








介绍
什么是线程池?
管理一系列线程的资源池。当有任务要处理时,直接从线程池中获取线程来处理,处理完之后线程并不会立即被销毁,而是等待下一个任务。
为什么要使用线程池?
池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。
线程池提供了一种限制和管理资源(包括执行一个任务)的方式。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
创建线程池
两种方式创建线程池
- 通过ThreadPoolExecutor构造函数来创建(推荐)

-
通过Executor框架的工具类Executor来创建
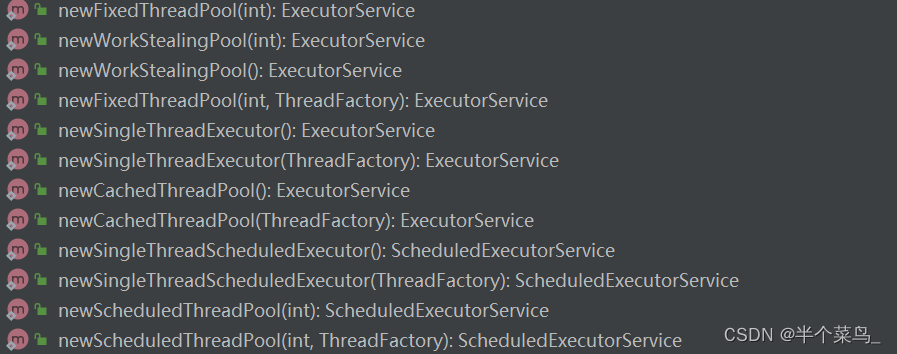
-
FixedThreadPool:
- 特点:该线程池维护固定数量的线程,线程数量不会变化。当有新任务提交时,如果有空闲线程,则立即执行;如果所有线程都在忙碌,新任务会暂存在任务队列中,待有线程空闲时再执行。
- 适用场景:适用于需要控制线程数量的情况,例如避免系统资源被过多的线程占用。
-
SingleThreadExecutor:
- 特点:该线程池只包含一个线程,所有任务按顺序在这个线程中执行。如果有多个任务被提交,它们会按照先入先出的顺序被放入任务队列中,等待线程执行。
- 适用场景:适用于需要保证任务按顺序执行的场景,例如需要按照队列中的顺序处理任务。
-
CachedThreadPool:
- 特点:该线程池的线程数量可根据实际情况动态调整。初始时,线程池中不包含任何线程。当有新任务提交时,如果没有可用线程,则会创建新线程处理任务;如果线程在一段时间内闲置,会被销毁以节省资源。
- 适用场景:适用于任务数量和任务执行时间不确定的情况,能够根据需求动态调整线程数量。
-
ScheduledThreadPool:
- 特点:该线程池用于在给定的延迟后运行任务或者定期执行任务。可以设置核心线程数量,根据需要动态创建线程来处理任务。
- 适用场景:适用于需要定期执行任务或者延迟执行任务的场景,例如定时任务调度。
谈谈Executor框架创建线程池有什么不好的地方呢?
-
FixedThreadPool:
- 弊端: 固定大小的线程池使用的是无界的
LinkedBlockingQueue。当任务提交速度快于任务执行速度时,任务队列可能会持续增长,直到消耗完系统的内存资源,导致 OutOfMemoryError。此外,固定大小的线程池的线程数是固定的,可能无法应对任务数量的剧增,导致无法处理新的任务,从而造成任务堆积或请求响应延迟。
- 弊端: 固定大小的线程池使用的是无界的
-
SingleThreadExecutor:
- 弊端: 单线程的线程池使用的也是无界的
LinkedBlockingQueue,因此也存在任务队列持续增长导致内存耗尽的风险。此外,由于只有一个线程,如果该线程发生异常而终止,整个线程池就会无法处理新的任务,造成请求响应延迟或任务堆积。
- 弊端: 单线程的线程池使用的也是无界的
-
CachedThreadPool:
- 弊端: 缓存线程池使用的是同步队列
SynchronousQueue,它不会保存任务,而是会立即将任务交给线程执行。如果任务提交速度快于任务执行速度,会导致线程池不断创建新的线程,直到耗尽系统的内存资源,最终导致 OutOfMemoryError。此外,线程池中的线程数量是不受限制的,当任务数量剧增时,可能会创建大量线程,影响系统的稳定性。
- 弊端: 缓存线程池使用的是同步队列
-
ScheduledThreadPool 和 SingleThreadScheduledExecutor:
- 弊端: 定时任务线程池使用的是无界的延迟阻塞队列
DelayedWorkQueue,同样存在任务队列持续增长导致内存耗尽的风险。当定时任务提交速度快于执行速度时,任务队列可能会不断增长,最终耗尽系统的内存资源,导致 OutOfMemoryError。
- 弊端: 定时任务线程池使用的是无界的延迟阻塞队列
ThreadPoolExecutor的使用以及注意事项
这里是线程池创建的构造方法,下面我们来说说它参数的一些细节
/**
* 用给定的初始参数创建一个新的ThreadPoolExecutor。
*/
public ThreadPoolExecutor(int corePoolSize, // 线程池的核心线程数量
int maximumPoolSize, // 线程池的最大线程数
long keepAliveTime, // 当线程数大于核心线程数时,多余的空闲线程存活的最长时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 任务队列,用来储存等待执行任务的队列
