvs/nat模式做高可用相比于DR模式就比较复杂了,还是两台机器做keepalived集群,其中一个作为备用,我们要用到俩个网卡所以添加一个桥接模式的网卡,我们需要做两个虚拟ip,一个网卡上添加一个vip,然后我们修改keepalived的配置文件,首先配置桥接网卡的vip,注意在一个网段即可,然后配置集群,在配置ens33的vip两台代理服务器配置好了之后,要开启路由转发,然后把ens33的vip添加到使用到的后端服务器上,开启服务即可。
要注意添加的vip要在同一网段内,主服务器和备用的定义的名字要不一样,优先级一定要有一定的差距,集群的调度器要一致,
3、Keepalived三个主要模块
分别是core、check和vrrp。
core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。
check负责健康检查,包括常见的各种检查方式。
vrrp模块是来实现VRRP协议的。
Ansible相关
1、Ansible的工作原理
Ansible由节点和控制机器组成。 控制机器是安装Ansibles的地方,节点由这些机器通过SSH管理。 借助SSH协议,控制机器可以部署临时存储在远程节点上的模块。
控制机器使用ansible或者ansible-playbooks在服务器终端输入的Ansible命令集或者playbook后,Ansible会遵循预先编排的规则将PLAYbook逐条拆解为Play,再将Play组织成Ansible可以识别的任务tasks,随后调用任务涉及到的所有MODULES及PLUGINS,根据主机清单INVENTORY中定义的主机列表通过SSH协议将任务集以临时文件或者命令的形式传输到远程节点并返回结果,如果是临时文件则执行完毕后自动删除。
2、Ansible的模块,你都使用过哪些?
1.copy
src=:指定源文件路径 dest=:目标地址(拷贝到哪里) owner:指定属主 group:指定属组 mode:指定权限,可以以数字指定比如0644
2.yum模块
state= #状态是什么,干什么
state=absent 用于remove安装包
state=latest 表示最新的
state=removed 表示卸载3.服务管理的service模块
name=httpd state=started 启动
name=httpd state=stopped 停止
name=httpd state=restarted 重启
4.文件模块file
owner:修改属主
group:修改属组
mode:修改权限
path=:要修改文件的路径
recurse:递归的设置文件的属性,只对目录有效
yes:表示使用递归设置
state:
touch:创建一个新的空文件
directory:创建一个新的目录,当目录存在时不会进行修改5.command模块
chdir ##执行命令前先进入到指定目录 cmd ##运行命令指定 creates ##如果文件存在将不运行 removes ##如果文件存在将运行
3、Ansible的剧本格式
- hosts: (控制节点)
user: (指定用户)
tasks: (任务元素,一个剧本只能有一个tasks)
- name: (定义tasks的名称,可以有多个name)
file: (使用的模块)
tags:
notify:
handlers: (用于当前关注的资源发生变化时采取的指定的操作)
- name: (名称要跟notify定义的对应)
tags: (给指定任务定义一个调用标识)
4、Ansible比其他自动运维工具的优缺点
1.部署简单,只需在主控端部署Ansible环境,被控端无需做任何操作;
2.默认使用SSH协议对设备进行管理;
3.有大量常规运维操作模块,可实现日常绝大部分操作;
4.配置简单、功能强大、扩展性强;
5.支持API及自定义模块,可通过Python轻松扩展;
6.通过Playbooks来定制强大的配置、状态管理;
7.轻量级,无需在客户端安装agent,更新时,只需在操作机上进行一次更新即可;
5、shell模块和command模块的区别
6、写过什么剧本、用Ansible做过什么?
jenkins +jdk +tomcat ,redis集群,
用ansible批量部署一些服务,比如控制多台机器批量下载安装nginx等,
然后还可以查看每台机器上的一些使用信息,比如查看某台机器的cpu使用率
Gitlab相关
1、git与SVN的区别
- 存储方式:Git使用的是元数据存储方式,它存储的是文件里的内容,并以key/value格式存储,返回key值作为唯一标识。而SVN则是直接存储文件。
- 使用方式:在Git中,代码的提交需要先添加到暂存区,然后再提交到本地仓库,最后才能推送到远程仓库。而在SVN中,可以直接提交到远程仓库。
- 管理模式:Git是一种分布式的系统,每个开发人员都可以从中心版本库/服务器上检出代码,并在自己的机器上克隆一个自己的版本库。SVN则是集中式的管理模式,所有版本信息都保存在中央服务器上。
- 分支管理:Git的分支管理更为简单和有趣。每一个Git仓库都可以有多个分支,并且可以在不同分支之间自由切换。而在SVN中,每一个分支都是从主干上拷贝出来的,并且每次切换分支都需要与主干进行合并。
2、github、Gitlab、Gitee的区别
GitLab是一个完整的持续集成/持续交付(CI/CD)平台,它提供了从代码托管到部署的一站式服务。GitLab还提供了强大的项目管理和协作工具,例如Wiki、 issue跟踪和代码审查。GitLab也可以在本地部署,因此可以在私有网络中进行安全存储和访问。
GitHub是一个基于Web的Git仓库托管服务,它提供了一个开源的代码托管平台,可以让开发者们共享和协作开发项目。GitHub还提供了一些额外的功能,例如GitHub Pages、GitHub Actions和GitHub Packages等。
Gitee是中国的Git托管服务,类似于GitHub和GitLab,它提供了代码托管、项目管理和协作工具。Gitee也支持私有仓库和企业版服务,可以满足企业的安全和隐私需求。
GitLab和Gitee都提供了数据备份和恢复功能,可以保证数据的安全性。GitHub也提供了数据备份功能,但在数据安全方面的保障相对较弱
GitLab和Gitee都提供了企业版服务,可以满足企业的安全和隐私需求。GitHub也提供了企业版服务,但价格相对较高。
3、公有代码仓库和私有代码仓库的区别
- 公开性:公有代码仓库,如GitHub,是公开的,任何人都可以查看、克隆和贡献代码。私有代码仓库则是私有的,只有授权的人才能够访问。
- 访问权限:公有仓库对所有人开放,任何人都可以进行修改和提交。私有仓库则只有特定的人能够访问和修改。
- 安全性:公有仓库的开源特性使得任何人都可以发现和报告安全漏洞。私有仓库的封闭性则可能导致安全问题被长期忽视。
- 社区支持:公有仓库因为其公开性和社区性质,往往能得到更广泛的社区支持和参与。私有仓库则相对较少受到社区的关注和支持。
- 开源文化:公有仓库鼓励开源文化和社区精神的传播,私有仓库则不强调这一点
Jenkins相关
1、Jenkins是什么?
Jenkins是一个用Java编写的开源自动化工具,带有为持续集成目的而构建的插件。Jenkins用于持续构建和测试您的软件项目,从而使开发人员更容易将更改集成到项目中,并使用户更容易获得全新的构建。它还允许您通过与大量测试和部署技术集成来持续交付软件。
2、Jenkins的工作流程
从git仓库拉取代码(需要git插件,jenkins服务器下载git,并将jenkins的公钥配置到仓库的ssh密钥,jenkinsweb界面配置自己的私钥),通过maven编译打包(可以达成war包或jar包,需要jdk和maven的环境和插件),将打包好的包发送到web服务器的网站发布目录(需要将jenkins的公钥发送到web服务器对应的用户家目录)
