






flux语言是influxdb2.0以上才支持的语言,influxdb1.8版本做了向后兼容,因此也可以使用flux语言。
在此之前influxdb的查询语言是influxQL,influx到了2.0版本之后又推出了apl,允许使用influxQL进行查询。
由官方文档Flux versions in InfluxDB | Flux 0.x Documentation,得知不同的influxdb版本支持的flux语言不同:
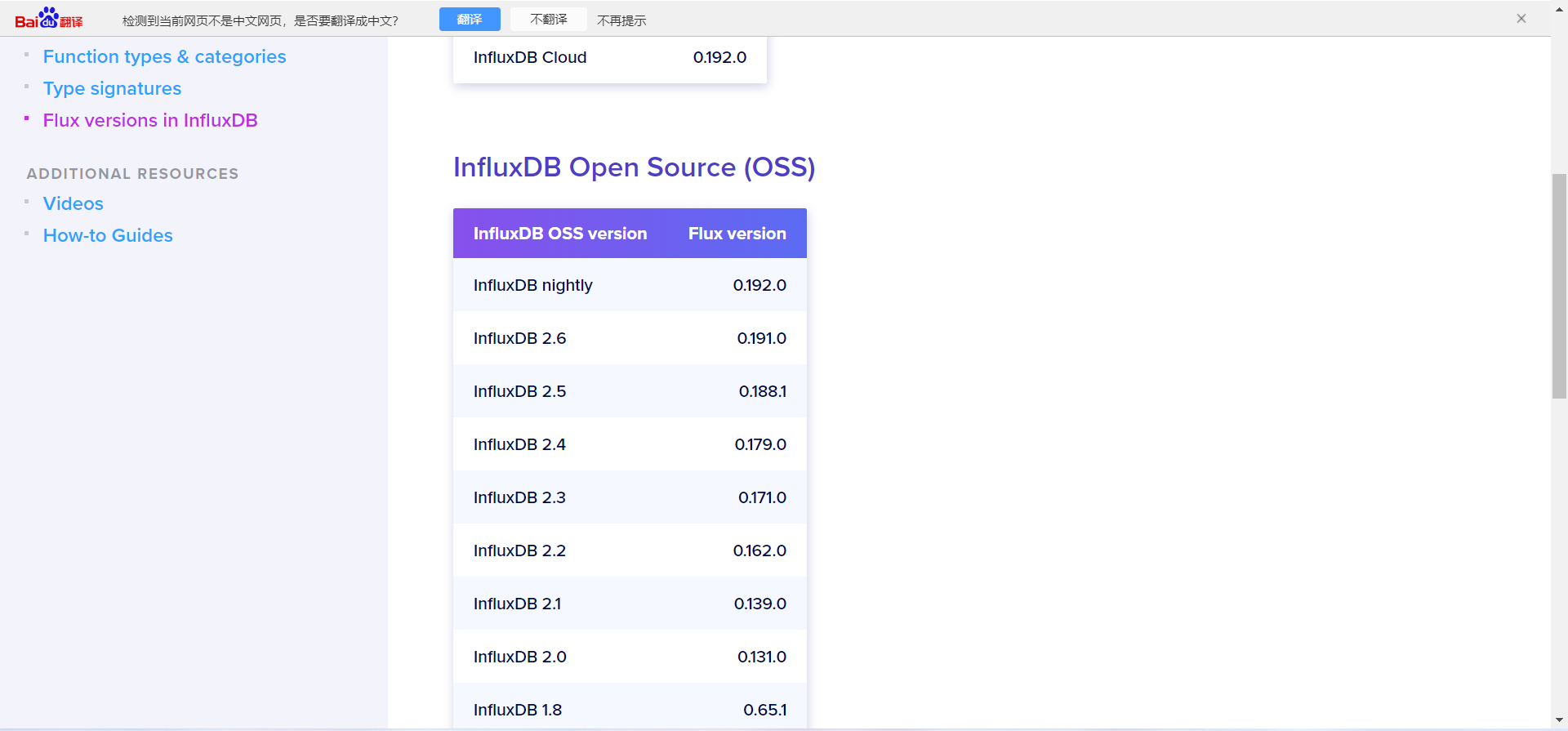
flux语法
变量与基本表达式:

