








1.1 网络爬虫概述
网络爬虫(又被称为网络蜘蛛、网络机器人,在某社区中经常被称为网页追逐者),可以按照指定的规则(网络爬虫的算法)自动浏览或抓取网络中的信息,通过 Python 可以很轻松地编写爬虫程序或者是脚本。
在学习爬虫时不仅需要了解爬虫的实现过程,还需要了解一些常见的爬虫算法。在特定的情况下,还需要开发者自己制定相应的算法。
1.2 网络爬虫的分类
网络爬虫按照实现的技术和结构可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫。在实际的网络爬虫中,通常是这几类爬虫的组合体,下面分别介绍。
1.通用网络爬虫
通用网络爬虫又叫作全网爬虫(Scalable Web Crawler),通用网络爬虫的爬行范围和数量巨大,正是由于其爬取的数据是海量数据,所以对于爬行速度和存储空间要求较高。通用网络爬虫在爬行页面的顺序要求上相对较低,同时由于待刷新的页面太多,通常采用并行工作方式,所以需要较长时间才可以刷新一次页面。所以存在着一定的缺陷,这种网络爬虫主要应用于大型搜索引擎中,有着非常高的应用价值。通用网络爬虫主要由初始 URL 集合、URL 队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等构成。
2.聚焦网络爬虫
聚焦网络爬虫(Focused Crawler)也叫主题网络爬虫(Topical Crawler),是指按照预先定义好的主题,有选择的进行相关网页爬取的一种爬虫。它和通用网络爬虫相比,不会将目标资源定位在整个互联网中,而是将爬取的目标网页定位在与主题相关的页面中。极大地节省了硬件和网络资源,保存的页面也由于数量少而更快了,聚焦网络爬虫主要应用在对特定信息的爬取,为某一类特定的人群提供服务。
