







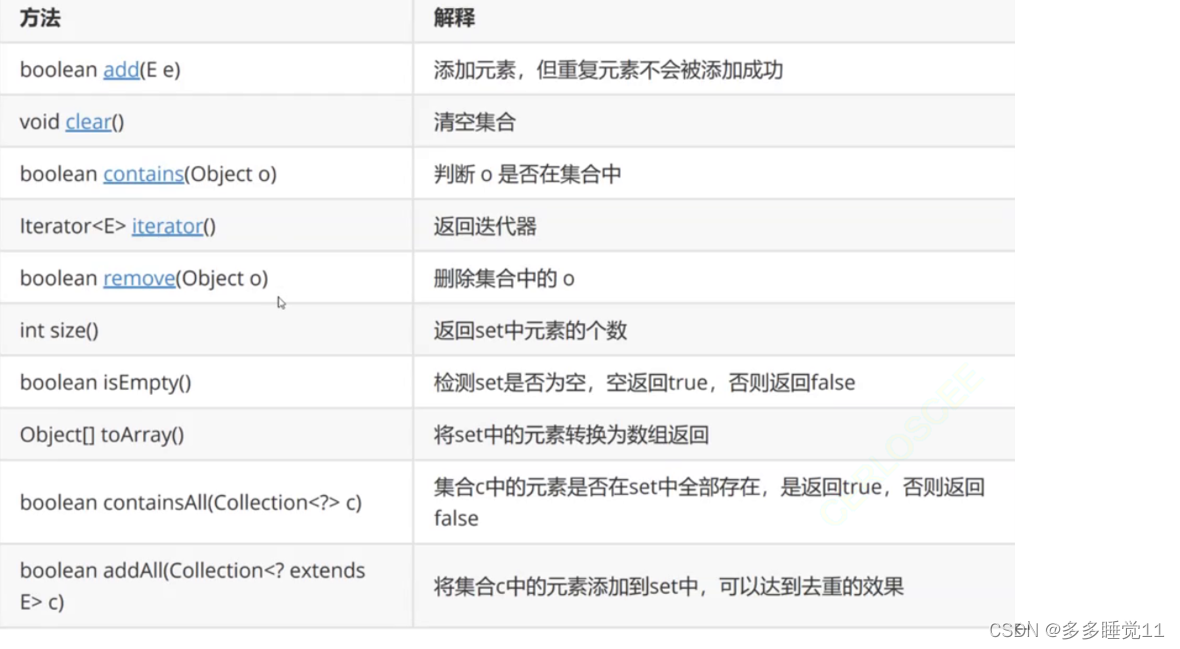
Map和Set是两个集合类的接口。
map的核心模型是Key-Value模型,set的模型是Key模型
Map和Set都有两种实现,分别是红黑树实现和hash实现
一、TreeMap
TreeMap和TreeSet都是红黑树,红黑树是一种搜索树,TreeMap和TreeSet都将key作为红黑树排序的依据,在查找数据时,也是使用红黑树查找key值,所以TreeMap和TreeSet的key类型需要实现了comparable接口作为红黑树排序的基础。
TreeMap的常用方法:
(一)创建一个TreeMap
TreeMap是一个泛型类,有key和value两个类型参数,key值是决定用来比较确定位置的值,value值是与key值绑定的实值。
TreeMap<K,V> map =new TreeMap<>();
创建一个TreeMap对象。
(二)向TreeMap中插入数据
V put(K k,V v);
向map中插入一个key-value键值对,并返回value的值,如果map之前存在相同的key值,则将之前的kay值对应的value值覆盖。
(三)向TreeMap中删除一个数据
V remove(K key);
删除map中和key值相同的k-v键值对,并返回对应的value值,如果map中不存在这个key值,则返回null值。
(四)用key查询map中对应的value值
V get(K key);
如果map中不存在这个key值则返回null
V getOrDefault(K key,V default);
查询对应key值的value值,如果key值不存在,则返回默认值。
(五)将map中所有的key值组织起来,放入一个set里面
Set<Key> keySet();
(六)将map中对应的value值组织起来,放入一个实现了colleciton接口的集合类里面
Collection<Value> values();
(七)查询map中是否包含某个key值或者value值
bool containsKey(Object key);
bool containsValue(Object value);
(八)Entry类
Entry是TreeMap的内部类。Entry就是TreeMap中用来存储键值对的节点类。Entry内部有包含左右子树节点。Entry是可比较的。
Entry的三个常用方法
(1)获取entry的key值
K getKey();
(2)获取Entry的value值
V getValue();
(3)设置Entry的value值
V setValue(V value);
(九)获取所有的键值对Entry节点,并以set的方式组织起来。
Set<Map.Entry<K,V>> entrySet();
EntrySet这个方法获取了所有的键值对,这个方法是为了遍历Map中的节点实现的。
正常情况下,单独的Map对象无法遍历其中的节点,因为map没有下标,并且没有实现迭代器接口,无法使用迭代器,也无法使用forEach。
为了遍历Map中的节点所以有了EntrySet,KeySet,Values。
set实现了迭代器接口,可以使用迭代器,也可以使用forEach,Values的返回值是实现了Collection接口的,也能遍历。
二、TreeSet
TreeSet的底层是TreeMap,TreeSet将TreeMap的Value值以一个默认的object对象自动填充,使用时只需要传入Key值。所以TreeSet的底层还是红黑树。
三、HashMap