3、Jenkins部署
Deploy to container ---支持自动化代码部署到tomcat容器
GIT plugin 可能已经安装,可在已安装列表中查询出来
Maven Integration jenkins利用Maven编译,打包所需插件
Publish Over SSH 通过ssh连接
enkins一般是配合tomcat使用的,所以我们先安装jdk8,tomcat8,maven3 jenkins用2.346版本即可
1、我们登录后安装推荐的插件即可,后面用到哪个在安装,我们平常用到的插件,maven插件:Mave integration plugin 发布插件 :Deploy to container Plugin ssh插件:Publish over ssh email邮箱插件等
2、我们配置jenkins的私钥,因为是用ssh连接的,公钥发给后端服务器,然后对SSH server进行配置连接填写后端服务器的ip
3、配置jdk和maven,在全局配置工具中配置即可,要注意路径一定要和自己的安装路径一致
4.构建发布任务,我们自定义一个就行,构建maven项目,然后可以设置构建策略,比如保持构建的天数等,然后进行源码管理,这里我们一般使用Gitlab,所以选择Git即可,填写正确的URL,然后配置maven版本,调用maven打包命令clean package,构建环境,一定要和后端的标识对应上,之后打包上传,然后可以配置邮箱,把构建结果通知到人,然后点击立即构建即可
5.我们也可以使用参数化构建,比如tag标签构建,commit修订号构建,如果开发人员不愿意给更新的代码打标签,我们就可以让他们用修订号的方式推送代码,让他们尽量把更新内容写详细点,我们在配置里使用git参数构建,参数类型选择标签,然后排序方式可以选择逆序,然指定分支那里填tag的值即可,这样以标签的方式推送代码,我们就会显示标签名,方便版本切换,修订号是一样的方法,
4、Jenkins自动化触发构建
实现的效果是:只要gitlab仓库的代码更新,或者有新的分支推送,jenkins就会自动拉取代码,自动完成构建任务,无需人为手动点击,jenkins版本2.346,gitlab版本16.0.4
1.我们先配置gitlab和后端服务器,可以用SSH方式拉取代码即可,然后创建一个gitlab私有仓库。
2.安装配置jenkins,和上面部署一样,注意的是我们要把部署jenkins机器的私钥,配置到项目中,把jenkins的公钥配置到gitlab中,这样就可以免密拉取代码。
3.构建触发器,这里会生成一个URL和认证密钥 我们要记录下来配置到gitlab中的webhook
4.配置gitlab,我们点击设置中的webhooks,把jenkins中生成的url和认证密钥部署上去,注意要打开允许本地网络发送webhook请求,我们可以进行测试,成功的话会显示200,我们可以选择有新代码更新,或者有分支推送,会触发构建。
5、Jenkins自动化构建有什么好处
- 自动化:Jenkins可以自动地触发构建过程,包括编译、打包、生成构建报告等,从而节省开发人员的时间和精力。
- 准确性:通过自动化构建,可以避免由于手动构建而导致的错误,从而提高构建的准确性。
- 效率:通过Jenkins自动化触发构建,可以及时发现和解决构建过程中的问题,加快软件交付的速度。
- 可重复性:自动化构建可以确保每次构建的结果都是一致的,无论是由谁或者在哪个环境下进行的构建。
- 灵活性:Jenkins支持不同的构建环境和流程,可以根据需要轻松地配置和扩展。
- 监控和报告:Jenkins提供了实时监控和报告功能,可以及时发现和解决构建过程中的问题。
6、在使用Jenkins的时候遇到过什么问题?怎么解决
1.构建项目报错:有时候在配置Jenkins构建项目时,会出现报错,导致构建无法正常进行。解决方法是仔细检查配置信息,例如源代码仓库地址、构建工具路径等,并确保它们是正确的。
2.无法获取构建依赖:有时候构建过程中会提示缺少依赖项,这是因为Jenkins没有正确地获取到构建所需的依赖。解决方法是检查构建脚本或配置文件,确保它们是正确的,并且包含了所有必需的依赖项。
3.构建失败后的自动邮件通知失败:有时候在Jenkins中配置了构建失败后的自动邮件通知,但是它无法正常工作。解决方法是检查邮件服务器配置和SMTP服务器地址等信息,并确保它们是正确的。
4.Jenkins服务启动失败:有时候Jenkins服务无法正常启动,可能是因为某些配置文件或插件存在问题。解决方法是仔细检查Jenkins的配置文件和插件,确保它们是正确的并且没有冲突。
5. Jenkins和Tomcat的版本兼容性问题、部署的应用程序无法正常运行等。解决方法是检查Jenkins和Tomcat的版本兼容性,以及应用程序的部署配置。
7、Jenkins怎么把war包部署到后端服务器
我们使用jenkins结合Ansible部署
8、Jenkins都需要什么插件
- Status Monitor Plugin:构建状态插件
- Publish Over SSH Plugin:通过ssh发布文件
- Job Configuration History Plugin:使用心得:使job具备版本管理的能力,diff和rollback功能更是非常赞
- Periodic Backup:使用心得:备份是运维一个系统必须要保障的事情,该插件的恢复功能可能不可用,需要手工进行,好处在于可以定时备份
- Build-timeout Plugin:任务构建超时插件
zabbix相关
1、zabbix的监控模式
被动模式:server端向agent端请求获取监控项配置的相关数据,agent端响应,并将数据发送给server端 ,监控对象上报故障
优点:占用网络资源少,占用存储资源少
缺点:及时性差
主动模式:agent端主动向server请求与自己相关监控配置,主动将server配置的监控项的相关数据发送给server端 ,定时查看业务状态
优点:及时性好
缺点:占用资源
2、你们用zabbix监控什么?自定义监控什么内容
硬件、软件、网络、集群、数据库、操作系统性能
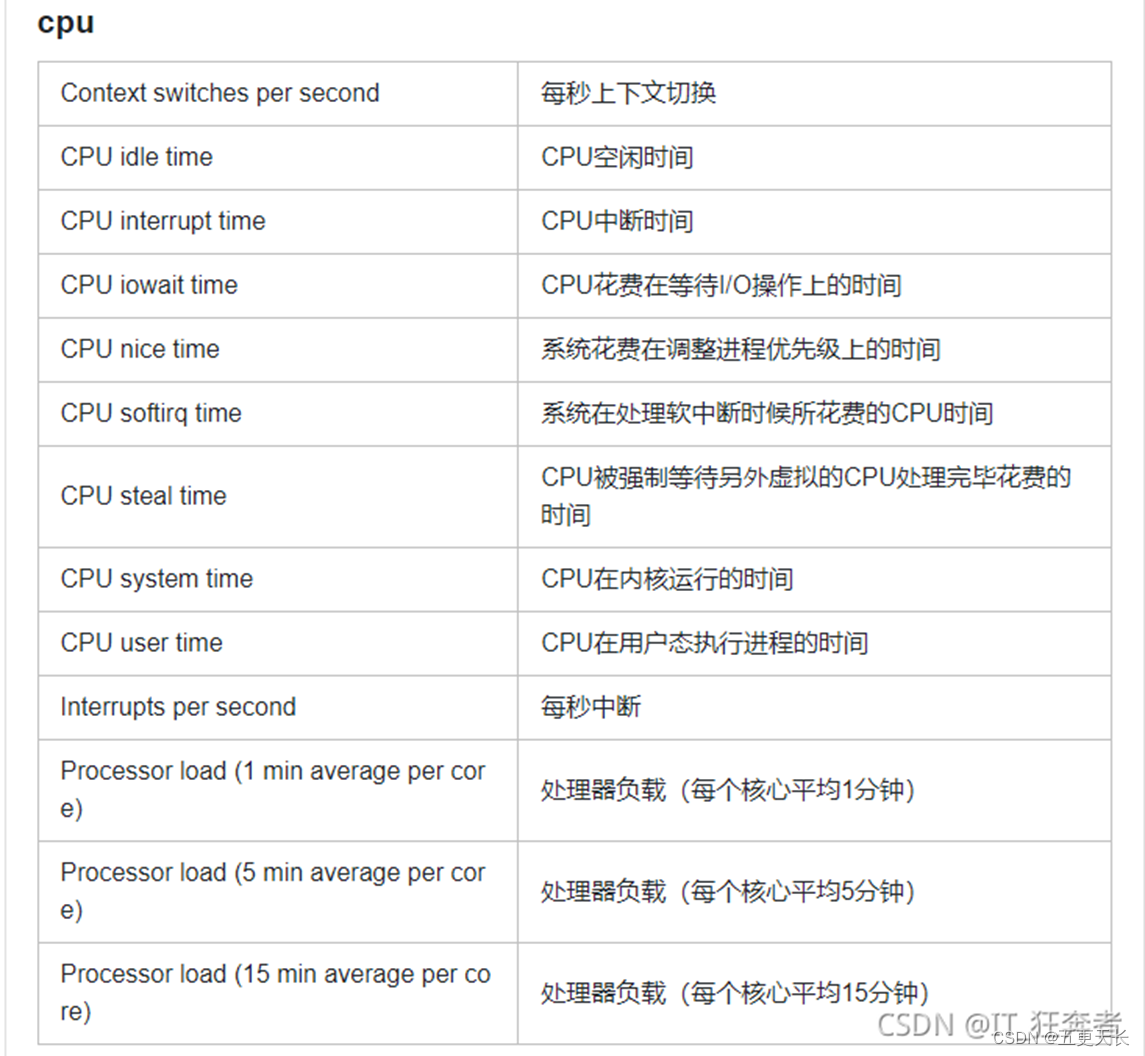
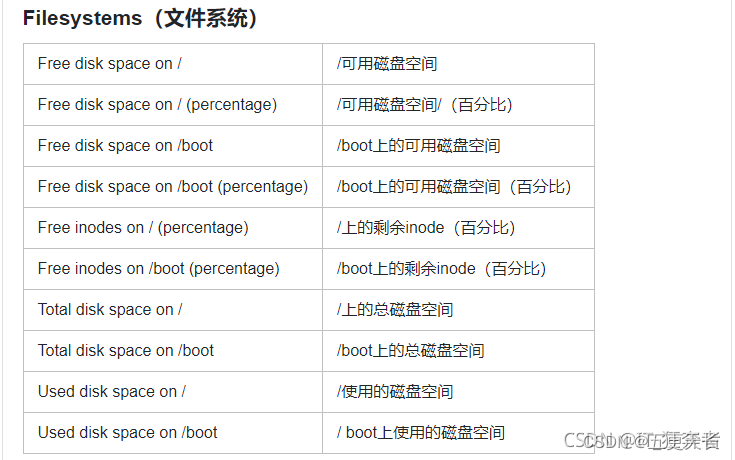
MySQL我们监控的有主从状态,监控MySQL的吞吐量、主从延迟、连接数等。监控Redis,监控Nginx的性能状态:连接数,处理请求数等,监控CPU的平均负载、中断时间、在内核运行的时间、监控可用的磁盘空间、使用的磁盘空间、监控网络,监控剩余内存、swap空间剩余量、正在运行的进程数、
监控MySQL及其主从状态
1.我们先部署好MySQL的主从,我们先监控master以及slave的3306端口,监测MySQL服务有没有出现错误,这里我们就直接使用zabbix自带的监控项即可,
2.监控MySQL的主从状态,这里我们主要就是查看slave的sql和io线程的状态是不是yes,所有我们会用到grep 进行一个命令操作,我们先修改slave节点的配置文件,我们要让MySQL不使用密码就能使用root用户登录,这样能方便我们后续进行操作,我们加入一个[mysql],然后在下面写入root用户已经密码,也些入主机ip,然后我们用非交互式命令,mysql -e 在数据库外查看slave的状态,然后用grep -E过滤出 sql和io,然后再过滤统计Yes的数量,正常即是2,然后我们在zabbix的配置文件-zabbix.agent.d下写一个自定义的.conf文件,就是写的UserParameter键值对,键是自定义的,也是后面要做成监控项的,值就是我们使用grep得到的值,然后要记得重启zabbix-agent服务,我们可以在zabbix上使用zabbix_get测试一下,如果有值,我们就可以使用了,在页面创建一个监控项,我们设置的键值一定要是我们定义的键值,然后后面就是我蛮正常的操作的了,添加触发器,我们可以给触发器设置成监控到最近一次的数值小于2,就触发即可,然后设置触发器动作,添加报警媒介就可以了。
