







参考:
芜湖韩金轮_HNU计算机结构体系-实验2:CPU动态指令调度Tomasulo
一、实验目的
- 熟悉Tomasulo模拟器
- 加深对Tomasulo算法的理解,从而理解指令级并行的一种方式-动态指令调度。
- 掌握在指令流出、执行、写结果各阶段,对浮点操作、load、store指令进行什么处理;
- 给定被执行代码片段,对于具体某个时钟周期,能够写出保留站、指令状态表、浮点寄存器状态表内容的变化情况。
二、实验说明
学习ScoreBoard和Tomasulo算法,并且进行Tomasulo算法的模拟实验,同时熟悉动态指令调度相关知识。
三、实验内容
1、Tomasulo算法模拟器
使用模拟器进行以下指令流的执行并对模拟器截图、回答问题
L.D F6, 21(R2)
L.D F2, 0 (R3)
MUL.D F0, F2, F4
SUB.D F8, F6, F2
DIV.D F10,F0, F6
ADD.D F6, F8, F2
题中假设浮点功能部件的延迟时间:加减法2个周期,乘法10个周期,load/store2个周期,除法40个周期。
0)设置指令和参数
直接用下拉框选择就行,默认的功能部件的执行时间即为要求的:

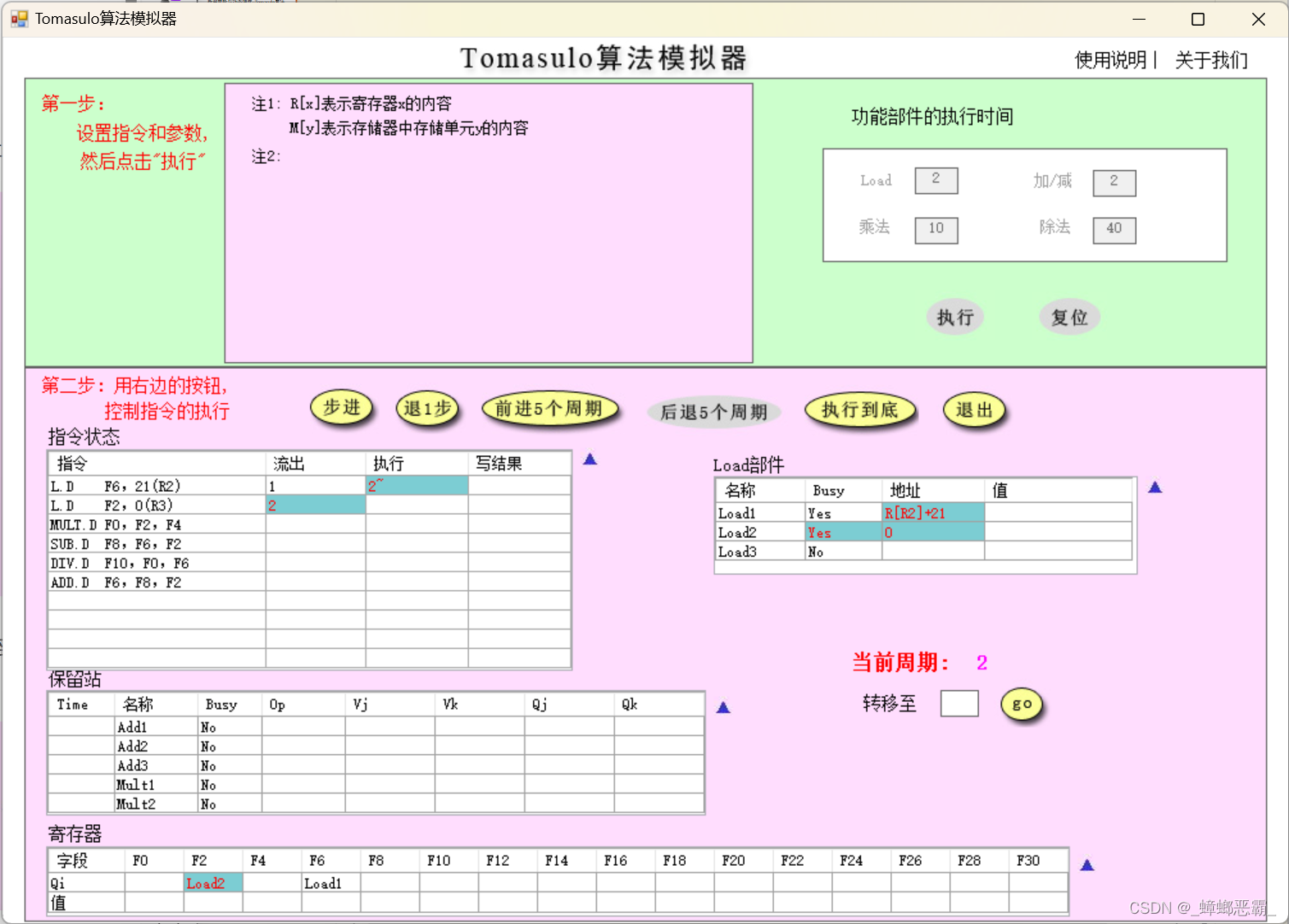
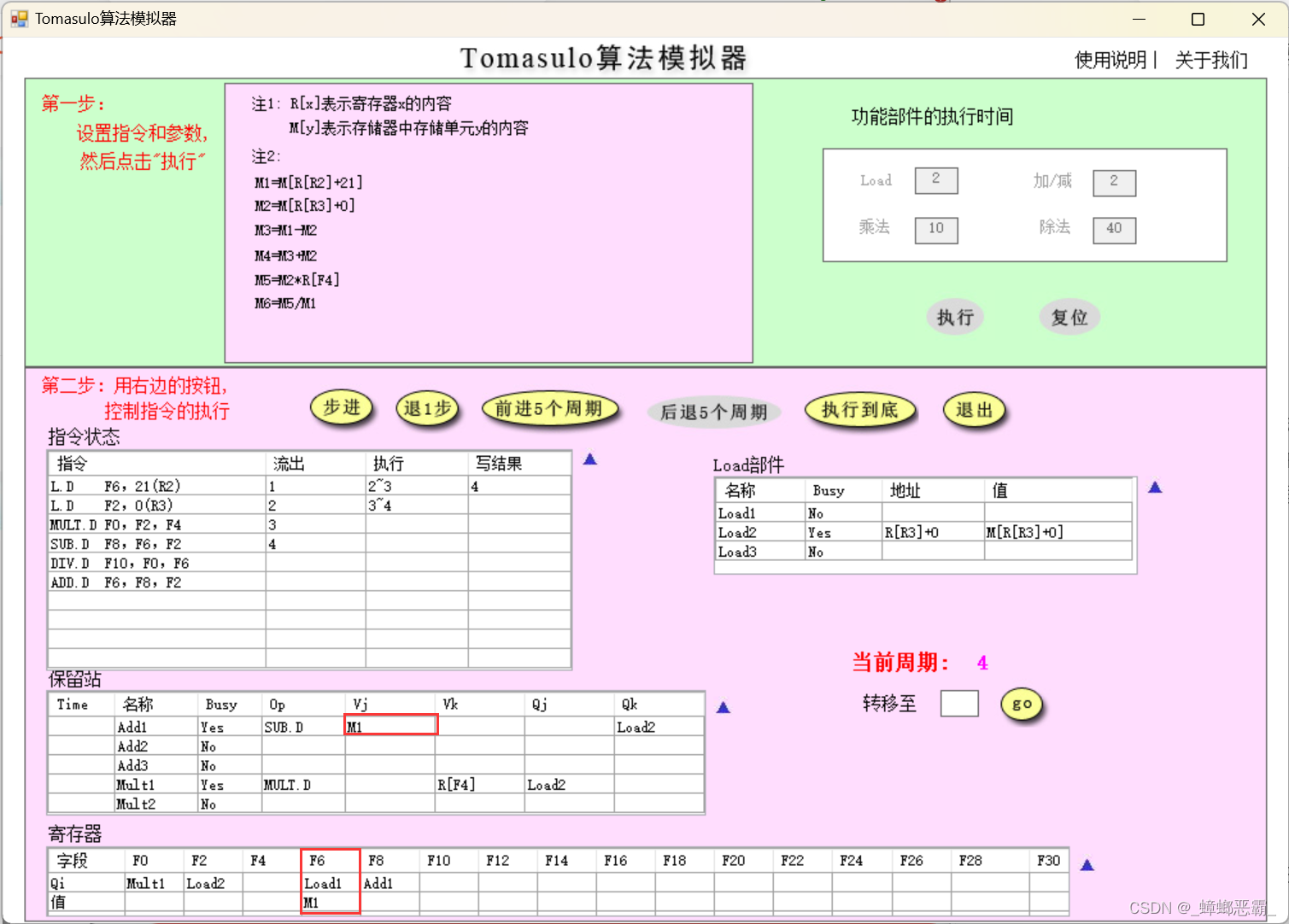
1)周期2、3的load部件
分别截图(当前周期2和当前周期3),请简要说明load部件做了什么改动
a)周期2:
说明:抹色的区域表示最近一个时钟周期其内容发生了变化;
说明:状态表的右上角外侧都有一个小三角,用鼠标左键点击它,会弹出该表在上一个时钟周期的内容;
-
指令状态:
- 指令1开始执行;指令2流出
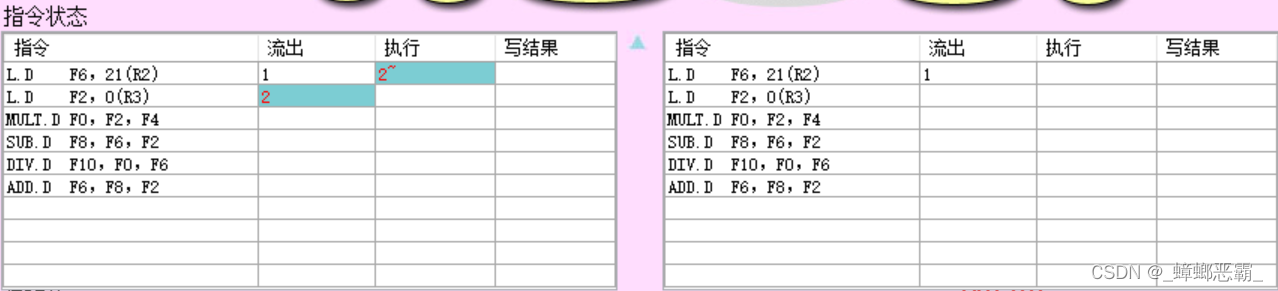
- 指令1开始执行;指令2流出
-
保留站:
