







前言:
这个实验要求用Gitee,笔者之前没有用过gitee或者github,对这个网站也不太熟,可以将所谓“实验仓库”简单的看成我们E盘(举例)中的一个文件夹,所以要注意一下各个文件、文件夹之间的联系,以及文件中链接的跳转。
而且本实验需要用git命令进行实验的下载和上传,当然也可以直接在网页上下载/上传,但是助教说还是尽量使用git,也算是学习使用一个新的东西,以后也可能会用到。
1.环境配置
“编译原理实验环境搭建”:Documentations/environments.md(仓库路径)
我是直接用的vmware中的ubuntu22.04(建议是20.04,不过我用22.04也没遇到什么问题),这个计算机系统、操作系统、数据挖掘(专选)都要求用了,就没用新的环境。另外,正如前面第一段所说,要注意一下各个文件、文件夹之间的联系。不要一上来就直接打开src/lexer/lexical_analyzer.l开始补全,下面是可能会忽略的几个点:
(1)安装LLVM
① 可以直接在Linux下命令行输入 sudo apt-get install llvm bison flex
安装完成后可以输入下面两行进行验证。
flex --version
bison --version
② 如果没有进行这一步,在camke ../或make lexer的时候可能会报错。如果看下报错信息的话,可以发现其中提到了没有llvm,然后安装就行。
(2)git的使用
① 实验手册中的方法
a.实验仓库克隆到本地
打开本地的工作目录,在命令行中输入
git clone https://gitee.com/你的gitee用户名/cminus_compiler-2021-fall.git
“你的gitee用户名”是打开个人主页,昵称下面有个“@……”,用户名就是@后面的一串字符;或者打开仓库,在最上边的https://gitee.com……也可以看到。
克隆到本地或者虚拟机还是建议用上边的命令行,如果直接在网页下载然后拖拽/复制粘贴到虚拟机的话可能会有问题(在下面的(3)测试python错误的一个可能)
b.将工作上传至git仓库
打开本地的工作目录,在命令行中输入
git add *
git commit -m "注释语句"
c. 然后push到仓库
git push
② Git Gui
笔者实验过程中,clone没什么问题,不过用git提交不太熟。可以用git的图形化界面git gui比较简单(注意,这个必用git clone下载到本地,直接在网页下载zip的话,笔者用git gui提交会报错)。当然,如果你对git的使用比较熟悉,不比听我的拙见。
a. 打开git gui,选择之间clone下来的文件夹。(注意若clone之后在网页端有修改,则需要重新clone)

b.依次选择stage,sign,commit,push.(sign off时可以在右下角的框里输入提交信息)
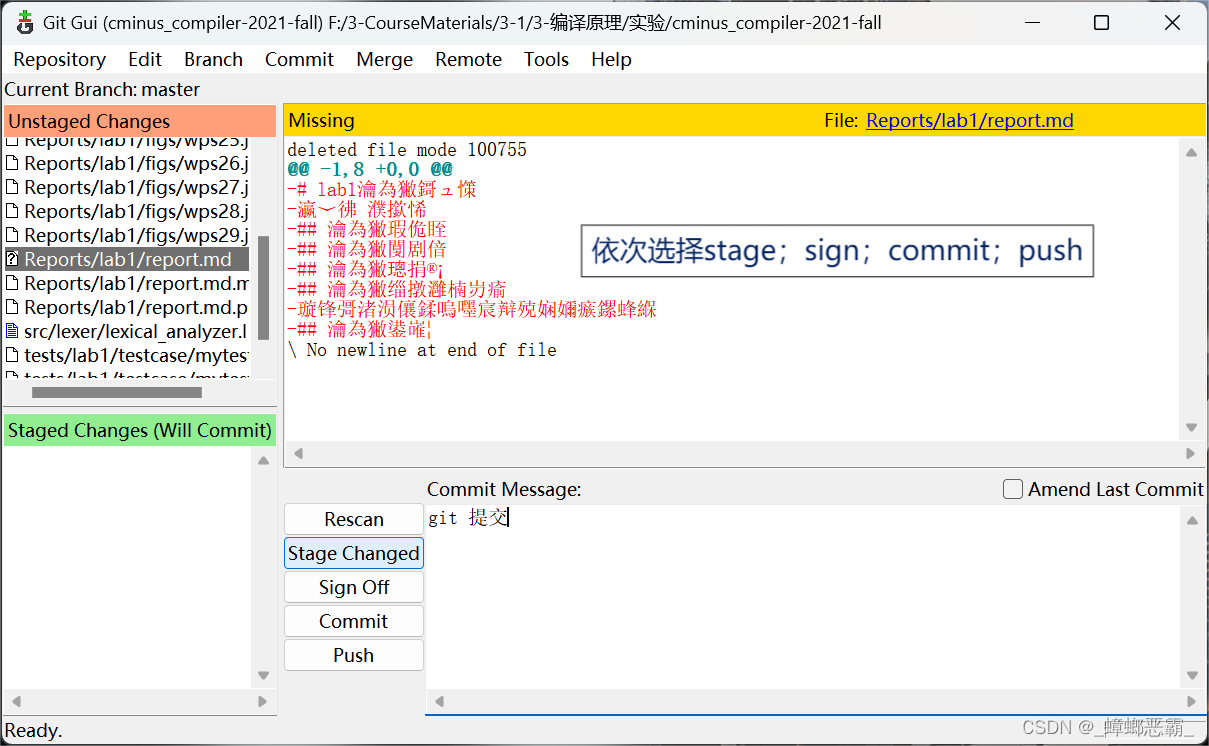
c.可能遇到错误,仔细看提示信息会让你输入两条命令行。
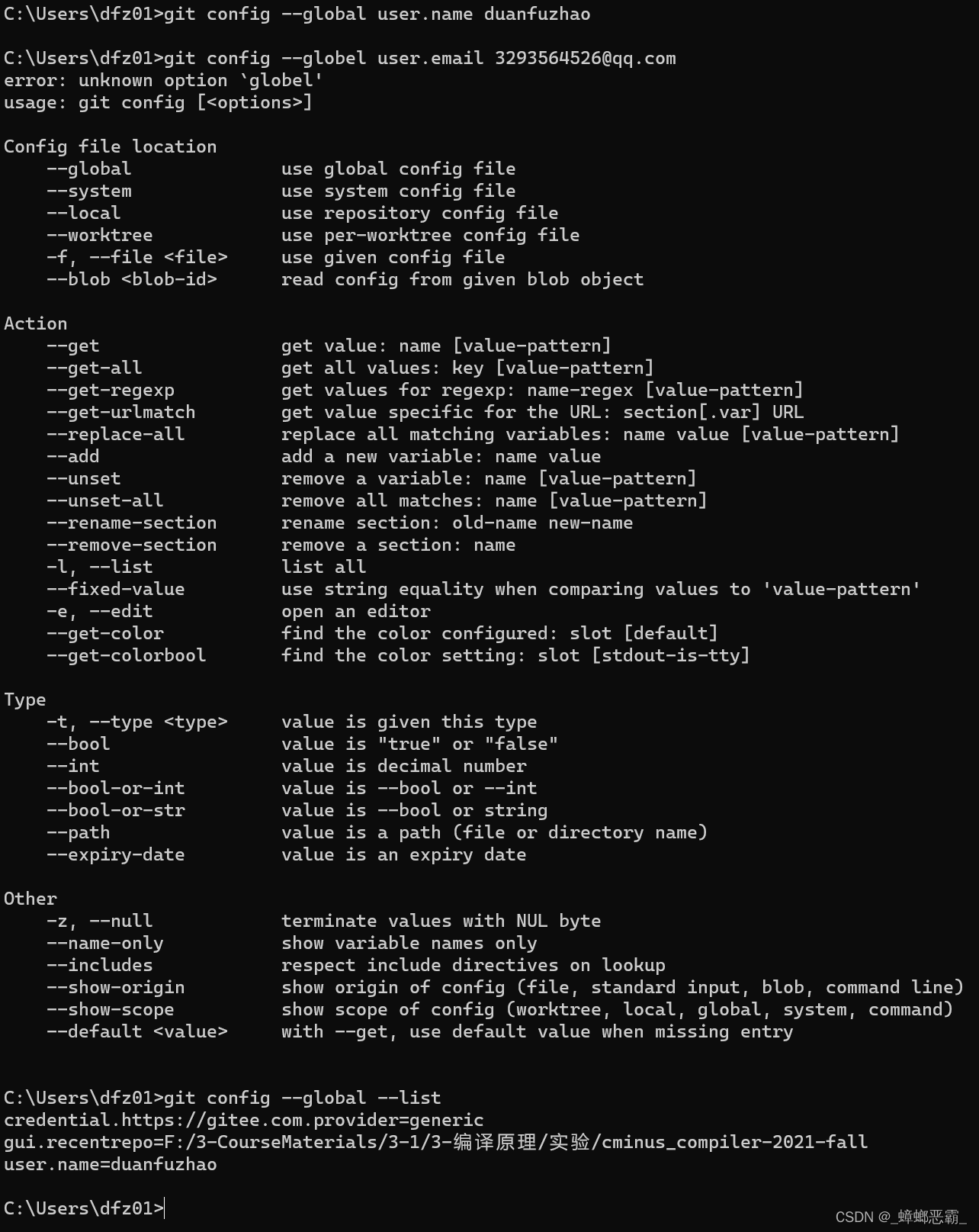
