







项目页面:https://cosmicman-cvpr2024.github.io/
CosmicMan:一种针对生成高保真人类图像的文本到图像基础模型。
Introduction
存在问题:
1. 缺乏专门用于人类主题任务的文本到图像基础模型;
2. 在以人为中心的内容生成任务中,先前研究所用数据集往往在多样性方面较窄,或缺乏质量。
适用于人类的文生图基础模型所需的关键要素:
1. 高质量数据;
2. 可扩展的数据生产(随时间推移数据生产流程能持续更新,并确保数据标注准确性和数据分布的动态适应性);
3. 实用模型(即易于集成到下游任务中)。
主要贡献:
1. 提出了一种新的数据生产范式,即“Annotate Anyone”;
2. 构建了一个大规模高质量的数据集 CosmicMan-HQ 1.0,其中包含 600 万张高质量真实世界单人图像,平均分辨率为 1488 × 1255,并附有来自不同粒度的 1.15 亿个属性的精确文本标注;
3. 提出以分解的方式对密集文本描述和图像像素之间的关系进行建模,并提出 Daring (Decomposed-Attention-Refocusing 分解注意力重聚焦(基于SD且没有添加额外模块))训练框架。
Method
1. Annotate Anyone – A Data Flywheel (数据飞轮)
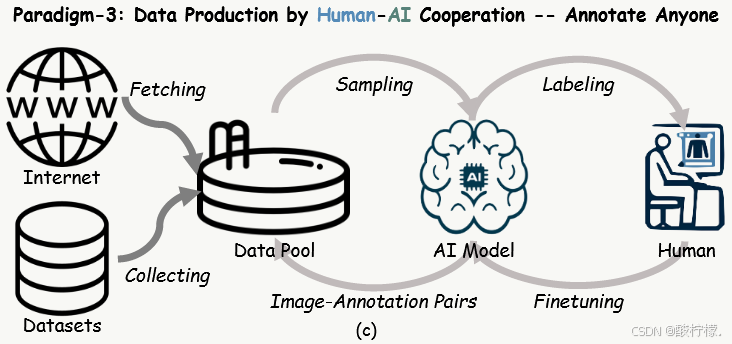
通过人机协作的数据生产范式——Annotate Anyone:
1) 流动数据(数据池是持续流动和更新的)
数据来源:从学术数据集和互联网上获取高质量的人类图像数据;
数据过滤:去除假人图像,图像质量评估等。(学术数据源:LAION-5B、SHHQ和 DeepFashion)
2) 闭环标注(三个实体:数据池、AI 和人类标注员)
标注迭代:如上图c所示,其中预训练的InstructBLIP作为AI模型。与完全人工标注相比,仅需要 1% 的标注量。
标签协议:利用人类解析模型SCHP将图像分解为 18 精细部分,包括背景、面部、上衣等。每个部分平均有 3 到 8 个相关问题,总共产生 70 个问题,对应 70 个类别。
人类解析模型SCHP来自:
Peike Li, Yunqiu Xu, Yunchao Wei, and Yi Yang. Self-correction for human parsing. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(6):3260–3271, 2020.