监控MySQL主从延迟
监控MySQL主从延迟我们还是和监控主从状态一样使用一样的命令,只不过我们过滤的是SQL_Delay,然后awk以冒号为分隔符,截取第二段,就会获得延迟时间,在配置触发器的时候,我们可以设置为超过几秒就报警即可,可以设置为超过3秒等
监控MySQL吞吐量
自定义监控项普通用法,键值对方式
mysqladmin extended-status | awk '/\<Com_insert\>/{print $4}'
我们用mysqladmin命令外部查看ectened-status,然后这里可以查看到插入,查询等的数量,然后我们用awk截取出来Com_insert这个单词部分,然后截取第四列即可,就可以获取到插入用到了几次,然后查询删除都是一样的用法,然后我们在zabbix的配置文件/etc/zabbix/zabbix-agent.d下编辑一个.conf文件,里面写入UserParameter键值对,键是自己定义的,值就是那个mysqladmin命令,然后我们可以在监控端使用zabbix_get测试一下,如果有值我们在去web页面添加监控项,
自定义监控升级用法使用shell脚本
我们可以编写一个shell脚本,脚本里写的主要也是mysqladmin命令然后awk截取到值,脚本里是把这些截取值的命令写成函数,然后在最后面写一个变量$1,用于传参,然后我们给脚本一个执行权限,后面我们还是在agent的配置文件下自定义一个.conf的配置文件,写入键值对,键我们写的是自定义的mysql_status[*] 然后值写的是bash 后面是脚本的绝对路径,最后是一个$1,传入的是【】里写入的字符串,然后就会调用脚本里的函数,就会出现值,然后就是可以get测试一下,可以的话我们就去页面添加监控项,因为比较多,我们就可以直接添加一个模板即可,然后给模板创建监控项,触发器,然后给动作添加媒介,最后把模板关联到主机即可
监控nginx
思路:首先。要先监控nginx的状态,我们要先在配置文件的server模块里添加配置文件,开启nginx的status状态,然后通过awk截取status的各个状态值,然后我们可以将取值的命令写成脚本,然后再以键值对的方式写到.conf的配置文件,然后可以在监控端使用get测试一下,能取到值的话就可以使用,然后创建监控项,创建触发器,添加动作即可
Accepts:接受的客户端请求数
Active:当前活跃的连接数
Handled:处理的请求数(正常服务器响应)
Requests:客户端处理的请求出(吞吐量)
Reading:当接收到的请求时,连接离开waiting状态,并且该请求本身使Reading状态统计数增加,这种状态下,nginx会读取客户端请求首部,请求首部是比较小的,因此这通常是一种快捷的操作
Writing:请求被读取之后,使得Writing状态计数增加,并保持在该状态,直到响应返回给客户端,这便意味着,该请求在writing状态时,
3、平常监控服务器的哪些内容


4、zabbix的优缺点
zabbix优点:
1、数据采集:可用性和性能检测,自动发现,支持agent、snmp、JMX、telnet等多种采集方式,支持主动和被动模式数据传输、支持用户自定义插件,自定义间隔收集数据
2、高可用:server对设备性能要求低,支持proxy分布式监控,分布式集中管理,有自动发现功能,可以实现自动化监控;开放式接口,扩展性强,插件编写容易
3、告警管理:支持多条件告警,支持多种告警方式,支持多组模板,模板继承。
4、告警设置:告警周期,告警级别,告警恢复通知、告警暂停,时段阈值、支持维护周期、支持单机停用
5、图形化展示:允许自定义创建多监控项视图,网络拓扑,自定义面板展示,自定义IT服务可用性
6、历史数据:历史数据查询可配置,内置housekeeping数据清理机制
7、安全审计:具备安全的用户审计日志,权限认证,用户可以限制允许维护的列表。
zabbix缺点:
1、性能瓶颈,监控系统没有低估高峰期,具有持续性和周期性,机器量越大,数据的增大会使数据库的写入成为一定的瓶颈,官网给出的单机上限5000台,届时就需要增加proxy,增加成本。
2、Zabbix采集数据有pull方式,也就是server主动模式,当目标机器量大之后,pull任务会出现积压。采集数据会延迟
3、项目二次开发,需要分析MySQL表结构,表结构比较复杂,通过API开发对开发能力有要求。
4、内置housekeeping在执行过程中会对数据库增加压力,需要对数据库进行优化
5、zabbix怎么开启企业微信报警
首先,需要有一个微信企业号。(一个实名认证的[微信号]一个可以使用的[手机号]一个可以登录的[邮箱号]
下载并配置微信公众平台私有接口。
配置Zabbix告警,(增加示警媒介类型,添加用户报警媒介,添加报警动作)。
6、你们都监控过Redis的什么指标
1. Redis响应一个请求的时间
2. 平均每秒处理请求总数
3. 已使用内存
4.客户端连接数
7、zabbix自动发现功能
创建发现规则,扫描一个规则范围内的ip,然后创建发现主机后的action动作,我们一般都有创建好的模板,模板关联某个主机群组(有监控项、触发器、动作),发现主机后,将它添加到主机群组,实现自动化监控
8、你都接收过什么报警信息
服务器报警: 当服务器的CPU利用率、内存使用率、磁盘空间等超过阈值时,会触发服务器报警。此时,我们会通过邮件或者微信等方式通知运维人员,并尽快处理问题,以避免对业务的影响。(CPU太高,内存太高,挖矿病毒)
应用程序报警:当应用程序出现异常、访问量过大或者请求超时等问题时,会触发应用程序报警。我们会通过邮件或者钉钉等方式通知开发人员或者运维人员,协调解决问题,以确保业务的正常运行。(MySQL主从失效)(Tomcat堆栈吃内存)
网络报警:当网络出现故障、流量异常、连接数过大等问题时,会触发网络报警。我们会通过邮件或者微信等方式通知网络运维人员,协调解决问题,以保证网络的稳定和可靠(nginx并发量)
9、zabbix遇到过什么问题
1.遇到中文字体显示问题,会出现乱码,我一般都是在自己电脑上找到字体,然后把文件拷贝上传到机器上,然后拷贝到zabbix字体的保存目录,给他改个名,给它权限然后重启zabbix即可
2.监控项报警后,报警媒介没有触发,我一般使用的动作克隆,关联好媒介之后可能没点更新,或者是没有关联用户,导致触发之后没有发送报警信息
3.创建自定义监控项时,在使用get测试的时候获取不到值,原因是写完.conf配置文件之后忘了重启zabbix-agent,还有创建监控项的时候键值名写错,最好直接复制,避免手敲
4.创建自定义监控项,使用脚本的时候,脚本里使用了函数,结果最后面忘了写个$1变量,取不到值,还有就是写完脚本要给脚本执行权限,在写键值对的时候最后也要加个$1
5.不要忘了校对时间
6.开启zabbix-agent2的时候开启失败,结果发现zabbix-agent还开着,占用了端口
问题1:主机有30多个图形,但是查看时只显示了20个图形。
原因:是因为zabbix的php默认值为20。
解决:修改zabbix前端默认配置文件 defines.inc.php中的 ZBX_MAX_GRAPHS_P ER_PAGE变量值,重启服务即可。
问题2: 内存溢出导致zabbix_server服务关闭?
