






目录
1.2.1根据题目所给示例对各项指标值进行编码,给出具体编码要求如下:
前言
大二上第一次参加本次比赛原本抱着拿下A题直接下班,结果~这个A题解决的有点慢来不及了,所以只能开肝B题~也很幸运团队齐心协力拿下了一等奖

任务1 数据探索与清洗
任务1.1 数据探索与预处理
这是个比较简单的问题:数据预处理。简单的缺失值、重复值、异常值处理
1.1.1缺失值、重复值处理:
Data_short = pd.read_csv("short-customer-data.csv")
#丢弃缺失值 dropna()删除缺失值所在行(axis=0)或列(axis=1) 默认为 axis=0
Data_short = Data_short.dropna()
#去重
Data_short.drop_duplicates(subset=['user_id'],keep='first',inplace=True)
Data_short.to_excel("result1_1.xlsx",index=None)最终去除行数据12716条,删除重复行数据33条,最后剩下30445行数据
1.1.2异常值处理:
Data_long = Data_long[~Data_long['Age'].isin(['-1'])]
Data_long = Data_long[~Data_long['Age'].isin(['0'])]
Data_long = Data_long[~Data_long['Age'].isin(['-'])]
Data_long['Age'].replace('\s+','',regex=True,inplace=True)
Data_long['Age'].replace(regex=True,inplace=True,to_replace=r'岁',value=r'')
Data_long['Age'] = Data_long['Age'].astype(int)
Data_long.to_excel("result1_2.xlsx",index=None)
最终去除存在数值为-1、0 和“0”的异常值行数据最终剩下9198行数据
任务1.2 特征编码
1.2.1根据题目所给示例对各项指标值进行编码,给出具体编码要求如下:
| 指标 | 编码 |
| Unemoloyed Technician Admin Single Married Divorced Illiterate Junior college High school Undergraduate | 0 1 10 0 1 2 0 1 2 3 |
使用repalce()方法将原数据中的字符数据用以上编码进行替换
Data_short = pd.read_excel("result1_1.xlsx")
Data_short['job'].replace(regex=True,inplace=True,to_replace=r'unemployed',value=r'0')
Data_short['marital'].replace(regex=True,inplace=True,to_replace=r'single',value=r'0')
Data_short['default'].replace(regex=True,inplace=True,to_replace=r'no',value=r'0')
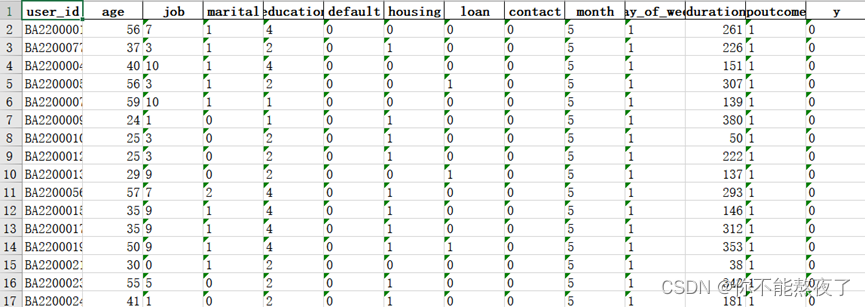
得到表的数据部分展示:
任务2 产品营销数据可视化分析
基本的绘图能力~在此省略咯
需要详细代码可以去我的Github上查看~
任务3 客户流失因素可视化分析
同样也是基本的绘图能力,也包含了一定的数据处理考验如任务3.4
需要详细代码可以去我的github上查看~
任务4 特征构建
对选手一定的数据处理能力要求
任务5 银行客户长期忠诚度预测建模
这是比较关键也是一个比较困难的任务,上面四项浪费的是时间,任务5需要振作数据分析的方法
选取相关特征(适当的构建)它说可以参照任务4,那咱就不搞复杂的参照任务4呗~给出选取依据!