git config --global user.email "xx@email.com"
git config --global user.name "name"
(第二条的name跟上边的①.a相同; 另外,你可能需要用管理员身份大概终端输入命令)
d.然后再push这样就成功了。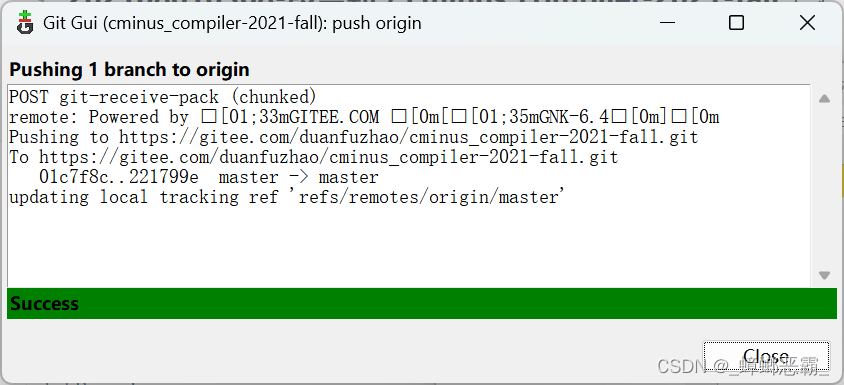
(3)测试python错误的一个可能
正如上面(2)-①-a中所说,克隆到本地或者虚拟机还是建议用上边的命令行,如果直接在网页下载然后拖拽/复制粘贴到虚拟机的话可能会有问题。
① 问题描述:查看运行错误的tokens,发现都是每行的末尾识别出错误;
② 问题原因:文件格式不同: Windows 和 Linux 使用不同的 行尾符。Windows 使用回车符(CR)和换行符(LF) ("\r\n"),而 Linux 使用换行符(LF)("\n")。
③ 解决方法:
在 linux 中使用 touch 新建文件:这样会自动使用换行符(LF)("\n"),而非 CRLF;
改动 lexer.analysize.l 文件:增加\r\n {return EOL;}, 这样就可以识别 Windows 中的 CRLF。
一、实验要求
1.要求
根据cminux-f的词法补全文件lexical_analyzer.l,完成词法分析器。
能够输出识别出的token,type ,line(刚出现的行数),pos_start(该行开始位置),pos_end(结束的位置,不包含)。
2.举例
(1)文本输入:
int a;
(2)识别结果:
| Token | Type | Line | Pos_start | Pos_end |
|---|---|---|---|---|
| int | 280 | 1 | 2 | 5 |
| a | 285 | 1 | 6 | 7 |
| ; | 270 | 1 | 7 | 8 |
特别说明:对于部分token,我们只需要进行过滤,即只需被识别,但是不应该被输出到分析结果中。因为这些token对程序运行不起到任何作用。
二、实验难点
1. 实验结果的提交。
第一次使用git提交到Gitee中。
2. 写出需要识别的token的正则表达式。
(1)Lex源程序的格式:
*声明部分:*变量的定义和声明,会直接复制到lex.yy.c中。
*转换规则:*形式为:模式{动作},模式为正则表达式,动作则是代码片段。
*辅助函数:*各个动作需要的辅助函数。用户自定义,直接复制到lex.yy.c末尾。
(2)注释
匹配的原则是最长匹配,但是如果有多个注释,中间的代码会被当作注释的内容匹配:
在进行匹配时,/*和*/之间不能有*/,即中间的连续字符可以划分为两种情况:
没有出现:可以表示为[^*]
*后加除/以外的任何字符:*+[^/]
"/"([^]|*+[^*/)*+"/"
三、实验设计
1. 补全lexical_analyer.l文件
(1)需要识别的token
① lexical_analyzer.h
需要识别的token在 lexical_analyzer.h中 定义,相应token以及其对应的字符、编号和含义,如下:
typedef enum cminus_token_type {