通过运行 Annotate Anyone,得到数据集 CosmicMan-HQ 1.0,其拥有多样化的人类图像,包括全身照、头像、半身照等。在分辨率方面,大幅超过 DF-MM 和 SHHQ 等;在整体和面部图像质量方面,仅次于 DF-MM 数据集。

上表中,“Common Scale”指包含以常见尺度拍摄的图像的数据集,例如全身照、人像照片和半身照;“HP”和“Aes”分别指人类解析图和美学评分。
2. Daring - 训练框架
Daring基于原始Stable Diffusion(SD)进行了最小修改。
前言:
SD 包含一个变分自动编码器 E,将图像 x 编码为紧凑潜在空间中的潜在变量 z,并在潜在空间中应用扩散方案,从而促进扩散过程并降低计算成本。通过最小化预测噪声 和真实噪声
之间的
误差优化去噪网络:
![]()
其中 是时间步t的潜在表示,c 是可以通过文本输入实例化的条件信息。
交叉注意力层:文本提示 P 首先通过 CLIP 文本编码器转换为文本嵌入 c。潜在表示 和文本嵌入 c 被投影为查询 Q 和键 K。计算交叉注意力图以将文本信息扁平化为空间特征:
(2)。
SD存在的问题:由于缺乏有效指导来学习独特且精确定位的特征、缺乏标题和图像像素之间的显式对齐约束,它仅当文本描述简短稀疏时效果良好,无法处理具有密集概念的文本信息。
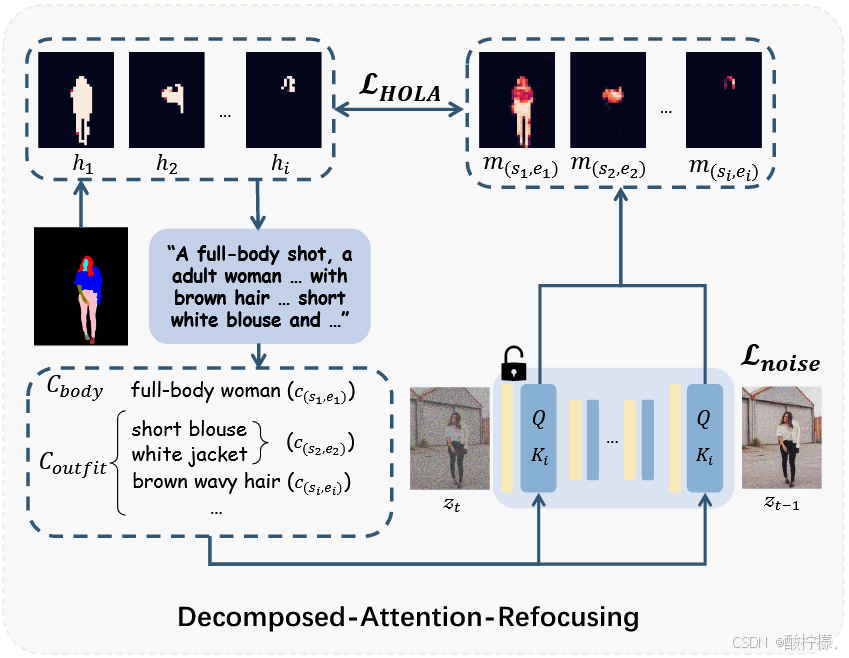
Daring的两部分设计:
1) 数据离散化,将文本-人类数据分解为遵循人类结构的固定组;
a. 在 CosmicMan-HQ 中给定人类数据样本 𝐱 ,首先将人类解析图重新组织成语义图集 ,其中 N 是语义掩码的数量,
属于人体级别(将所有人类解析图聚合起来以区分前景和背景),其余属于服装级别。
b. 根据 H 分割文本描述,所有文本描述都可以表示为 ,整体外观
,服装的细粒度属性
。其中,
表示与语义图
相关的第 n 个子描述组,
分别是描述中概念的开始和结束索引,将没有对应语义掩码的描述短语收集为
,例如背景的描述。
2) 一个新的损失 – HOLA,用于强制交叉注意力特征在相对于身体结构和服装排列的适当空间区域内积极响应。
给定描述 C 和 潜在表示 ,交叉注意力图 M 可以分解为
。每个
由公式2计算得出,将 K 转换为
(子描述
的投影嵌入)。
在SD中结合HOLA和原始损失,以显式引导交叉注意力图只在特定区域有高响应,而不是在整个图像中均匀分布响应。HOLA 定义如下:
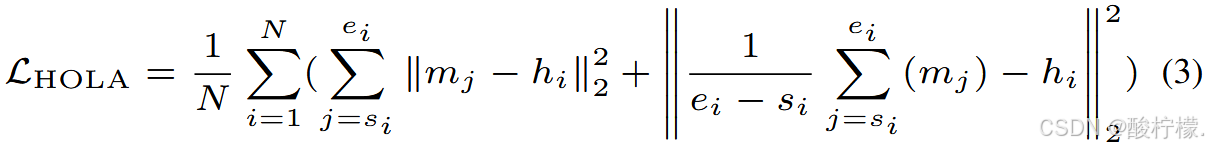
其中,N 表示子描述的数量,即文本描述被划分成的片段数; 和
分别表示第i个子描述的起始和结束位置;
是交叉注意力图中的元素,表示在第j个位置的注意力权重;
