







 本文聚焦于Django的Models模型层。介绍了Django的MVT架构,重点讲解了Models模型层,包括简单上手、注册迁移、字段类型与选项、关联关系等内容,还提及编写自定义字段类型,最后列举了部分模型字段及验证器相关知识。
本文聚焦于Django的Models模型层。介绍了Django的MVT架构,重点讲解了Models模型层,包括简单上手、注册迁移、字段类型与选项、关联关系等内容,还提及编写自定义字段类型,最后列举了部分模型字段及验证器相关知识。
引言
Django 是一个使用 "MVT" 架构的 Web 框架,而不是常见的 "MVC" 架构。MVT 代表着 "Model-View-Template",它在概念上与 "Model-View-Controller"(MVC)有一些相似之处,但有一些不同之处。以下是 Django 中的 MVT 架构的组成部分:
-
Model(模型):
- 模型表示应用程序的数据结构和数据库表格。
- 在 Django 中,模型是 Python 类,通过继承
models.Model类来创建。 - 模型定义了数据库中的表格、字段以及字段之间的关系。它们负责处理数据的存储和检索,以及数据的验证和处理。
- Django 的模型提供了一个对象关系映射(ORM)层,使你可以使用 Python 代码来操作数据库,而不必编写原始的 SQL 查询。
-
View(视图):
- 视图负责处理来自用户的 HTTP 请求,并生成 HTTP 响应。
- 在 Django 中,视图可以是函数或类,它们接受请求并根据请求的内容和参数决定如何响应。
- 视图通常包含业务逻辑,处理数据模型、渲染模板以生成 HTML 输出,并将响应返回给客户端。
-
Template(模板):
- 模板用于定义 HTML 页面的结构和布局,以及如何呈现数据。
- 在 Django 中,模板是包含 HTML 和模板标签的文件,它们可以包含变量、循环、条件语句等,以动态地生成页面内容。
- 模板引擎将模板解释为最终的 HTML,根据视图中传递的数据进行渲染。
虽然 Django 使用 MVT 架构而不是 MVC,但概念上非常相似。主要的区别在于视图(View)和模板(Template)之间的关系。在 Django 中,视图处理请求的逻辑,而模板负责呈现数据。这使得 Django 项目更容易组织和维护,并促进了逻辑和界面的分离。
我们在第一篇中已经简单的了解了其中的M(Model)和V(View),这一篇将会仔细讲解Models模型层。
一,Models 模型层
模型准确且唯一的描述了数据。它包含我们需要储存的数据的重要字段和行为。一般来说,每一个模型都映射一张数据库表。
- 每个模型都是一个 Python 的类,这些类继承 django.db.models.Model
- 模型类的每个属性都相当于一个数据库的字段。
- 利用这些,Django 提供了一个自动生成访问数据库的 API
1.1 简单上手
1.1.1 编写模型类
在我们应用下的models.py中写入我们的模型类。
from django.db import models
# Create your models here.
# 创建我们新闻中的第一个类:新闻种类Category,继承models.Model
class Category(models.Model):
# 类属性,通常需要写入到类的初始化init方法中的,在这里因为继承了models.Model,可以直接进行编写
# 使用的CharField字段也就对应着数据库中的varchar等字段
# max_length最大长度必须要指明,verbose_name是在网站上的展示名,可选
name = models.CharField(max_length=20, verbose_name="新闻种类")
# __str__方法定义了模型的字符串表示,通常在在管理界面中显示模型的对象时使用。
def __str__(self):
return self.name
# 创建我们新闻中的第二个类:新闻News,同样继承models.Model
class News(models.Model):
# 新闻标题,同样使用CharField字段,这里由于不能重复,需要使用unique唯一约束
title = models.CharField(max_length=10, verbose_name="标题", unique=True)
# 新闻正文,这里使用长文本,未来在使用第三方富文本插件后可以进行更改
content = models.TextField(verbose_name="新闻正文")
# 时间,使用DateTimeField字段,auto_now_add=True可以自动添加新闻添加时的时间,不用手动添加
time = models.DateTimeField(auto_now_add=True, verbose_name="时间")
# 新闻种类,联系到Category表,所以使用ForeignKey外键,on_delete=models.CASCADE为级联删除
category = models.ForeignKey(to="Category", on_delete=models.CASCADE)1.1.2 对应数据表结构
Category中的name和News中的title,content,time和category是模型的字段。每个字段都被指定为一个类属性,并且每个属性映射为一个数据库列。创建的数据库模型如下: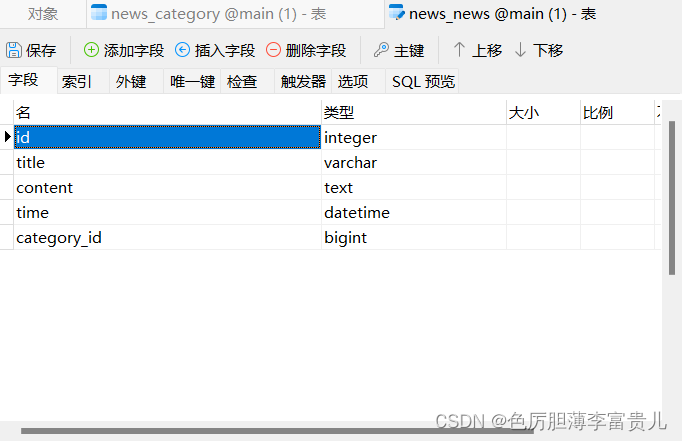
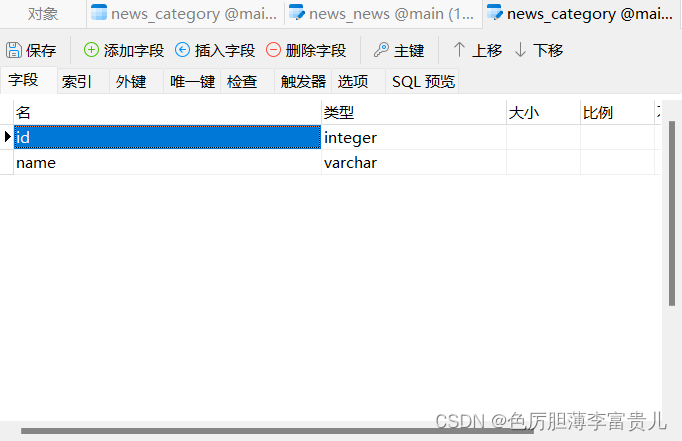
在这里我们可以发现,虽然我们并没有指定表中的 id 也就是主键pk(primary key)列,但是如果我们没有指定主键,Django是会自动帮我们在表中生成的。
说明:
- 我们这些表的名称 news_category和news_news是自动从某些模型元数据中派生出来,也就对应我们的应用名_类名但也可以被改写。
- 一个 id 主键字段会被自动添加,这种行为也可以被改写。
- 本例子中 创建数据表 的语法是 Sqlite3 格式的。值得注意的是,Django 依据在配置文件中指定的数据库后端生成对应的 SQL 语句。
1.2 注册迁移
我们在定义了模型后,需要告诉 Django 所以这时需要几个步骤才能将我们的模型迁移到数据库。
- 注册自己的应用。修改设置文件中的 INSTALLED_APPS ,在这个设置中添加包含 models.py 文件所在的模块(也就是应用)名称。这一步建议在创建完应用就给注册。
- 生成模型的迁移文件:每次修改字段或者添加模型都需要重新生成迁移文件并重新迁移。生成迁移文件命令:python manage.py makemigrations。
- 迁移到数据库:需要在上两步都做完才可以,将数据模型同步到数据库生成对应的表。迁移到数据接口命令:python manage.py migrate。
1.3 字段
Django 中的字段是用于在模型中存储数据的一种机制。字段定义了数据的类型、大小和其他属性。模型中最重要且唯一必要的是数据库的字段定义。字段在类属性中定义。定义字段名时应小心避免使用与 模型 API 冲突的名称, 如 clean,save,or,delete 等。
1.3.1 字段类型
模型中每一个字段都应该是某个 Field 类的实例, Django 利用这些字段类来实现以下功能:
- 字段类型用以指定数据库数据类型(如:INTEGER 对应 models.IntegerField 数据类型,用于存储整数数据。VARCHAR 对应 models.CharField 数据类型,用于存储字符串数据。TEXT 对应 models.TextField 数据类型,用于存储大量字符串数据)。
- 在渲染表单字段时默认使用的 HTML 视图 (如: <input type="text">, <select>)。
- 基本的有效性验证功能,用于 Django 后台和自动生成的表单。
Django 内置了数十种字段类型,我们会在后面进行讲解。如果 Django 内置类型不能满足需求,也可以编写自定义的字段类型。
1.3.2 字段选项
每一种字段都需要指定一些特定的参数(参考 模型字段 )。 例如, CharField (以及它的子类)需要接收一个 max_length 参数,用以指定数据库存储 VARCHAR 数据时用的字节数。
一些可选的参数是通用的,可以用于任何字段类型,详情会在后面进行补充 ,下面介绍一部分经常用到的通用参数:
null:如果设置为 True,当该字段为空时,Django 会将数据库中该字段设置为 NULL。默认为 False 。(数据库是否可以为空)
blank:如果设置为 True,该字段允许为空。默认为 False。(表单是否可以为空)
choices:一系列二元组,用作此字段的选项。如果提供了二元组,默认表单小部件是一个选择框,而不是标准文本字段,并将限制给出的选项。
null和blank:null 选项仅仅是数据库层面的设置,而 blank 是涉及表单验证方面。如果一个字段设置为 blank=True ,在进行表单验证时,接收的数据该字段值允许为空,而设置为 blank=False 时,不允许为空。
choice的选项列表:
一个选项列表:
YEAR_IN_SCHOOL_CHOICES = [
("FR", "Freshman"),
("SO", "Sophomore"),
("JR", "Junior"),
("SR", "Senior"),
("GR", "Graduate"),
]每个二元组的第一个值会储存在数据库中,而第二个值将只会用于在表单中显示。