解决:修改/etc/zabbix/zabbix_server.conf配置文件里添加CacheSize=1024M ,重启服务
问题3:Zabbix给新机器添加监控,按正常操作完成后,发现主机那一栏最后的灯不亮
解决:检查防火墙和SELinux是否关闭,查zabbix_server日志,查zabbox是否启动,来回检查了好几遍,没发现问题,删除后重新加了两遍,还是灯不亮,后来在网上找相关的解决方法,试了发现不是自己遇到的问题,等过了一段时间发现灯正常亮了。
10、讲一下告警屏蔽
1.处于维护中的主机,告警信息还是会报出来,但是不会触发动作;
2. 对于可预知的临时维护或紧急维护,可以提前设置告警屏蔽;
3. 可针对组、单台或多台主机,进行一次性、每日定时、每月定时、每周定时屏蔽;
4. 前端可以将维护中的主机不进行显示,Dashboard右上角有个图标可以进行筛选是否显示维护中的主机;
5. 告警屏蔽时,可以设置采集数据或不采集数据两种方式。
11.说一下zabbix和Prometheus的区别
| Zabbix | Prometheus |
|---|---|
| 后端用 C 开发,界面用 PHP 开发,定制化难度很高。 | 后端用 golang 开发,前端是 Grafana,JSON 编辑即可解决。定制化难度较低。 |
| 集群规模上限为 10000 个节点。 | 支持更大的集群规模,速度也更快。 |
| 更适合监控物理机环境。 | 更适合云环境的监控,对 OpenStack,Kubernetes 有更好的集成。 |
| 监控数据存储在关系型数据库内,如 MySQL,很难从现有数据中扩展维度。 | 监控数据存储在基于时间序列的数据库内,便于对已有数据进行新的聚合。 |
| 安装简单,zabbix-server 一个软件包中包括了所有的服务端功能。 | 安装相对复杂,监控、告警和界面都分属于不同的组件。 |
| 图形化界面比较成熟,界面上基本上能完成全部的配置操作。 | 界面相对较弱,很多配置需要修改配置文件。 |
| 发展时间更长,对于很多监控场景,都有现成的解决方案。 | 2015 年后开始快速发展,但发展时间较短,成熟度不及 Zabbix。 |
综合来看,Zabbix 的成熟度更高,上手更快,但更好的集成导致灵活性较差,问题更大是,监控数据的复杂度增加后,Zabbix 做进一步定制难度很高,即使做好了定制,也没法利用之前收集到的数据了(关系型数据库造成的问题)。
Prometheus 基本上是正相反,上手难度大一些,但由于定制灵活度高,数据也有更多的聚合可能,起步后的使用难度远小于 Zabbix。
如果监控的是物理机,Zabbix 在传统监控系统中,尤其是在服务器相关监控方面,占据绝对优势。
如果是云环境的话,除非是 Zabbix 玩的非常溜,可以做各种定制,Prometheus更有优势
Firewalld和iptables
1、四表五链说一下
1、filter(过滤)进行包过滤处理的一张表
2、nat(网络地址转换)对数据地址信息进行转换、数据包端口信息进行转换
3、mangle(重新封装)给数据包打标记,做标记
4、raw (追踪)将数据包一些标记信息进行拆解
INPUT 就是过滤进来的数据包(输入)
OUTPUT 发出去的数据包
PREROUTING 进路由之前的数据包
POSTROUTING 出路由之后的数据包
FORWARD 转发
2、iptables处理数据包的四种方式
ACCEPT 允许数据包通过
DROP 直接丢弃数据包,不给任何回应信息
REJECT 拒绝数据包通过,必要时会给数据包发送一个响应信息
3、Firewalld的区域(zone)有哪些
1、public 默认区域,仅允许ssh dhcpv6-client数据通过
2、trusted 允许所有流量通过
3、work 仅允许ssh ipp-client dhcpv6-client数据通过
4、block 任何传入的网络数据包都将被阻止,拒绝所有流量
5、drop 丢弃所有流量,没有返回回应消息
4、说一下iptables和Firewalld的区别
1、Firewalld操作使用的是区域,iptables操作的四表五链
2、Firewalld默认是拒绝的,需要设置以后才能放行,iptables默认是允许的,需要拒绝的才能去限制
3、Firewalld可以动态修改单条规则,动态管理规则集,允许更新规则而不破坏现有的会话和连接,而iptables,在修改了规则后必须全部刷新才能生效
4、Firewalld自身并不具备防火墙的功能,而是和iptables一样需要通过内核的netfilter来实现的,
5、iptables的配置文件在/etc/sysconfig/iptables中,而Firewalld的配置文件在/usr/lib/firewalld和/etc/firewalld中的各种xml文件中
6、iptables通过控制端口来实现控制服务,Firewalld是通过控制协议来控制端口的
5、防火墙常用命令
iptables
iptables -I INPUT -p tcp --dport 22 -j REJECT 拒绝所有机器通过ssh(22端口)连接
Rabbitmq消息队列
1、你们公司用的什么消息中间件?原理是什么
用的RabbitMQ 我们通常谈到消息队列,就会联想到这其中的三者:生产者、消费者和消息队列,生产者将消息发送到消息队列,消费者从消息队列中获取消息进行处理。对于RabbitMQ,它在此基础上做了一层抽象,引入了交换器exchange的概念,交换器是作用于生产者和消息队列之间的中间桥梁,它起了一种消息路由的作用,也就是说生产者并不和消息队列直接关联,而是先发送给交换器,再由交换器路由到对应的队列,
2、RabbitMQ与kafka的区别
kafka是基于pull的模式来处理消息消费,追求高吞吐量,目的是用于日志的搜集和传输,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据搜集业务
RabbitMQ是基于AMQP协议实现的,这个协议主要特征是面向消息队列、路由(包括点对点和发布订阅)、可靠性、安全。用于在企业系统内对数据一致性,稳定性和可靠性要求很高的场景,对性能和吞吐量的要求在其次。
3、RabbitMQ的优缺点
优点
开源、性能优秀,稳定性保障
提供可靠性消息投递模式、返回模式
拥有持久化的机制,进程消息,队列中的信息也可以保存下来
对于高并发场景下,利用消息队列可以使得同步访问变为串行访问达到一定量的限流,利于数据库的操作。
缺点
系统可用性降低:系统引入的外部依赖增多,系统的稳定性就会变差。一旦MQ宕机,就会对业务产生影响。
消息一致性问题:A系统处理完业务,通过MQ发送消息给B、C系统进行后续的业务处理。如果B系统成功,C系统失败,这就需要考虑消息的一致性。
4、Rabbitmq普通模式与镜像模式的区别
RabbitMQ的普通模式和镜像模式的主要区别在于数据的复制和高可用性。
在普通模式下,队列中的消息只会存在于单个节点上,如果这个节点出现故障,那么队列中的消息将会丢失。而在镜像模式下,队列中的消息会被复制到所有的节点上,这样即使某个节点出现故障,其他节点也可以继续处理队列中的消息。
普通模式和镜像模式的性能和资源占用也有所不同。镜像模式会消耗更多的网络带宽和存储空间,因为数据需要在节点之间同步复制。而普通模式则不需要进行数据同步,因此在性能和资源占用方面相对更轻量级。
总的来说,如果你的应用对消息的可靠性要求比较高,那么镜像模式是一个不错的选择。但如果你的应用对消息的可靠性要求不是特别高,或者希望更加轻量级一些,那么普通模式可能更适合你的需求。
ELK相关
1、ELK的工作流程是什么?
logstash安装在需要搜集日志的主机上,负责搜集日志,并发送给es集群(配置文件中input配置日志搜集的位置,filter过滤作用,output配置输出es集群的ip地址),es集群负责存储日志数据,kibana提供可视化日志分析界面
elasticsearch提供搜集、分析、存储数据三大功能。他的特点有:分布式、零配置、自动发现、索引自动切片,索引副本机制、使用java开发的,依赖于openjdk1.8
2、ELK的优点
1. 强大的搜索功能,elasticsearch可以以分布式搜索的方式快速检索,而且支持DSL的语法来进行搜索,简单的说,就是通过类似配置的语言,快速筛选数据。
2. 完美的展示功能,可以展示非常详细的图表信息,而且可以定制展示内容,将数据可视化发挥的淋漓尽致。
3. 分布式功能,能够解决大型集群运维工作很多问题,包括监控、预警、日志收集解析等。
3、ES常用的插件
head 插件:
它展现ES集群的拓扑结构,并且可以通过它来进行索引(Index)和节点(Node)级别的操作
它提供一组针对集群的查询API,并将结果以json和表格形式返回
它提供一些快捷菜单,用以展现集群的各种状态
4、logstash的过滤功能用过吗?
logstash过滤功能用过,实用filter模块过滤日志或者数据,但是我们用的是filebeat实现过滤功能的,直接在采集的时候过滤不需要的内容。filebeat将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户
5、收集过什么数据,怎么过滤的
数据没有搜集过,只搜集过日志信息,用来给开发优化代码。比如nginx的访问日志,其他服务的错误日志,主要搜集error和warn信息。通过filebeat的处理器进行过滤。
6、logstash常用插件模块
- input Logstash的数据来源,可以是文件、Kafka、RabbitMQ、socket等等。
- filter 从input接收到的数据经过filter进行数据类型转换、字段增减和修改、以及一些逻辑处理。虽然 filter模块是非必选的部分,但由于其可以将收集的日志格式化,合理的字段类型定义和辅助字段的创建可以使得以后的查询统计更加容易和高效。所以filter模块的配置是整个Logstash配置文件最重要的地方。
- output 将filter得到的结果输出,可以是文件,Elasticsearch,Kafka等等
Docker相关
Docker的优点和缺点
优点:
提高服务器资源利用率、快速搭建新技术环境,不用学习复杂的部署环境、完美构建微服务部署环境、一次构建多次部署、快速部署、迁移、回滚、不依赖底层环境
相对于传统虚拟机,占用资源更少、启动更快、可移植性强,一次交付多次使用
缺点:
Docker的容器共享宿主机的资源,如果容器使用了大量的资源,可能会影响宿主机的性能。
单纯用docker的话,网络是个问题,容器之间不能通信,排查问题比较麻烦
Dockerfile你写过哪些?详细说说常用指令?
Dockerfile我写过Nginx镜像,Redis镜像,Jenkins镜像,
例如写Nginx镜像,
1、先创建一个Dockerfile文件写入内容
2、FROM 基于哪个镜像,RUN yum wget等常用服务,然后wget获取jdk tomcat 和Jenkins包,ADD解压jdk和tomcat,把tomcat的默认发布目录的默认删除,然后COPY jenkins的war包到tomcat的默认发布目录下,ENV设定环境变量,然后EXPOSE暴露端口,ENTRYPOINT 指定要运行的命令
3、Docker build 构建镜像即可
常用指令
FROM 指定基础镜像
RUN 运行命令
ENV 设定环境变量
COPY 文件拷贝
ADD 添加文件到容器,压缩包能自动解压
WORKDIR 指定工作目录
EXPOSE 暴露端口
CMD 指定要运行的命令
注意:通过Dockerfile构建镜像的时候尽量把命令写到一行,因为Dockerfile创建镜像是一层一层创建的,如果命令行太多,会导致镜像比较大,写在一行的话,能够减小镜像的大小
Docker的网络模式
Docker默认三种网络类型,bridege、host、none
bridge:网络桥接 默认情况下启动,创建都是用该模式,
none:无指定网络 启动容器时,可以通过 --network=none,Docker容器不会分配局域网ip
host: 主机网络 Docker容器和宿主机共用一个ip地址
然后可以使用Docker network create 创建新的网络类型
为什么要对容器进行资源限制?