ThreadFactory threadFactory, // 线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler // 拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
) {
// 参数合法性校验
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
// 参数非空性校验
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
// 将参数赋值给对应的成员变量
this.corePoolSize = corePoolSize; // 设置核心线程数
this.maximumPoolSize = maximumPoolSize; // 设置最大线程数
this.workQueue = workQueue; // 设置任务队列
this.keepAliveTime = unit.toNanos(keepAliveTime); // 设置空闲线程的存活时间
this.threadFactory = threadFactory; // 设置线程工厂
this.handler = handler; // 设置拒绝策略
}
ThreadPoolExecutor 3 个最重要的参数:
- corePoolSize: 任务队列未达到队列容量时,最大可以同时运行的线程数量。
- maximumPoolSize: 任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
- workQueue: 新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
其他参数
- keepAliveTime:当线程数大于核心线程数时,多余的空闲线程存活的最长时间。
- unit: keepAliveTime 参数的时间单位。
- threadFactory:executor 创建新线程的时候会用到。
- handler:饱和策略。
下面举一个例子来说明这几个参数:
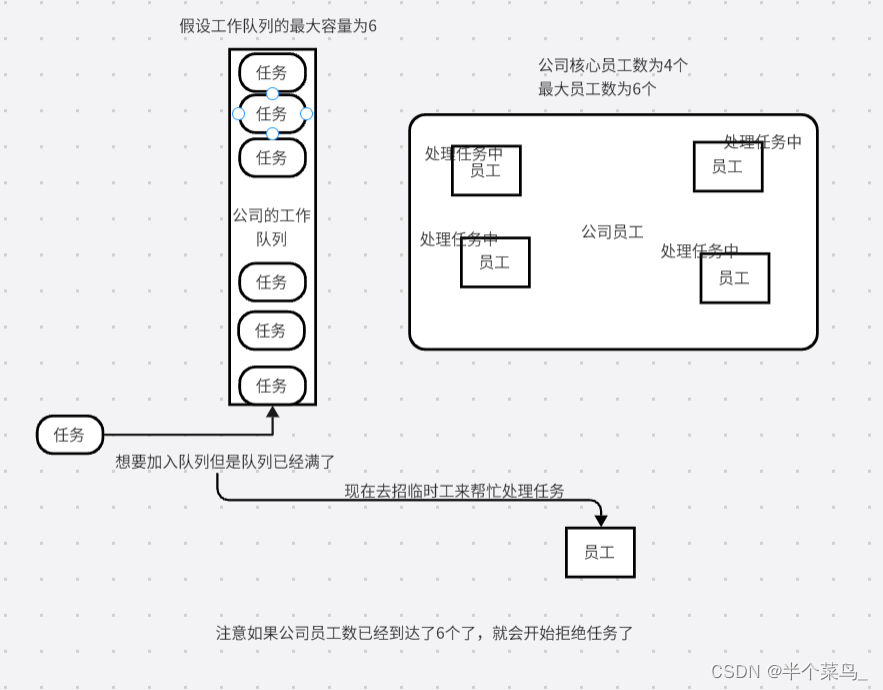
让我们将线程池比喻成一个小公司,并对其中的参数进行解释:
假设我们有一个小公司,公司员工可以处理任务,而线程池中的线程就相当于公司的员工,任务则相当于公司要处理的工作。
-
corePoolSize(核心员工数):这是公司正式员工的数量。无论工作量如何,公司始终保持这么多员工。每个员工可以同时处理一个任务。
-
maximumPoolSize(最大员工数):这是公司允许的最大员工数量,包括核心员工和临时员工。当工作量增加时,公司会招募临时员工来应对高峰时期的工作压力。
-
keepAliveTime(员工空闲时间):如果公司员工超过核心员工数量,那么多余的员工会被视为临时员工。当这些临时员工在一段时间内没有工作可做时,公司会解雇他们。这个时间就是空闲时间,超过这个时间,临时员工就会被解雇。
-
workQueue(工作队列):这是公司的工作任务队列,用来存放还未被处理的任务。如果所有的员工都在忙于处理任务,而新的任务又不断涌入,那么这些任务就会暂时放在队列中,等待员工有空闲的时候再处理。
-
threadFactory(员工招聘渠道):这是公司用来招聘新员工的渠道。线程工厂负责创建新的线程(员工),你可以自定义线程工厂来创建线程。
-
handler(拒绝任务政策):当公司处理不过来任务时,会采取一定的策略来处理。例如,可以采取拒绝策略,直接拒绝接收新任务,或者采取临时雇佣策略,暂时招募更多员工来应对高峰时期的工作压力。
下面是一个demo,在Spring Boot环境下运行
线程池配置类:
package com.pxl.bi.config;
import com.pxl.bi.common.ErrorCode;
import com.pxl.bi.exception.BusinessException;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.*;
import org.jetbrains.annotations.NotNull;
@Configuration
@Slf4j
public class ThreadPoolExecutorConfig {
@Bean
public ThreadPoolExecutor threadPoolExecutor() {
// 创建一个线程工厂
ThreadFactory threadFactory = new ThreadFactory() {
// 初始化线程数为 1
private int count = 1;
@Override
// 每当线程池需要创建新线程时,就会调用newThread方法
// @NotNull Runnable r 表示方法参数 r 应该永远不为null,
