







需要项目源码可私信博主!!!
技术概述
图书推荐部分采用传统的机器学习,包括基于内容的推荐算法和基于用户的协同过滤,设计混合推荐策略,将以上算法推荐结果加权后综合权值进行推荐,将代码部分封装为python脚本后由后端调用其服务,系统整体技术栈为Spring Boot + Vue + MySQL。
功能模块
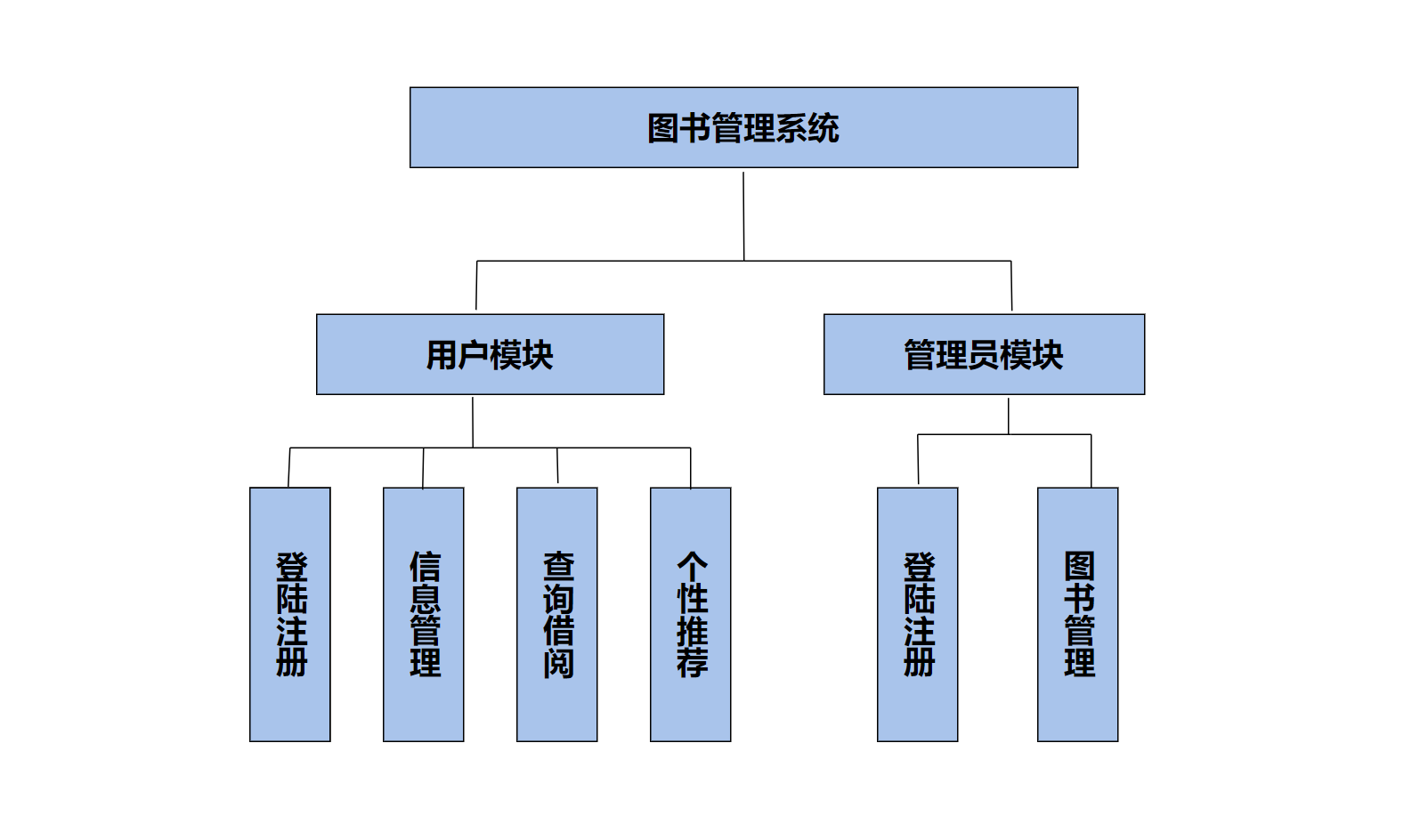
推荐算法
数据来源
此次图书数据集采用百度飞桨官网提供的公开数据集---豆瓣图书数据集
豆瓣图书数据集![]() https://aistudio.baidu.com/datasetdetail/101247其中包含3张表:用户信息表、图书信息表、用户评分表
https://aistudio.baidu.com/datasetdetail/101247其中包含3张表:用户信息表、图书信息表、用户评分表
用户信息表如下所示,一共278858行数据

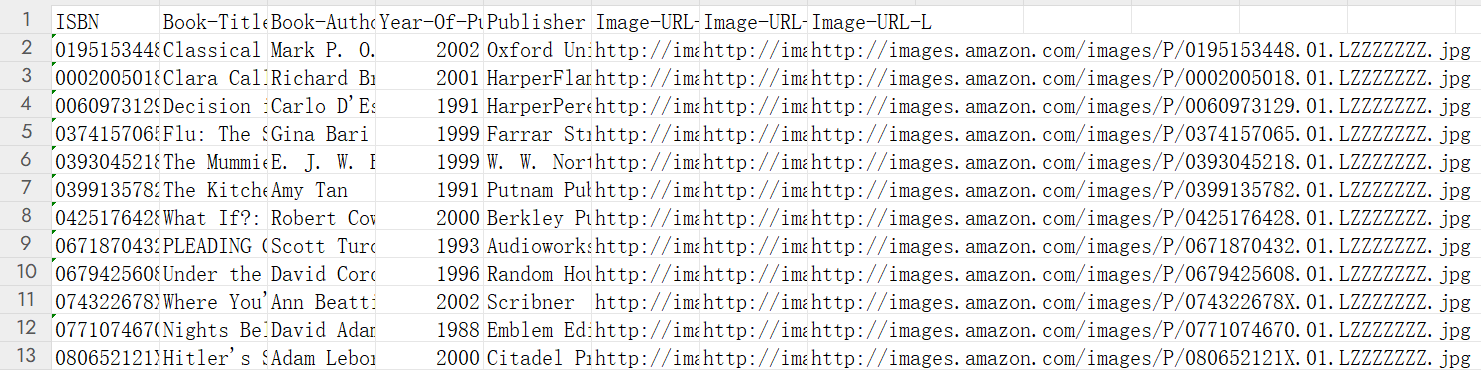
图书信息表如下所示,一共271360行数据
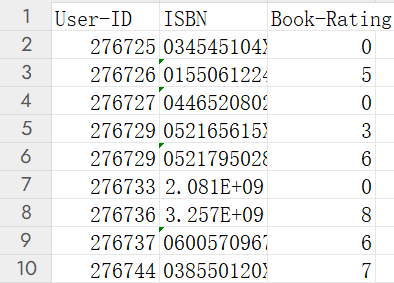
用户评分表如下所示,一百万行数据以上
数据预处理
def _load_and_preprocess_data(self):
//读取用户评分表
ratings = self._optimized_read_csv(
self.ratings_path,
{'User-ID': 'category', 'ISBN': 'category', 'Book-Rating': 'int8'},
['User-ID', 'ISBN', 'Book-Rating']
)
//评分数据量过大,只读取20%
selected_users = ratings['User-ID'].unique()[:len(ratings['User-ID'].unique()) // 20]
self.ratings = ratings[ratings['User-ID'].isin(selected_users)]
//图书信息表有选择地读取数据列
books = self._optimized_read_csv(