我采用了随机森林分类模型来进行预测
1、对测试集进行按照任务3.4的模式对其进行对账号户龄(Tenure)和客户金融资产(Balance)进行划分,并分别进行特征编码作为新的客户特征,使用Python进行编码将其保存到“result_test.xlsx”中
2、再按照任务4的模式使用Python进行特征构建,得到新老客户活跃程度的特征、不同金融资产客户活跃程度的特征、不同金融资产信用卡持有状态的特征,将其存储到“result_test处理.xlsx”中
3、模型建立原理:一个样本容量为的样本,有放回的抽取次,每次抽取1个,最终形成了个样本。这选择好了的个样本用来训练一个决策树,作为决策树根节点处的样本。当每个样本有个属性时,在决策树的每个节点需要分裂时,随机从这个属性中选取出个属性,满足条件。然后从这个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。决策树形成过程中每个节点都要按照步骤2来分裂。
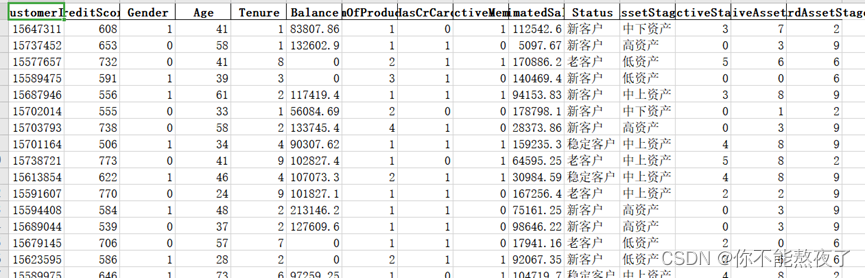
下面是预测结果
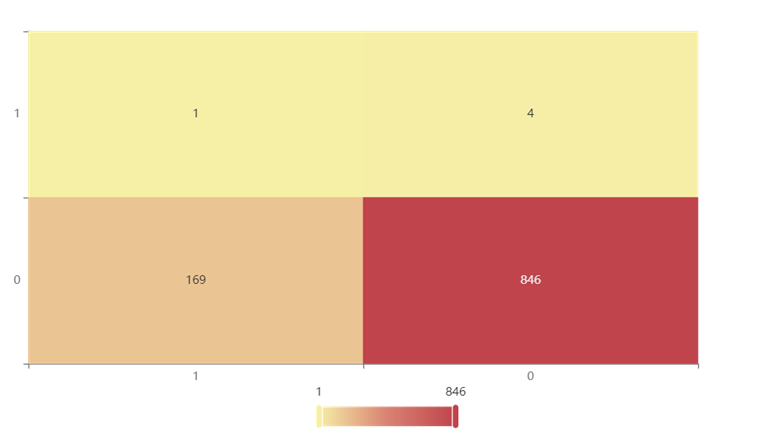
更关键是对模型的评估也是误差分析,可行性分析构建混淆矩阵
随机森林分类模型预测步骤:
1、对训练集“result4.xlsx”和测试集“result_test处理.xlsx”进行拼接保存得到“YC.xls”文件。
2、运用SPSSPRO的随机森林分类进行预测得到预测结果。
3、将预测结果进行整合,与“result_test处理.xlsx”联系保存放入“result5.xlsx”中。
测试数据预测评估部分结果如下所示:
| 预测结果Y | Exited | 预测结果概率_0.0 | 预测结果概率_1.0 | IsActiveStatus | IsActiveAssetStage | CrCardAssetStage | Age |
| 0 | 0 | 0.9106697025634223 | 0.0893302974365775 | 1 | 0 | 0 | 34 |
| 0 | 0 | 0.7328094813950821 | 0.2671905186049182 | 3 | 6 | 6 | 56 |
| 0 | 1 | 0.6243078246600751 | 0.37569217533992494 | 1 | 2 | 9 | 43 |
| 0 | 0 | 0.7850127338142185 | 0.21498726618578134 | 0 | 2 | 9 | 38 |
| 1 | 1 | 0.4029040475830763 | 0.5970959524169238 | 2 | 1 | 7 | 50 |
| 0 | 0 | 0.5590212174768847 | 0.44097878252311523 | 5 | 8 | 2 | 47 |
| 0 | 0 | 0.8321741558755249 | 0.16782584412447504 | 0 | 2 | 9 | 34 |
| 1 | 0 | 0.44325271844804326 | 0.5567472815519569 | 2 | 2 | 9 | 46 |
| 0 | 1 | 0.7430377360199014 | 0.2569622639800987 | 0 | 2 | 2 | 40 |
| 0 | 0 | 0.7149957939256096 | 0.28500420607439053 | 2 | 1 | 2 | 42 |
| 0 | 0 | 0.8699273534296157 | 0.1300726465703847 | 3 | 8 | 9 | 37 |
| 0 | 0 | 0.7808444433292575 | 0.21915555667074205 | 4 | 8 | 9 | 42 |
| 0 | 0 | 0.8967023885177757 | 0.10329761148222437 | 5 | 8 | 9 | 74 |
| 0 | 0 | 0.8910305935283059 | 0.10896940647169417 | 4 | 8 | 9 | 36 |
| 0 | 1 | 0.8787306609708248 | 0.12126933902917511 | 3 | 7 | 7 |
结言
以上就是大致思路和内容,想获取详细代码可以去我的Github上查看,想获取详细PDF论文可以关注私信我,我会定期查看发送。若无法联系,请备注添加vx:tt1144139594 欢迎各位交流
GitHub - FoolDeer/CompetitionStory
如果有更好的方式可以留言交流学习~谢谢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