// 如果这个方法被调用的时候传递了一个null参数,就会报错
public Thread newThread(@NotNull Runnable r) {
// 创建一个新的线程
Thread thread = new Thread(r);
// 给新线程设置一个名称,名称中包含线程数的当前值
thread.setName("线程" + count);
// 线程数递增
count++;
// 返回新创建的线程
return thread;
}
};
// 创建一个拒绝执行处理器
ThreadPoolExecutor threadPoolExecutor = getThreadPoolExecutor(threadFactory);
// 返回创建的线程池
return threadPoolExecutor;
}
@NotNull
private static ThreadPoolExecutor getThreadPoolExecutor(ThreadFactory threadFactory) {
RejectedExecutionHandler rejectionHandler = new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 这里可以根据具体业务需求来处理拒绝执行的任务
log.error("线程处理已满,拒绝处理服务");
throw new BusinessException(ErrorCode.SYSTEM_BUSY,"系统繁忙");
}
};
// 创建一个新的线程池,线程池核心大小为2,最大线程数为4,
// 非核心线程空闲时间为100秒,任务队列为阻塞队列,长度为4,使用自定义的线程工厂创建线程
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 4, 100, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(4), threadFactory, rejectionHandler);
return threadPoolExecutor;
}
}这里是任务添加控制类
package com.pxl.bi.controller;
import cn.hutool.json.JSONUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Profile;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ThreadPoolExecutor;
/**
* 队列测试
*/
@Profile({"dev","local"})
@RestController
@Slf4j
@RequestMapping("/queue")
public class QueueController {
@Resource
private ThreadPoolExecutor threadPoolExecutor;
/**
* 接收一个名为name的任务,将任务添加到线程池中
* @param name
*/
@GetMapping("/add")
public void add(String name){
// 使用CompletableFuture运行一个异步任务
CompletableFuture.runAsync(() -> {
// 打印一条日志信息,包括任务名称和执行线程的名称
log.info("任务执行中:" + name + ",执行人:" + Thread.currentThread().getName());
try {
// 让线程休眠10分钟,模拟长时间运行的任务
Thread.sleep(600000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 异步任务在threadPoolExecutor中执行
}, threadPoolExecutor);
}
/**
* 获取线程池中的信息
* @return
*/
@GetMapping("/get")
public String get(){
// 创建一个HashMap存储线程池的状态信息
Map<String, Object> map = new HashMap<>();
//获取线程池大小
int size = threadPoolExecutor.getQueue().size();
// 将队列长度放入map中
map.put("队列长度", size);
// 获取线程池已接收的任务总数
long taskCount = threadPoolExecutor.getTaskCount();
// 将任务总数放入map中
map.put("任务总数", taskCount);
// 获取线程池已完成的任务数