# 对于一个模型实例,要获取该字段二元组中相对应的第二个值,使用 get_FOO_display() 方法。
from django.db import models
class Person(models.Model):
SHIRT_SIZES = [
("S", "Small"),
("M", "Medium"),
("L", "Large"),
]
name = models.CharField(max_length=60)
shirt_size = models.CharField(max_length=1, choices=SHIRT_SIZES)
# 实例展示
>>> p = Person(name="Fred Flintstone", shirt_size="L")
>>> p.save()
>>> p.shirt_size
'L'
>>> p.get_shirt_size_display()
'Large'
# 也可以使用枚举类以简洁的方式来定义 choices :
from django.db import models
class Runner(models.Model):
MedalType = models.TextChoices("MedalType", "GOLD SILVER BRONZE")
name = models.CharField(max_length=60)
medal = models.CharField(blank=True, choices=MedalType.choices, max_length=10)
default:该字段的默认值。可以是一个值或者是个可调用的对象,如果是个可调用对象,每次实例化模型时都会调用该对象。
help_text:额外的“帮助”文本,随表单控件一同显示。即便你的字段未用于表单,它对于生成文档也是很有用的。
primary_key:如果设置为 True ,将该字段设置为该模型的主键。(在一个模型中,如果没有对任何一个字段设置 primary_key=True 选项。 Django 会自动添加一个 IntegerField 字段,并设置为主键,因此除非想重写 Django 默认的主键设置行为,可以不手动设置主键。)
# 主键字段是只可读的,如果修改一个模型实例的主键并保存,这等同于创建了一个新的模型实例。
from django.db import models
class Fruit(models.Model):
name = models.CharField(max_length=100, primary_key=True)
>>> fruit = Fruit.objects.create(name="Apple")
>>> fruit.name = "Pear"
>>> fruit.save()
>>> Fruit.objects.values_list("name", flat=True)
<QuerySet ['Apple', 'Pear']>unique:如果设置为 True,这个字段的值必须在整个表中保持唯一。
更多的具体的字段与选项会在后面补充。
1.3.3 自动设置主键
默认情况下,Django 给每个模型一个自动递增的主键,其类型在 AppConfig.default_auto_field 中指定,或者在 DEFAULT_AUTO_FIELD 配置中全局指定。
在总应用的settings中可以找到:DEFAULT_AUTO_FIELD = 'django.db.models.BigAutoField'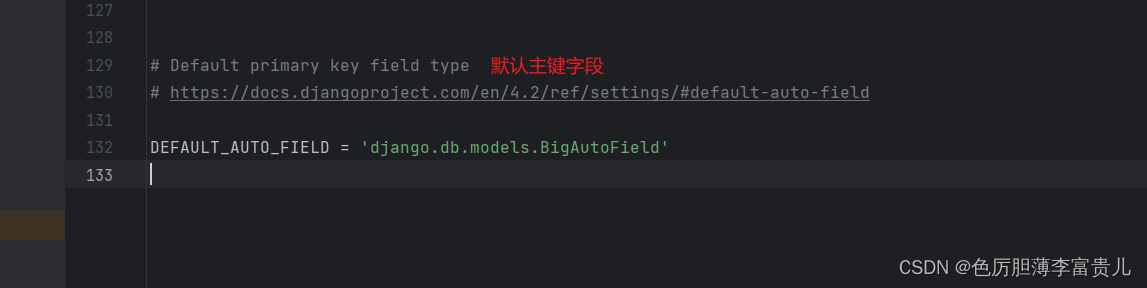
如果想自己指定主键, 可以想要设置为主键的字段上设置参数 primary_key=True。如果 Django 在看到已经显式地设置了 Field.primary_key,将不会自动在表(模型)中添加 id 列。每个模型都需要拥有一个设置了 primary_key=True 的字段(无论是显式的设置还是 Django 自动设置)。
1.3.4 字段备注名
除了 ForeignKey, ManyToManyField 和 OneToOneField,任何字段类型都接收一个可选的位置参数 verbose_name,如果未指定该参数值, Django 会自动使用字段的属性名作为该参数值,并且把下划线转换为空格。其实也就是我们可以在admin后台前端路由看到的备注名。
# 在该例中指定verbose_name参数备注名为 "person's first name"(建议多使用第二种关键字传参)
first_name = models.CharField("person's first name", max_length=30)
first_name = models.CharField(verbose_name"person's first name", max_length=30)
# 在该例中由于没有指定verbose_name参数,备注名为 "first name":
first_name = models.CharField(max_length=30)ForeignKey, ManyToManyField and OneToOneField 接收的第一个参数为模型的类名,后面可以添加一个 verbose_name 参数:
poll = models.ForeignKey(
Poll,
on_delete=models.CASCADE,
verbose_name="the related poll",
)
sites = models.ManyToManyField(Site, verbose_name="list of sites")
place = models.OneToOneField(
Place,
on_delete=models.CASCADE,
verbose_name="related place",
)官网给出的惯例是不将 verbose_name 的首字母大写,必要时 Django 会自动把首字母转换为大写。
1.4 关联关系
关联关系在第二篇博客中也进行了对应的总结,这里再简述一下。Django学习(2):Django的ORM操作_色厉胆薄李富贵儿的博客-CSDN博客在 Django 中,使用模型类来定义数据模型,这些模型类是 Python 类,它们继承自。 https://blog.csdn.net/qq_62278240/article/details/132825099?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_62278240/article/details/132825099?spm=1001.2014.3001.5501
显然,关系型数据库的强大之处在于各表之间的关联关系。 Django 提供了定义三种最常见的数据库关联关系的方法:多对一,多对多,一对一。
1.4.1 多对一关联
定义一个多对一的关联关系,使用 django.db.models.ForeignKey 类。就和其它 Field 字段类型一样,只需要在模型中添加一个值为该类的属性。ForeignKey 类需要添加一个位置参数:"to=",即想要关联的模型类名。
例如,我们在自己的应用中有两个数据模型:Car和Manufacturer ,其中Car中有一个manufacturer 字段,对应的也就是Category表,此时category就是News中的外键,每个新闻都属于一个种类,而每个新闻种类又包含多条新闻。就可以使用下方定义:
from django.db import models
# 制造商模型类
class Manufacturer(models.Model):
# 填写制造商相关字段
pass
# 汽车模型类
class Car(models.Model):
# 使用外键关联到Manufacturer表,第一个参数就是对应的关联到的表,也可以位置传参
# 第二个参数就是是否采用级联删除
manufacturer = models.ForeignKey(to=Manufacturer, on_delete=models.CASCADE)
# 其他字段
# ...也可以创建自关联关系(一个模型与它本身有多对一的关系)和 与未定义的模型间的关联关系 。
建议设置 ForeignKey 字段名(上例中的 manufacturer )为想要关联的模型名,并且也可以随意设置为想要的名称,例如:
class Car(models.Model):
# 自定义名字,但是还是建议与表有关名
company_that_makes_it = models.ForeignKey(
to=Manufacturer,
on_delete=models.CASCADE,
)
# ...ForeignKey 字段还可以接收一些其他的参数,我们会在后面补充,这些可选的参数可以更深入的规定关联关系的具体实现。关于反向关联对象的细节,可以去第二篇ORM中查看关联关系。
1.4.2 多对多关联
定义一个多对多的关联关系,使用 django.db.models.ManyToManyField 类。就和其他 Field 字段类型一样,只需要在模型中添加一个值为该类的属性。ManyToManyField 类也需要添加一个位置参数"to=",即想要关联的模型类名。
例如:如果 Pizza 含有多种 Topping (配料)——也就是一种 Topping 可能存在于多个 Pizza 中,并且每个 Pizza 含有多种 Topping——那么可以这样表示这种关系:
from django.db import models
class Topping(models.Model):
# Topping字段
# ...
pass
class Pizza(models.Model):