在Docker中每个容器都共享宿主机的资源,如果容器没有受到限制,可能会消耗大量的资源,导致其他容器无法运行,因此限制资源是非常有必要的,
限制容器的资源使用,可以避免容器过度消耗系统资源,提高容器的运行效率,可以避免容器之间的资源竞争,保证容器的正常运行,可以保证宿主机的稳定性,避免宿主机因为容器的过度消耗资源导致宕机。
你都对什么容器,做过什么限制?
对Tomcat容器做过内存限制,防止Tomcat发生内存溢出
docker run --itd -m 指定可以使用的内存
还可以对CPU进行限制
docker run --itd -c 指定cpu share 一般默认是1024 最大也是1024 按比例占用内存
docker run --itd --cpus 指定容器可以使用的cpu核数 0.1~宿主机的核数
docker run --itd --cpuset-cpu=0,3 指定编号0和3的cpu供容器使用
k8s相关
k8s的组件有哪些?都分别什么作用?
master节点上的组件:
apiserver:k8s系统的入口,封装了核心对象的增删改查功能。收集pod的信息,保存到etcd
scheduler:负责pod的节点选择,负责集群的资源调度,组件抽离
controller:执行各种控制器,目前提供了很多种调度器保证k8s集群的正常运行
node节点上的组件:
kubelet:负责管控容器,kubelet会从k8sapiserver接受pod的创建请求,启动和停止容器,监控容器的状态并汇报给k8sapiserver
k8s-proxy:负责为pod创建代理服务。k8s-proxy会从apiserver获取所有的service信息,并根据service的信息创建代理服务,实现service到pod的请求路由和转发,从而实现k8s层级的虚拟转发网络
docker engine:docker引擎,负责本机的容器创建和管理工作以及镜像的拉取。
Container Runtime:负责管理容器的运行,如Docker、containerd等。
flannel网络插件:
etcd可以部署在master也可以单独部署,分布式键值存储系统,用于保存集群状态数据,比如pod、service、等对象信息。
二进制部署k8s集群和Kubeadm方式部署 有什么区别?
1、部署方式不同:二进制部署需要手动下载、编译、和部署k8s的各个组件,而kubeadm方式部署k8s集群则可以通过简单的命令行操作来完成整个部署过程
2、部署难度不同:二进制部署k8s集群需要对k8s的各个组件有深入的了解,而且需要进行复杂的配置和调整,而kubeadm方式部署k8s集群则可以减少很多配置和调整工作,部署难度相对较低。
3、部署灵活性不同:二进制部署k8s集群可以自由选择和配置k8s的各个组件,而kubeadm方式部署k8s集群则需要有一些固定的配置选项和流程,灵活性相对较低。
4、部署速度不同:kubeadm方式部署k8s集群的速度相对较快,只需要很快就可以完成整个部署过程,而二进制部署k8s集群则需要更长时间
Deployment和Rc的区别是什么?
Deployment是一种新型的容器编排方式,可以指定集群中存在指定数量的pod,能够实现弹性伸缩、动态扩容、还能对副本进行热升级,即在更新过程中,新的pod后旧的pod同时运行,从而避免了服务中断的风险,当新的pod运行成功后旧的会关闭,从而实现热升级,
RC也能容器编排,可以指定集群中存在指定数量的pod,能够实现弹性伸缩、动态扩容,但是RC不能够实现热升级更新,如果要更新先要把运行的pod删除,重新apply,所以更新的时候服务会中断。
如何暴露pod,举个例子说一下?
有四种方式:
1、Cluster IP :这是k8s service的默认方式,会提供一个集群内部的虚拟ip,以供集群内pod之间的通信使用
2、NodePort:外部访问 nodeip+nodeport 转到podip+podport,实现访问
我们一般使用资源对象Service结合nodeport来暴露,我们需要编写yml文件,指定资源对象为service,要给secvice打标签,然后定义为nodeport类型,然后指定nodeport,port、targetport,nodeport是k8s提供给集群外部客户访问service入口的一种方式,port是service 暴露在cluster ip 上的端口,提供给集群内部访问service的入口,targetport就是pod上的端口,总的来说就是集群外的访问由nodeport转到port在转到targetport,能够从外部访问容器,使用nodeip+nodeport就能实现外部访问
3、loadbalance:LoadBalancer在NodePort基础上,K8S可以请求底层云平台创建一个负载均衡器,将每个Node作为后端,进行服务分发
4、Ingress是一种HTTP方式的路由转发机制,为K8S服务配置HTTP负载均衡器,通常会将服务暴露给K8S群集外的客户端。
k8s网络插件calico和flanneld的区别是什么?
实现方式:
Calico使用的是基于路由的方法实现网络功能,每个容器都有一个唯一的ip,Flannel使用虚拟网络(overlay network)来实现网络功能,每个节点上都有一个Flannel agent,他负责创建一个虚拟网络,将每个容器的ip映射到虚拟网络中的唯一一个的地址。
配置和部署:
Calico 的配置和部署相对来说比较复杂,因为它需要为每个节点设置路由规则。 Flannel 的配置和部署相对来说比较简单,因为它不需要为每个节点设置路由规则,而是使用 overlay 网络。在 K8s 集群中,只需在每个节点上安装 Flannel agent,然后使用 ConfigMap 或命令行参数配置即可。
功能:
相对于Flannel,Calico以其性能、灵活性而闻名,功能更为全面,不仅提供主机和 Pod 之间的网络连接,还涉及网络安全和管理。Calico CNI 插件在 CNI 框架内封装了 Calico 的功能。
除了性能优势之外,在出现网络问题时,用户还可以用更常规的方法进行故障排除。 虽然使用VXLAN等技术进行封装也是一个不错的解决方案,但该过程处理数据包的方式同场难以追踪。 使用Calico,标准调试工具可以访问与简单环境中相同的信息,从而使更多开发人员和管理员更容易理解行为。
kubectl apply 和kubectl create的区别?
- 命令声明式和命令式:kubectl apply属于声明式命令,只需要声明一个YAML文件,然后由Kubernetes根据该文件自动探测要执行的操作。相对而言,kubectl create属于命令式命令,需要明确告诉Kubernetes要创建的资源或对象类型。
- 资源创建和更新:当使用kubectl create命令时,如果集群中已存在与所指定资源名称相同的资源,那么该命令将会删除旧资源,然后根据新的YAML文件重新创建一个新的资源对象。而kubectl apply命令并不会删除旧资源,它只会对比YAML文件与当前资源状态之间的差异,并进行必要的更新。
说一下你对资源对象Secret的理解
secret是用来保存小片敏感数据的k8s资源对象,例如密码,密钥。放在secret中更方便的控制如何使用数据,减少暴露的风险,更好的保护数据安全。
secret有两种方式创建,使用命令方式kubectl create secret,使用yaml文件创建。当pod引用Secret中的数据时,会自动解码,解码方式是base64。
Pod容器有两种引用secret的方式,一种是以卷挂载的方式引用,一种是以环境变量的方式引用,在卷挂载的方式时,如果secret中的数据进行修改,那么pod容器就会自动更新数据,但是必须是yml文件创建的secret,在环境变量的方式时,secret中的数据进行更新时,pod容器不会进行热更新。
说一下你对资源对象configmap的理解
ConfigMap是Kubernetes中的一种资源对象,用于存储非机密性的配置数据,例如环境变量、命令行参数、配置文件等。
在使用ConfigMap时,可以通过两种方式将配置数据注入到Pod中:环境变量和卷挂载。通过环境变量注入的配置数据需要在Pod的spec.containers.env字段中定义,而通过卷挂载注入的配置数据需要在Pod的spec.volumes字段中定义。
ConfigMap有四种创建方式,可以直接采用命令行的方式,也可以通过指定文件和目录的方式,也可以利用yaml文件进行创建,在使用卷挂载的引用方式时,可以支持热更新,但是前提是不能使用subPath参数,ConfigMap资源对象必须是以yaml方式创建的。在使用环境变量的方式进行引用时,不支持热更新。
Secret和configmap的区别?
Secret资源对象可以保存轻量的敏感信息,如数据库的用户名和密码、认证秘钥等。为了保护这些敏感信息,Secret在保存数据时使用了加密的方式,而不是明文方式。
与Secret不同,ConfigMap资源对象主要用于保存一些不太重要的数据,如配置文件、日志参数等。这些数据虽然不涉及敏感信息,但仍然需要被其他资源对象使用,因此ConfigMap以明文方式存储数据。
Serviceaccount有什么作用?如何使用
ServiceAccount是用于与API服务器进行身份验证和授权的实体,为Pod或其他资源提供身份验证和授权,以便它们能够与Kubernetes API进行交互
ServiceAccount通常被用于Pod的提权,每个Pod都会自动分配一个默认的ServiceAccount,可以通过在Pod配置中指定不同的ServiceAccount来为不同的Pod分配不同的权限
如何给pod进行提权操作?
ServiceAccount:给pod进行提权的(每个pod基本)用clusterrolebangding来绑定clusterrole。创建pod的时候引用对应的sa达到提权的目的。
Service有几种类型,有什么区别?
