







目录
字符串离散化:
对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
思路:重新构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1
import pandas as pd
import numpy as np
file_path = "./IMDB-Movie-Data.csv"
df = pd.read_csv(file_path,delimiter=",")
#将电影分类这一列取出来
df1 = df["Genre"]
print(df1)
print("*"*100)
#将每个电影类型转换成列表形式
temp_list = df["Genre"].str.split(",").tolist()
print(temp_list)
对电影类型去重
genre_list = list(set([j for i in temp_list for j in i]))#去重
print(genre_list)
构造全为0,行数为电影个数,列数为电影类型个数的DataFrame
#构造全为0的数组(np.zeros(行数,列数))
df_0 = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
print(df_0)
出现类型的电影修改为1
#给每个电影出现类型的位置将0修改为1(df.shape[0]表示电影总数)
for i in range(df.shape[0]):
# for j in temp_list[i]:
# df_0.loc[i,j]=1
#注释掉的两行等价于
#即取一行多列,df_0[i,[" Romance"," War","Horror"]]
df_0.loc[i,temp_list[i]]=1
print(df_0)
本剧电影类型统计电影数
#统计每个分类的电影的数量和
genre_sum = df_0.sum(axis=0)#行方向上的统计求和
print(genre_sum)按照统计结果排序
#排序
genre_count = genre_count.sort_values(ascending=False)
print(genre_count)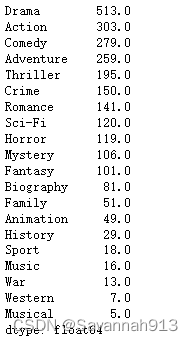
绘制条形图
绘制条形图
plt.figure(figsize=(20,8),dpi=80)
_x = genre_count.index
_y = genre_count.values
plt.barh(range(len(_x)),_y)
plt.yticks(range(len(_x)),_x)
plt.show()
完整代码
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = "./IMDB-Movie-Data.csv"
df = pd.read_csv(file_path,delimiter=",")
#将电影分类这一列取出来
df1 = df["Genre"]
#将每个电影类型转换成列表形式
temp_list = df["Genre"].str.split(",").tolist()
genre_list = list(set([j for i in temp_list for j in i]))#去重
#构造全为0的数组(np.zeros(行数,列数))
df_0 = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
#给每个电影出现类型的位置将0修改为1(df.shape[0]表示电影总数)
for i in range(df.shape[0]):
# for j in temp_list[i]:
# df_0.loc[i,j]=1
#注释掉的两行等价于
#即取一行多列,df_0[i,[" Romance"," War","Horror"]]
df_0.loc[i,temp_list[i]]=1
#统计每个分类的电影的数量和
genre_count = df_0.sum(axis=0)#行方向上的统计求和
#排序
genre_count = genre_count.sort_values()
#绘制条形图
plt.figure(figsize=(20,8),dpi=80)
_x = genre_count.index
_y = genre_count.values
plt.barh(range(len(_x)),_y)
plt.yticks(range(len(_x)),_x)
plt.show()
数据合并
按照行索引合并join
join:默认情况下他是把行索引相同的数据合并到一起,
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#index表示的是列标签,columns表示的是行标签
df1 = pd.DataFrame(np.ones((2,4)),index=["A","B"],columns=list("abcd"))
print(df1)
df2 = pd.DataFrame(np.ones((3,3)),index=["A","B","C"],columns=list("xyz"))
print(df2)
print("*"*100)
#用.join将两个表连接起来
print("df1.join(df2)")
print(df1.join(df2))
print("df2.join(df1)")
print(df2.join(df1)) 
显然,df1.join(df2)的话总是以df1的index为总体的index,在df1的基础上加上df2
按照列索引合并merge
merge:按照指定的列把数据按照一定的方式合并到一起,
内连接
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#index表示的是列标签,columns表示的是行标签
df1 = pd.DataFrame(np.ones(((3,3))),index=["A","B","C"],columns=list("nmx"))
print("df1",df1)
df2 = pd.DataFrame(np.ones((3,3)),index=["A","B","C"],columns=list("xyz"))
print("df2",df2)
df3 = pd.DataFrame(np.zeros(((3,3))),index=["A","B","C"],columns=list("nmx"))
df3.loc["A","x"]=1
print("df3",df3)
print("*"*100)
#merge内连接(交集∩)默认情况下merge做得是内连接
print("内连接","两个df在x列有一样数值","df1.merge(df2,on=x)")
print(df1.merge(df2,on="x"))#on表示按照哪一列连接
print("内连接","两个df在x列存在不一样的数值","df1.merge(df3,on=x)")
print(df1.merge(df3,on="x"))
外连接,左连接,右连接
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#index表示的是列标签,columns表示的是行标签
df1 = pd.DataFrame(np.ones(((3,3))),index=["A","B","D"],columns=list("nmx"))
print("df1",df1)
df2 = pd.DataFrame(np.zeros((3,3)),index=["A","K","C"],columns=list("xyz"))
print("df2",df2)
df3 = pd.DataFrame(np.zeros(((3,3))),index=["A","B","C"],columns=list("nmx"))
df3.loc["A","x"]=1
print("df3",df3)
print("*"*100)
#外连接需要参数how="outer",内连接时,how="inner"(默认)外连接取并集∪
print(df1.merge(df2,on="x",how="outer"))
#一个表中有,另一个表没有,且两个表数值不完全一样,用NaN表示
#左连接,列根据df1的列来,即左边为准NaN补全
print("左连接")
print(df1.merge(df2,on="x",how="left"))
#右连接,列根据df2的列来,即右边为准NaN补全
print("右连接")
print(df1.merge(df2,on="x",how="right"))
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