//运算
ADD = 259,
SUB = 260,
MUL = 261,
DIV = 262,
LT = 263,
LTE = 264,
GT = 265,
GTE = 266,
EQ = 267,
NEQ = 268,
ASSIN = 269,
//符号
SEMICOLON = 270,
COMMA = 271,
LPARENTHESE = 272,
RPARENTHESE = 273,
LBRACKET = 274,
RBRACKET = 275,
LBRACE = 276,
RBRACE = 277,
//关键字
ELSE = 278,
IF = 279,
INT = 280,
FLOAT = 281,
RETURN = 282,
VOID = 283,
WHILE = 284,
//ID和NUM
IDENTIFIER = 285,
INTEGER = 286,
FLOATPOINT = 287,
ARRAY = 288,
LETTER = 289,
//others
EOL = 290,
COMMENT = 291,
BLANK = 292,
ERROR = 258
} Token;② 正则表达式
运算、符号:对应英文状态下的半角符号。
关键字: 对应的小写状态。
ID,NUM:使用语法糖以简化构造;
变量名:a-z/A-Z的1或多个字母的组合,即[a-zA-Z]+。
整数: 从0-9中选一个或多个数,即[0-9]+。
浮点数:[0-9]+.|[0-9]*.[0-9]+,小数点前后各有0或多个数字。‘.’前要加\转义符,否则会当做任意字符来匹配。
数组: 要匹配数组[],则两个框都要加转义符。因为[和]和[]是三个不同的表示。
其他符号
换行符:[\n]+,因为要实现一到多行的换行。
注释符:注释不能嵌套。"/"([^]|*+*/)**+"/"
空白符:[ \f\n\r\t\v],包括空格、制表符、换页符等。
ERROR:错误可以匹配任何字符,所以用.来表示错误,
| Token | Type | 正则表达式 |
|---|---|---|
| ADD | 25 | + |
| SUB | 260 | - |
| MUL | 261 | * |
| DIV | 262 | / |
| LT | 263 | < |
| LTE | 264 | <= |
| GT | 265 | > |
| GTE | 266 | >= |
| EQ | 267 | == |
| NEQ | 268 | != |
| ASSIN | 269 | = |
| SEMICOLON | 270 | ; |
| COMMA | 271 | , |
| LPARENTHESE | 272 | ( |
| RPARENTHESE | 273 | ) |
| LBRACKET | 274 | [ |
| RBRACKET | 275 | ] |
| LBRACE | 276 | { |
| BBRACE | 277 | } |
| ELSE | 278 | else |
| IF | 279 | if |
| INT | 280 | int |
| FLOAT | 281 | float |