分别是ClusterIP(常用+默认),NodePort(常用),LoadBalancer以及ExternalName
ClusterIP:K8S会在Service创建完毕后提供一个内部IP作为ClusterIP,K8S内部服务可以通过ClusterIP或者ServiceName来访问该服务。用ServiceName访问起作用的是coredns
NodePort:在ClusterIP的基础之上,为集群内的每台物理机绑定一个端口,外网通过任意节点的物理机IP:端口来访问服务。应用方式:外服访问服务
LoadBalancer:在NodePort基础之上,提供外部负载均衡器与外网统一IP,此IP可以将请求转发到对应服务上。这个是各个云厂商提供的服务。应用方式:外服访问服务
ExternalName:引入集群外部的服务,可以在集群内部通过别名方式访问
k8s的pod如何做资源限制
可以通过在Pod的yaml文件中设置resources字段来对Pod进行资源限制。可以设置Pod的内存的大小,以及CPU的数量和大小。利用Requests和Limits进行限制。
requests 是创建容器时需要预留的资源量。如果无法满足,则pod 无法调度。但是,这不是容器运行实际使用的资源,容器实际运行使用的资源可能比这个大,也可能比这个小。
Limit 是限制pod容器可以使用资源的上限。容器使用的资源无法高于这个限制任何情况下Limits都应该设置为大于或等于Requests。
k8s的pod镜像使用策略有几种?什么区别
IfNotPresent:在镜像已经存在的情况下,kubelet将不再去拉取镜像,仅当本地缺失时才会从仓库中拉取,默认的镜像拉取策略。
Alaways:每次创建Pod都会重新拉取一次镜像
Never:Pod不会主动拉取这个镜像,仅使用本地镜像。
注意:对于标签为latest的镜像文件,其默认的镜像获取策略即为Always;而对于其他标签的镜像,其默认策略则为IfNotPresent。
k8s的存储了解吗?说一下你对k8s存储的了解都能用什么
EmptyDir:这是一种临时性的存储,它会在Pod被删除时一并删除。
HostPath:这种存储将主机上的文件或目录挂载到Pod中,但是它不具备可移植性,因为Pod可能会被调度到其他节点上。
NFS:这是一种网络存储,可以在多个Pod之间共享。
PersistentVolume(PV)和PersistentVolumeClaim(PVC):PV是一种集群级别的存储资源,而PVC是对PV的请求使用。PVC可以指定所需的存储大小和访问模式(例如 ReadWriteOnce、ReadOnlyMany等),而PV则可以指定实际的存储位置和类型(例如NFS、iSCSI等)。
K8s静态存储和动态存储有什么区别?如何使用动态存储
静态存储是指在K8s集群中手动地配置和管理存储卷。这意味着管理员需要提前创建和配置存储卷,并且将其手动绑定到Pod中的容器。
动态存储是可以自动化管理存储卷的创建和绑定过程。管理员只需要定义存储类(StorageClass),然后在创建Pod时使用该存储类进行声明。K8s集群会自动根据存储类的定义,动态创建并绑定一个存储卷到Pod中。当我们创建Pod的时候就会自动创建PVC和PV了。
使用方法:
我们需要先部署NFS,创建一个共享目录。
创建存储类,比如说(Storage calss)
然后我们需要部署一个能够自动创建PV的Pod,在这个Pod中需要声明使用存储类,并且要定义一个共享目录,但是前提是我们需要对这个Pod进行提权。
完成之后,我们需要编写Yaml文件进行Pod的创建,在这个文件中声明存储类,当创建Pod时,Kubernetes会根据存储类的定义,动态创建并绑定一个存储卷到Pod中。
平常遇到的问题
Tomcat假死
有一次做活动的时候,tomcat服务器假死,导致用户打不开页面(问题分析,有可能是做活动,服务器的访问量上来了,导致数据库扛不住,但是zabbix监控现实mysql的状态正常,可能跟tomcat本身有关,查看tomcat的监听端口发现,有大量的tcp连接等待关闭,手动关闭就行了)
解决方法:修改linux的tcp超时时间/etc/sysctl.conf,重启network生效
Keepalived ip不漂移
测试环境中:keepalived高可用的时候,发现vip不漂移。仔细检查发现从节点的keepalived配置文件中优先级设置的不合理,没有设置不抢占资源,修改之后发现可以实现漂移,但是在杀死mysql进程的时候还是不漂移,仔细检查后发现健康检测脚本中,root用户不支持远程登录,换成普通用户即可。
服务器比较卡
某天突然收到报警信息,cpu使用率和cpu负载一直很高,我就用top命令看了一下,发现是mysql占用cpu的使用率很高,就对数据库的状态进行排查,先看了一下mysql的连接数,发现并不高,然后就show processlist查看了一下mysql哪些线程在运行,发现有几条sql语句一直在执行,陷入了循环,我就把这几条sql语句截图发到开发工作群,问一下这个sql语句是干啥的,能不能停掉,不然cpu负载一直这么高要是宕机了就麻烦了,开发说可以先停掉,我就kill id号,将这几个线程杀死。
MySQL版本不一致导致主从不同步
当时也没发现是版本不一致导致的,因为mysql8.0不能直接使用grant这个命令生成用户并授权,只能先创建用户在授权,然后把这个语句在从库上执行了一下,发现不能执行,想了好一会想到会不会是版本不一致导致的,就看一了下版本,发现是8.0版本。
解决方案:
1、stop slave
2、set global sql_slave_skip_counter=1 跳过这个事务
3、start slave
4、show slave status \G 查看异常是否解决,发现解决了,但是用户授权未成功,所以需要手动执行一下
5、因为从库设置了只读,需要先关闭一下set global read_only=0
6、create user 'query_data_analysis'@'%' identified by 'Han2rZY7uEn9m!Asana';
7、GRANT all privileges on data_analysis.* to query_data_analysis@'%';
8、把从库重新设为只读set global read_only=1
二、缓存雪崩及解决办法
缓存在同一时间大面积失效,从而导致所有的请求都去查数据库,导致数据库和CPU负载过高,甚至宕机
解决方法:缓存高可用,缓存层设计高可用,防止缓存大面积故障,即使一个宕机掉依然可以提供服务,redis数据备份
三、缓存穿透
缓存穿透是指查询一个不存在的数据,缓存中没有,需要去数据库中查询,然后大量的请求会到达数据库,从而压垮数据库
解决方法:如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库。设置一个过期时间或者当有值的时候将缓存中的值替换掉即可。
有一次我收到报警消息,cpu使用率过高,我使用top命令查看到一个java程序占用了40多的cpu,然后iowait的使用率也很高,使用iostat查看整体I/O情况,然后我就使用pidstat查看是元凶是哪个进程,找到他的pid,然后赶快去询问开发人员,这个进程能不能停掉,然后我使用strace来查看这个进程到底在干什么,发现它一直在写一个文件,这也就是我们高io的原因,然后我使用lsof查看它在写那个文件,然后开发说可以停掉,我就把这个进程停掉了,也把它产生的文件删除了。
磁盘空间不足报警,找到一些大文件,无用的话就删除
内存使用率过高,例如Nginx,Nginx超过200就报警,
监控web场景,比如说下载速度,Nginx的连接数
清除内存,我们使用free -m 查看内存使用情况,发现cache有点多,然后使用sync 把buff中的数据先写入到磁盘,然后echo 3 > /proc/sys/vm/drop_caches,然后就清除了一些缓存
