






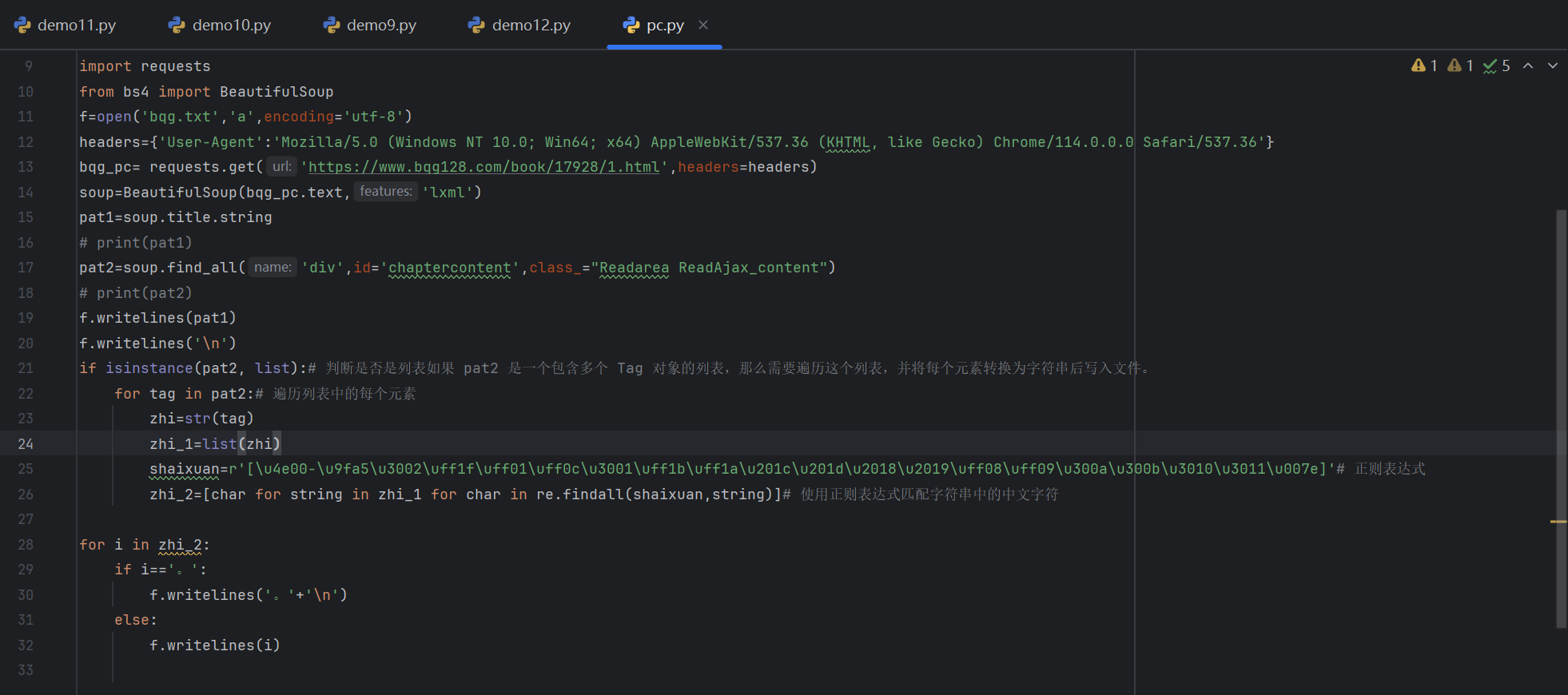
1.首先小说要以记事本存储:
f=open('bqg.txt','a',encoding='utf-8')
2,模仿自己是浏览器:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
3,访问笔趣阁网址:
bqg_pc= requests.get('https://www.bqg128.com/book/17928/1.html',headers=headers)
4,进行解析
soup=BeautifulSoup(bqg_pc.text,'lxml')
5,提取小说题目
pat1=soup.title.string

6,提取小说文章内容
pat2=soup.find_all('div',id='chaptercontent',class_="Readarea ReadAjax_content")