| RETURN | 282 | return |
| VOID | 283 | void |
| WHILE | 284 | while |
| IDENTIFIER | 285 | [a-zA-Z]+ |
| INTEGER | 286 | [0-9]+ |
| FLOATPOINT | 287 | [0-9]+.|[0-9]*.[0-9]+ |
| +ARRAY | 288 | [] "[]" |
| LETTER | 289 | [a-zA-Z] |
| EOL | 290 | [\n]+ |
| COMMENT | 291 | "/"([^]|*+*/)**+"/" |
| BLANK | 292 | [ \f\n\r\t\v] |
| ERROR | 293 |
注:标识符的识别规则要在letter的上方,否则单个字符不会被识别为标识符。
③ 指定模式匹配时对应的动作
yytext指针指向本次匹配的输入文本;*左部分*写要匹配的正则表达式;*右部分*为匹配到该正则表达式后执行的动作。
%%
/*你可以在这里使用你熟悉的正则表达式来编写模式*/
/*你可以用C代码来指定模式匹配时对应的动作*/
/*yytext指针指向本次匹配的输入文本*/
/*左部分([a-zA-Z]+)为要匹配的正则表达式,
右部分({ chars += strlen(yytext);words++;})为匹配到该正则表达式后执行的动作*/
[a-zA-Z]+ { chars += strlen(yytext);words++;}
. {}
/*对其他所有字符,不做处理,继续执行*/
%%题目要求能够输出识别出的token,type ,line(刚出现的行数),pos_start(该行开始位置),pos_end(结束的位置,不包含) 。
pos_start开始的位置:*和结束位置设置成一样,代表当前识别的字符从上一识别完的字符的末尾开始。
pos_end结束的位置:pos_end+=strlen(yytext) ,对于运算符,符号和关键字,长度是确定的,可以直接加上长度,不需要调用sterlen。
Line出现的行数:可以在识别到换行符时lines++实现。
Token:返回识别出的token即可。
/******** 运算 ********/
\+ {pos_start = pos_end; pos_end++; return ADD;}
\- {pos_start = pos_end; pos_end++; return SUB;}
\* {pos_start = pos_end; pos_end++; return MUL;}
\/ {pos_start = pos_end; pos_end++; return DIV;}
\< {pos_start = pos_end; pos_end++; return LT;}
"<=" {pos_start = pos_end; pos_end+=2; return LTE;}
\> {pos_start = pos_end; pos_end++; return GT;}
">=" {pos_start = pos_end; pos_end+=2; return GTE;}