# Pizza字段
# ...
# 关联到Topping
toppings = models.ManyToManyField(to=Topping)和 ForeignKey 类一样,也可以创建自关联关系(一个对象与他本身有着多对多的关系)和 与未定义的模型的关系 。建议设置 ManyToManyField 字段名(上例中的 toppings )为一个复数名词,表示所要关联的模型对象的集合。
对于多对多关联关系的两个模型,可以在任何一个模型中添加 ManyToManyField 字段,但只能选择一个模型设置该字段,即不能同时在两模型中添加该字段。
一般来讲,应该把 ManyToManyField 实例放到需要在表单中被编辑的对象中。在之前的例子中, toppings 被放在 Pizza 当中(而不是 Topping 中有指向 pizzas 的 ManyToManyField 实例 )因为相较于配料被放在不同的披萨当中,披萨当中有很多种配料更加符合常理。按照先前说的,在编辑 Pizza 的表单时用户可以选择多种配料。
ManyToManyField 字段也接受一些模型字段参数中介绍的参数。这些可选的参数可以更深入地规定关联关系的具体实现。
在多对多(many-to-many)关系中添加添加额外的属性字段
如果只是想要一个类似于记录披萨和配料之间混合和搭配的多对多关系,标准的 ManyToManyField 就足够你用了。但是,有时可能需要将数据与两个模型之间的关系相关联。
举例来讲,考虑一个需要跟踪音乐人属于哪个音乐组的应用程序。在人和他们所在的组之间有一个多对多关系,可以使用 ManyToManyField 来代表这个关系。然而,想要记录更多的信息在这样的关联关系当中,比如想要记录某人是何时加入一个组的。
对于这些情况,Django 允许指定用于控制多对多关系的模型。可以在中间模型当中添加额外的字段。在实例化 ManyToManyField 的时候使用 through 参数指定多对多关系使用哪个中间模型。对于我们举的音乐家的例子,代码如下:
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=128)
def __str__(self):
return self.name
class Group(models.Model):
name = models.CharField(max_length=128)
# through指定多对多关系中使用的中间模型
members = models.ManyToManyField(to=Person, through="Membership")
def __str__(self):
return self.name
class Membership(models.Model):
# 两个外键字段
person = models.ForeignKey(Person, on_delete=models.CASCADE)
group = models.ForeignKey(Group, on_delete=models.CASCADE)
# 加入日期字段,使用DateField
date_joined = models.DateField()
invite_reason = models.CharField(max_length=64)在设置中间模型的时候,显式地为多对多关系中涉及的中间模型指定外键。这种显式声明定义了这两个模型之间是如何关联的。
在中间模型当中有一些限制条件:
- 中间模型要么有且仅有一个指向源模型(我们例子当中的 Group )的外键,要么必须通过 ManyToManyField.through_fields 参数在多个外键当中手动选择一个外键,如果有多个外健且没有用 through_fields 参数选择一个的话,会出现验证错误。对于指向目标模型(我们例子当中的 Person )的外键也有同样的限制。
- 在一个用于描述模型当中自己指向自己的多对多关系的中间模型当中,可以有两个指向同一个模型的外健,但这两个外健分表代表多对多关系(不同)的两端。如果外健的个数 超过 两个,你必须和上面一样指定 through_fields 参数,要不然会出现验证错误。
现在已经设置了 ManyToManyField 来使用中介模型(在本例中为“成员资格”),就可以开始创建一些多对多关系了。 您可以通过创建中间模型的实例来完成此操作:
>>> ringo = Person.objects.create(name="Ringo Starr")
>>> paul = Person.objects.create(name="Paul McCartney")
>>> beatles = Group.objects.create(name="The Beatles")
>>> m1 = Membership(
... person=ringo,
... group=beatles,
... date_joined=date(1962, 8, 16),
... invite_reason="Needed a new drummer.",
... )
>>> m1.save()
>>> beatles.members.all()
<QuerySet [<Person: Ringo Starr>]>
>>> ringo.group_set.all()
<QuerySet [<Group: The Beatles>]>
>>> m2 = Membership.objects.create(
... person=paul,
... group=beatles,
... date_joined=date(1960, 8, 1),
... invite_reason="Wanted to form a band.",
... )
>>> beatles.members.all()
<QuerySet [<Person: Ringo Starr>, <Person: Paul McCartney>]>还可以使用 add()、create() 或 set() 来创建关系,只要为任何必填字段指定 through_defaults 即可:
>>> beatles.members.add(john, through_defaults={"date_joined": date(1960, 8, 1)})
>>> beatles.members.create(
... name="George Harrison", through_defaults={"date_joined": date(1960, 8, 1)}
... )
>>> beatles.members.set(
... [john, paul, ringo, george], through_defaults={"date_joined": date(1960, 8, 1)}
... )如果中间模型定义的自定义直通表不强制 (model1, model2) 对的唯一性,允许多个值,则remove() 调用将删除所有中间模型实例:
>>> Membership.objects.create(
... person=ringo,
... group=beatles,
... date_joined=date(1968, 9, 4),
... invite_reason="You've been gone for a month and we miss you.",
... )
>>> beatles.members.all()
<QuerySet [<Person: Ringo Starr>, <Person: Paul McCartney>, <Person: Ringo Starr>]>
>>> # 这将删除 Ringo Starr 的两个中间模型实例
>>> beatles.members.remove(ringo)
>>> beatles.members.all()
<QuerySet [<Person: Paul McCartney>]>clear() 方法可用于删除一个实例的所有多对多关系:
>>> # 披头士乐队解散了
>>> beatles.members.clear()
# 请注意,这会删除中间模型实例
>>> Membership.objects.all()
<QuerySet []>一旦建立了多对多关系,就可以发出查询。 就像正常的多对多关系一样,可以使用多对多相关模型的属性进行查询:
# 查找成员名称以“Paul”开头的所有群组
>>> Group.objects.filter(members__name__startswith="Paul")
<QuerySet [<Group: The Beatles>]>当使用中间模型时,还可以查询其属性:
# 查找 1961 年 1 月 1 日之后加入的所有披头士乐队成员
>>> Person.objects.filter(
... group__name="The Beatles", membership__date_joined__gt=date(1961, 1, 1)
... )
<QuerySet [<Person: Ringo Starr]>如果需要访问会员信息,可以通过直接查询会员模型来实现:
# 导入了Django的Membership模型(前提是你已经在代码中导入了所需的模型)
>>> from your_app.models import Membership
# 使用Django ORM查询数据库,寻找一个与'beatles'组和'ringo'成员相关联的Membership对象
>>> ringos_membership = Membership.objects.get(group=beatles, person=ringo)
# 访问Membership对象的date_joined属性,获取成员加入组的日期
>>> ringos_membership.date_joined # 结果应该是:datetime.date(1962, 8, 16)
# 访问Membership对象的invite_reason属性,获取成员加入组的邀请原因
>>> ringos_membership.invite_reason # 结果应该是:'Needed a new drummer.'
访问相同信息的另一种方法是从 Person 对象查询多对多反向关系:
# 使用Django的ORM,假设你有一个名为'ringo'的成员对象以及一个名为'beatles'的组对象
# 通过'ringo'成员对象的membership_set属性来获取与'beatles'组相关联的Membership对象
>>> ringos_membership = ringo.membership_set.get(group=beatles)
# 访问Membership对象的date_joined属性,获取成员加入组的日期
>>> ringos_membership.date_joined # 结果应该是:datetime.date(1962, 8, 16)
# 访问Membership对象的invite_reason属性,获取成员加入组的邀请原因
>>> ringos_membership.invite_reason # 结果应该是:'Needed a new drummer.'
1.4.3 一对一关联
使用 OneToOneField 来定义一对一关系。就像使用其他类型的 Field 一样:在模型属性中包含它。当一个对象以某种方式“继承”另一个对象时,这对该对象的主键非常有用。OneToOneField 需要一个位置参数"to=":与模型相关的类。
例如,当要建立一个有关“位置”信息的数据库时,可能会包含通常的地址,电话等字段。接着,如果想接着建立一个关于关于餐厅的数据库,除了将位置数据库当中的字段复制到 Restaurant 模型,也可以将一个指向 Place OneToOneField 放到 Restaurant 当中(因为餐厅“是一个”地点);在处理这样的情况时最好使用模型继承 ,它隐含的包括了一个一对一关系。和 ForeignKey 一样,可以创建自关联关系与尚未定义的模型的关系 。
# 在本例中,一个 Place 可可以一个 Restaurant:
from django.db import models
class Place(models.Model):
name = models.CharField(max_length=50)
address = models.CharField(max_length=80)
def __str__(self):
return f"{self.name} the place"
class Restaurant(models.Model):
place = models.OneToOneField(
Place,
on_delete=models.CASCADE,
primary_key=True,
)
serves_hot_dogs = models.BooleanField(default=False)
serves_pizza = models.BooleanField(default=False)
def __str__(self):
return "%s the restaurant" % self.place.name
class Waiter(models.Model):
restaurant = models.ForeignKey(Restaurant, on_delete=models.CASCADE)
name = models.CharField(max_length=50)
def __str__(self):
return "%s the waiter at %s" % (self.name, self.restaurant)使用django自带api进行操作
# 创建几个Place实例:
>>> p1 = Place(name="Demon Dogs", address="944 W. Fullerton")
>>> p1.save()
>>> p2 = Place(name="Ace Hardware", address="1013 N. Ashland")
>>> p2.save()
# 创建一个Restaurant实例。 通过"parent"对象作为这个对象的主键
>>> r = Restaurant(place=p1, serves_hot_dogs=True, serves_pizza=False)
>>> r.save()
# Restaurant可以访问其place
>>> r.place
<Place: Demon Dogs the place>
# 一个Place可以访问其restaurant(如果有)
>>> p1.restaurant
<Restaurant: Demon Dogs the restaurant>
# p2 没有关联的餐厅
>>> from django.core.exceptions import ObjectDoesNotExist
>>> try:
... p2.restaurant
... except ObjectDoesNotExist:
... print("There is no restaurant here.")
...
There is no restaurant here.