7,内容提出了是 Tag 对象的列表,那么需要遍历这个列表,并将每个元素转换为字符串后写入文件
if isinstance(pat2, list):# 判断是否是列表如果 pat2 是一个包含多个 Tag 对象的列表,那么需要遍历这个列表,并将每个元素转换为字符串后写入文件。
for tag in pat2:# 遍历列表中的每个元素
zhi=str(tag)
zhi_1=list(zhi)
8,运用正则表达式筛选出汉字和标点符号
shaixuan=r'[\u4e00-\u9fa5\u3002\uff1f\uff01\uff0c\u3001\uff1b\uff1a\u201c\u201d\u2018\u2019\uff08\uff09\u300a\u300b\u3010\u3011\u007e]'# 正则表达式 zhi_2=[char for string in zhi_1 for char in re.findall(shaixuan,string)]# 使用正则表达式匹配字符串中的中文字符
9,在。后面进行换行
for i in zhi_2:
if i=='。':
f.writelines('。'+'\n')
else:
f.writelines(i)
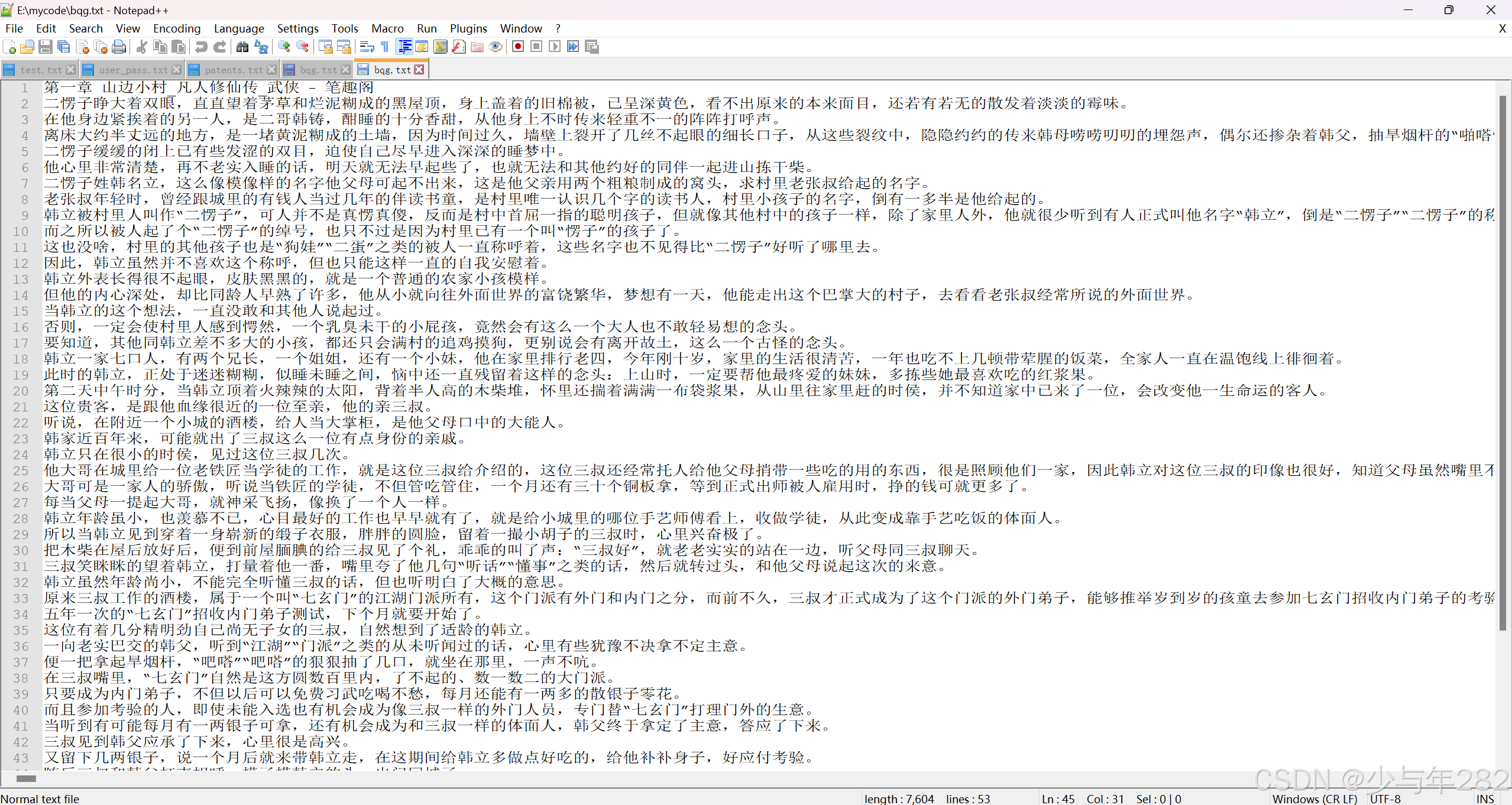
最后结果的txt:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