self.books_path,
{'ISBN': 'category', 'Book-Title': 'object', 'Book-Author': 'object',
'Year-Of-Publication': 'object', 'Publisher': 'object', 'Image-URL-M': 'object'},
['ISBN', 'Book-Title', 'Book-Author', 'Year-Of-Publication', 'Publisher', 'Image-URL-M']
)
//图书出版年份进行数值转换
books["Year-Of-Publication"] = pd.to_numeric(books["Year-Of-Publication"], errors='coerce')
self.books = books.dropna(subset=["Year-Of-Publication"])
//提取图书标题特征,形成图书标题特征矩阵
vectorizer = TfidfVectorizer(max_features=100)
book_title_features = vectorizer.fit_transform(self.books["Book-Title"])
//对图书信息的作者和出版商进行独热编码,形成作者出版商特征矩阵
encoder = OneHotEncoder(handle_unknown="ignore")
author_publisher_features = encoder.fit_transform(self.books[["Book-Author", "Publisher"]])
//对出版年份进行标签化处理
bins = [0, 1950, 1980, 2000, 2020]
labels = ["pre-1950", "1950-1980", "1980-2000", "2000-2020"]
self.books["Year-Bin"] = pd.cut(self.books["Year-Of-Publication"], bins=bins, labels=labels)
//出版年份独热编码,形成年份特征矩阵