公有云和私有云的区别
私有云和公有云的显著区别在于对数据的掌控。采用公有云的企业必须将数据托管与云服务商的数据中心,企业对数据的掌控力度自然减弱,一旦数据中心因为自然灾害人为因素或者法律规范等问题导致数据丢失,将对企业造成致命伤害。私有云在数据安全、数据备份等方面有更多的选择空间,公有云当然也具备数据安全服务和数据备份的能力,但企业对数据的控制力度差,不能处于主导地位。
Jenkins流水线部署k8s

编写Dockerfile
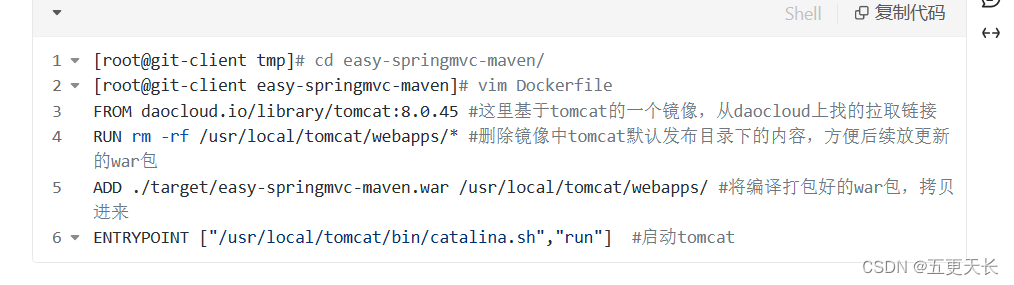
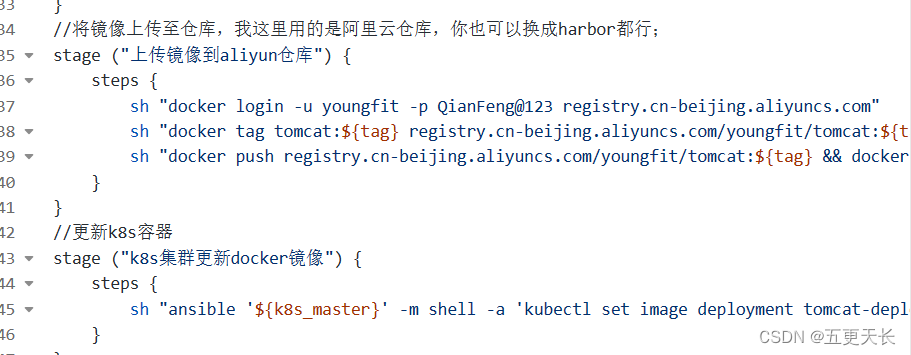
编写流水线代码

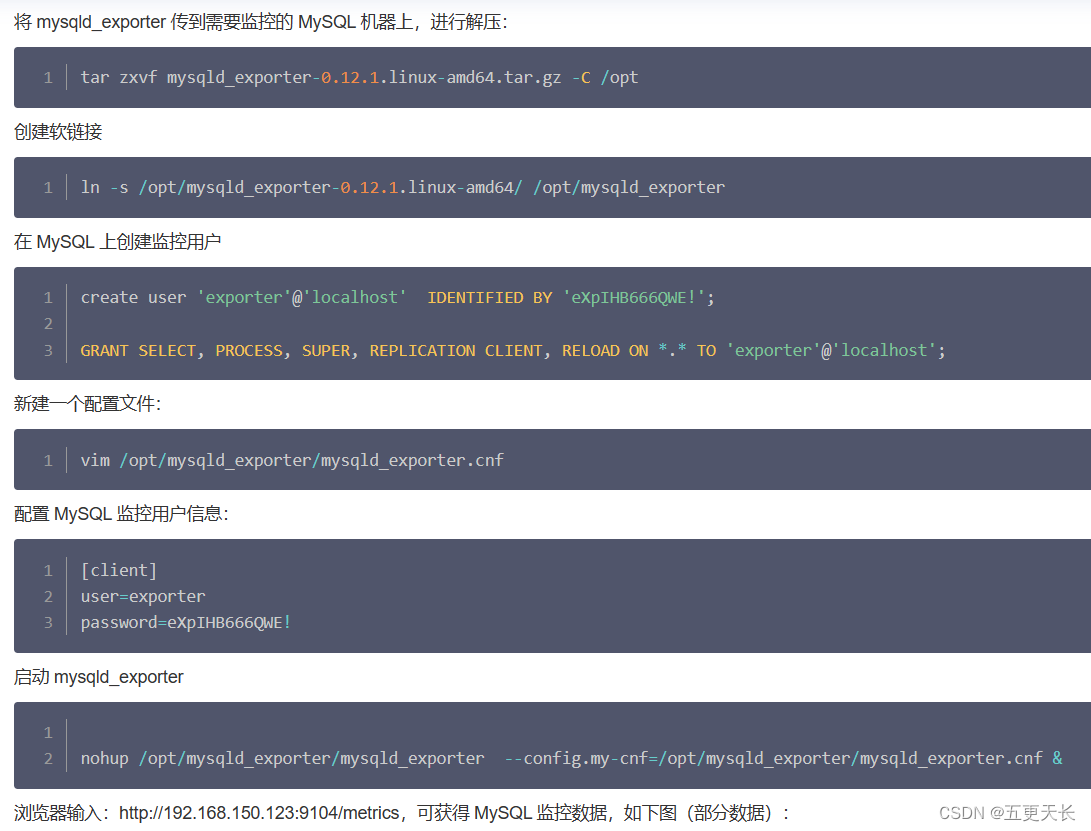
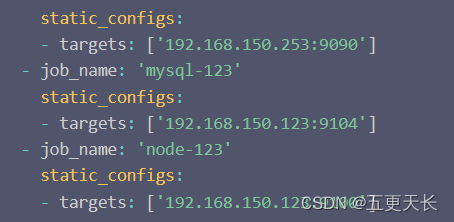
普罗米修斯监控MySQL

数据库备份脚本



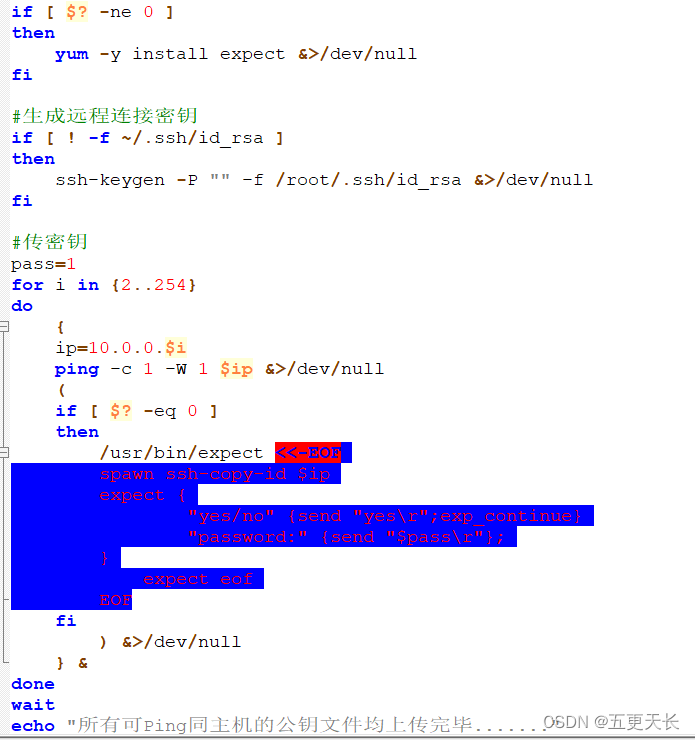
批量上传密钥
1.ubantu与centos的区别
1.ubantu主要面向个人用户和开发者,centos主要面向企业用户和系统管理员
2.用户界面:ubantu采用了unity 桌面环境,界面简单、易于使用。centos采用gnome桌面环境,界面较为传统,但是功能强大
3.软件包管理:ubantu采用了APT软件包管理器,可以方便安装和更新软件。centos采用yum软件包管理器,也可以方便的安装和更新软件
4.安装命令:在安装软件方面,ubantu使用的是apt-get,而centos使用的是yum
2.centos7与centos6的区别
1.二者的内核版本不一致
2.软件包管理器:7版本采用yum4,6版本采用yum3,yum4提供了更快的软件包安装和更新速度
3.网络管理:CentOS 7引入了新的NetworkManager工具,可以方便地管理网络连接。CentOS 6使用了旧的网络管理工具,需要手动配置网络连接。
4.7新增了主机名管理工具hostnamectl
5.安全性:CentOS 7引入了新的SELinux安全机制,可以更好地保护系统安全。CentOS 6使用了旧的Security-Enhanced Linux(SELinux)安全机制,但配置较为复杂。
3.软连接与硬链接的区别
1.软连接创建时,会创建一个新的文件,这个文件可以是一个符号链接,也可以是一个特殊的文件。而硬链接的创建则是通过在文件系统中创建一个新的文件,这个新的文件与原始文件具有相同的 inode 信息,因此它们都指向同一个物理位置。删除原始文件,硬链接不会受到影响,只有当所有硬链接都被删除时,才会删除原始文件的内容。
2.文件类型:软连接可以指向任何类型的文件,包括普通文件、目录、符号链接等。硬链接只能指向普通文件,不能指向目录或符号链接。
3.删除文件:如果删除了被软连接指向的文件,软连接将变成无效的。如果删除了被硬链接指向的文件,硬链接仍然有效,但被指向的文件将不可访问。
4.文件数量:对于同一个文件,可以创建多个软连接,但只能创建一个硬链接。
5.使用限制:软连接可以跨越不同的文件系统,因为它们只是指向另一个文件的路径。而硬链接只能在同一文件系统中创建,因为它们需要指向相同的数据块。
6.创建方式:软连接可以使用 ln -s 命令创建,而硬链接可以使用 ln 命令创建。
4.磁盘列阵
RAID ( Redundant Array of Independent Disks )即独立磁盘冗余阵列,通常简称为磁盘阵列。简单地说, RAID 是由多个独立的高性能磁盘驱动器组成的磁盘子系统,从而提供比单个磁盘更高的存储性能和数据冗余的技术。
最常用的raid级别:0、1、5、6、10:是 1和0 的组合
raid0
最少需要两块磁盘,分别往每一块磁盘上写一部分数据
优点:
1.读写速度快,
2.磁盘利用率:100%
缺点:不提供数据冗余,无数据检验,不能保证数据的正确性,存在单点故障。
应用场景:
1)对数据完整性要求不高的场景,如:日志存储,个人娱乐
2)要求读写效率高,安全性能要求不高,如图像工作站
raid1
一般需要两块磁盘,每块磁盘上都会存储一份完整数据。其数据安全性就会较高,但是磁盘空间利用率是比较低的。
优点:提供数据冗余,数据双倍存储安全性高支持容错。读速度快
缺点:写速度慢,无数据校验。磁盘利用率不高
磁盘利用率:50%
应用场景:
存放重要数据,如数据存储领域
raid5
RAID5应该是目前最常见的 RAID 等级,它的校验数据分布在阵列中的所有磁盘上。RAID5的磁盘上同时存储数据和校验数据。当一个数据盘损坏时,系统可以根据其他数据块和对应的校验数据来重建损坏的数据。
raid5最少需要3块磁盘。
优点:
1.可以找回丢失的数据---数据可以通过校验计算得出,
2.冗余磁盘-->(需要4快磁盘将其中一块做热备)当某一块磁盘坏掉后,冗余磁盘会自动替换上去
3.有校验机制
4.读写速度高
5.磁盘利用率高
缺点:
1.磁盘越多安全性能越差
应用场景:安全性高,如金融、数据库、存储等。
raid6
最少需要四块磁盘,两块存校验位。RAID6引入双重校验的概念,它可以保护阵列中同时出现两个磁盘失效时,阵列仍能够继续工作,不会发生数据丢失。。
优点:
1.容错:允许两块磁盘同时坏掉。读写快。
2.良好的随机读性能
3.有校验机制
缺点:
1.写入速度差
2.成本高
应用场景:对数据安全级别要求比较高的企业
raid10
优点:
1.较高的IO性能
2.有数据冗余
3.无单点故障
4.安全性能高
缺点:成本稍高
应用场景:
特别适用于既有大量数据需要存取,同时又对数据安全性要求严格的领域,如银行、金融、商业超市、仓储库房、各种档案管理等。
5.nfs与vsftp的区别
NFS(Network File System)和VSFTP(Very Secure FTP)是两种不同的文件共享和传输协议,它们之间有以下区别:
-
功能:NFS是一种文件共享协议,可以让多台计算机共享同一个文件系统,实现文件的共享和访问。VSFTP是一种文件传输协议,可以让用户在客户端和服务器之间进行文件的上传和下载。
-
协议类型:NFS使用的是TCP/IP协议,而VSFTP使用的是FTP协议。
-
安全性:NFS采用了安全的加密传输方式,可以保护文件的安全性和隐私性。VSFTP也支持安全传输,但是需要用户自行配置安全选项,安全性相对较低。
-
文件传输速度:NFS的文件传输速度较快,因为它采用了本地文件系统的方式进行文件访问,而VSFTP的文件传输速度较慢,因为它需要进行网络传输和协议交互。
-
使用场景:NFS适用于需要共享文件的场景,例如文件服务器、分布式计算等。VSFTP适用于需要进行文件传输的场景,例如网站文件上传、文件共享等。
6.查看文件内容的方式
1.cat--查看一个文件的全部内容 -n 显示行号,-A显示控制字符
2.head查看头部, 默认查看前十行,加-2 查看前两行
3.tail查看尾部,默认查看后十行,-1查看最后一行,-f动态查看后十行
4.grep过滤关键字,grep针对文件内容进行过滤
5.less分页显示
6.more分页显示文件内容
7.设置特殊权限
chmod u+s file 命令提权
chmod g+s dir 组继承 创建的文件组一样
chmod o+t dir 权限控制 只能是属主才能修改文件
取消提权 u-s
8.chattr文件属性
chattr +a file1 #不允许修改,只允许追加
chattr +i file2 #不允许做任何操作
i:即Immutable,系统不允许对这个文件进行任何的修改
a:即Append Only,系统只允许在这个文件之后追加数据,不允许任何覆盖或截断这个文件
9.进程命令
查看进程
ps aux | less ps aux
ps -ef ps -ef | grep httpd
动态查看进程 :top #动态显示信息,三秒刷新一次。也可看平均负载