- 没有运算指令,这里的保留站为空;
-
寄存器:
- 写入寄存器F2的保留站的站号为:Load2

- 写入寄存器F2的保留站的站号为:Load2
-
Load部件:
- Load1:部件的地址寄存器设为R[R2]+21;
- Load2:部件填入了指令2,Busy置位,地址寄存器设为0;

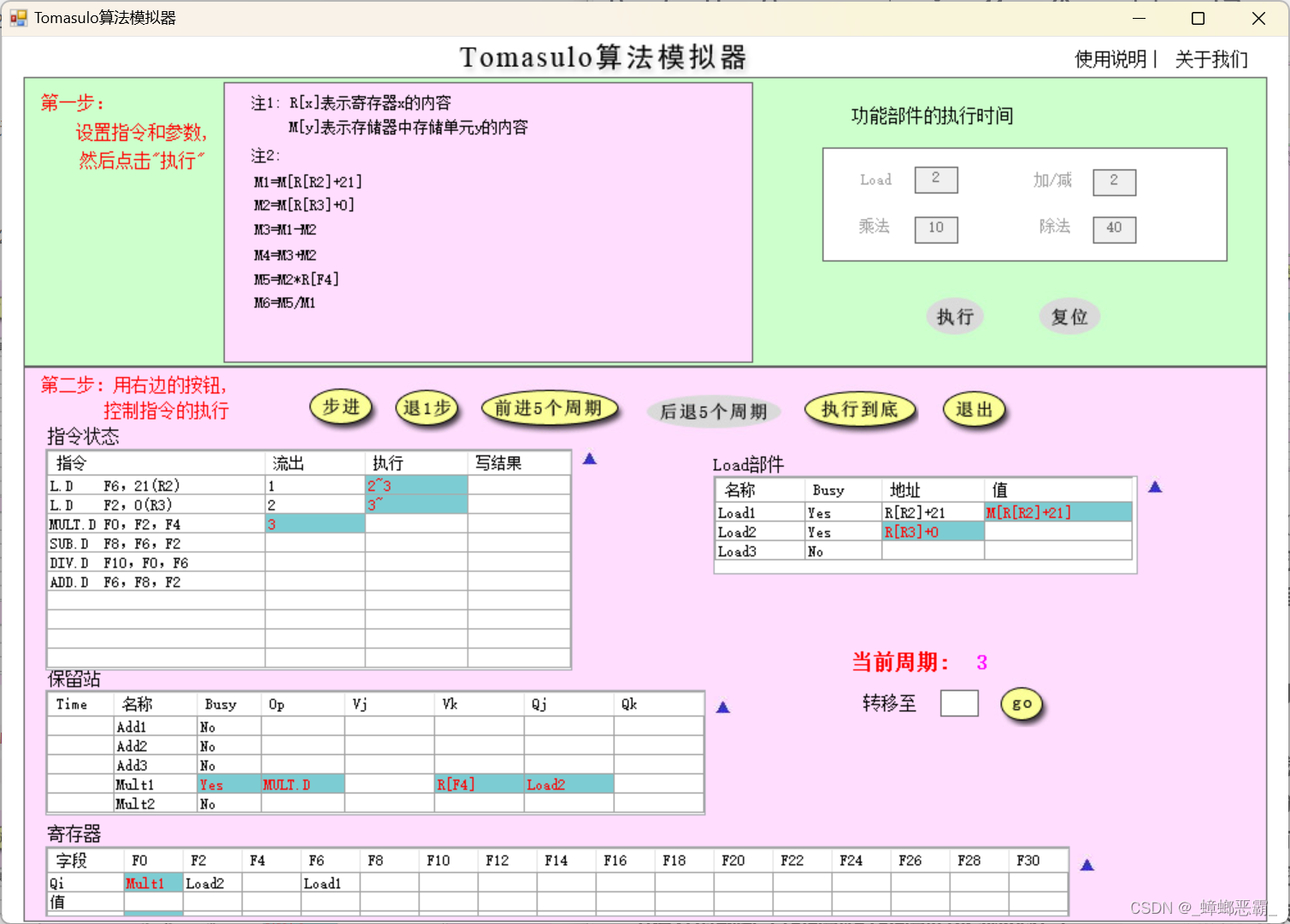
b)周期3:
-
指令状态:
- 指令1执行完成;指令2开始执行;指令3流出;
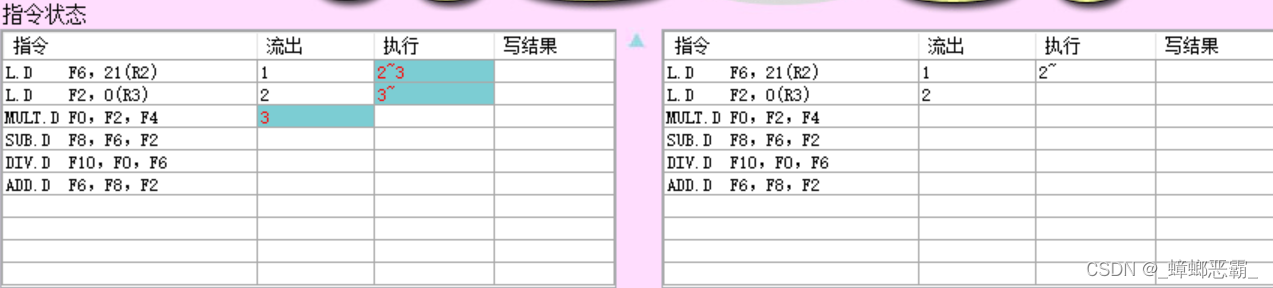
- 指令1执行完成;指令2开始执行;指令3流出;
-
保留站:
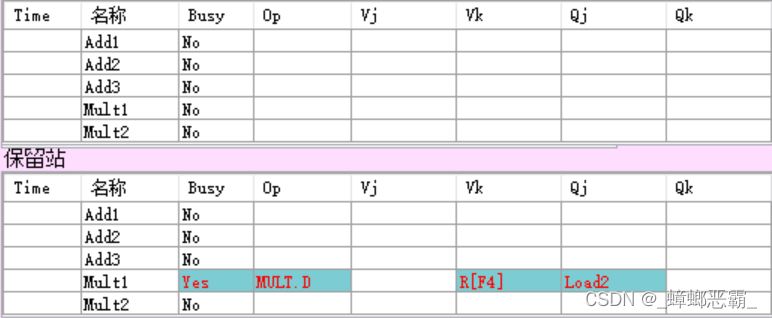
- 流出的指令3,操作为MULT.D,占用保留站Mult1;
- 源操作数是F2、F4;检查寄存器可知:
- F2-Qj:保留站的站号为Load2;本指令需等Load2写回;【RAW】