3.增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler),所谓增量式,对应着增量式更新。增量式更新指的是在更新时只更新改变的地方,而未改变的地方则不更新。所以增量式网络爬虫,在爬取网页时,只会在需要的时候爬行新产生或发生更新的页面,对于没有发生变化的页面,则不会爬取。这样可有效减少数据下载量,减小时间和空间上的耗费,但是在爬行算法上增加了一些难度。
1.3 网络爬虫的基本原理
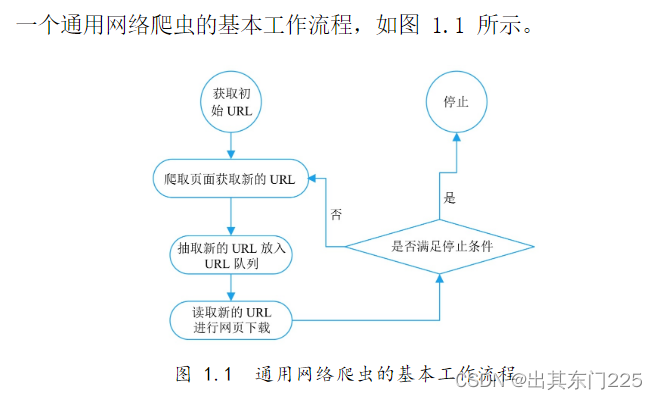
(1)获取初始的 URL,该 URL 地址是用户自己制定的初始爬取的网页。
(2)爬取对应 URL 地址的网页时,获取新的 URL 地址。
(3)将新的 URL 地址放入 URL 队列。
(4)从 URL 队列中读取新的 URL,然后依据新的 URL 爬取网页,同时从新的网页中获取新的 URL 地址,重复上述的爬取过程。
(5)设置停止条件,如果没有设置停止条件,那么爬虫会一直爬取下去,直到无法获取新的 URL 地址为止。设置了停止条件后,爬虫将会在满足停止条件时停止爬取。
安装 Anaconda
Anaconda 是一个完全免费的大规模数据处理、预测分析和科学计算工具。该工具中不仅集成了 Python 解析器,还有很多用于数据处理和科学计算的第三方模块,其中也包含许多网络爬虫所需要使用的模块,如 requests 模块、Beautiful Soup 模块、lxml 模块等。
安装教程自己搜
了解 Web 前端
爬虫的对手就是网页,所以了解 Web 前端的知识很重要。关于 Web 前端的知识是非常广泛的,所以本章将针对与爬虫相关的知识,如什么是 HTTP 协议、HTTP 与 Web 服务器的通信过程、HTML 的基本结构、什么是 CSS 层叠样式表,以及什么是 JavaScript 动态脚本语言的 Web 相关知识进行讲解,为学习爬虫技术打好基础。
HTTP 协议
HTTP(HyperText Transfer Protocol),即超文本传输协议,是互联网上应用最为广泛的一种网络协议。HTTP 是利用 TCP 在 Web 服务器和客户端之间传输信息的协议。客户端使用 Web 浏览器发起 HTTP 请求给 Web 服务器,Web 服务器发送被请求的信息给客户端。