# 还可以使用 hasattr 来避免捕获异常
>>> hasattr(p2, "restaurant")
False
# 使用赋值符号设置位置。 因为place 是Restaurant的主键,所以保存将创建一个新restaurant
>>> r.place = p2
>>> r.save()
>>> p2.restaurant
<Restaurant: Ace Hardware the restaurant>
>>> r.place
<Place: Ace Hardware the place>
# 使用相反方向的赋值再次设置该位置
>>> p1.restaurant = r
>>> p1.restaurant
<Restaurant: Demon Dogs the restaurant>
# 必须先保存对象,然后才能将其分配给一对一关系。 创建一个未保存地点的餐厅会引发 ValueError
>>> p3 = Place(name="Demon Dogs", address="944 W. Fullerton")
>>> Restaurant.objects.create(place=p3, serves_hot_dogs=True, serves_pizza=False)
Traceback (most recent call last):
...
ValueError: save() prohibited to prevent data loss due to unsaved related object 'place'.
# Restaurant.objects.all() 返回餐厅,而不是地点。 请注意,有两家餐厅 - Ace Hardware 餐厅是在调用 r.place = p2 时创建的、
>>> Restaurant.objects.all()
<QuerySet [<Restaurant: Demon Dogs the restaurant>, <Restaurant: Ace Hardware the restaurant>]>
# Place.objects.all() 返回所有地点,无论它们是否有餐厅
>>> Place.objects.order_by("name")
<QuerySet [<Place: Ace Hardware the place>, <Place: Demon Dogs the place>]>
# 可以使用跨关系查找来查询模型
>>> Restaurant.objects.get(place=p1)
<Restaurant: Demon Dogs the restaurant>
>>> Restaurant.objects.get(place__pk=1)
<Restaurant: Demon Dogs the restaurant>
>>> Restaurant.objects.filter(place__name__startswith="Demon")
<QuerySet [<Restaurant: Demon Dogs the restaurant>]>
>>> Restaurant.objects.exclude(place__address__contains="Ashland")
<QuerySet [<Restaurant: Demon Dogs the restaurant>]>
# 这也适用于反转的情况
>>> Place.objects.get(pk=1)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant__place=p1)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant=r)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant__place__name__startswith="Demon")
<Place: Demon Dogs the place>
# 如果删除一个地点,其餐厅也将被删除(假设 OneToOneField 定义时 on_delete 设置为 CASCADE,这是默认值)
>>> p2.delete()
(2, {'one_to_one.Restaurant': 1, 'one_to_one.Place': 1})
>>> Restaurant.objects.all()
<QuerySet [<Restaurant: Demon Dogs the restaurant>]>
# 向Restaurant添加一个Waiter
>>> w = r.waiter_set.create(name="Joe")
>>> w
<Waiter: Joe the waiter at Demon Dogs the restaurant>
# 查询waiters
>>> Waiter.objects.filter(restaurant__place=p1)
<QuerySet [<Waiter: Joe the waiter at Demon Dogs the restaurant>]>
>>> Waiter.objects.filter(restaurant__place__name__startswith="Demon")
<QuerySet [<Waiter: Joe the waiter at Demon Dogs the restaurant>]>OneToOneField 字段还接受一个可选的 parent_link 参数。OneToOneField 类通常自动的成为模型的主键,这条规则现在不再使用了(然而可以手动指定 primary_key 参数)。因此,现在可以在单个模型当中指定多个 OneToOneField 字段。
1.5 跨文件模型导入
一个应用中的models中的模型可能需要关联到另一个应用中的模型。为了实现这一点,在定义模型的文件开头导入需要被关联的模型。接着就可以在其他有需要的模型类当中关联它了。比如:
from django.db import models
from geography.models import ZipCode
class Restaurant(models.Model):
# ...
zip_code = models.ForeignKey(
ZipCode,
on_delete=models.SET_NULL,
blank=True,
null=True,
)可能遇到问题:在这里需要注意一点的是, 如果直接导入从项目路径导入,可能没有提示并报错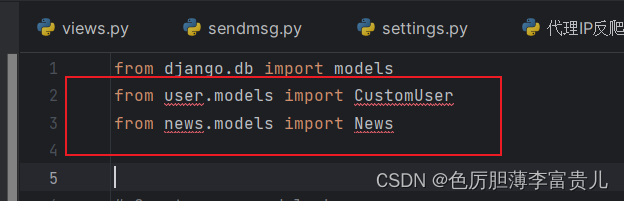
解决方案:此时可以将项目路径设置为源路径,便可以解决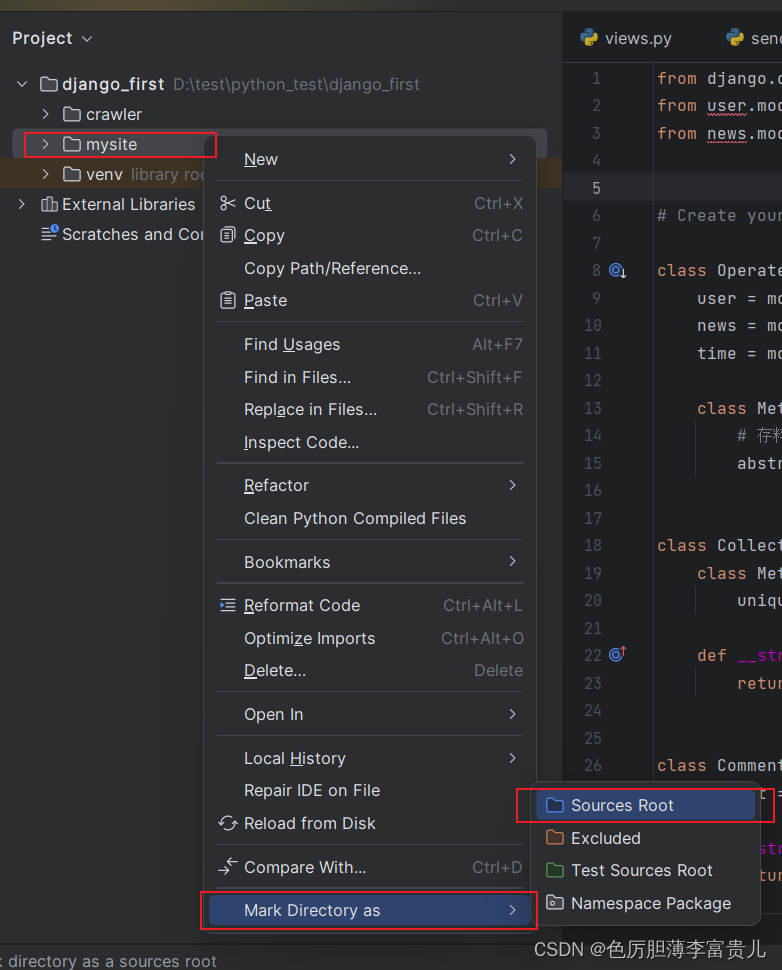
再重新启动或加载一下项目,便不再报错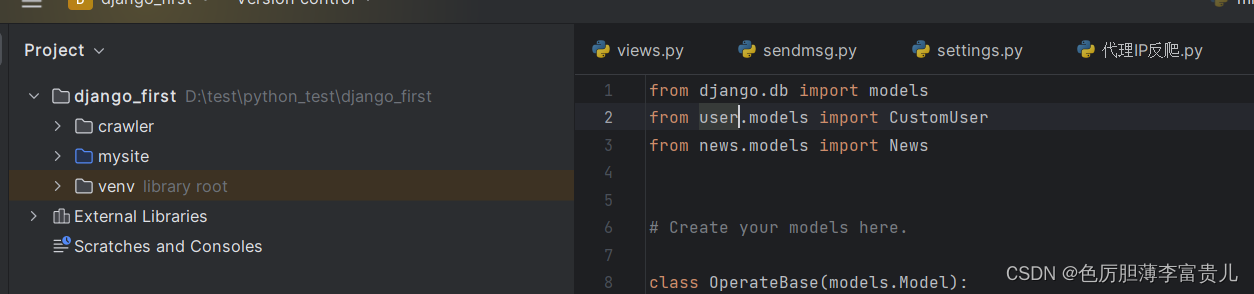
1.6 字段命名限制
Django 对模型的字段名有一些限制:
- 字段名称不能是 Python 保留字,预留字(关键字,输入数据时不得使用的字符),因为这会导致 Python 语法错误。 例如:
class Example(models.Model): pass = models.IntegerField() # 'pass' 是一个保留字! -
一个字段名称不能包含连续的多个下划线,原因在于 Django 查询语法的工作方式。例如:
class Example(models.Model): foo__bar = models.IntegerField() # 'foo__bar' 有两个连续下划线! -
字段名不能以下划线结尾,原因同上。
但是,这些限制是可以被解决的,因为字段名没要求和数据库列名一样。可以查看官方文档 db_column 选项。SQL保留字,例如 join, where 或 select, 是 可以被用在模型字段名当中的,因为 Django 在对底层的 SQL 查询当中清洗了所有的数据库表名和字段名,通过使用特定数据库引擎的引用语法。
二,编写自定义字段类型
2.1 介绍
如果已经存在的模型字段不能满足需求,或者希望支持一些不太常见的数据库列类型,可以创建自己的字段类。在官方文档中的"编写自定义模型字段"中提供了创建自定义字段的各方面内容。
字段参考介绍了如何使用 Django 的标准字段类—— CharField, DateField,等等。大多数情况下,这些类就是我们所需要的。虽然有时候,Django 的版本不能精确地匹配需求,或者想使用的字段与 Django 内置的完全不同。
Django 内置的字段类型并未覆盖所有可能的数据库字段类型——只有常见的类型,例如 VARCHAR 和 INTEGER。对于更多模糊的列类型,例如地理多边形(geographic polygons),甚至是用户创建的类型,例如 PostgreSQL custom types,可以自定义 Django 的 Field 子类。
或者,我们有一个复杂的 Python 对象,它可以以某种形式序列化,适应标准的数据库列类型。这是另一个 Field 子类能帮助你配合模型使用你的对象的示例。
2.2 本次介绍实例对象
创建自定义字段要求注意一些细节。为了简化问题,在本文档中全程使用同一实例:封装一个 Python 对象,代表手上桥牌的细节。不需要知道如何玩桥牌就能学习此例子。只需知道 52 张牌被均分给 4 个玩家,称这四个玩家为东,南,西和北。模型如下:
class Hand:
"""一手牌(桥牌)"""
def __init__(self, north, east, south, west):