long completedTaskCount = threadPoolExecutor.getCompletedTaskCount();
// 将已完成的任务数放入map中
map.put("已完成任务数", completedTaskCount);
// 获取线程池中正在执行任务的线程数
int activeCount = threadPoolExecutor.getActiveCount();
// 将正在工作的线程数放入map中
map.put("正在工作的线程数", activeCount);
// 将map转换为JSON字符串并返回
return JSONUtil.toJsonStr(map);
}
}
加入这两个类了,就可以使用Swagger或postman进行测试了。
线程池饱和策略
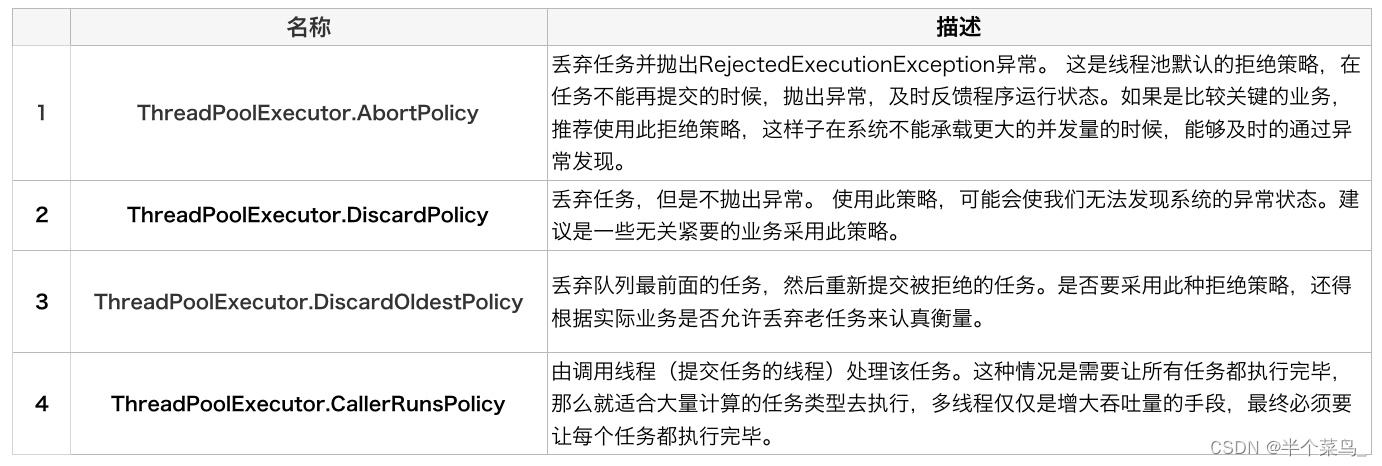
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,ThreadPoolExecutor 定义一些策略:
- ThreadPoolExecutor.AbortPolicy: 抛出 RejectedExecutionException来拒绝新任务的处理。(默认)
- ThreadPoolExecutor.CallerRunsPolicy: 调用执行自己的线程运行任务(如果任务时间过长可能会导致当前服务直接堵死)
- ThreadPoolExecutor.DiscardPolicy: 不处理新任务,直接丢弃掉。
- ThreadPoolExecutor.DiscardOldestPolicy: 此策略将丢弃最早的未处理的任务请求。
线程池中常用的阻塞队列有哪些

-
LinkedBlockingQueue(无界队列):
- 应用于FixedThreadPool和SingleThreadExecutor。
- 无界队列意味着队列可以无限增长,不会出现任务被拒绝的情况。在FixedThreadPool和SingleThreadExecutor中,无界队列的作用是用来存储等待执行的任务,而且这两种线程池都有固定的核心线程数,因此任务队列永远不会被放满。
-
SynchronousQueue(同步队列):
- 应用于CachedThreadPool。
- SynchronousQueue 是一个没有容量的队列,它不存储元素,而是直接将任务交给线程执行。在CachedThreadPool中,每当有任务提交时,如果有空闲线程则立即使用,如果没有则会新建一个线程来处理任务。这种设计使得CachedThreadPool的线程数可以根据需求动态地增加,但同时也会增加系统资源的消耗,可能导致OutOfMemoryError。
-
DelayedWorkQueue(延迟阻塞队列):
- 应用于ScheduledThreadPool和SingleThreadScheduledExecutor。
- DelayedWorkQueue 用于存储延迟执行的任务,并根据任务的延迟时间对任务进行排序。它的内部采用堆的数据结构,保证每次出队的任务都是当前队列中执行时间最靠前的。这种队列的特性使得ScheduledThreadPool和SingleThreadScheduledExecutor能够按照预定的时间执行任务,而且队列不会阻塞,可以动态地扩容,最多只能创建核心线程数的线程。
线程池执行流程

如何给线程池命名
两种方式实现:
-
利用 guava 的 ThreadFactoryBuilder
-
自己实现 ThreadFactory。
guava 的 ThreadFactoryBuilder
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
public class Main {
public static void main(String[] args) {
// 创建一个 ThreadFactoryBuilder
ThreadFactoryBuilder threadFactoryBuilder = new ThreadFactoryBuilder();
// 设置线程名称格式
threadFactoryBuilder.setNameFormat("my-pool-%d");
// 创建 ThreadFactory
ThreadFactory threadFactory = threadFactoryBuilder.build();
// 使用自定义的 ThreadFactory 创建线程池
ExecutorService executorService = Executors.newFixedThreadPool(5, threadFactory);
// 提交一些任务到线程池中
for (int i = 0; i < 10; i++) {
executorService.submit(() -> {