year_features = pd.get_dummies(self.books["Year-Bin"], sparse=True)
//合并所有特征矩阵并进行降维处理
book_features = hstack([book_title_features, author_publisher_features, year_features])
svd = TruncatedSVD(n_components=500, random_state=42)
self.book_features_svd = svd.fit_transform(book_features)基于内容的推荐算法
基于内容的推荐算法主要依赖于用户感兴趣的图书信息进行推荐。这种算法的优势很大,一方面,推荐结果具备出色的可解释性,能够清晰地向用户阐释推荐某物品的具体缘由;另一方面,在处理新物品时表现良好,即便新物品尚未积累大量用户交互数据,凭借其自身特征也能快速融入推荐体系,有效解决物品冷启动难题。
但只使用基于内容的推荐算法仍存在一些问题,一是在系统内新注册的用户,还未产生足够的偏好信息,在内容推荐算法难以实现有效推荐的特定应用场景里,本文面临的典型挑战是推荐系统领域的用户冷启动问题,针对这个问题,本文运用基于用户的协同过滤算法来解决,该算法的具体应用机制会在下一章节详细说明。另外当系统处理海量物品数据和高维特征时,此算法在计算物品相似度与生成用户推荐列表过程中会产生巨大计算开销,导致时间复杂度呈指数级增长,使得推荐效率大幅降低,本文创新性地引入Annoy索引技术来优化这个性能瓶颈。
Annoy索引作为一种借助树结构实现近似最近邻搜索的算法,其主要借助构建一系列二叉树来对高维空间中的数据点加以组织,在索引构建阶段,Annoy会对数据展开分层划分,每个树节点都代表空间中的一个区域,借助持续递归划分空间的方式,将数据点分配至对应的节点当中。而这种结构在执行最近邻搜索时,可避免遍历整个数据集,而是从根节点出发,依据目标节点与节点区域的相对位置,迅速向下搜索可能包含最近邻的子树,如此便有效减少了搜索范围以及计算量,较大降低了计算复杂度。
//建立Annoy索引
def _build_annoy_index(self):