# Input parameters are lists of cards ('Ah', '9s', etc.)
self.north = north
self.east = east
self.south = south
self.west = west
# ... (省略其他可能有用的方法) ...这是一个一般的 Python 类,其中没有特殊的 Django 内容。期望模块中做如下操作 (假设模型中的 hand 属性是 Hand 的一个实例):
example = MyModel.objects.get(pk=1)
print(example.hand.north)
new_hand = Hand(north, east, south, west)
example.hand = new_hand
example.save()对模型中的 hand 属性的赋值与取值操作与其它 Python 类一直。技巧是告诉 Django 如何保存和加载对象。我们不需要修改这个类来为了在模型中使用 Hand 类。
2.3 背后的理论
2.3.1 数据库存储
从模型字段开始。把它们分开来看,一个模型字段可以在处理数据库时,提供处理一般 Python 对象的方法(字符串,布尔值, datetime ,或像 Hand 这样更复杂的类型),并将其转换成有用的格式。(对序列化而言这种格式是很有用的,但接下来我们会看到,如果数据库端处于控制之下,序列化会更简单)
模型中的字段必须能以某种方式转换为已存在的数据库列类型。不能的数据库提供不同的可用列类型集,但规则仍相同:只需要处理这些类型。想存在数据库中的任何数据都必须能适配这些类型中的某一个。
一般地讲,要么编写一个 Django 字段来匹配特定的数据库列类型,要么需要一种方法将数据转换为字符串。
对于手牌示例来说,我们可以通过按预定顺序将所有牌连接在一起,将牌数据转换为 104 个字符的字符串。例如,首先是所有北牌,然后是东、南和西牌。 因此,Hand 对象可以保存到数据库中的文本或字符列中。
2.3.2 一个字段(Field)类做了什么?
所有的 Django 字段(本页提到的 字段 均指模型字段,而不是 表单字段)都是 django.db.models.Field 的子类。对于所有字段,Django 记录的大部分信息是一样的——名字,帮助文本,是否唯一,等等。存储行为由 Field 处理。稍后,我们会深入了解 Field 能做什么;现在, 可以说万物源于 Field,并在其基础上自定义了类的关键行为。
了解 Django 字段类不保存在模型属性中很重要。模型属性包含普通的 Python 对象。你所以定义的字段类实际上在模型类创建时在 Meta 类中(这是如何实现的在这里不重要)。这是因为在仅创建和修改属性时,字段类不是必须的。相反,他们提供了属性值间转换的机制,并决定了什么被存入数据库或发送给 序列化器。
在创建自定义字段时牢记这点:所写的 Django 的 Field 子类提供了多种在 Python 实例和数据库/序列化器之间的转换机制(比如,保存值和使用值进行查询之间是不同的)。只要记住,在需要一个自定义字段时,只需创建两个类:
- 第一个类是用户需要操作的 Python 对象。它们会复制给模型属性,它们会为了显示而读取属性,就想这样。这里本例中的
Hand类。 - 第二类是
Field的子类。这个类知道如何在永久存储格式和 Python 格式之间来回转换。
2.4 编写一个 field 子类
2.4.1 编写字段 field 子类
编写一个 Field 子类时,需要先想想新字段和哪个已有的 Field 最相似。继承 Django 其他字段节约你的时间吗?如果不会,我们需要继承 Field 类,因为它继承了一切。
初始化新字段有点麻烦,因为要从公共参数中分离需要的参数,并将剩下的传给父类 Field 的 __init__() 方法(或我们定义的父类)。
在本例中,我们会调用 HandField。(也可以调用 Field 子类它并不表现的像任何已存在的字段,所以我们将直接继承自 Field:
from django.db import models
class HandField(models.Field):
description = "A hand of cards (bridge style)"
def __init__(self, *args, **kwargs):
kwargs["max_length"] = 104
super().__init__(*args, **kwargs)我们的 HandField 接收大多数标准字段选项(参考下面的列表),但是我们确定参数是定长的,因为它只需要保存 52 个卡片和它们的值;总计 104 个字符。
2.4.2 Field.__init__() 方法接收参数
verbose_name:
作用:用于设置字段的人类可读的名称。
默认值:如果未提供,则Django将使用字段的名称,将下划线转换为空格,并首字母大写。
示例:verbose_name="First Name"。
name:
作用:字段在数据库表中的列名。
默认值:如果未提供,则Django将使用字段的Python属性名,并将其转换为小写。
示例:name="first_name"。
primary_key:
作用:指定是否将该字段作为主键。主键用于唯一标识数据库表中的每一行记录。
默认值:False,通常由Django自动创建一个自增主键。
示例:primary_key=True。
max_length:
作用:用于指定字段的最大字符长度。通常用于字符型字段(如CharField)。
默认值:一些字段(如CharField)需要此参数,但其他字段(如IntegerField)不需要。
示例:max_length=100。
unique:
作用:指定该字段的值是否在表中必须是唯一的。
默认值:False,允许多个行具有相同的字段值。
示例:unique=True。
blank:
作用:指定在表单验证中是否允许该字段为空(即不填写该字段)。
默认值:False,通常情况下,字段是不允许为空的。
示例:blank=True。
null:
作用:指定数据库中该字段是否可以存储为NULL值。
默认值:False,通常情况下,字段是不允许为NULL的。
示例:null=True。
2.2 模型中的Meta元类
Meta 元类是 Python 中的一个高级概念,用于控制类的创建和行为。在 Python 中,一切皆为对象,包括类本身。Meta 元类就是用来定义类的类,它决定了类的属性、方法和行为。我们会在后续python学习中拓展Meta元类用法等。
模型字段参考
字段选项
从技术上讲,这些方法都被定义在django.db.models.fields,但为了方便,它们被导入到django.db.models,标准的惯例是使用:from django.db import models 并利用 models.<Foo>Field。
以下参数对所以字段类型均有效,且是可选的。
null:Field.null
如果是True, Django 将在数据库中存储空值为NULL。默认为False。
避免在基于字符串的字段上使用null,如CharField和TextField。如果一个基于字符串的字段有null=True,这意味着它有两种可能的“无数据”值。NULL,和空字符串。在大多数情况下,“无数据”有两种可能的值是多余的,Django 的惯例是使用空字符串,而不是NULL。一个例外是当一个CharField同时设置了unique=True和blank=True。在这种情况下,null=True是需要的,以避免在保存具有空白值的多个对象时违反唯一约束。
无论是基于字符串的字段还是非字符串的字段,如果希望在表单中允许空值,还需要设置blank=True,因为null参数只影响数据库的存储(参见后续blank选项)。
blank:Field.blank
如果是 True ,该字段允许为空。默认为 False 。
注意,这与 null 不同。 null 纯属数据库相关,而 blank 则与验证相关。如果一个字段有 blank=True,表单验证将允许输入一个空值。如果一个字段有 blank=False,则该字段为必填字段。
提供缺失值:blank=True 可以用于 null=False 的字段,但这需要在模型上实现 clean(),以便以编程方式提供任何缺失值。
choices:Field.choices
一个 sequence(顺序) 本身由正好两个项目的迭代项组成(例如 [(A,B),(A,B)...] ),作为该字段的选择。如果给定了选择,它们会被 模型验证 强制执行,默认的表单部件将是一个带有这些选择的选择框,而不是标准的文本字段。
每个元组中的第一个A元素是要在模型上设置的实际值,第二个B元素是人可读的名称。例如:
YEAR_IN_SCHOOL_CHOICES = [
("FR", "Freshman"),
("SO", "Sophomore"),
("JR", "Junior"),
("SR", "Senior"),
("GR", "Graduate"),
]一般来说,最好在模型类内部定义选择,并为每个值定义一个合适的名称的常量:
from django.db import models
class Student(models.Model):
FRESHMAN = "FR"
SOPHOMORE = "SO"
JUNIOR = "JR"
SENIOR = "SR"
GRADUATE = "GR"
YEAR_IN_SCHOOL_CHOICES = [
(FRESHMAN, "Freshman"),
(SOPHOMORE, "Sophomore"),
(JUNIOR, "Junior"),
(SENIOR, "Senior"),
(GRADUATE, "Graduate"),
]
year_in_school = models.CharField(
max_length=2,
choices=YEAR_IN_SCHOOL_CHOICES,
default=FRESHMAN,
)
def is_upperclass(self):
return self.year_in_school in {self.JUNIOR, self.SENIOR}虽然可以在模型类之外定义一个选择列表,然后引用它,但在模型类内定义选择和每个选择的名称,可以将所有这些信息保留在使用它的类中,并帮助引用这些选择(例如,Student.SOPHOMORE 将在导入 Student 模型的任何地方工作)。还可以将可用选择收集到可用于组织目的的命名组中:
MEDIA_CHOICES = [
(
"Audio",
(
("vinyl", "Vinyl"),
("cd", "CD"),
),
),
(
"Video",
(
("vhs", "VHS Tape"),
("dvd", "DVD"),
),
),
("unknown", "Unknown"),
]每个元组中的第一个元素是应用于该组的名称。第二个元素是一个二元元组的迭代,每个二元元组包含一个值和一个可读的选项名称。分组后的选项可与未分组的选项结合在一个单一的列表中(如本例中的 'unknown' 选项)。