- F4-Vk:无保留站,直接读寄存器即可R[F4]
-
寄存器:
- 写入寄存器F0的保留站的站号为:Mult1

- 写入寄存器F0的保留站的站号为:Mult1
-
Load部件:
- Load1:从存储器读地址为R[R2]+21 的值,保存在Load1部件寄存器;
- Load2:部件的地址寄存器设为R[R3]+0;

-
寄存器重命名:这里为后面的思考题WAW、WAR做准备
- 一个新的指令流出,进入保留站之后,在寄存器中检查对应的操作数:
- 源操作数:寄存器–>保留站
- 非Busy:直接取值,填到本指令的保留站的Vj/Vk即可;
- Busy:使用该操作数寄存器的保留站Qi,填到本指令的保留站的Qj/Qk;
- 目的操作数:保留站–>寄存器
- 将本指令的保留站的站名,填到该操作数寄存器的保留站的Qi,并把Busy设为yes
- 源操作数:寄存器–>保留站
- 一个新的指令流出,进入保留站之后,在寄存器中检查对应的操作数:
2)MUL.D刚开始执行时系统状态
请截图(MUL.D刚开始执行时系统状态),并说明该周期相比上一周期整个系统发生了哪些改动(指令状态、保留站、寄存器和Load部件)
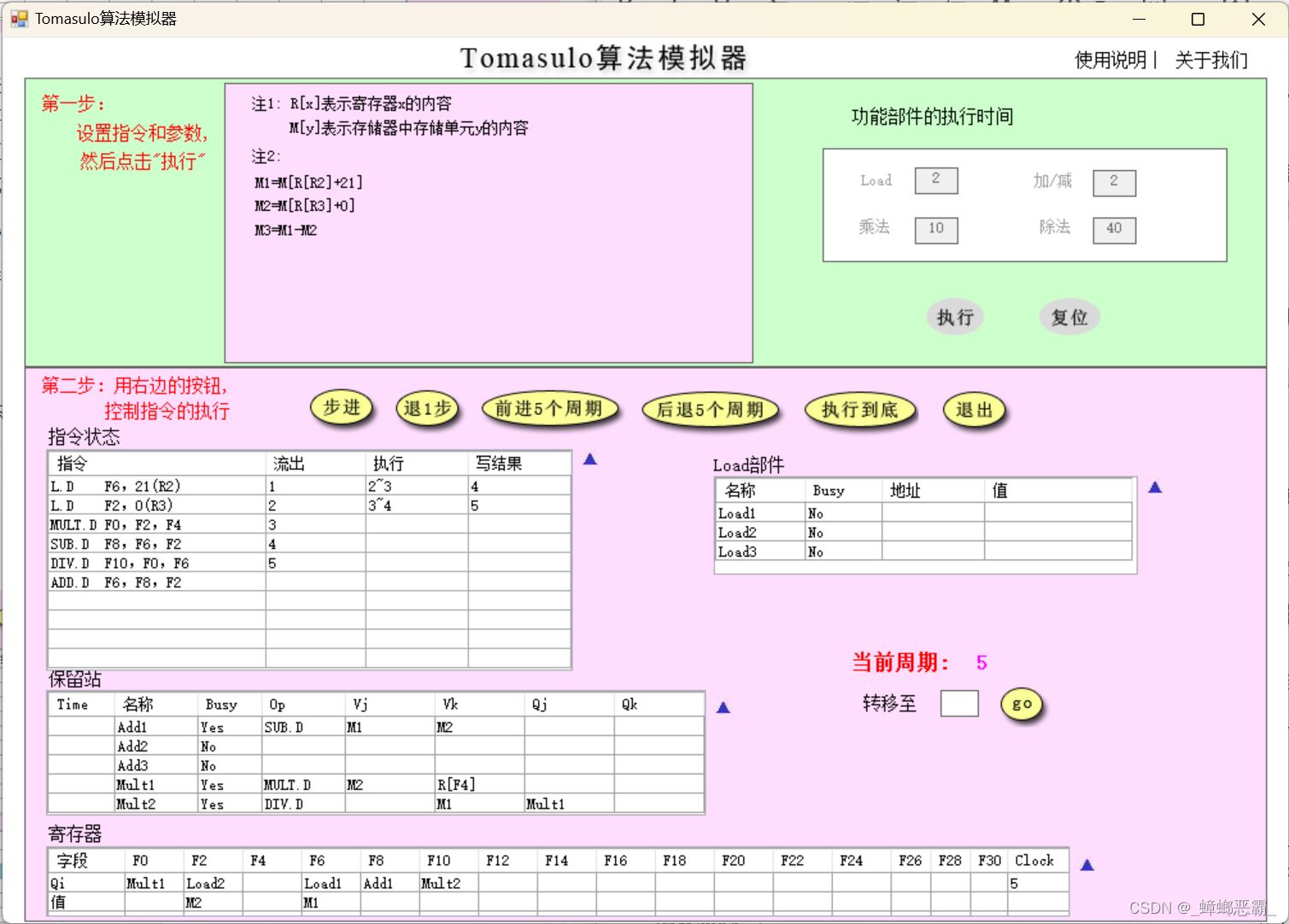
a)MUL.D开始执行的上一周期–周期5
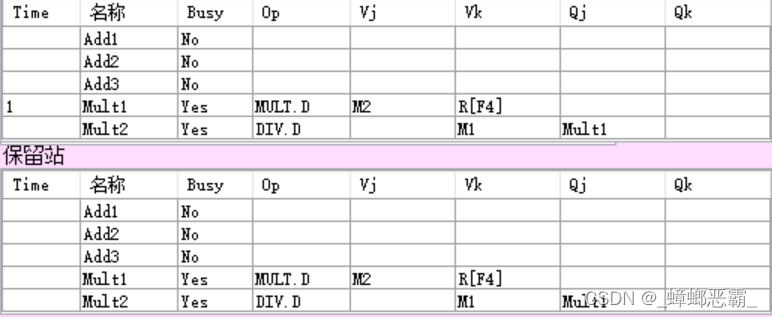
这里其实周期5,指令2 L.D F2,0(R3)写回寄存器的时候,保留站中Add1和Mult1已经通过CDB得到了F2的值M2,但是需到周期6才开始执行。
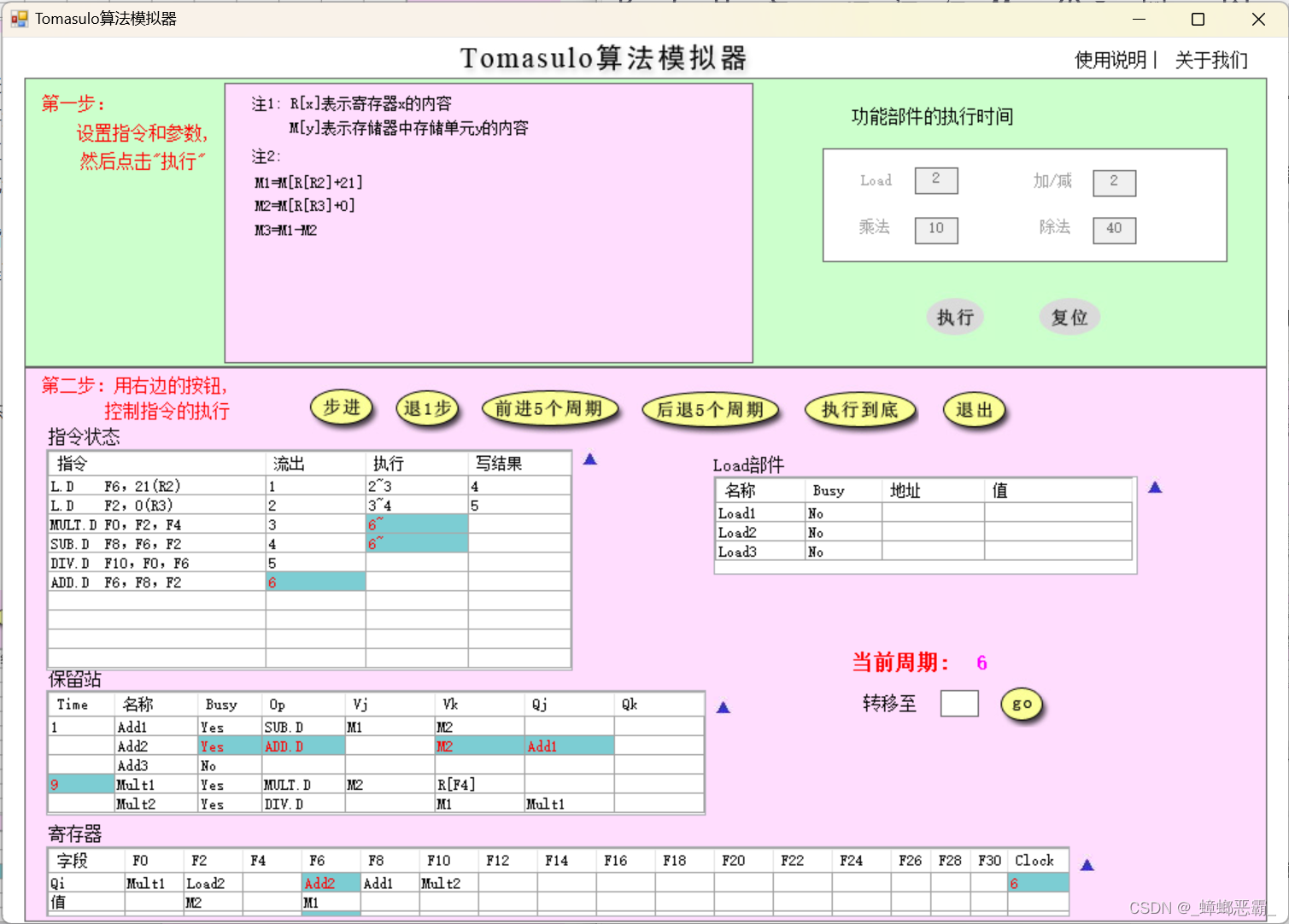
b)MUL.D刚开始执行的周期–周期6(与周期5对比分析)
-
指令状态:
- 指令3、4开始执行;指令6流出
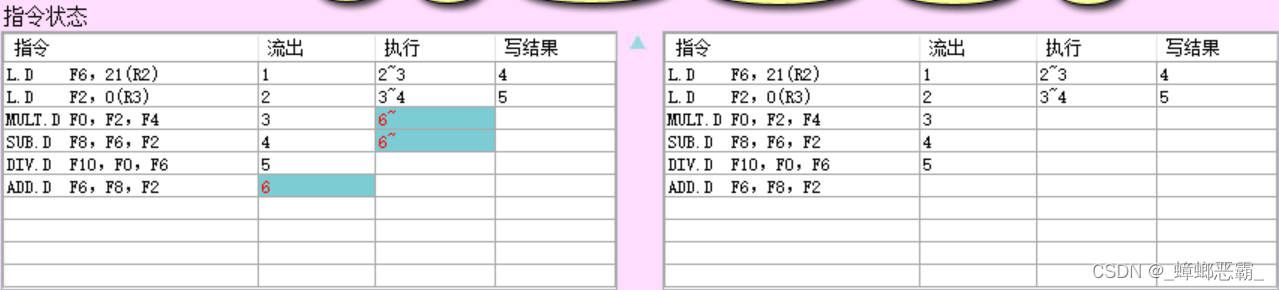