index_file = os.path.join(os.path.dirname(__file__), "index.ann")
if not os.path.exists(index_file):
def build_annoy_index(features, n_trees=5):
dim = features.shape[1]
t = AnnoyIndex(dim, 'angular')
for i in range(features.shape[0]):
t.add_item(i, features[i])
t.build(n_trees)
return t
self.annoy_index = build_annoy_index(self.book_features_svd)
self.annoy_index.save(index_file)
else:
self.annoy_index = AnnoyIndex(self.book_features_svd.shape[1], 'angular')
self.annoy_index.load(index_file) //借助Annoy索引实现的基于内容的推荐算法
def annoy_based_recommend(self, user_id, n=5):
user_code = self._get_user_code(user_id)
if user_code is None:
print("用户 ID 未找到对应的编码。")
return pd.DataFrame()
user_ratings = self.ratings[self.ratings["User-ID"] == user_id]
rated_book_indices = []
for isbn in user_ratings["ISBN"]:
try:
rated_book_indices.append(self.books[self.books["ISBN"] == isbn].index[0])
except IndexError:
continue
recommended_scores = {}
for book_index in rated_book_indices:
similar_books = self.annoy_index.get_nns_by_item(book_index, n + 1)[1:]
for similar_book in similar_books:
if similar_book not in rated_book_indices:
if similar_book not in recommended_scores:
recommended_scores[similar_book] = 0
recommended_scores[similar_book] += 1
sorted_recommendations = sorted(recommended_scores.items(), key=lambda item: item[1], reverse=True)
top_n_recommendations = sorted_recommendations[:n]
top_n_indices = [index for index, _ in top_n_recommendations]
return self.books.iloc[top_n_indices]基于用户的协同过滤
基于用户的协同过滤算法区别于基于内容的推荐算法,核心在用户,可以通过相似用户群体的行为发掘用户的潜在兴趣,突破内容特征的限制,解决长尾兴趣挖掘。本文通过实施基于用户的协同过滤算法,构建了完整的计算流程。
构建用户物品矩阵
def _build_user_item_matrix(self):
self.user_id_to_code = dict(zip(self.ratings['User-ID'], self.ratings['User-ID'].astype('category').cat.codes))
user_codes = self.ratings['User-ID'].astype('category').cat.codes
isbn_codes = self.ratings['ISBN'].astype('category').cat.codes
self.user_item_matrix = csr_matrix((self.ratings['Book-Rating'], (user_codes, isbn_codes)))图书推荐