对于每一个设置了 choice 的模型字段,Django 会添加一个方法来检索字段当前值的可读名称。参见数据库 API 文档中的 get_FOO_display()。
请注意,选择可以是任何序列对象——不一定是列表或元组。这可以动态地构造选择。但是如果发现自己把 chips 魔改成动态的,可能最好使用一个合适的的带有 ForeignKey 的数据库表。 chips 是用于静态数据的,如果有的话,不应该有太大的变化。
备注:每当 choices 的顺序变动时将会创建新的迁移。
除非 blank=False 与 default 一起设置在字段上,否则包含 "---------" 的标签将与选择框一起呈现。要覆盖这种行为,可以在 choices 中添加一个包含 None 的元组,例如 (None, 'Your String For Display') 。另外,也可以在有意义的地方使用一个空字符串来代替 None ——比如在 CharField。
枚举类型:
此外,Django 还提供了枚举类型,可以通过将其子类化来简洁地定义选择:
from django.utils.translation import gettext_lazy as _
class Student(models.Model):
class YearInSchool(models.TextChoices):
FRESHMAN = "FR", _("Freshman")
SOPHOMORE = "SO", _("Sophomore")
JUNIOR = "JR", _("Junior")
SENIOR = "SR", _("Senior")
GRADUATE = "GR", _("Graduate")
year_in_school = models.CharField(
max_length=2,
choices=YearInSchool.choices,
default=YearInSchool.FRESHMAN,
)
def is_upperclass(self):
return self.year_in_school in {
self.YearInSchool.JUNIOR,
self.YearInSchool.SENIOR,
}这些工作类似于 Python 标准库中的 enum,但是做了一些修改。
-
枚举成员值是构造具体数据类型时要使用的参数元组。Django 支持在这个元组的末尾添加一个额外作为人可读的名称的字符串值 label。label 可以是一个惰性的可翻译字符串。因此,在大多数情况下,成员值将是一个 (value, label) 二元组。请看下面使用更复杂的数据类型 子类化选择的例子。如果没有提供元组,或者最后一项不是(惰性)字符串,label 是从成员名 自动生成。
-
在值上添加 .label 属性,以返回人类可读的名称。
-
在枚举类中添加了一些自定义属性—— .choice、.labs、.values 和 .names ——以便于访问枚举的这些单独部分的列表。在字段定义中,使用 .choice 作为一个合适的值传递给 choice。警告:这些属性名称不能作为成员名称使用,因为它们会发生冲突。
-
强制使用 enum.unique() 是为了确保不能多次定义值。在选择一个字段时,不太可能会出现这种情况。
如果不需要将人类可读的名称进行翻译,可以从成员名称中推断出这些名称(将下划线替换为空格,并使用标题大小写形式)。
>>> class Vehicle(models.TextChoices):
... CAR = "C"
... TRUCK = "T"
... JET_SKI = "J"
...
>>> Vehicle.JET_SKI.label
'Jet Ski'由于枚举值需要为整数的情况极为常见,Django 提供了一个 IntegerChoices 类。例如:
class Card(models.Model):
class Suit(models.IntegerChoices):
DIAMOND = 1
SPADE = 2
HEART = 3
CLUB = 4
suit = models.IntegerField(choices=Suit.choices)也可以使用枚举(Enum)的功能性API,但需要注意的是标签会自动生成,就像上面突出显示的那样。
>>> MedalType = models.TextChoices("MedalType", "GOLD SILVER BRONZE")
>>> MedalType.choices
[('GOLD', 'Gold'), ('SILVER', 'Silver'), ('BRONZE', 'Bronze')]
>>> Place = models.IntegerChoices("Place", "FIRST SECOND THIRD")
>>> Place.choices
[(1, 'First'), (2, 'Second'), (3, 'Third')]如果需要支持 int 或 str 以外的具体数据类型,可以将 Choices 和所需的具体数据类型子类化,例如 date 与 DateField 一起使用:
class MoonLandings(datetime.date, models.Choices):
APOLLO_11 = 1969, 7, 20, "Apollo 11 (Eagle)"
APOLLO_12 = 1969, 11, 19, "Apollo 12 (Intrepid)"
APOLLO_14 = 1971, 2, 5, "Apollo 14 (Antares)"
APOLLO_15 = 1971, 7, 30, "Apollo 15 (Falcon)"
APOLLO_16 = 1972, 4, 21, "Apollo 16 (Orion)"
APOLLO_17 = 1972, 12, 11, "Apollo 17 (Challenger)"还有一些注意事项需要注意:
-
枚举类型不支持命名组。
-
因为具有具体数据类型的枚举要求所有值都与类型相匹配,所以不能通过创建一个值为
None的成员来覆盖空白标签。相反,在类上设置__empty__属性:class Answer(models.IntegerChoices): NO = 0, _("No") YES = 1, _("Yes") __empty__ = _("(Unknown)")
db_column:Field.db_column
这个字段是要使用的数据库列名。如果没有给出列名,Django 将使用字段名。
如果数据库列名是 SQL 的保留字,或者包含了 Python 变量名中不允许的字符——特别是连字符——那也没关系。Django 会在幕后引用列名和表名。
db_comment:Field.db_comment(Django 4.2版本新增。)
这是关于用于该字段的数据库列的注释。这对于那些直接访问数据库但可能不查看编写Django代码的人来说很有用,用来记录字段的信息。
pub_date = models.DateTimeField(
db_comment="Date and time when the article was published",
)db_index:Field.db_index
如果是True,将为该字段创建数据库索引。默认为False。
在可能的情况下,使用Meta.indexes选项。几乎所有情况下,索引提供比db_index更多的功能。db_index可能会在将来被弃用。
db_tablespace:Field.db_tablespace
如果这个字段有索引,那么要为这个字段的索引使用的数据库表空间的名称。默认是项目的 DEFAULT_INDEX_TABLESPACE 设置(如果有设置),或者是模型的 db_tablespace (如果有)。如果后端不支持索引的表空间,则忽略此选项。
default:Field.default
该字段的默认值。可以是一个值或者是个可调用的对象,如果是个可调用对象,每次实例化模型时都会调用该对象。
默认值不能是一个可更改的对象(模型实例、list、set 等),因为对该对象同一实例的引用将被用作所有新模型实例的缺省值。相反,将所需的默认值包裹在一个可调用对象中。例如,如果想为 JSONField 指定一个默认的 dict,使用一个函数:
def contact_default():
return {"email": "to1@example.com"}
contact_info = JSONField("ContactInfo", default=contact_default)lambda 不能用于 default 等字段选项,因为它们不能被 迁移序列化。其他注意事项见该文档。对于像 ForeignKey 这样映射到模型实例的字段,默认应该是它们引用的字段的值(默认是 pk 除非 to_field 被设置了),而不是模型实例。当创建新的模型实例且没有为该字段提供值时,使用默认值。当字段是主键时,当字段设置为`None` 时,也使用默认值。
editable:Field.editable
如果是 False,该字段将不会在管理或任何其他 ModelForm 中显示。在 模型验证 中也会跳过。默认为 True。
error_messages:Field.error_messages
error_messages 参数可以覆盖该字段引发的默认消息。传入一个与想覆盖的错误信息相匹配的键值的字典。
错误信息键包括 null、blank、invalid、invalid_choice、unique 和 unique_for_date。在下面的字段类型中为每个字段指定了额外的错误信息键。
模型的 error_messages 的注意事项
在 表单字段 级别或者 表单 Meta 级别定义的错误信息优先级总是高于在 模型字段 级别定义的。在模型字段上定义的错误信息只有在 模型验证 步骤引发 ValidationError 时才会使用,并且没有在表单级定义相应的错误信息。可以通过添加 NON_FIELD_ERRORS 键到 ModelForm 内部的 Meta 类的 error_messages 中来覆盖模型验证引发的 NON_FIELD_ERRORS 错误信息。
from django.core.exceptions import NON_FIELD_ERRORS
from django.forms import ModelForm
class ArticleForm(ModelForm):
class Meta:
error_messages = {
NON_FIELD_ERRORS: {
"unique_together": "%(model_name)s's %(field_labels)s are not unique.",
}
}help_text:Field.help_text
额外的“帮助”文本,随表单控件一同显示。即便字段未用于表单,对于生成文档也是很有用的。
请注意,在自动生成的表格中,这个值不是 HTML转义的。如果愿意可以在 help_text 中加入 HTML。例如:
help_text = "Please use the following format: <em>YYYY-MM-DD</em>."
