






目录
概述 :
作者作为遥感专业的学生并且刚接触到python爬虫,刚好可以利用python爬虫的优势解决下数据这个令人头痛的问题。(本代码几乎不用怎么修改就能直接用)
整个代码采用面对对象编程,只用到了Python爬虫一些基本的东西和正则表达式
关于连接,一些脚本或者去下载器直接下载进行, 或者还可以selenium通过浏览器下载
NASA·modis数据:
数据下载地址:
NASA数据连接![]() https://e4ftl01.cr.usgs.gov
https://e4ftl01.cr.usgs.gov
分析获取连接需要的参数:
1、产品(默认参数为MOLT):

2、产品类型:
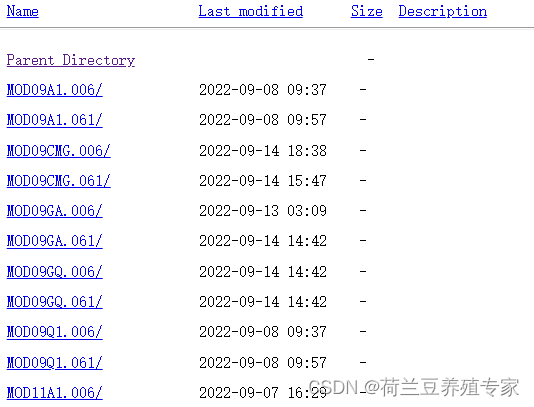
3、时间(使用star_time, end_time 两个参数获取想要的时间段):
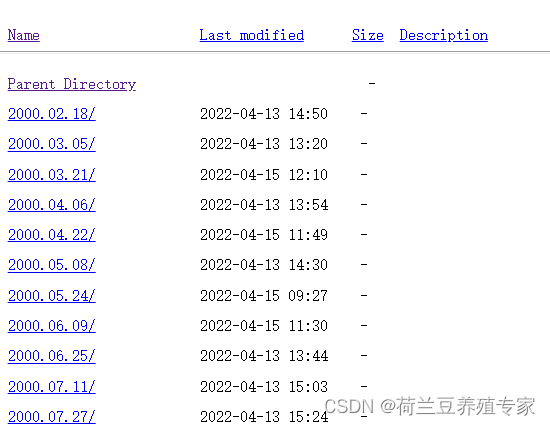
4、条带号(因为条带号在连接中,所以需要使用正则表达式获取指定条带号的连接)

面对对象初始化类,设置参数:
class modis_download(object):
''' 初始化Modis数据下载的参数 '''
def __init__(self,
modis_url='https://e4ftl01.cr.usgs.gov',
tiles=None, # 设置默认条带号
path='MOLT', # 下载地址与产品目录之间的文件夹
product=None, # 产品类型
star_time=None, # 开始时间
end_time=None, # 结束时间
):
self.modis_url = modis_url
self.tiles = tiles
self.path = path
self.product = product
self.star_time = star_time
self.end_time = end_time定义类函数:
时间段获取函数(基本思路:例如:str(2020.06.17) 转为 int(20200617) 通过numpy的where比大小找到时间段:
def path_time_get(self, star_time, end_time):
time_path = self.modis_url + '/' + self.path + '/' + self.product + '/'
response = requests.get(time_path)
html = response.text
regular = r'<a.+?href=\"(\d.*)/\".*>' # 正则表达式
time_list = re.findall(regular, html)
regular_num = u"([^\u0030-\u0039])" # 只保留数字
for i in range(len(time_list)):
time_list[i] = int(re.sub(regular_num, '', time_list[i]))#将time_list str 转为 int
time_list_array = np.array(time_list)
result_time = time_list_array[np.where((time_list_array >= star_time) & (time_list_array <= end_time))]
result_time = result_time.astype(str)
for i in range(len(result_time)):
result_time[i] = result_time[i][:4] + '.' + result_time[i][4:6] + '.' + result_time[i][6:8] # 格式化时间
return result_time爬取连接函数(主要是获取时间段列表后循环每一个时间去拼接连接地址,然后直接get加正则):
def down_load_conect(self, path_time):
# 设置headers
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
# 拼接下载连接
url = self.modis_url + '/' + self.path + '/' + self.product + '/' + path_time + '/'
response = requests.get(url)
html = response.text
regular = f'<a.+?href=\\"(.+{self.tiles}.*.hdf?)\\".*>' # 正则表达式获取指定条带号数据
hdf_list = re.findall(regular, html)
#写文件
print(f'{path_time}总共有{len(hdf_list)}个连接')
a = 0 # 文件计数
for i in hdf_list:
url_download = url + i
with open('data.txt', 'a') as f:
f.writelines(url_download + '\n')
a += 1
print(f'已经写入{a}个连接')完整代码:
'''****************爬取NASA modis数据**********************
作者:荷兰豆养殖专家
待优化:
1、过程有待简化
2、多条带号、多产品类型一步到位
'''
import requests
import re
import numpy as np
class modis_download(object):
''' 初始化Modis数据下载的参数 '''
def __init__(self,
modis_url='https://e4ftl01.cr.usgs.gov',
tiles=None, # 设置默认条带号
path='MOLT', # 下载地址与产品目录之间的文件夹
product=None, # 产品类型
star_time=None, # 开始时间
end_time=None, # 结束时间
):
self.modis_url = modis_url
self.tiles = tiles
self.path = path
self.product = product
self.star_time = star_time
self.end_time = end_time
# 定义爬取数据的方法
def down_load_conect(self, path_time):
# 设置headers
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
# 拼接下载连接
url = self.modis_url + '/' + self.path + '/' + self.product + '/' + path_time + '/'
response = requests.get(url)
html = response.text
regular = f'<a.+?href=\\"(.+{self.tiles}.*.hdf?)\\".*>' # 正则表达式获取指定条带号数据
hdf_list = re.findall(regular, html)
#写文件
print(f'{path_time}总共有{len(hdf_list)}个连接')
a = 0 # 文件计数
for i in hdf_list:
url_download = url + i
with open('data.txt', 'a') as f: #统一到一个data.txt文件中
f.writelines(url_download + '\n')
a += 1
print(f'已经写入{a}个连接')
# 获取时间
def path_time_get(self, star_time, end_time):
time_path = self.modis_url + '/' + self.path + '/' + self.product + '/'
response = requests.get(time_path)
html = response.text
regular = r'<a.+?href=\"(\d.*)/\".*>' # 正则表达式
time_list = re.findall(regular, html)
regular_num = u"([^\u0030-\u0039])" # 只保留数字
for i in range(len(time_list)):
time_list[i] = int(re.sub(regular_num, '', time_list[i]))#将time_list str 转为 int
time_list_array = np.array(time_list)
result_time = time_list_array[np.where((time_list_array >= star_time) & (time_list_array <= end_time))]
result_time = result_time.astype(str)
for i in range(len(result_time)):
result_time[i] = result_time[i][:4] + '.' + result_time[i][4:6] + '.' + result_time[i][6:8] # 格式化时间
return result_time
def main_get(self):
time_list = self.path_time_get(self.star_time, self.end_time)
for i in time_list:
self.down_load_conect(i)
print('写入完成!')
if __name__ == '__main__':
#根据需要修改参数,以下为参数格式参考
download = modis_download(product='MOD13Q1.061', star_time=20190218, end_time=20190306, tiles='h26v06')
download.main_get()















 7407
7407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