"==" {pos_start = pos_end; pos_end+=2; return EQ;}
"!=" {pos_start = pos_end; pos_end+=2; return NEQ;}
\= {pos_start = pos_end; pos_end++; return ASSIN;}
/******** 符号 ********/
\; {pos_start = pos_end; pos_end++; return SEMICOLON;}
\, {pos_start = pos_end; pos_end++; return COMMA;}
\( {pos_start = pos_end; pos_end++; return LPARENTHESE;}
\) {pos_start = pos_end; pos_end++; return RPARENTHESE;}
\[ {pos_start = pos_end; pos_end++; return LBRACKET;}
\] {pos_start = pos_end; pos_end++; return RBRACKET;}
\{ {pos_start = pos_end; pos_end++; return LBRACE;}
\} {pos_start = pos_end; pos_end++; return RBRACE;}
/******** 关键字 ********/
else {pos_start = pos_end; pos_end+=4; return ELSE;}
if {pos_start = pos_end; pos_end+=2; return IF;}
int {pos_start = pos_end; pos_end+=3; return INT;}
float {pos_start = pos_end; pos_end+=5; return FLOAT;}
return {pos_start = pos_end; pos_end+=6; return RETURN;}
void {pos_start = pos_end; pos_end+=4; return VOID;}
while {pos_start = pos_end; pos_end+=5; return WHILE;}
/******** ID和NUM ********/
[a-zA-Z]+ {pos_start = pos_end; pos_end+=strlen(yytext); return IDENTIFIER;}
[a-zA-Z] {pos_start = pos_end; pos_end++; return LETTER;}
[0-9]+ {pos_start = pos_end; pos_end+=strlen(yytext); return INTEGER;}
[0-9]+\.|[0-9]*\.[0-9]+{pos_start=pos_end;pos_end+=strlen(yytext);return FLOATPOINT;}
"[]" {pos_start = pos_end; pos_end+=2; return ARRAY;}