def user_based_collaborative_filtering(self, user_id, n=5):
user_code = self._get_user_code(user_id)
if user_code is None:
print("用户 ID 未找到对应的编码。")
return pd.DataFrame()
user_vector = self.user_item_matrix[user_code].toarray().flatten()
similarities = []
for i in range(self.user_item_matrix.shape[0]):
if i != user_code:
other_user_vector = self.user_item_matrix[i].toarray().flatten()
similarity = cosine_similarity([user_vector], [other_user_vector])[0][0]
similarities.append((i, similarity))
similarities.sort(key=lambda x: x[1], reverse=True)
top_similar_users = similarities[:n]
recommended_scores = {}
user_rated_books = set(self.user_item_matrix[user_code].nonzero()[1])
for similar_user, sim in top_similar_users:
similar_user_ratings = self.user_item_matrix[similar_user].nonzero()[1]
for book in similar_user_ratings:
if book not in user_rated_books:
if book not in recommended_scores:
recommended_scores[book] = 0
recommended_scores[book] += sim * self.user_item_matrix[similar_user, book]
sorted_recommendations = sorted(recommended_scores.items(), key=lambda item: item[1], reverse=True)
top_n_recommendations = sorted_recommendations[:n]
top_n_indices = [index for index, _ in top_n_recommendations]
return self.books.iloc[top_n_indices]混合推荐策略
综合上述两种不同的推荐算法,本文采用混合推荐策略,原因在于基于内容的推荐算法可以解决物品冷启动和系统冷启动问题,对新加入的物品友好,正好解决了基于用户的协同过滤在冷启动场景下无效有效推荐的问题,而基于用户的协同过滤可以通过相似用户群体的行为发掘用户的潜在兴趣,可以突破内容特征的限制,解决长尾兴趣挖掘。两种推荐算法相互补充,可以更好的提升推荐效果。
def hybrid_recommend(self, user_id, n=5, content_weight=0.5, cf_weight=0.5):
content_based_rec = self.annoy_based_recommend(user_id, n * 2)
cf_based_rec = self.user_based_collaborative_filtering(user_id, n * 2)
recommendation_scores = {}
for _, row in content_based_rec.iterrows():
isbn = row['ISBN']
if isbn not in recommendation_scores:
recommendation_scores[isbn] = 0
recommendation_scores[isbn] += content_weight
for _, row in cf_based_rec.iterrows():
isbn = row['ISBN']