或者可以使用纯文本和 django.utils.html.escape() 来转义任何 HTML 特殊字符。确保转义任何可能来自不受信任的用户的帮助文本,以避免跨站脚本攻击。
primary_key:Field.primary_key
如果设置为 True ,将该字段设置为该模型的主键。
如果没有为模型中的任何字段指定 primary_key=True,Django 会自动添加一个字段来保存主键,所以不需要在任何字段上设置 primary_key=True,除非想覆盖默认主键行为。自动创建的主键字段的类型可以在 AppConfig.default_auto_field 中为每个应用程序指定,或者在 DEFAULT_AUTO_FIELD 配置中全局指定。
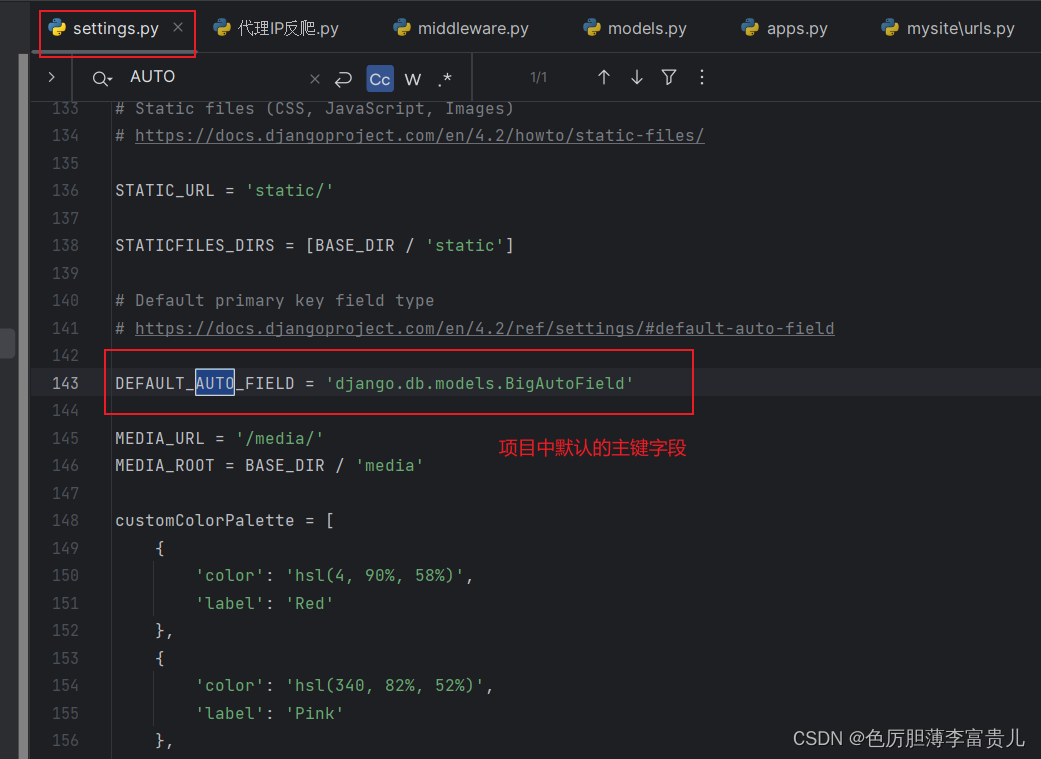
primary_key=True 意味着 null=False 和 unique=True。一个对象只允许有一个主键。主键字段是只读的。如果改变了现有对象的主键值,然后将其保存,则会在旧对象旁边创建一个新对象。在删除对象时,主键字段被设置为None。
unique:Field.unique
如果设置为 True,这个字段必须在整个表中保持值唯一。
这是在数据库级别和模型验证中强制执行的。如果你试图保存一个在 unique 字段中存在重复值的模型,模型的 save() 方法将引发 django.db.IntegrityError。除了 ManyToManyField 和 OneToOneField 之外,该选项对所有字段类型有效。
请注意,当 unique 为 True 时,不需要指定 db_index,因为 unique 意味着创建一个索引。
unique_for_date:Field.unique_for_date
将其设置为 DateField 或 DateTimeField 的名称,要求该字段的日期字段值是唯一的。
例如,如果字段 title 有 unique_for_date="pub_date",那么 Django 就不允许输入两条相同 title 和 pub_date 的记录。请注意,如果将其设置为指向 DateTimeField,则只考虑该字段的日期部分。此外,当 USE_TZ 为 True 时,检查将在对象保存时的当前时区中进行。
这在模型验证过程中由 Model.validate_unique() 强制执行,但在数据库级别上不执行。如果任何 unique_for_date 约束涉及的字段不属于 ModelForm (例如,如果其中一个字段被列”exclude"中,或者有 editable=False ), Model.validate_unique() 将跳过对该特定约束的验证。
unique_for_month:Field.unique_for_month
像 unique_for_date 一样,但要求字段对月份是唯一的。
unique_for_year:Field.unique_for_year
如 unique_fordate 和 unique_formonth。
补充:unique_for_date、unique_for_month 和 unique_for_year 是Django模型字段中的选项,用于定义字段在特定时间范围内必须具有唯一值的规则。这些选项通常用于日期和时间相关的字段,如DateField或DateTimeField。
具体解释如下:
-
unique_for_date:当设置为某个字段名称时,要求在指定日期(天)内,该字段的值必须是唯一的。这意味着在同一天内,不同记录的该字段的值不能相同。 -
unique_for_month:当设置为某个字段名称时,要求在指定月份内,该字段的值必须是唯一的。这意味着在同一月内,不同记录的该字段的值不能相同。 -
unique_for_year:当设置为某个字段名称时,要求在指定年份内,该字段的值必须是唯一的。这意味着在同一年内,不同记录的该字段的值不能相同。
这些选项可以用来强制确保某些字段的唯一性在特定的时间间隔内,通常用于需要跟踪时间的模型,以防止在相同的日期、月份或年份内出现重复数据。例如,你可以在一个博客模型中使用unique_for_date来确保每一天只有一篇文章。
verbose_name:Field.verbose_name
字段的一个人类可读名称,如果没有给定详细名称,Django 会使用字段的属性名自动创建,并将下划线转换为空格。可以参考上方详细字段名。
validators:Field.validators
要为该字段运行的验证器列表。(后续会对验证器做出详细讲解)
字段类型
AutoField:class AutoField(**options)
一个 IntegerField(整形字段),根据可用的 ID 自动递增。通常不需要直接使用。如果没有指定,主键字段会自动添加到你的模型中。
BigAutoField:class BigAutoField(**options)
一个 64 位整数,与 AutoField 很相似,但范围更大,保证适合 1 到 9223372036854775807 之间的数字。
BigIntegerField:class BigIntegerField(**options)
一个 64 位的整数,和 IntegerField 很像,只是它保证适合从 -9223372036854775808 到 9223372036854775807 的数字。该字段的默认表单部件是一个 NumberInput。
BinaryField:class BinaryField(max_length=None, **options)
一个用于存储原始二进制数据的字段。可以指定为 bytes、bytearray 或 memoryview。
默认情况下,BinaryField 将 ediditable 设置为 False,在这种情况下,它不能被包含在 ModelForm 中。
BinaryField.max_length:可选项。字段的最大长度(以字节为单位)。最大长度在Django的验证中通过MaxLengthValidator进行强制。
BooleanField:class BooleanField(**options)
一个 true/false 字段。
该字段的默认表单部件是 CheckboxInput,或者如果 null=True 则是 NullBooleanSelect。当 Field.default 没有定义时,BooleanField 的默认值是 None。
CharField:class CharField(max_length=None, **options)
一个字符串字段,适用于小到大的字符串。对于大量的文本,使用 TextField。该字段的默认表单部件是一个 TextInput。
CharField具有以下额外的参数:
CharField.max_length(最大长度):字段的最大长度(以字符为单位)。max_length在数据库级别和Django的验证中都会使用MaxLengthValidator进行强制。它对于Django附带的所有数据库后端都是必需的,除了支持无限VARCHAR列的PostgreSQL。
如果编写的应用程序必须可移植到多个数据库后端,应该意识到,有些后端对 max_length 有限制。详情请参考官文档数据库后端注释。
在Django 4.2中的变更:在PostgreSQL上增加了对无限VARCHAR列的支持。
CharField.db_collation(列的排序规则):用于设置数据库列的排序规则(collation)。排序规则决定了在执行字符串比较和排序操作时如何处理字符的顺序,例如,是否区分大小写、特殊字符排序等等。
这个参数允许指定特定的数据库排序规则,以覆盖数据库默认的排序规则。通常,这个参数用于处理不同语言或文化背景下的字符串排序需求。
如果应用需要支持多种语言,可以使用 CharField.db_collation 来设置适合不同语言的排序规则,以确保在排序和比较字符串时得到正确的结果。
请注意,db_collation 参数在不同的数据库后端中可能有不同的支持和行为,具体取决于数据库系统的特性。在使用时,需要查阅相应数据库的文档以了解可用的排序规则选项。
DateField:class DateField(auto_now=False, auto_now_add=False, **options)
用于表示一个日期,在 Python 中用一个 datetime.date 实例表示。有一些额外的、可选的参数。
auto_now:当对象被创建时,自动将字段设置为当前日期。
默认值:False,不会自动设置当前日期。
示例:auto_now=True。
auto_now_add:当对象第一次被创建时,自动将字段设置为当前日期。
默认值:False,不会自动设置当前日期。
示例:auto_now_add=True。
default:设置字段的默认值。可以是一个日期对象或一个可调用的函数,用于提供默认日期。
默认值:None,如果不提供默认值,则字段默认值为空。
示例:default=datetime.date(2023, 9, 23) 或 default=timezone.now。
该字段的默认表单部件是一个 DateInput。管理中增加了一个 JavaScript 日历,以及“今天”的快捷方式。包含一个额外的 invalid_date 错误信息键。
备注:auto_now_add、auto_now 和 default 选项是相互排斥的。这些选项的任何组合都会导致错误。目前,将 auto_now 或 auto_now_add 设置为 True,将导致该字段设置为 editable=False 和 blank=True。auto_now 和 auto_now_add 选项将始终使用创建或更新时默认时区的日期。如果需要一些不同的东西,可能需要考虑使用自己的可调用的默认值,或者覆盖 save() 而不是使用 auto_now 或 auto_now_add ;或者使用 DateTimeField 而不是 DateField,并决定如何在显示时间处理从日期时间到日期的转换。
DateTimeField:class DateTimeField(auto_now=False, auto_now_add=False, **options)
用于表示日期和时间。它包含了与 DateField 相似的参数,并额外包含了时间信息。
额外参数:
auto_now:当对象被创建或保存时,自动将字段设置为当前日期和时间。
默认值:False,不会自动设置当前日期和时间。
示例:auto_now=True。
auto_now_add:当对象第一次被创建时,自动将字段设置为当前日期和时间。
默认值:False,不会自动设置当前日期和时间。
示例:auto_now_add=True。