hashMap中的键值对是没有顺序的,因为HashMap是使用哈希函数的方法将关键码转化为存储地址,只要知道关键码和哈希方法,就可以通过计算得出存储地址,所以HashMap中的键值对并没有顺序。被HashMap传入的key类型必须要有正确的hashCode和equals方法。
hashCode和equals必须要使用相同的标准判断,当两个对象hashCode相同时,需要使用equals判断这两个对象是相同的还是只有hashCode相同,但是实际上是两个对象。
默认的equals只是比较两个对象的内存地址是否相等,所以要想用对象的内容来判断两个对象是否相等需要重写equals方法。
要想以内容来确定hashcode,也要重写hashcode方法。
(一)哈希冲突:不同的关键码经过哈希函数计算得出相同的存储地址。
冲突是肯定会发生的,我们能做的就只是降低冲突发生的概率。
(二)降低冲突发生的概率的方法
(1)设计合理的哈希函数
哈希函数的设计原则:
哈希函数比较简单;
哈希函数的定义域应该包括所有的关键码,若表的的长度为m,则哈希函数的值域应该在0-m-1之间;
哈希函数计算出来的地址应该均匀;
(2)减小负载因子
负载因子=放入hash表中的元素个数/hash表的长度
负载因子越大,冲突的概率越大。
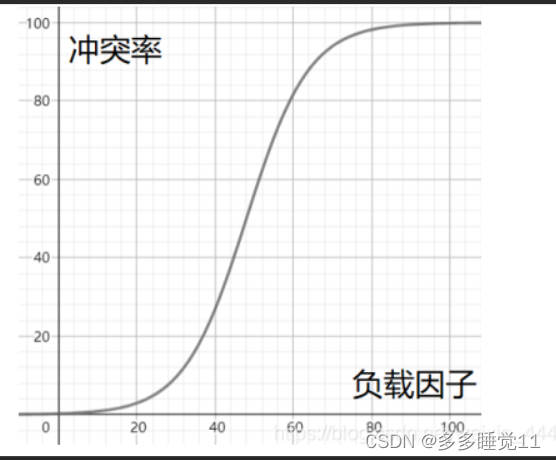
HashMap的默认负载因子为0.75,只要负载因子超过0.75,HashMap就会自动扩容。
(三)解决hash冲突
hash冲突是必定发生的,当冲突发生时,需要对冲突进行处理。
冲突处理有两种方法:开散列和闭散列。
(1)闭散列
闭散列:也叫开方地址法,当发生哈希冲突时,如果hash表并未被装满,则将要放入的值放在最近的空位置上。
放在空位置有两种方法。线性探测法和二次探测法
线性探测法:当发生冲突时,依次向后探测,知道找到空位置。
二次探测法:发生冲突时,用函数
![]()
H是函数计算出来的存储位置,i是第几次计算,m是表的长度
使用闭散列的方法处理hash冲突时,不能随便的删除表中的元素,否则查找一个使用了探测法来计算存储位置的数据时,可能回查找不到,所以闭散列的删除不是直接删除,删除也只能使用其他标记位来逻辑删除。
(2)开散列(哈希桶)
开散列解决冲突的方式是,将插入的数据包装为链表的节点,如果发生冲突,在冲突的存储位置上已经存在的节点上头插或者尾插。(JDK1.7之前用的是头插,JDK1.8用的是尾插)
并且当数组的长度超过64,链表的长度超过8,链表将会变成红黑树。
开散列的解决方案虽然冲突时会让链表越来越长,但是链表长度超过8时链表会转变为红黑树,查找链表的效率会提高,并且存在着负载因子,随着表中给的数据增多,负载因子变大,当负载因子到达临界条件时,hash表会扩容,扩容过后数据的存储位置都会重新计算,链表的长度也会变短,所以可以认为链表的长度是常数,hash表的查询时间复杂度是O(1);
HashMap的实现就是使用的开散列的方法
四、HashSet
HashSet也是以HashMap为底层的将value值用默认对象实例化。使用方法和TreeSet相差不大。
总结:
map可以分离所有的value和key值存储带set当中。
map的key值是唯一的,不能改变,如果要改变,只能先修改,再插入。
set实现了Collection接口。
set的key值是唯一的,set不能存储重复的数据,set最大的作用就是去重,set的key不仅是关键码,也是set存储的数据。















 1211
1211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