- 指令3、4开始执行;指令6流出
-
保留站:
- 流出的指令6,操作为ADD.D,占用Add2保留站;
- 源操作数是F8、F2;检查寄存器可知:
- F8-Qj:保留站的站号为Add1;本指令需等Add1写回;
- F2-Vk:Load2已写回M2,直接取该值即可;
- Time:表示相应的保留站还有要执行多少个时钟周期;
- 指令SUB.D和MUL.D开始执行,时间开始倒计时;
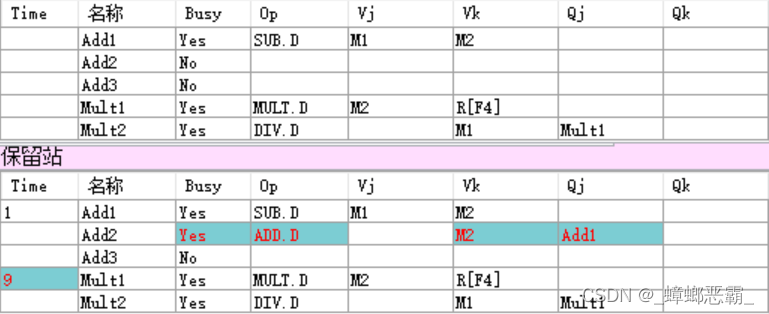
- 指令SUB.D和MUL.D开始执行,时间开始倒计时;
-
寄存器:
- 写入寄存器F6的保留站的站号,更改为Add2

- 写入寄存器F6的保留站的站号,更改为Add2
-
这里其实有点问题:
-
寄存器既然已经写入了值M1/M2,应该把上面的Qi(Load1/Load2)删去(比如下面两张图就是PPT中的例子,在Load1写回F6后,寄存器结果状态中的F6处的Load1就删去了);不然其他指令取该寄存器的值的时候,是直接取M1/M2呢,还是等Qi写回呢