HTTP 与 Web 服务器
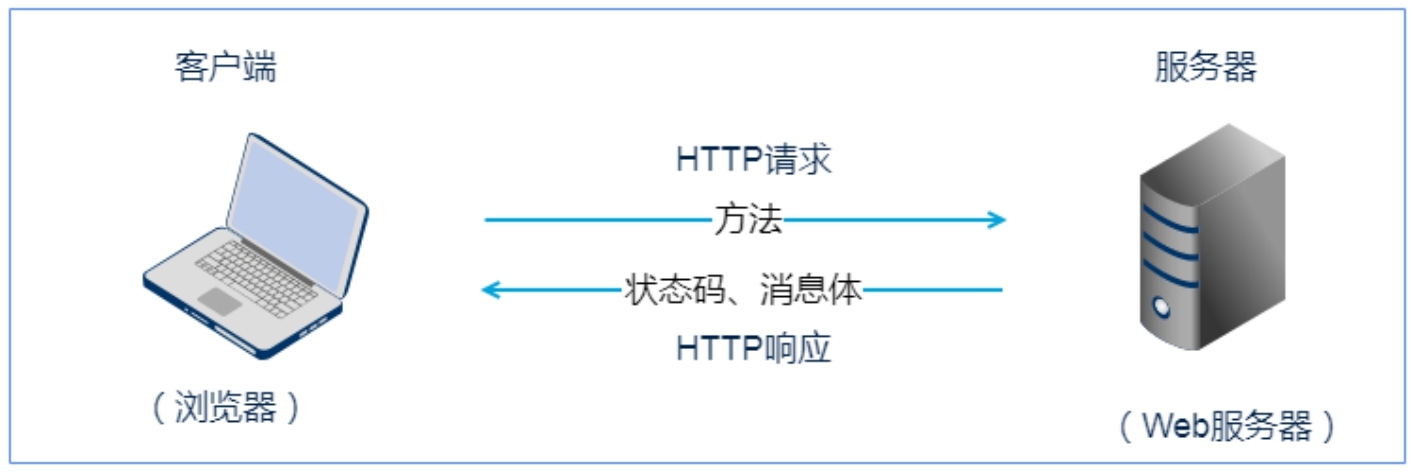
当在浏览器输入 URL 后,浏览器会先请求 DNS 服务器,获得请求站点的 IP 地址(即根据 URL 地址 www.mingrisoft.com 获取其对应的 IP 地址,如 101.201.120.85),然后发送一个 HTTP Request(请求)给拥有该 IP 的主机(,接着就会接收到服务器返回的 HTTP Response(响应),浏览器经过渲染后,以一种较好的效果呈现给用户。HTTP 基本原理如图 2.1 所示。
Web 服务器的工作原理可以概括为以下 4 个步骤。
(1)建立连接:客户端通过 TCP/IP 协议建立到服务器的 TCP 连接。
(2)请求过程:客户端向服务器发送 HTTP 协议请求包,请求服务器里的资源文档。
(3)应答过程:服务器向客户端发送 HTTP 协议应答包,如果请求的资源包含有动态语言的内容,那么服务器会调用动态语言的解释引擎负责处理「动态内容」,并将处理后得到的数据返回给客户端。由客户端解释 HTML 文档,在客户端屏幕上渲染图形结果。
图 2.1 HTTP 基本原理
(4)关闭连接:客户端与服务器断开。
HTTP 协议的常用请求方法

HTTP 状态码含义

浏览器中的请求和响应
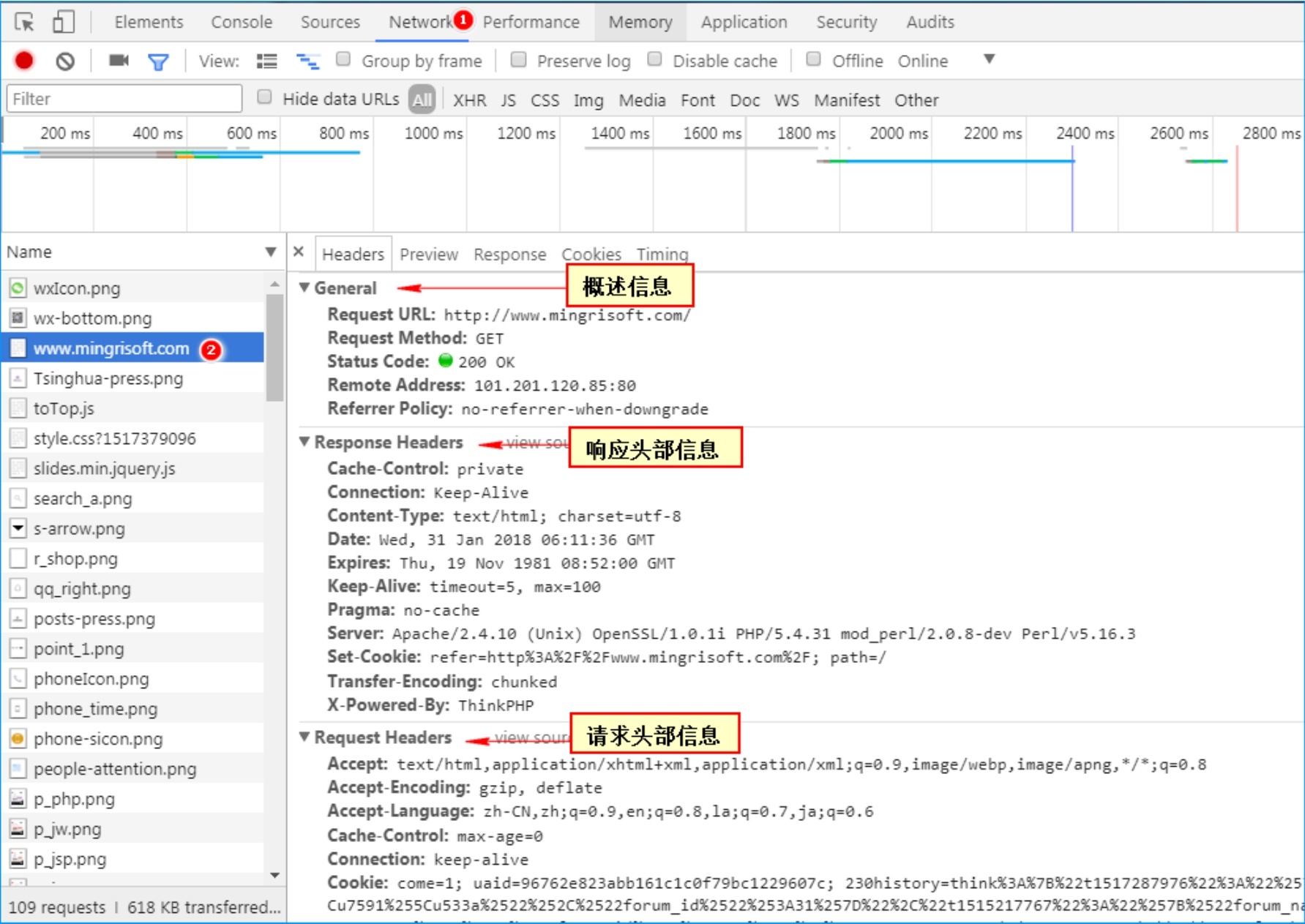
用谷歌浏览器,查看一下请求和响应的流程。步骤如下。
(1)在谷歌浏览器中进入一个网址
(2)按 F12 键(或右击,选择「检查」选项),审查页面元素
(3)单击谷歌浏览器调试工具的 Network 选项,按 F5 键(或手动刷新页面),单击调试工具中 Name 栏目下的 网页地址查看请求与响应的信息
















 117
117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