/******** others ********/
\n {return EOL;}
"/*"([^*]|\*+[^*/])*\*+"/" {return COMMENT;}
[" "|\t] {pos_start = pos_end; pos_end+=strlen(yytext);return BLANK;}
. {return ERROR;}(2)analyzer函数
关于匹配到注释COMMENT、空格BLANK、换行EOL后执行的动作在analyzer函数中实现。
case COMMENT: //注释
len = strlen(yytext);
for(int i=0;i<len;i++){//循环判断注释中是否存在换行符
if(yytext[i]=='\n') {//yytext[i]是换行\n
lines++;{ //则将lines加1;
pos_end = 1; //将pos_start和pos_end设置为1
}
else pos_end++; //否则pos_end++;
}
break; //当循环结束则break;
case BLANK:
break;
case EOL:
lines++;
pos_end = 1;
break;四、实验结果验证
1. 编译
(1)Cmake
① 报错
创建build文件夹,配置编译环境, 执行指令cmake ../时出错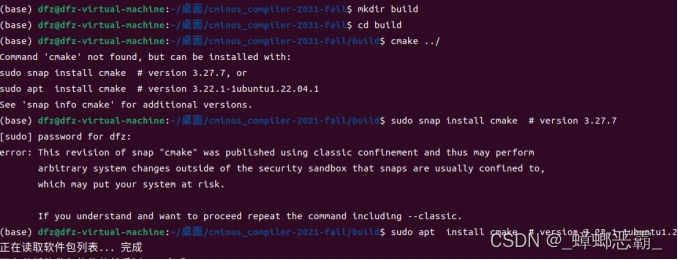
② Sudo apt install
③ 成功
安装cmake后成功:
(2)make lexer
执行指令make lexer运行代码,编译:
2. 运行test_lexer.py
执行指令python3 ./tests/lab1/test_lexer.py来查看,结果通过了6个测试样例: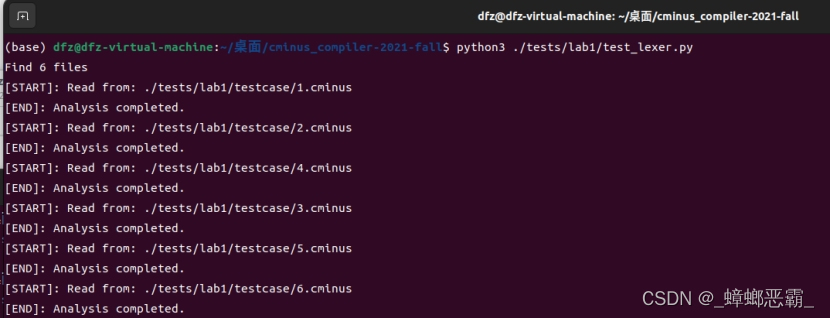
3. 比较diff
diff ./tests/lab1/token ./tests/lab1/TA_token 将自己的生成结果和助教提供的TA_token进行比较。
没有任何输出结果,表示结果是正确的。
4. 自行设计testcase
(1) Mytest1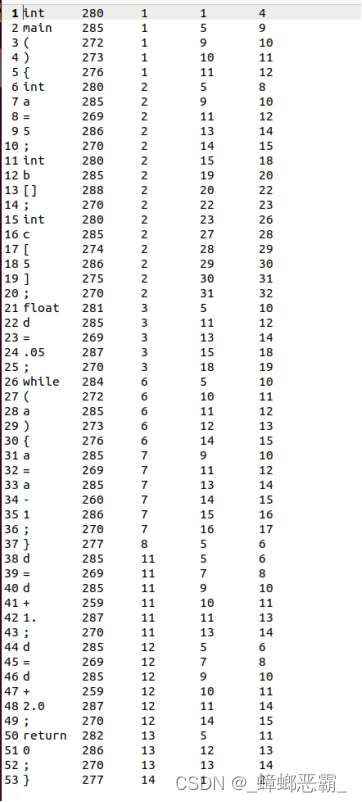
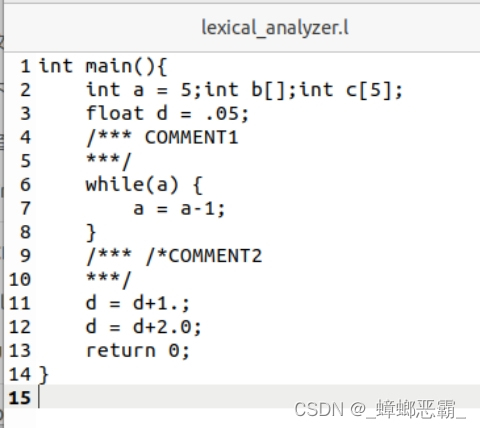
(2) Mytest2

五、实验反馈
通过本次实验,我对正则表达式有了更加深刻的理解。如对于注释的正则表达式,多个注释时,中间的代码会被当作注释的内容匹配。
同时在做这次实验也遇到了一些困难,比如gitee的使用问题,由于之前没使用过gitee,对于gitee上的很多操作都很不熟悉。
但是,通过实践生成词法分析器,补充完了一个识别token的程序,从而实现对输入的词法进行识别和分析的功能,并能准确给出token所在行,开始位置和结束位置,我对于课程中的正则表达式、词法分析器flex等有了更为深入的认识。















 2052
2052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