查看指定pid :ps aux | grep sshd
查看端口
lsof -i:80 #端口号,这能查看带端口的进程
netstat -lntp 查网络进程和正在监听的端口
查看后台进程:jobs
查看当前cpu负载 :uptime top
查看内存使用情况 :free -m
查看系统版本 :cat /etc/redhat-release
查看内核 :uname -r
10.远程管理服务ssh与telnet的区别
-
安全性:SSH是一种加密的远程管理协议,可以保护用户的登录信息和传输的数据安全。Telnet是一种不加密的远程管理协议,用户的登录信息和传输的数据都是明文传输,容易被窃取和篡改。
- 端口号:SSH使用的默认端口号是22,而Telnet使用的默认端口号是23。
- telnet不能压缩传输数据,所以传输慢。ssh传输数据经过压缩,所以传输速度比较快
11.grep awk sed 的区别与各自的特点
grep主要用于搜索某些字符串,sed,awk 用于处理文本
-
grep:grep是一种文本搜索工具,可以在文本文件中搜索指定的字符串,并输出匹配的行。grep支持正则表达式,可以搜索文本文件中的单个字符、字符串、行等。grep的特点是简单、快速、可扩展性强。
-
awk:awk是一种文本处理工具,可以对文本文件进行格式化输出、统计分析等操作。awk支持模式匹配,可以搜索文本文件中的单个字符、字符串、行等。awk的特点是功能强大、灵活、可扩展性强。
-
sed:sed是一种文本处理工具,可以对文本文件进行编辑、替换、删除等操作。sed支持模式匹配,可以搜索文本文件中的单个字符、字符串、行等。sed的特点是功能强大、灵活、可扩展性强。正在处理的内容存放在模式空间(缓冲区)内,处理完成后按照选项的规定进行输出或文件的修改
http常用状态码
常见的 HTTP 状态码:
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 403 - 服务器理解请求客户端的请求,但是拒绝执行此请求
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
- 502 - 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应
- 503 - 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中
如何配置ssl证书,说下流程
第一步下载证书到本地电脑中
在阿里云控制台中的SSL操作界面中找到刚申请成功的免费SSL证书,点击右侧的下载链接,弹出下载页面,然后点击Nginx右侧的下载按钮,下载证书文件。
下载完是一个zip压缩包文件,需要进行解压,解压下来是两个文件:
以.key为后缀的文件是密钥文件
以.pem为后缀的文件是证书文件
第二步上传到服务器中的特定文件夹目录下
将第1步中的证书文件(.pem结尾)和密钥文件(.key)文件上传到Nginx服务器中,这两个文件具体的放置路径是在Nginx安装目录下的conf/cert文件夹中。
第三步配置nginx.conf,使证书生效
修改nginx的配置文件/usr/local/nginx/conf/nginx.conf,修改之前最好通过复制命令将该配置文件备份一份,在配置文件里添加一些配置即可,完成后重新启动即可
四七层负载均衡的区别?
四层负载均衡工作在OSI模型的传输层,由于在传输层,只有TCP/UDP协议,这两种协议中除了包含源IP、目标IP以外,还包含端口号以及目的端口号。四层均衡负载服务器在接受到客户端请求后,以后通过修改数据包的地址信息(IP+端口号)将流量转发到应用服务器。
七层负载均衡工作在OSI模型的应用层,应用层协议比较多,常用的有http等,七层负载就可以基于这些协议来负载,这些应用层协议中会包含很多有意义的内容,比如同一个web服务器的负载均衡,除了根据IP+端口进行负载外,还可以根据七层的URL、浏览器类别、语言来决定是否要进行负载
nginx-http请求方法
HTTP1.0定义了3种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了5种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
重点方法:
GET:单纯获取数据(获取一个index.html页面)
POST:上传/创建文件(会产生新的数据)
PUT:保存数据(覆盖/更新文件、图片等,不会产生新的数据)
DELETE:删除
什么是虚拟主机
虚拟主机,就是把一台物理服务器划分成多个虚拟的服务器,这样我们的一台物理服务器就可以做多个服务器来使用,从而可以配置多个网站。nginx提供虚拟主机的功能,就是为了让我们不需要安装多个nginx,就可以运行多个域名不同的网站。
配置虚拟主机的方式:基于域名的虚拟主机,基于ip的虚拟主机,基于端口的虚拟主机
传输层有几种协议?什么区别?
1.TCP协议
TCP是一种面向连接的协议,它在传输数据之前会建立一条专用的通信连接。这意味着在数据传输过程中,两台计算机之间会有一条稳定的数据传输通道。因此,TCP可以保证数据传输的可靠性,但会带来一定的延迟。
面向连接,速度慢,可靠传输
2.UDP协议
UDP是一种无连接的协议,它不会建立专用的通信连接。每个数据包都是独立的,可以直接传输。因此,UDP的传输速度比TCP快,但不能保证数据传输的可靠性。
3.区别
连接
- TCP 是面向连接的传输层协议,传输数据前先要建立连接。
- UDP 是不需要连接,即刻传输数据。
服务对象
- TCP 是一对一的两点服务,即一条连接只有两个端点。
- UDP 支持一对一、一对多、多对多的交互通信
可靠性
- TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按需到达。
- UDP 是尽最大努力交付,不保证可靠交付数据。
传输方式
- TCP 是流式传输,没有边界,但保证顺序和可靠。
- UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序
cat /etc/passwd |awk -F ':' '/root/ {print $7}' # 其实也非常的简单,将要匹配的正则表达式使用两个斜杠包裹起来就行了,这里匹配含有root字符的记录
awk 统计nginx访问最多的ip
awk '{print $1}’/usr/local/nginx/logs/domain.access.log|sort |uniq �c|head -n10
查看2009年6月21日14时这一个小时内有多少IP访问:
awk '{print $4,$1}' log_file | grep 21/Jun/2009:14 | awk '{print $2}'| sort | uniq | wc -l
awk取第二行第一列
awk -F: 'NR==2{print $1}' /etc/passwd过滤日志中的ERROR字段
find /var/log/ -type f -name "*.log" | xargs grep "ERROR"
过滤ip
ifconfig | egrep "inet\>" | tr -s " " | cut -d" " -f3
过滤文本中的单词并统计数量
grep -o '\<[a-zA-Z]*[a-zA-Z]\>' /etc/passwd | sort | uniq -c | awk '{print $2,$1}' sort默认的排序方式是升序,如果想改成降序,就加个-r。
sed用法
把oo换成kk
sed -e 's/oo/kk/g' testfile















 5165
5165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