是第i个子描述对应的语义区域的特征。这个公式通过计算注意力图和语义区域特征之间的差异,来衡量模型对齐的好坏。
具体来说,HOLA 的第一项是在人体结构的指导下,将每个概念特征的高响应区尽可能地推向对应的语义区(让模型更好地理解文本描述和图像之间的对应关系)。第二项是在处理同一组概念时,能够将这些概念的注意力图平均,并且要与该组概念对应的语义图更接近(让模型更好地理解不同概念之间的关系)。
整体损失函数如下:整体损失函数:。
Experiment
实现细节:
基于 Stable Diffusion(SD-1.5 和 SDXL),结合 Daring 框架对 Stable Diffusion 预训练模型中的整个 UNet 进行微调。使用 AdamW 作为优化方法,学习率为 1e-5,权重衰减为 1e-2。在 32 个 80G NVIDIA A100 GPU 上以 64 个批处理大小训练了大约一周。
评估指标:
1. 图像质量:Frechet Inception Distance(FID)和人类偏好评分 v2 (HPSv2);
2. 文本-图像对齐:受 DSG 启发的语义准确度指标,专重点关注 object (), texture (
), shape (
), and overall (
)。(CLIPScore很难捕捉到详细的图像-文本关系。)
3. 人类偏好:用户研究。
定量评估:
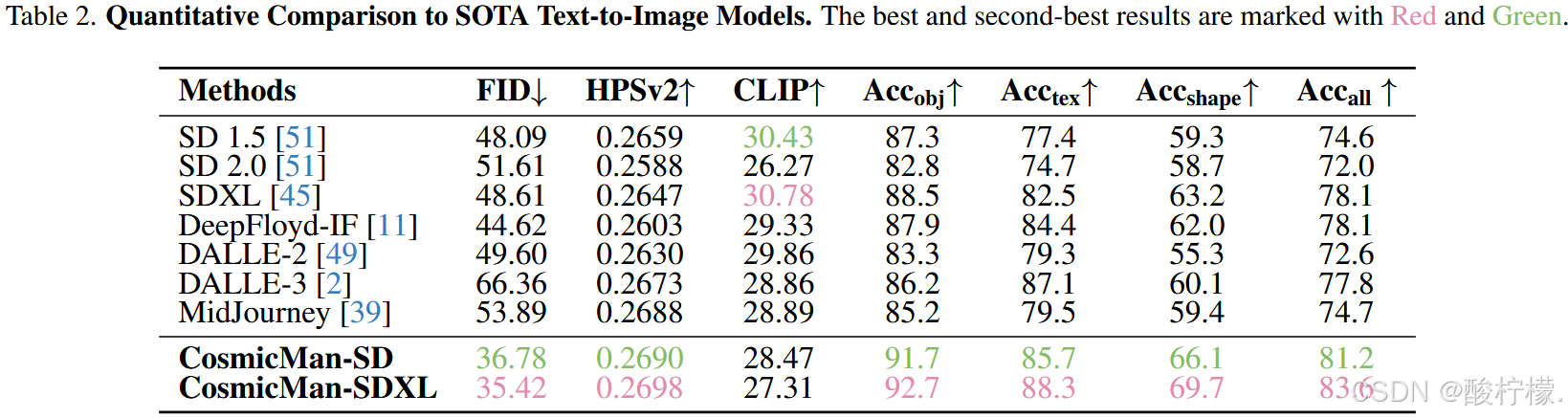
CLIPScore 缺乏细粒度评估的能力,所以CosmicMan-SD/SDXL 的 CLIPScore 相对较低。
人类偏好评估:与 DeepFloyd-IF、SDXL、DALLE3 和 MidJourney 进行比较,结果显示更多的受试者在图像质量和文本-图像对齐方面更喜欢我们的结果。
消融研究:
1. 训练数据消融:
比较对象:a. LAION-5B 和 HumanSD 两个前沿数据集,b. 我们的数据集由三种不同方法生成文本描述,c. 我们的数据集由 Annotate Anyone 生成的描述。
比较结果证明我们提出的 CosmicMan-HQ 数据集的有效性。
2. 训练策略消融:
比较对象:SD 预训练模型,SD + CosmicMan-HQ,SD + CosmicMan-HQ + HOLA损失。
证明我们对数据和模型设计的创新视角显著提升了 CosmicMan 在细粒度人类生成上的提升。
应用:
1. 2D人体编辑:用于调整人类图像以实现特定姿势;
2. 3D 人体重建:从单张图像中重建 3D 物体。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