if isbn not in recommendation_scores:
recommendation_scores[isbn] = 0
recommendation_scores[isbn] += cf_weight
sorted_recommendations = sorted(recommendation_scores.items(), key=lambda item: item[1], reverse=True)
top_n_recommendations = sorted_recommendations[:n]
top_n_isbns = [isbn for isbn, _ in top_n_recommendations]
return self.books[self.books['ISBN'].isin(top_n_isbns)]管理系统
用户模块
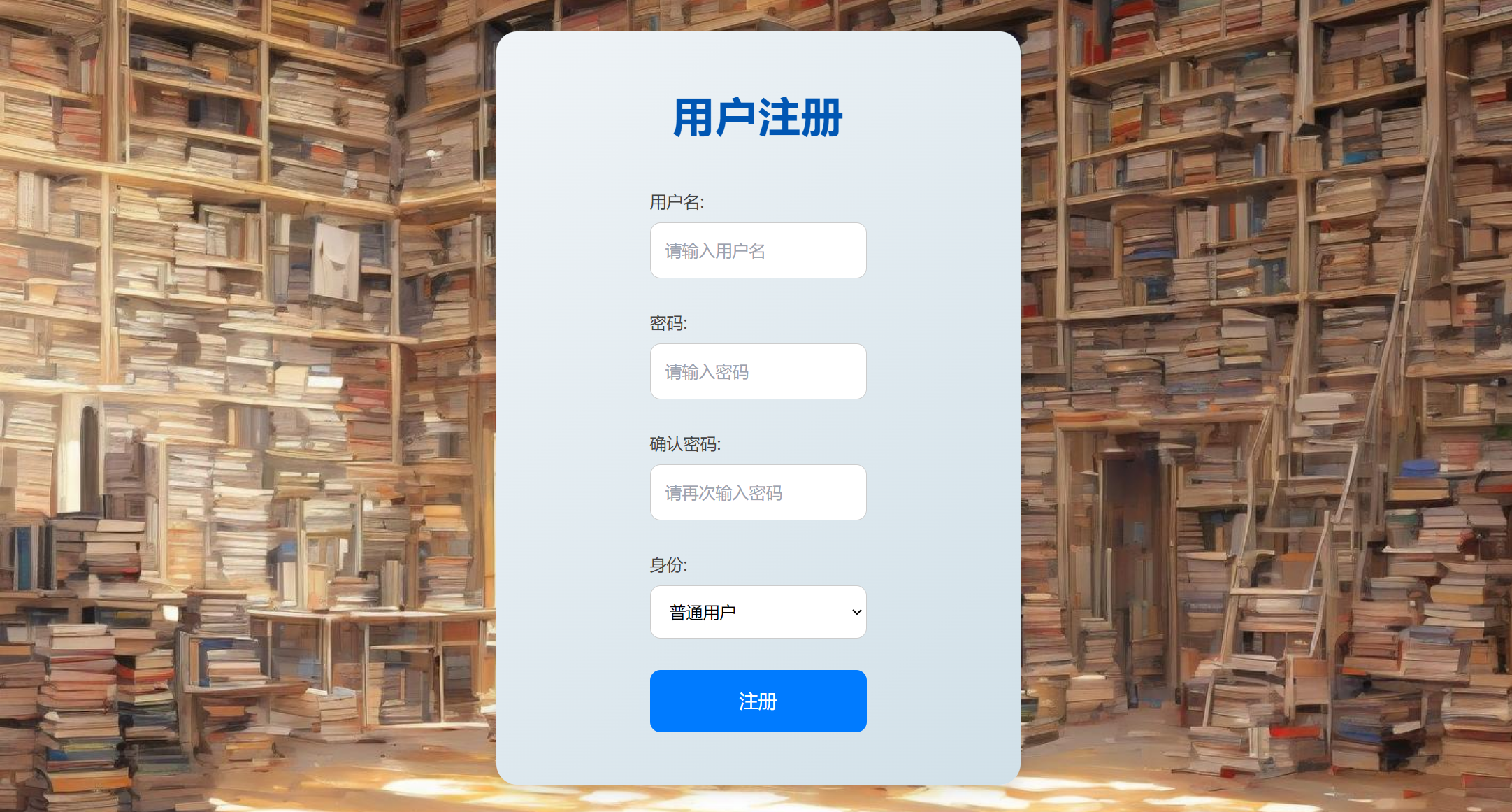
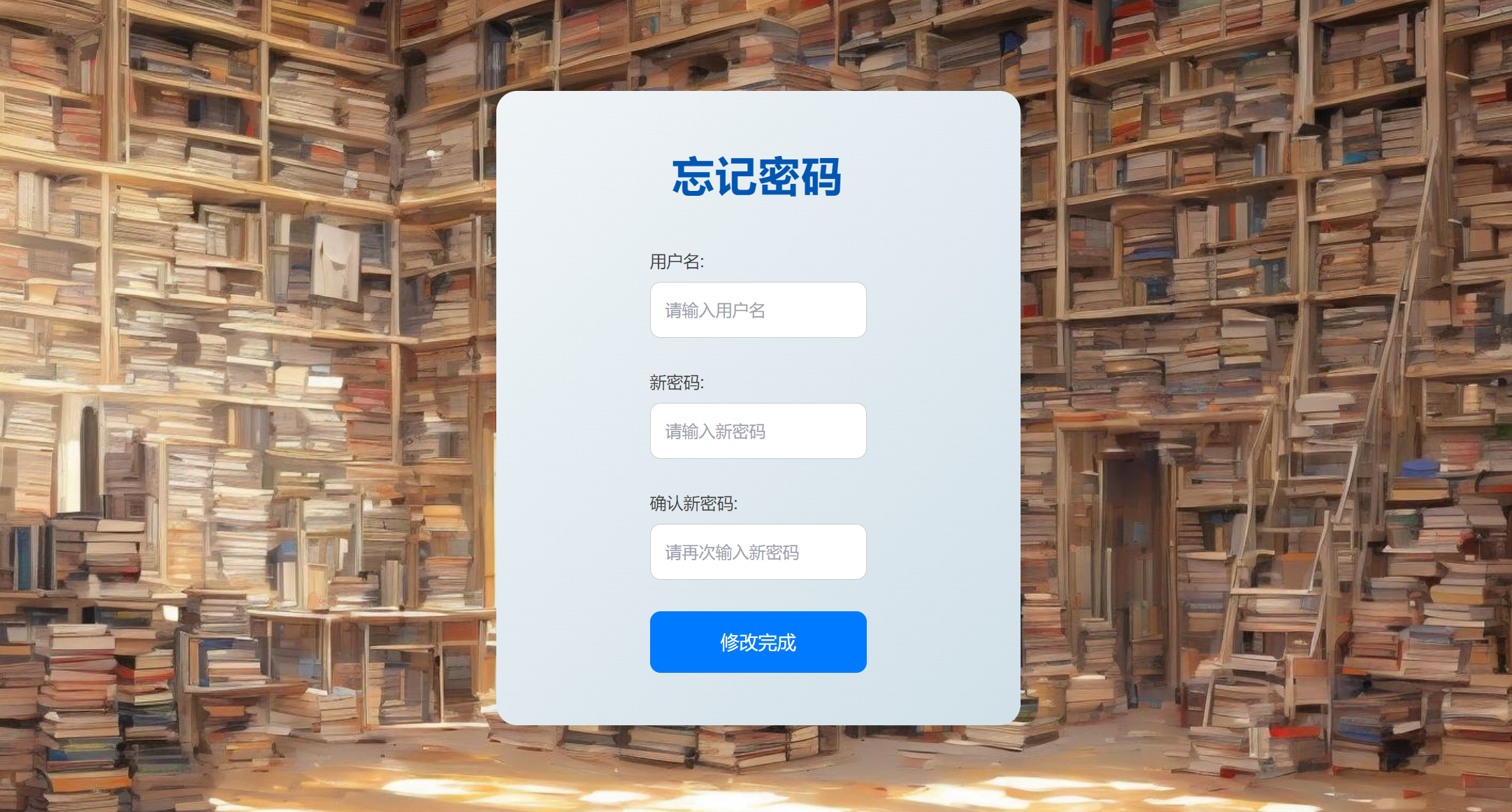
登陆注册:支持不同身份用户登录注册、忘记密码重新修改
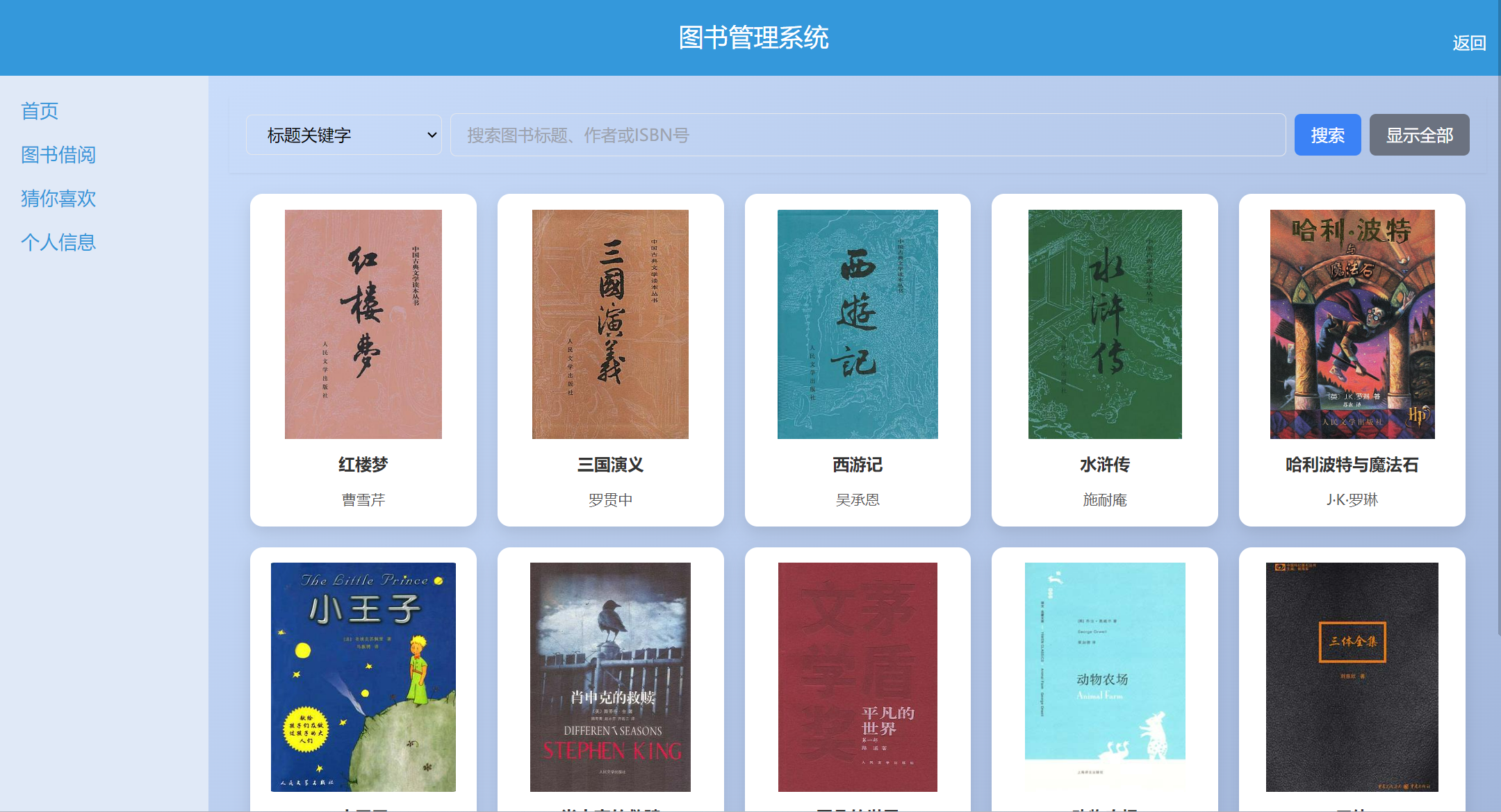
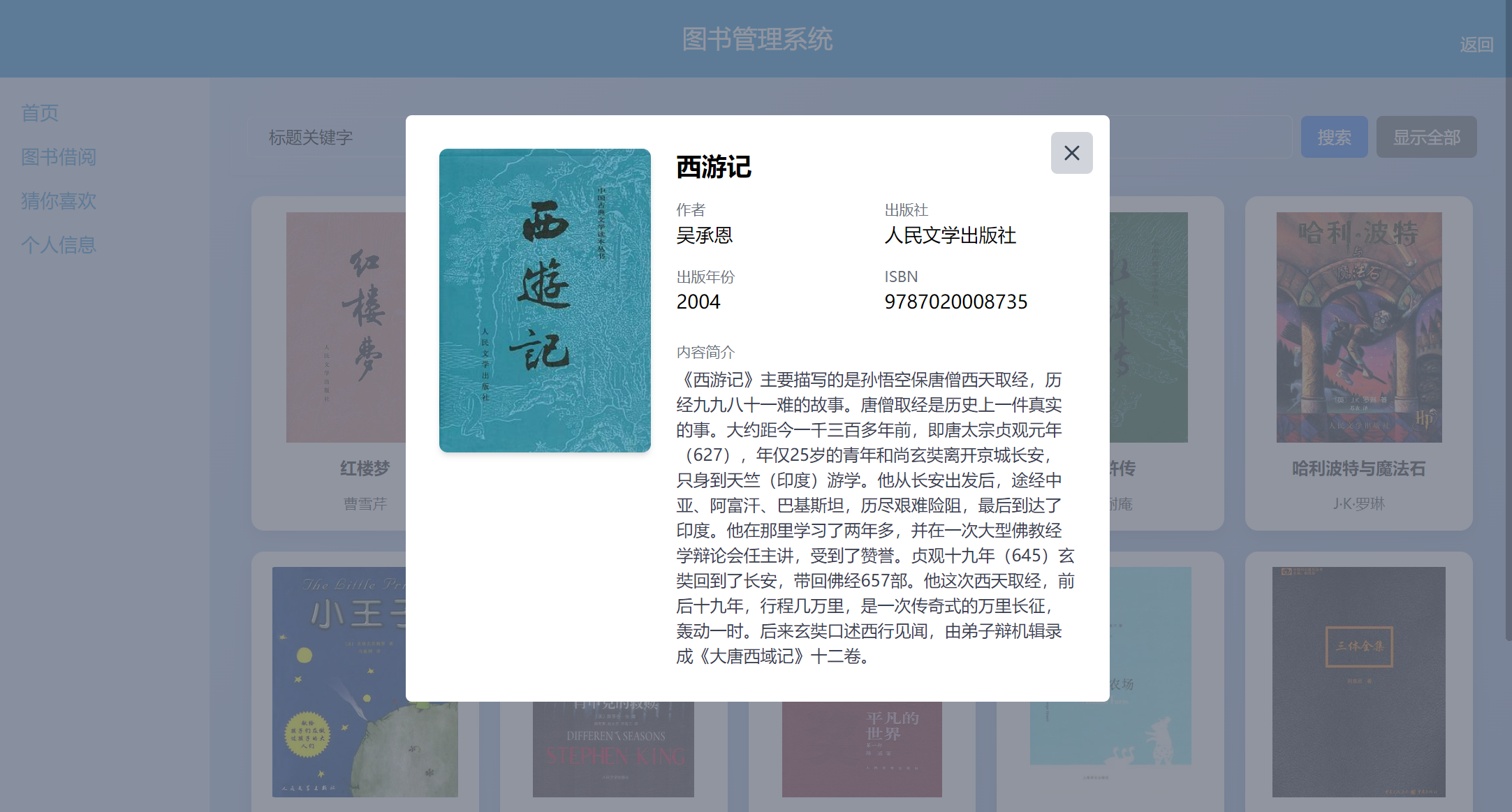
首页展示:支持标题/作者关键字模糊搜索、ISBN搜索,展示图书详情信息
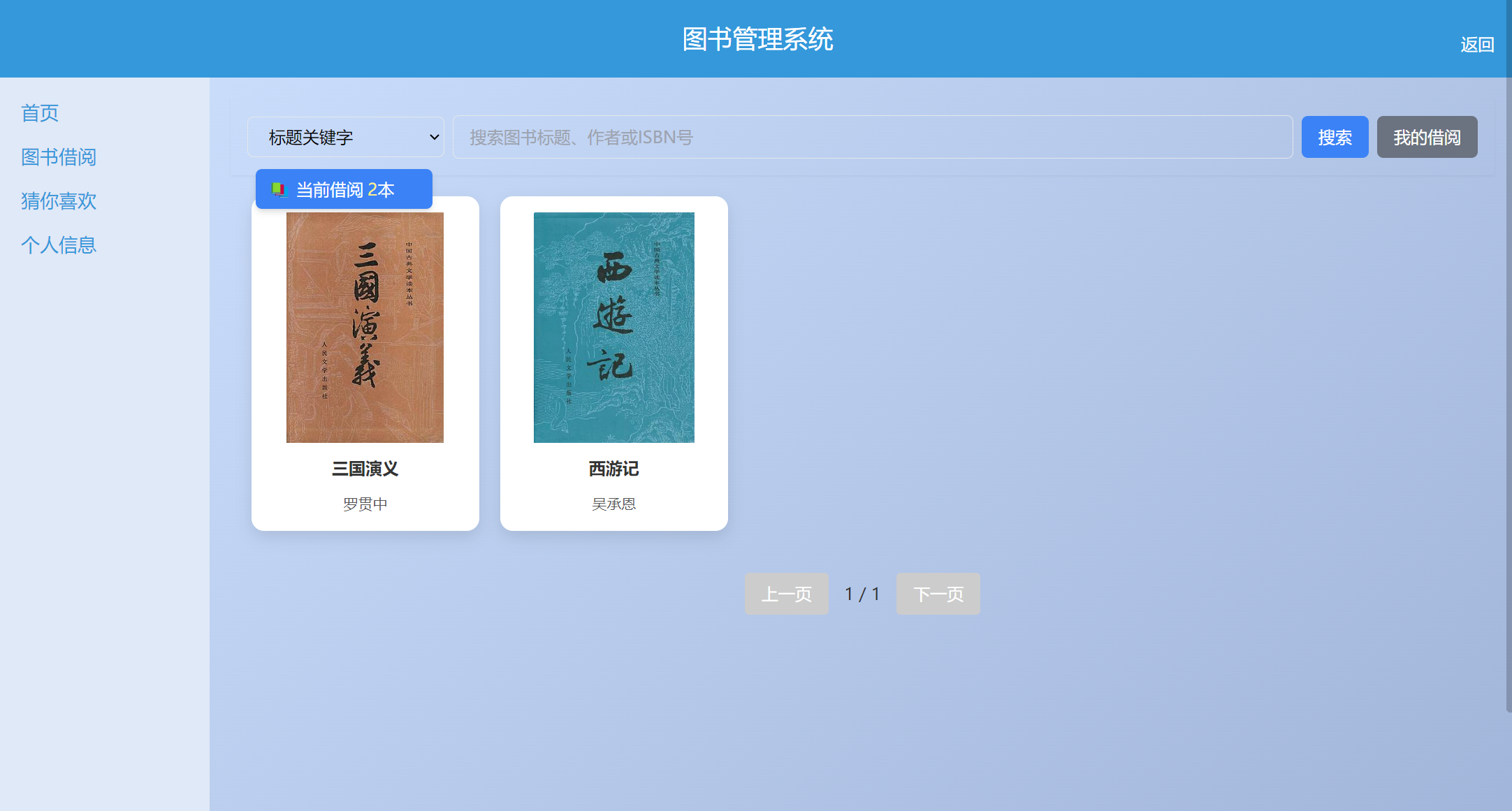
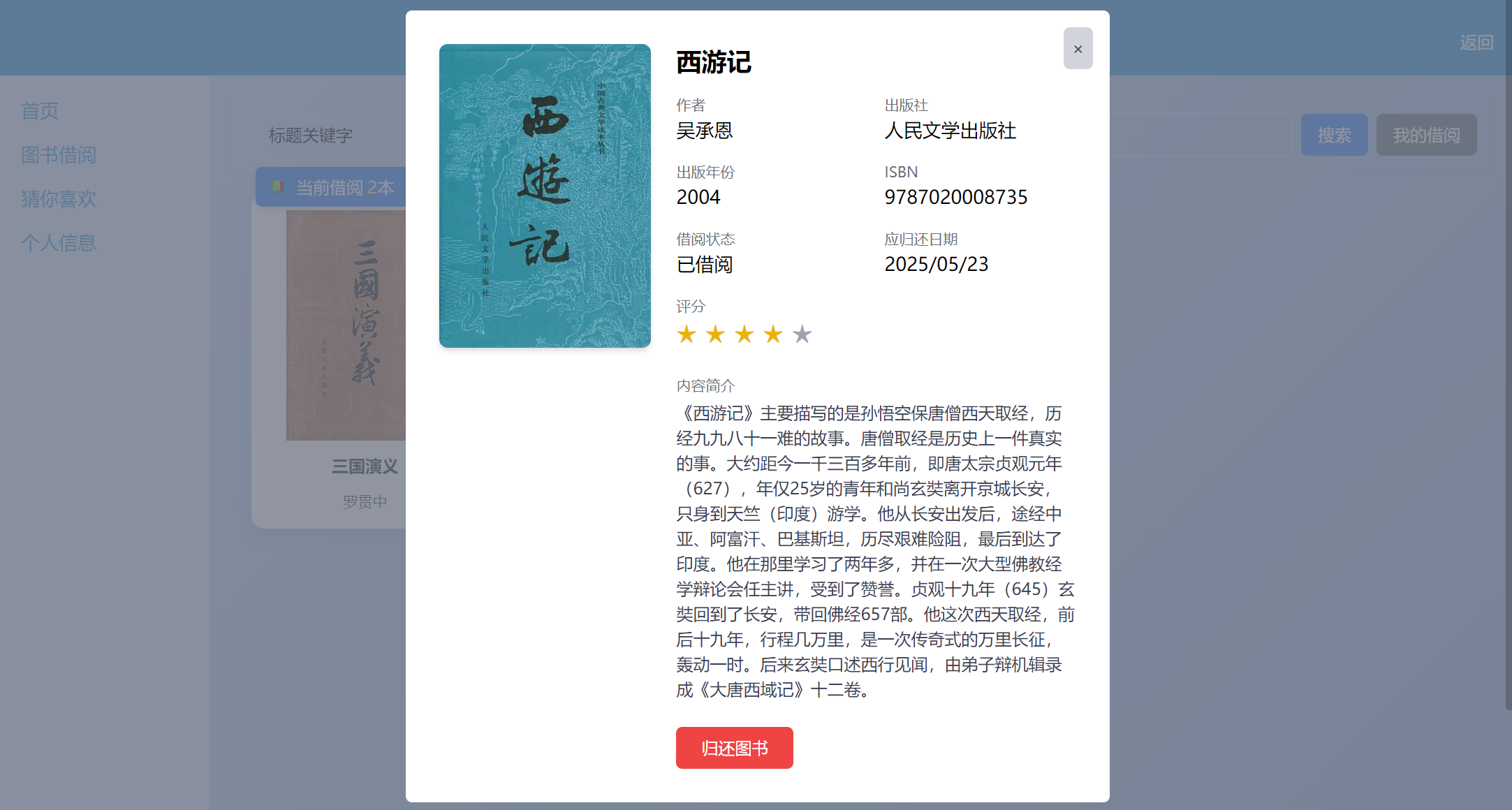
图书借阅:实时展示借阅信息,支持搜索借阅,评分功能
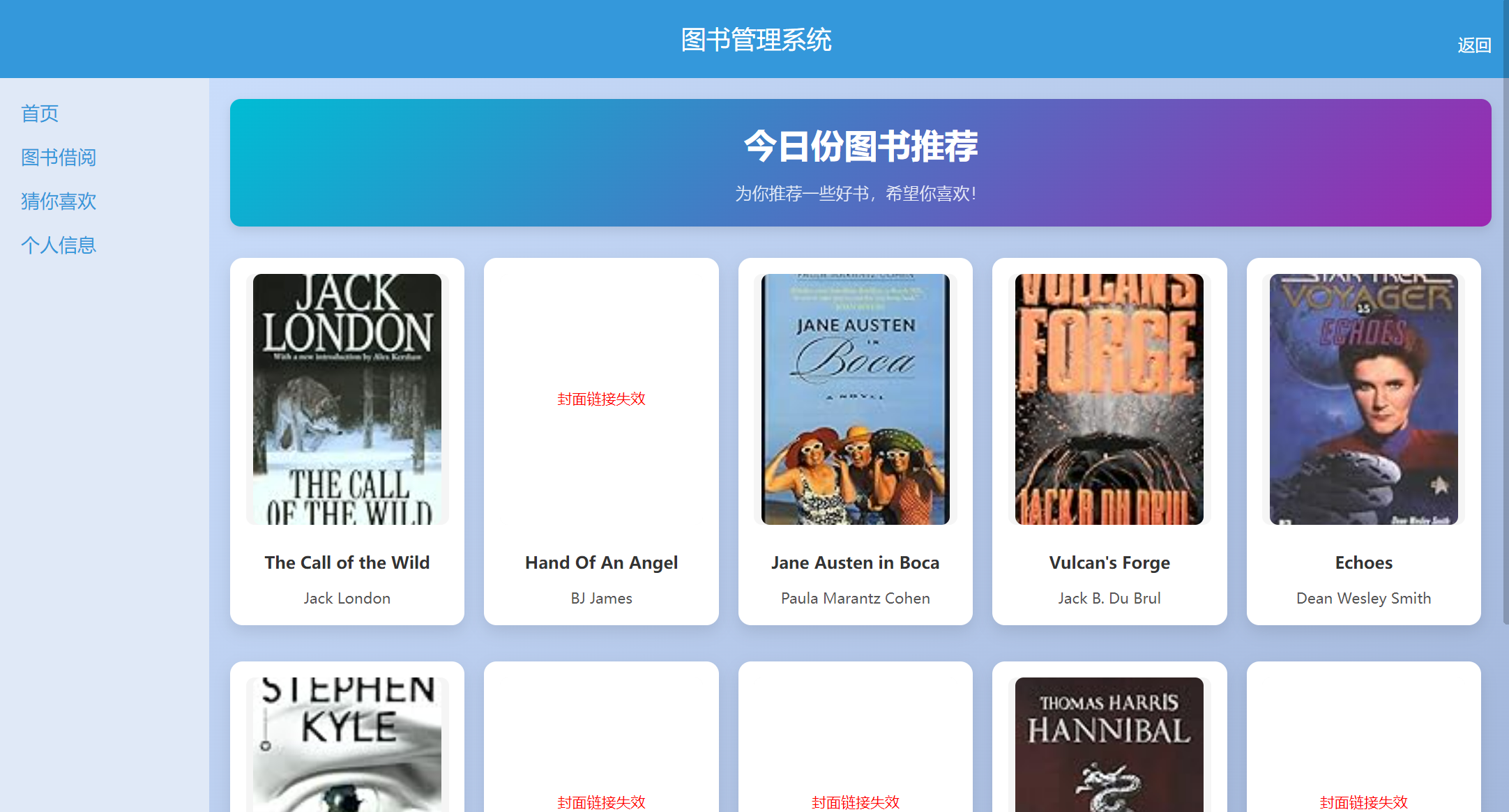
个性推荐:数据集中的封面链接有些已经失效,特加入链接失效判断
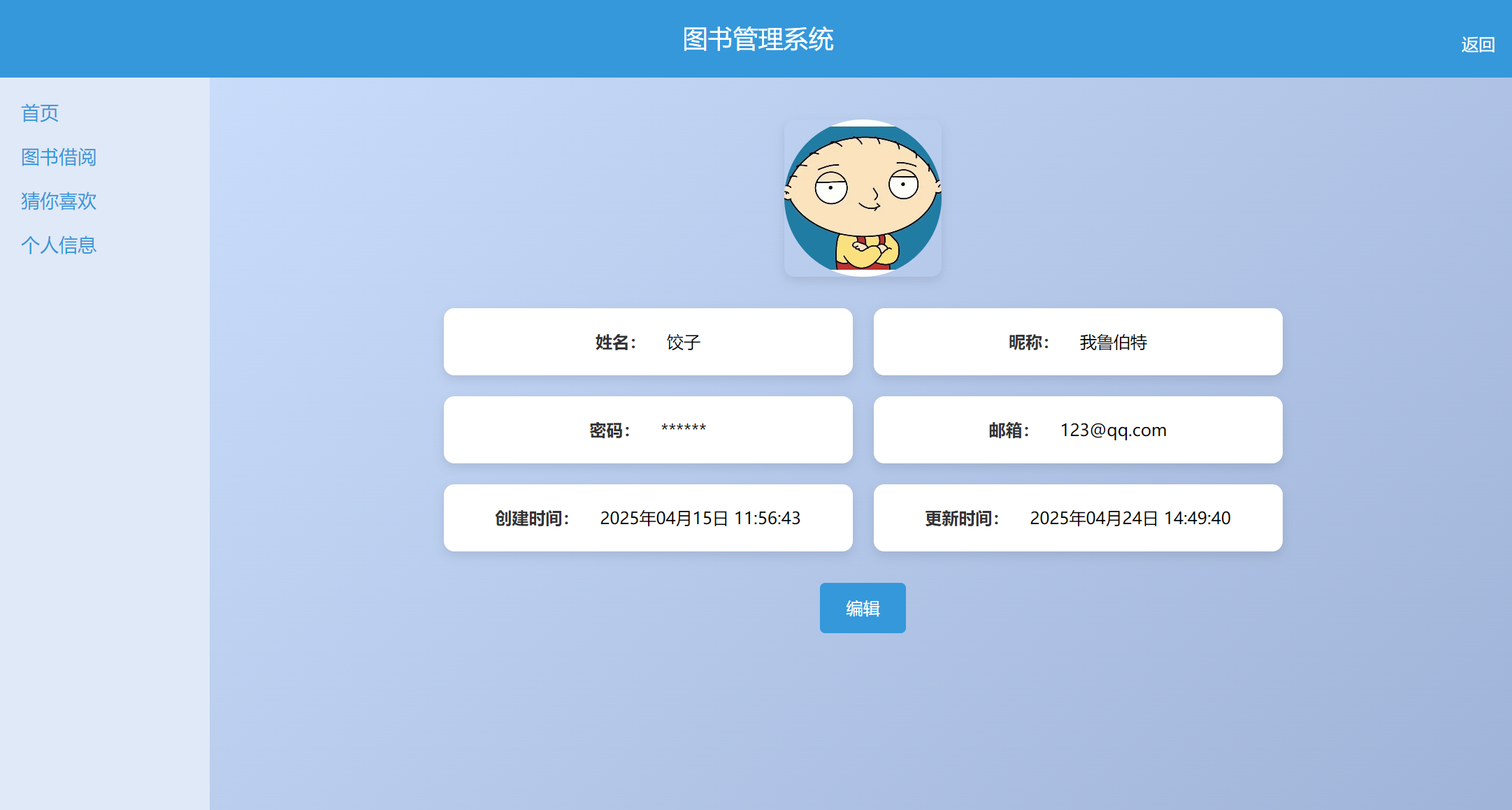
个人信息:支持各类个人信息的修改
管理员模块
登陆注册:同上
图书管理
小结
以上即本项目的全部内容,欢迎各位同学交流讨论,关注我,分享更多新手入门项目


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