这样点击submit会报错,想要正常运行,就要把数字放在表里面。
解决方法:使用array.from函数解决这个问题:

点击inject:



谓词表达式:
(点击submit会默认提交query里面的结果)
大小比较:
字符串大小比较:按照utf-8的编码,对英文有效(先比第一个,在比第二个...),对中文无效。
数字比较:可以跨类型比较。
特殊情况:

结果是false,因为0.1在计算机底层可能是0.100000000001.索引大于0.3
且和或:
and,or
正则表达式:
不会
逻辑取反:
not
控制语句:
只保留了三元运算符
三元运算符:
import "array"
x = 2
a = if x==0 then "green" else if x==1 then "red" else "yellow"
array.from(rows: [{"value":a}])10种基本数据类型(具体看文档)
bool:
import "array"
x = 0
b = bool(v: x)
array.from(rows: [{"value":b}])x的值只能是0或1,可以是浮点数,也可以是字符串的“1”或“true”。
bytes:
注意是 bytes(复数)不是 byte,bytes 类型表示一个由字节组成的序列。无法直接声明一个字节序列,只能转成字节序列。
代码这样写时,会报错:
import "array"
b = "abc"
x = bytes(v: b)
array.from(rows: [{"value":x}])因为flux数据要放到表里面,即数据要有行有列,有列即有类型,而flux支持bytes,influxdb不支持bytes。
解决方法:
1.把bytes类型转换成字符串:
import "array"
b = "abc"
x = bytes(v: b)
c = string(v: x)
array.from(rows: [{"value":c}])2.display函数打印字节序列:
import "array"
b = "abc"
x = bytes(v: b)
c = display(v: x)
array.from(rows: [{"value":c}])返回utf-8编码之后的字符串:

a:61,b:62
bytes的作用:序列化
向外发送post请求时,字符串必须先转为bytes类型,再传递给post函数
字节序列到字符串:
import "contrib/bonitoo-io/hex"
import "array"
b = "616263"
c = hex.bytes(v: b)//解析为bytes类型
array.from(rows: [{"value":display(v:c)}])duration时间间隔:
duration是flux脚本里面支持的类型,而不是influxdb里面支持的存储类型。
import "array"
import "date"
//RFC3339格式日期时间:
a = 2022-09-29T05:10:00Z
b = 2022-09-29T05:10:00.001Z
c = 1d2h//1天零2小时
c2 = -1d2h
e = date.add(d:c,to:a)
array.from(rows: [{"value":a},{"value":b},{"value":e}])类型转换问题:
字符串:
import "array"
import "date"
//RFC3339格式日期时间:
a = 2022-09-29T05:10:00Z
b = 1mo
c = 1d2h//1天零2小时
d = duration(v: c)
array.from(rows: [{"value":display(v:d)}])整数:
import "array"
import "date"
//RFC3339格式日期时间:
a = 2022-09-29T05:10:00Z
b = 1mo
c = 1000*1000*1000*60*60*24
//直接用整数表示的是纳秒:
d = duration(v: c)
array.from(rows: [{"value":display(v:d)}])time时间点:
import "array"
import "date"
b = now()//获取当前时间点
c = date.hour(t: now())//返回int类型,把时间对应的小时提取出来
array.from(rows: [{"value":c}])与时间戳的相互转换:
import "array"
import "date"
a = 1022-01-30T05:10:00.001Z
//时间戳转时间点
b = time(v: 1664401985000*1000*1000)//化成微秒再化成纳秒
//时间点转时间戳
c = uint(v: a)
array.from(rows: [{"value":c}])字符串:
import "array"
import "date"
a = "ab\"c"//用反斜杠转义
array.from(rows: [{"value":a}])其他类型转成字符串:
import "strings"
import "array"
import "date"
//判断字符串里面是否包含某个字符串
a = strings.containsStr(v: "This and that", substr: "and")
//
b = strings.joinStr(arr: ["a", "b", "c"], v: ",")
//判断字符串里面是不是一个英文字母(字符串里面只能有一个字符)
c = strings.isLetter(v: "A")
array.from(rows: [{"value":c}])更多:
Flux standard library | Flux 0.x Documentation
正则表达式:
正则表达式是flux脚本里面支持的类型,而不是influxdb里面支持的存储类型。要展示需要display函数转成字符串。
import "strings"
import "array"
import "date"
//正则表达式里面包含abc或bcd或edf:
a = "abcdefg"
b = /abc|bcd|edf/
c = a =~ b
array.from(rows: [{"value":c}])字符串匹配其中内容并提取其中内容:
import "regexp"
import "strings"
import "array"
import "date"
a = "abcdefg"
b = /abc|bcd|edf/
c = regexp.findString(r: b, v: a)//返回字符串里面最左边被匹配到的内容。r:正则表达式,v:要被匹配的内容
array.from(rows: [{"value":c}])字符串转成正则表达式:
import "regexp"
import "array"
a = "abc|bcd"
b = regexp.compile(v:a)
c = "abcdef"
array.from(rows: [{"value":c =~ b}])整数:
整数和无符号整数的区别是整数可以带正负号。flux语言里面的整数由8个字节表示,因此取值范围是2^63-1~2^63-1。
其他类型与整数的转换:
字符串转整数:
字面值必须是数字。
import "array"
a = int(v: "123")
array.from(rows: [{value: a}])小数转整数:
只保留整数部分(即截断)。
import "array"
a = int(v: 12.8)
array.from(rows: [{value: a}])如果要四舍五入:
import "math"
import "array"
a = math.round(x: 12.5)//返回结果是浮点数
b = int(v: a)//转换成整数
array.from(rows: [{value: b}])整数的16进制表示:
import "contrib/bonitoo-io/hex"
import "math"
import "array"
a = hex.int(v: "a")//传入参数:表示了16进制数字的字符串。在16进制里面a表示10
b = hex.int(v: "a0")//=160
array.from(rows: [{value: a}])无符号整数:
范围:0~2^64-1
声明无符号整数:
import "contrib/bonitoo-io/hex"
import "math"
import "array"
a = uint(v: 123)
array.from(rows: [{value: a}])由于整数最大只能是2^63-1,为了让v的值可以是2^64-1,使用字符串方式声明:
import "contrib/bonitoo-io/hex"
import "math"
import "array"
a = uint(v: "9223372036854775808")
array.from(rows: [{value: a}])浮点数:
用8个字节表示。在flux语言里面只有float这个类型。
科学计数法:
import "array"