System.out.println(Thread.currentThread().getName() + " is executing task");
});
}
// 关闭线程池
executorService.shutdown();
}
}
自己实现ThreadFactory实现命名
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
public class NamedThreadFactoryExample {
public static void main(String[] args) {
// 创建一个带有自定义命名的线程池
ExecutorService executorService = Executors.newFixedThreadPool(5, new NamedThreadFactory("MyThreadPool"));
// 提交一些任务到线程池中
for (int i = 0; i < 10; i++) {
executorService.submit(() -> {
System.out.println(Thread.currentThread().getName() + " is executing task");
});
}
// 关闭线程池
executorService.shutdown();
}
}
// 自定义的线程工厂类
class NamedThreadFactory implements ThreadFactory {
private final String namePrefix;
public NamedThreadFactory(String namePrefix) {
this.namePrefix = namePrefix;
}
@Override
public Thread newThread(Runnable r) {
// 创建一个新线程,并设置名称
Thread t = new Thread(r, namePrefix + "-Thread");
return t;
}
}
扩展
如何设置线程池大小问题
主要其实还是看具体的业务场景来看,有些时候实际处理能力或需求只有那么多,如果线程太多会导致性能上的浪费。
有一个简单并且适用面比较广的公式:
- CPU 密集型任务(N+1): 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1。(用来计算之类的操作)
- I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。(一般这种使用在文件传输、通信、数据库访问等方面)
如何动态修改线程池的参数
-
使用可调整的线程池实现:
- Java 并发包中提供了
ThreadPoolExecutor类的相关实现,例如ScheduledThreadPoolExecutor和ThreadPoolExecutor。它们允许你动态地修改线程池的参数,如核心线程数、最大线程数、任务队列大小等。你可以通过提供新的参数值来调用相应的 setter 方法来实现动态修改。
- Java 并发包中提供了
-
使用自定义的动态调整方法:
- 你可以编写自定义的方法来动态地调整线程池的参数。例如,你可以编写一个方法,定期检查系统的负载情况,根据负载情况动态地调整线程池的参数。这种方法需要一定的编程技巧和经验,但可以根据具体需求来实现更灵活和智能的调整。
-
使用监控工具:
- 你可以使用监控工具来监视线程池的运行状态和性能指标,如活动线程数、任务队列长度、任务完成率等。根据监控数据的分析,你可以手动或自动地调整线程池的参数。常用的监控工具包括 JConsole、VisualVM、Prometheus 等。
-
使用外部配置文件:
- 你可以将线程池的参数配置到外部配置文件中,如 properties 文件、XML 文件等。然后,在程序运行时动态地加载和解析配置文件,根据配置文件中的参数值来调整线程池的参数。这种方法适用于需要频繁修改参数但又不希望修改源代码的情况。
-
使用管理平台:
- 如果你的应用程序部署在容器或云平台上,通常会提供管理平台或控制台,你可以通过管理平台来动态地调整线程池的参数。例如,在容器管理平台中,你可以通过修改容器的环境变量或配置文件来修改线程池的参数。
下面是两个可以实现动态线程池的开源程序:
- Hippo4jopen in new window:异步线程池框架,支持线程池动态变更&监控&报警,无需修改代码轻松引入。支持多种使用模式,轻松引入,致力于提高系统运行保障能力。
- Dynamic TPopen in new window:轻量级动态线程池,内置监控告警功能,集成三方中间件线程池管理,基于主流配置中心。















 2261
2261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