default:设置字段的默认值。可以是一个日期时间对象或一个可调用的函数,用于提供默认日期和时间。
默认值:None,如果不提供默认值,则字段默认值为空。
示例:default=datetime.datetime(2023, 9, 23, 12, 0, 0) 或 default=timezone.now。
一个日期和时间,在 Python 中用一个 datetime.datetime 实例表示。与 DateField 一样,使用相同的额外参数。该字段的默认表单部件是一个单独的 DateTimeInput。管理中使用两个单独的 TextInput 部件,并使用 JavaScript 快捷方式。
DecimalField:class DecimalField(max_digits=None, decimal_places=None, **options)
存储精确的十进制数值,通常用于表示货币金额或其他需要高精度计算的数值。
额外参数:
max_digits:指定字段能够存储的最大位数(包括整数和小数部分)。
默认值:无,默认必须提供。
示例:max_digits=10。
decimal_places:指定字段中小数部分的最大位数。
默认值:无,默认必须提供。
示例:decimal_places=2。
max_value:指定字段允许的最大值。
默认值:None,不做限制。
示例:max_value=1000.00。
min_value:指定字段允许的最小值。
默认值:None,不做限制。
示例:min_value=0.01。
default:设置字段的默认值,可以是一个十进制数值。
默认值:None,如果不提供默认值,则字段默认值为空。
示例:default=0.00。
当 localize 为 False 时是 NumberInput 否则,该字段的默认表单部件是 TextInput。
DurationField:class DurationField(**options)
用于表示时间间隔或持续时间。它通常用于存储一段时间的长度,例如,任务的执行时间、音乐曲目的持续时间等。一个用于存储时间段的字段在 Python 中用 timedelta 建模。当在 PostgreSQL 上使用时,使用的数据类型是 interval,在 Oracle 上使用的数据类型是 INTERVAL DAY(9) TO SECOND(6)。否则使用微秒的 bigint。
EmailField:class EmailField(max_length=254, **options)
一个 CharField,使用 EmailValidator 来检查该值是否为有效的电子邮件地址。
FileField:class FileField(upload_to='', storage=None, max_length=100, **options)
一个文件上传字段用于存储文件的路径。它用于将文件上传到服务器,并在数据库中存储文件的路径。
额外参数:
FileField.upload_to:这个属性提供了一种设置上传目录和文件名的方式,可以有两种设置方式。在这两种情况下,值都会传递给 Storage.save() 方法。指定文件上传后保存的目标路径。可以是一个字符串,表示相对于MEDIA_ROOT的相对路径,也可以是一个可调用函数,接收实例和文件名作为参数,并返回目标路径。
默认值:空字符串,表示文件将保存在MEDIA_ROOT的根目录下。\
upload_to 也可以是一个可调用对象,如函数。这个函数将被调用以获得上传路径,包括文件名。这个可调用对象必须接受两个参数,并返回一个 Unix 风格的路径(带斜线),以便传给存储系统。这两个参数是:
- instance:定义 FileField 的模型实例。更具体地说,这是附加当前文件的特定实例。
在大多数情况下,这个对象还没有被保存到数据库,所以如果它使用默认的 AutoField,它的主键字段可能还没有一个值。 - filename:最初给文件的文件名。在确定最终目标路径时,可能会考虑到,也可能不会考虑到。
def user_directory_path(instance, filename):
# 文件将被上传到 MEDIA_ROOT/user_<id>/<filename>。
return "user_{0}/{1}".format(instance.user.id, filename)
class MyModel(models.Model):
upload = models.FileField(upload_to=user_directory_path)
FileField.storage:
一个存储对象,或是一个返回存储对象的可调用对象。它处理你的文件的存储和检索。参见官方文档中的管理文件,了解如何提供这个对象。用于指定存储文件的存储系统(Storage System)。存储系统负责确定文件存储的位置以及如何存储和检索文件。
该字段的默认表单部件是一个 ClearableFileInput。
在模型中使用 FileField 或 ImageField (见下文)需要几个步骤:
- 在的配置文件中,需要将 MEDIA_ROOT 定义为所希望 Django 存储上传文件的目录的完整路径。(为了提高性能,这些文件不会存储在数据库中。)将 MEDIA_URL 定义为该目录的基本公共 URL。确保这个目录是可以被网络服务器的用户账户写入的。
- 将 FileField 或 ImageField 添加到模型中,定义 upload_to 选项,指定 MEDIA_ROOT 的子目录,用于上传文件。
- 所有这些将被存储在数据库中的是一个文件的路径(相对于 MEDIA_ROOT )。很可能要使用 Django 提供的方便的 url 属性。例如, ImageField 的上传路径叫做 mug_shot,可以在模板中使用 {{ object.mug_shot.url }} 获取图片的绝对路径。
例如,MEDIA_ROOT 设置为 '/home/media', upload_to 设置为 'photos/%Y/%m/%d'。upload_to 中的 '%Y/%m/%d' 部分是 strftime() 格式化,'%Y' 是四位数的年,'%m' 是两位数的月,'%d' 是两位数的日。如果在 2007 年 1 月 15 日上传了一个文件,它将被保存在 /home/media/photos/2007/01/15 目录下。
如果想检索上传文件的盘上文件名,或者文件的大小,可以分别使用 name 和 size 属性;关于可用属性和方法的更多信息,会在后面继续学习中补充文件管理的配置。
上传的文件的相对 URL 可以通过 url 属性获得。内部调用底层 Storage 类的 store() 方法。
请注意,无论何时处理上传的文件,都应该密切注意在哪里上传文件以及它们是什么类型的文件,以避免安全漏洞。 验证所有上传的文件 ,这样就能确定文件是认为的那样。例如,如果盲目地让别人上传文件,而不进行验证,直接到网站服务器的文件根目录中,那么有人就可以上传 CGI 或 PHP 脚本,并通过访问网站上的 URL 来执行该脚本。不要允许这样做。
另外要注意的是,即使是上传的 HTML 文件,由于可以被浏览器执行(虽然不能被服务器执行),也会造成相当于 XSS 或 CSRF 攻击的安全威胁。
FileField 实例在数据库中被创建为 varchar 列,默认最大长度为 100 个字符。与其他字段一样,你可以使用 max_length 参数改变最大长度。
FileField 和 FieldFile:class FieldFile
当访问一个模型上的 FileField 时,会得到一个 FieldFile 的实例作为访问底层文件的代理。
FieldFile 的 API 与 File 的 API 相同,但有一个关键的区别。该类所封装的对象不一定是 Python 内置文件对象的封装 相反,它是 Storage.open() 方法结果的封装,该方法可能是 File 对象,也可能是自定义存储对 File API 的实现。
除了从 File 继承的 API,如 read() 和 write() 之外,FieldFile 还包括一些可以用来与底层文件交互的方法:
- FieldFile.name:返回文件的名称(包括文件扩展名),包括文件的相对路径。这通常是文件在存储系统中的唯一标识符示例:
myfile.name可能返回'uploads/myfile.jpg'。 - FieldFile.path:一个只读属性,通过调用底层的 path() 方法,访问文件的本地文件系统路径。
- FieldFile.size:底层 Storage.size() 方法的结果。
- FieldFile.url:一个只读属性,通过调用底层 Storage 类的 Storage() 方法来访问文件的相对 URL。
验证器
验证器是可调用的函数,它接收一个值,如果该值不满足某些条件,则会引发一个ValidationError异常。验证器可用于在不同类型的字段之间重用验证逻辑,以提高代码的可维护性和复用性。
# 这里有一个只允许偶数的验证器
from django.core.exceptions import ValidationError
from django.utils.translation import gettext_lazy as _
def validate_even(value):
if value % 2 != 0:
raise ValidationError(
_("%(value)s is not an even number"),
params={"value": value},
)
# 可以通过字段的 validators 参数将其添加到模型字段
from django.db import models
class MyModel(models.Model):
even_field = models.IntegerField(validators=[validate_even])
# 在验证器运行之前,值已经被转换为 Python,甚至可以在表单中使用相同的验证器
from django import forms
class MyForm(forms.Form):
even_field = forms.IntegerField(validators=[validate_even])也可以使用一个带有 __call__() 方法的类,用于更复杂或可配置的验证器。 RegexValidator,例如,使用了这种技术。如果在 validators 模型字段选项中使用了一个基于类的验证器,应该通过添加 deconstruct() 和 __eq__() 方法来确保它是可由迁移框架序列化。

















 161
161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