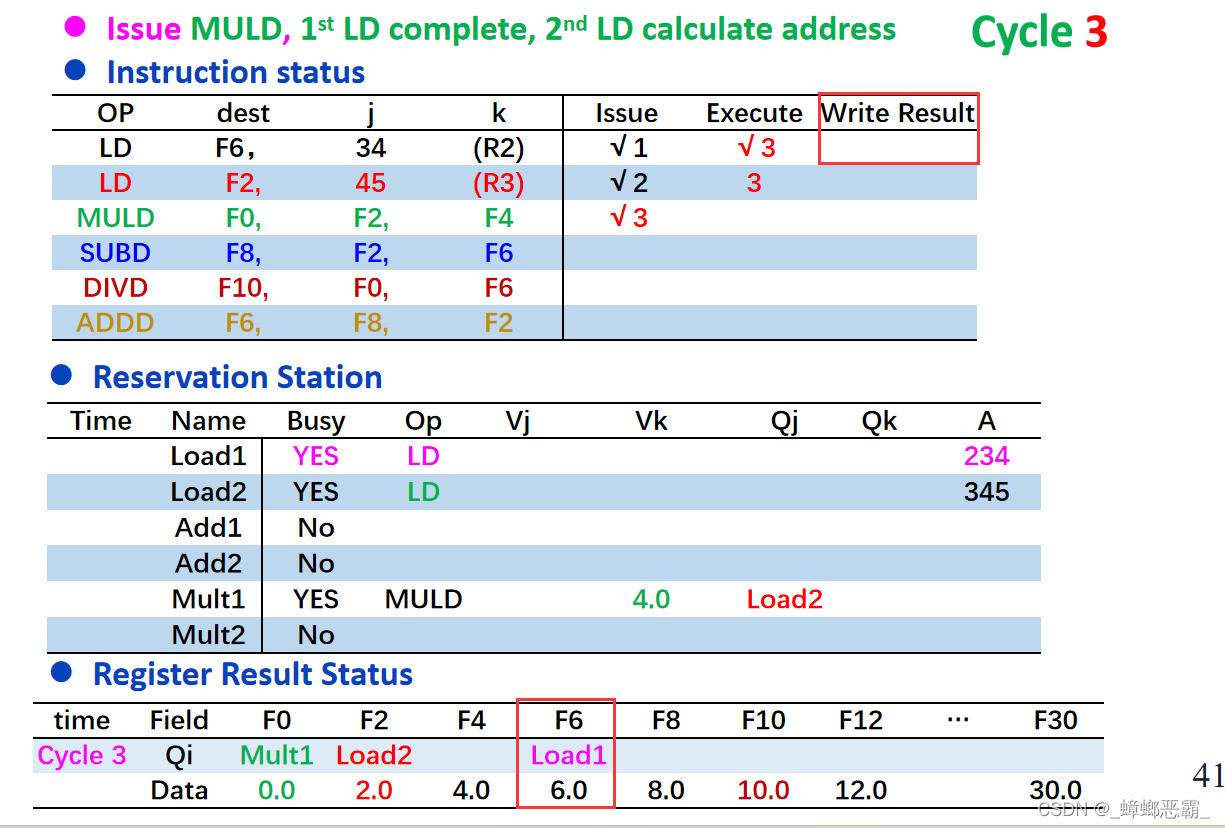
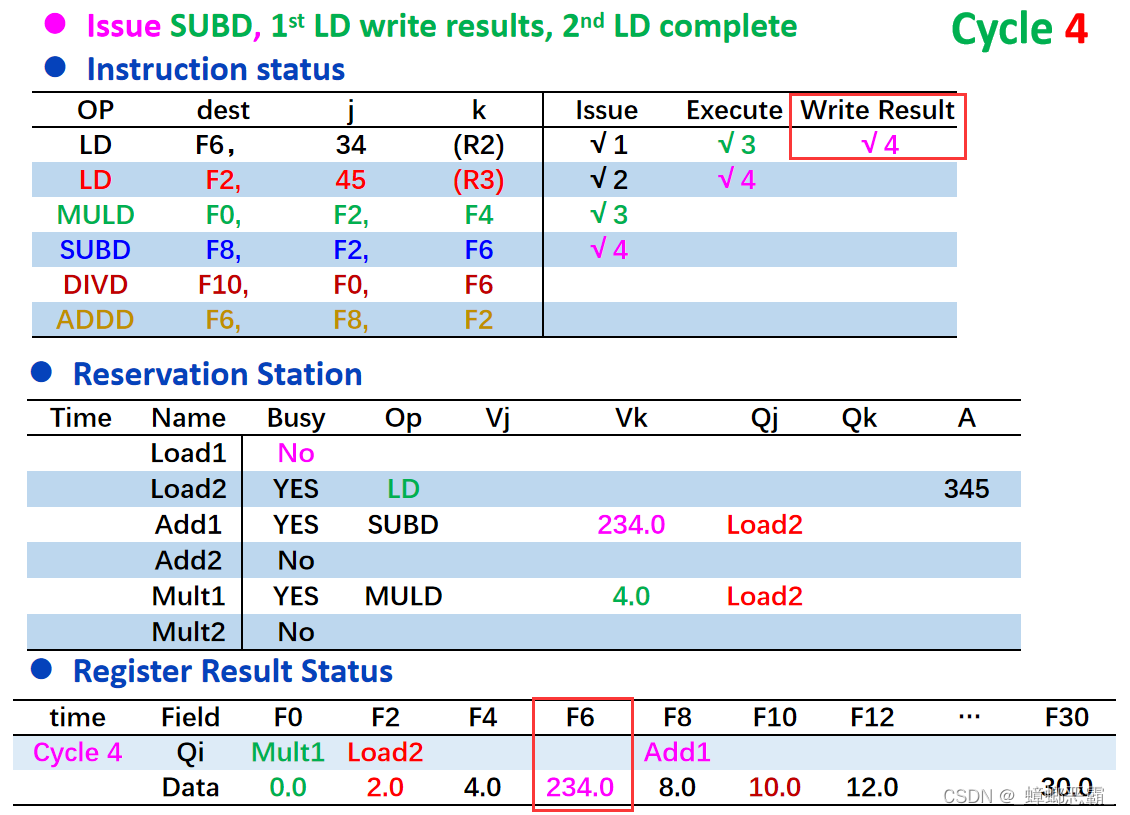
-
本例,上面的保留站的Add2中的F2-Vk是直接取M2呢,还是等Load2写回呢
-
解决:如果你看到了上面寄存器的图片中,M1单元格的下面还有点“抹色”,这表示F6的状态变成Busy。(详见文章的4-1.寄存器的Busy)
-
-
Load部件:
- 无变化;

- 无变化;
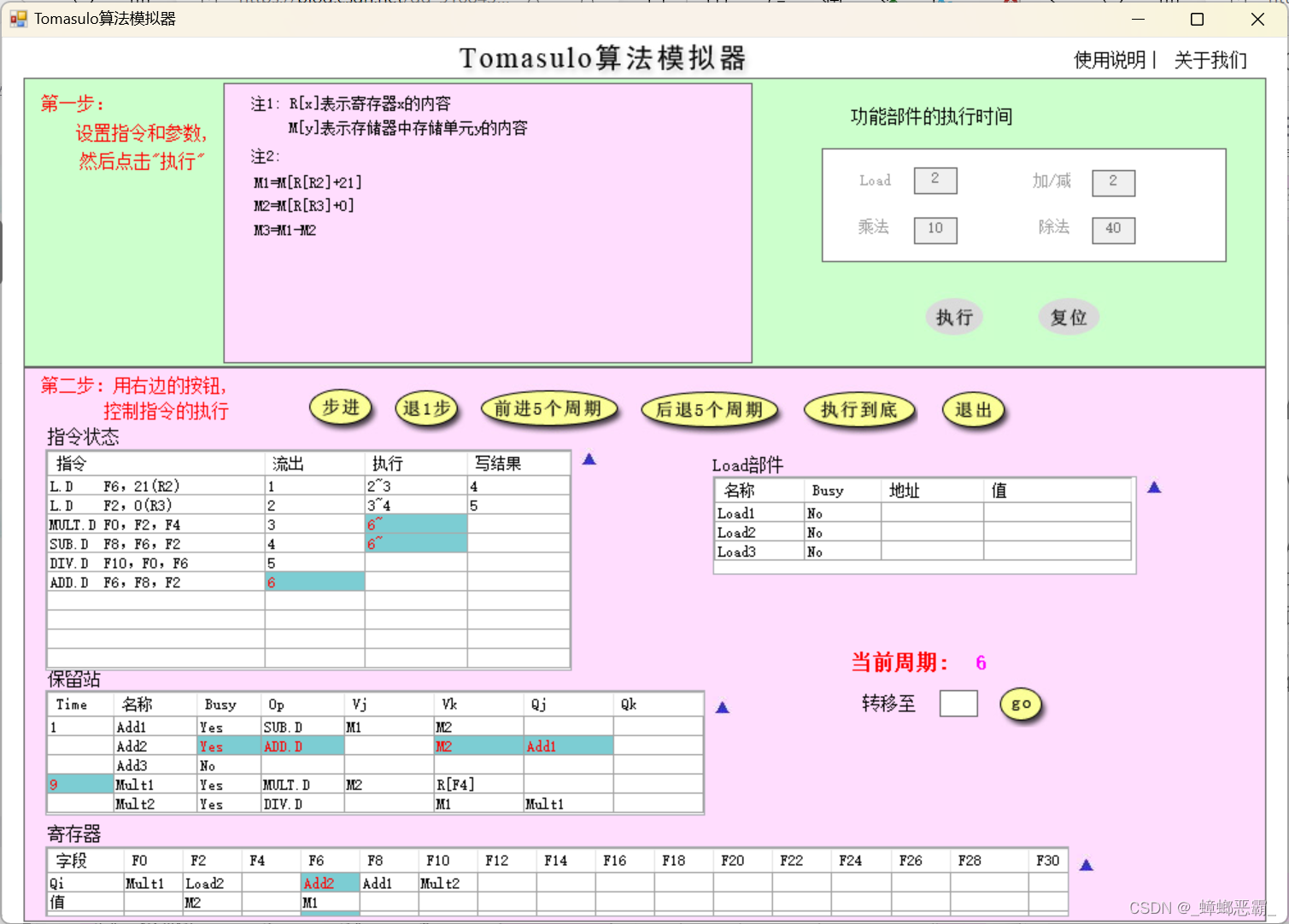
3)为什么MUL.D流出后没有立即执行
简要说明是什么相关导致MUL.D流出后没有立即执行
周期6的图中可以看到:
- MUL.D流出是在周期3,而执行是在周期6;
- 原因是:MUL.D F0, F2, F4与指令2-L.D F2 0(R3)关于F2的写后读RAW