a = float(v: "1.2345e+10")//e表示10的几次方
//正无穷大表示:+Inf
//不是一个数字:Nan
array.from(rows: [{value: a}])null:
flux语言不支持null类型。解决方法:使用debug函数:
import "array"
import "internal/debug"//前端里面没有定义要自己导包
a = debug.null(type:"string")//得到一个string类型的null值
b = exists a//判断a是不是null。是返回false
array.from(rows: [{value: b}])4种复合类型
Record(记录):
一个记录是一堆键值对的集合,其中键必须是字符串,值可以是任意类型,在键上没 有空白字符的前提下,键上的双引号可以省略。
import "array"
a = {"name":"tom",age:18,"x y":"20,40"}//record不能直接当做列里面的数据
b = {"name":"jack",age:18,"x y":"20,40"}
//array.from(rows: [{value: display(v:a)}])//因此使用display函数
array.from(rows:[a,b])
因此flux里面的表是由多个record构成的。
访问 Record 里面的数据:
import "array"
a = {"name":"tom",age:18,"x y":"20,40"}
b = {"name":"jack",age:18,"x y":"20,40"}
//1.通过 .属性 的方式
c1 = b.name
//2.["键名"]
c2 = b["age"]
//record里面的属性不能进行动态访问
key_name = "age"
c3 = b[key_name]
array.from(rows: [{value: c}])判断2个record是否相等:
import "array"
a = {"name":"tom",age:18,"x y":"20,40"}
b = {"name":"jack",age:18,"x y":"20,40"}
c = a == b
array.from(rows: [{value: c}])拓展一个 record:
import "array"
a = {"name":"tom",age:18,"x y":"20,40"}
b = {"name":"jack",age:18,"x y":"20,40"}
c = {b with age:19,height:111}
array.from(rows: [c])记录嵌套:
嵌套在flux语法里面支持,在返回结果里面不支持
import "array"
a = {
name:"tom",
address:{
country:"china"
}
}
array.from(rows: [c])记录嵌套可以用来做HTTP请求的JSON数据体。
c = json.encode(v:a)访问属性:
d = a.address.countryDictionary(字典):
字典和记录很像,但是 key-value 上的要求有所不同。一个字典是一堆键值对的集合,其中所有键的类型必须相同,且所有值的的类型必须相同,但字典的键不要求一定是字符串。 在语法上,dictionary 需要使用方括号[ ]声明,键的后面跟冒号(:)键值对之间需要使 用英文逗号( , )分隔。
插入/覆盖/删除键值对 :
import "dict"
import "array"
a = ["name":"tony","age":"18"]
b = dict.insert(dict:a,key:"height",value:"200")
c = dict.insert(dict:a,key:"age",value:"19")
d = dict.remove(dict:a,key:"height")
array.from(rows: [{"value":display(v:b)}])从字典里取值:
import "dict"
import "array"
a = ["name":"tony","age":"18"]
b = dict.get(dict:a,key:"age",default:"244")//如果字典里面没有age这个键,要用默认值替代
array.from(rows: [{"value":display(v:b)}])字典可以动态访问:
import "dict"
import "array"
a = ["name":"tony","age":"18"]
key_name = "age"
b = dict.get(dict:a,key:key_name,default:"244")//如果字典里面没有age这个键,要用默认值替代
array.from(rows: [{"value":display(v:b)}])字典的用法:映射
Array(数组):
数据是一个由相同类型的值构成的有序序列。 在语法上,数组是用方括号[ ]起来的一堆同类型元素,元素之间用英文逗号( , )分隔, 并且类型必须相同。
import "dict"
import "array"
a = ["a","b","c"]
//数组内容是record:
//注意:键一样、值的类型一样才是同类型
b = [{"name":"tom",age:18},{"name":"jack",age:18}]
array.from(rows: [{"value":display(v:a)}])数组操作:
import "dict"
import "array"
a = [1,2,3]
//数组元素的访问:
b = a[0]
c = length(arr: a)
d = contains(value: 1, set: a)
array.from(rows: [{"value":display(v:b)}])function(函数):
import "array"
//乘法运算函数
chengfa = (a,b=100) => a * b
x = chengfa(a:4,b:5)
array.from(rows: [{"value":x}])import "array"
//乘法运算函数
chengfa = (a,b=100) => {
return a * b
}
x = chengfa(a:4,b:5)
array.from(rows: [{"value":x}])flux语言里面,函数也是一个类型,因此可以作为返回值。
类型约束:
自动
flux语言官方文档
flux查询influxdb
from(bucket: "example_query")
|> range(start: -3h)序列、表、表流:
表和表流是flux语言的概念,序列是influxdb的概念,在web端influxdb中的数据以表的形式展示。为了flux中的表和influxdb中的序列能够吻合,创建了表流的概念,可以理解为由表形成的数组。

 表流(stream)也可以按照重新定义进行分组
表流(stream)也可以按照重新定义进行分组
filter维度过滤:
from(bucket: "example_query")
|> range(start: -26h)
|> filter(fn: (r) => r["_measurement"]=="car", onEmpty: "keep")//影响的是table的编号:是把过滤掉的当做没有还是保留
|> filter(fn: (r) => (r["code"]=="02"))//用 r["code"] 访问属性类型转换函数与下划线字段:
通过行协议向example_query中写入:

查询,
from(bucket: "example_query")
|> range(start: -5h)
|> filter(fn: (r) => r["_measurement"]=="test")发现filed3的value类型被转换成了浮点数:

因此,为了不出现这种情况要对field进行过滤,让_value类型保证统一,
from(bucket: "example_query")
|> range(start: -5h)
|> filter(fn: (r) => r["_measurement"]=="test")
|> filter(fn: (r) => r["_field"]=="field1")//要让_value类型保证统一
类型转换:
让10转成整数类型:
from(bucket: "example_query")
|> range(start: -5h)
|> filter(fn: (r) => r["_measurement"]=="test")
|> filter(fn: (r) => r["_field"]=="field2")//要让_value类型保证统一
|> toInt()约定:
上面的toInt函数没有指定任何字段,直接对value这个字段进行了类型转换的处理。这种函数类型称之为约定,使用下划线开头的字段都带有某种约定。
map函数:
遍历表流里面每一条数据
import "array"
//手动创建一个表流:
array.from(rows: [{"name":"tony"},{"name":"jack"}])
//返回一个record类型
// |> map(fn: (r)=>({"name":"tony2"}))
|> map(fn: (r)=>{
return if r["name"] == "tony" then {"_name":"tony不是jack"} else {"_name":"jack不是tony"}
})自定义管道函数:
big100 = (table=<-) => {
return table
|> map(fn: (r)=>({r with "_value":r["_value"]*100.0}))
}
chengfa = (x,y) => x*y
from(bucket:"test_init")
|>range(start:-1h)
|>filter(fn:(r)=>r["_measurement"]=="go_goroutines")
|>big100()big100 = (table=<-,x=100.0) => {
return table
|> map(fn: (r)=>({r with "_value":r["_value"]*x}))
}
chengfa = (x,y) => x*y
from(bucket:"test_init")
|>range(start:-1h)
|>filter(fn:(r)=>r["_measurement"]=="go_goroutines")
|>big100(x:2.0)这里需要强调的是,管道函数的第一个参数必须写成 table=<-,它表示通过管道符输 入进来的表流数据,需要注意,table 并不一定写成 table 但是=<-的格式绝对不能变。
window和aggregateWindow:
开窗改变了原有序列,把整个表流按照窗口的开始时间和截止时间进行了重新分组。
from(bucket: "example02")
|> range(start: -10m)
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["_field"] == "usage_user")
//开窗改变了原有序列,把整个表流按照窗口的开始时间和截止时间进行了重新分组
|> window(period: 30s)//period:时间间隔间隔,每隔30s开一次窗;every:窗口宽度,默认等于period
//开窗之后可以做聚合操作:
|> max()//默认对value操作aggregateWindow:
aggregateWindow 不会影响原来的序列结构
|> aggregateWindow(period: 30s, every: 30s, fn: max)yield和join:
当 flux 脚本中出现未被赋值给某个变量的表流时,InfluxDB 执行 FLUX 脚本时会自动 帮他们在管道的最后面加上|> yield(name: "_result")函数,yield 函数其实是指定了我们当前 这个表流是整个 FLUX 脚本最后返回的结果,而且这个结果的名字叫"_result"。
from(bucket: "example02")
|> range(start: -10m)
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["_field"] == "usage_user")
|> aggregateWindow(period: 30s, every: 30s, fn: max)
|> yield(name: "tony")
from(bucket: "example02")
|> range(start: -10m)
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["_field"] == "usage_user")
|> aggregateWindow(period: 30s, every: 30s, fn: max)
|> yield(name: "jack")具体见文档。














 6243
6243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