- 动态调度:按指令的操作数的可用性进行调度;
- 调度队列: 当指令需要等待操作数时,会被放置在调度队列中,直到所有操作数都可用。
- 作用:有效地隐藏RAW依赖的延迟,因为指令可以在操作数就绪后立即被调度执行;
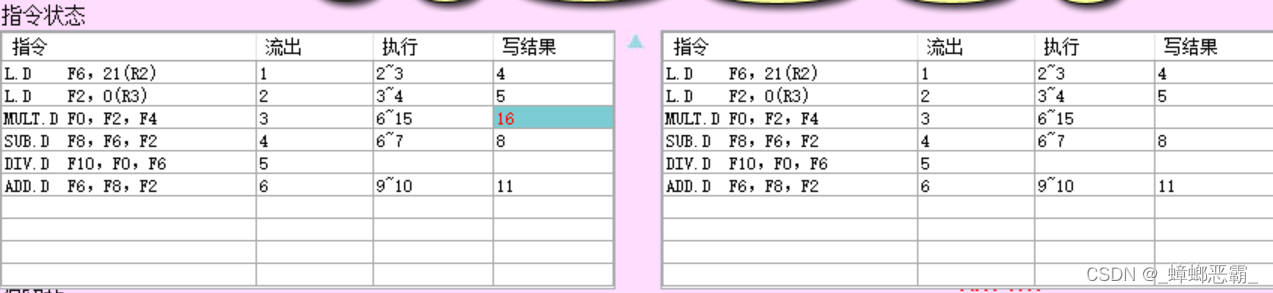
4)15周期和16周期的系统状态
请分别截图(15周期和16周期的系统状态),并分析系统发生了哪些变化
a)15周期
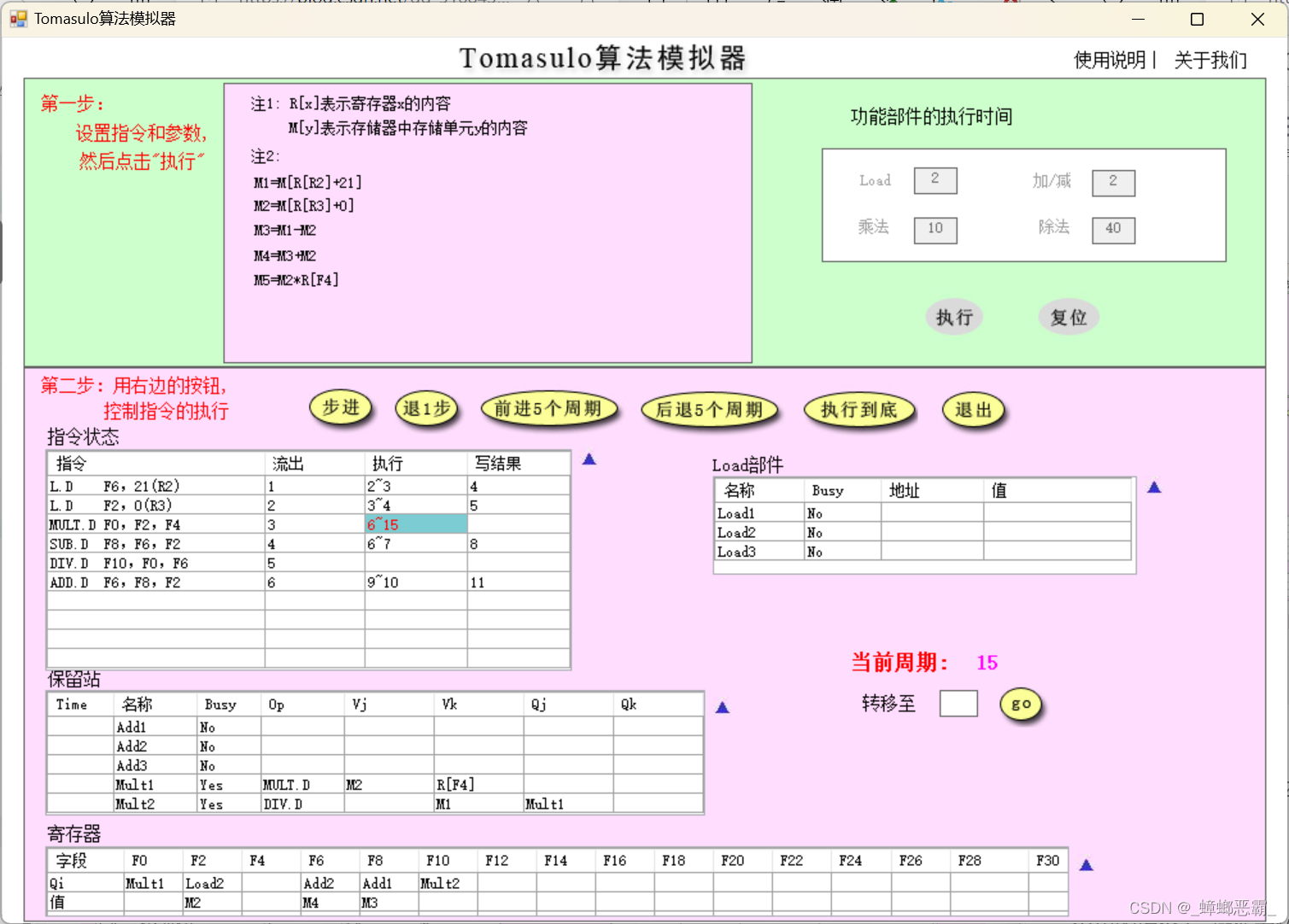
-
指令状态:
- 指令3 MULT.D刚执行完成;
- 指令3 MULT.D刚执行完成;
-
保留站:
-
Time:MUL.D还要执行的时钟周期数变为0
-
寄存器:
- 无操作,F0结果还未写回

- 无操作,F0结果还未写回
-
Load部件:
- 无操作

- 无操作
b)16周期
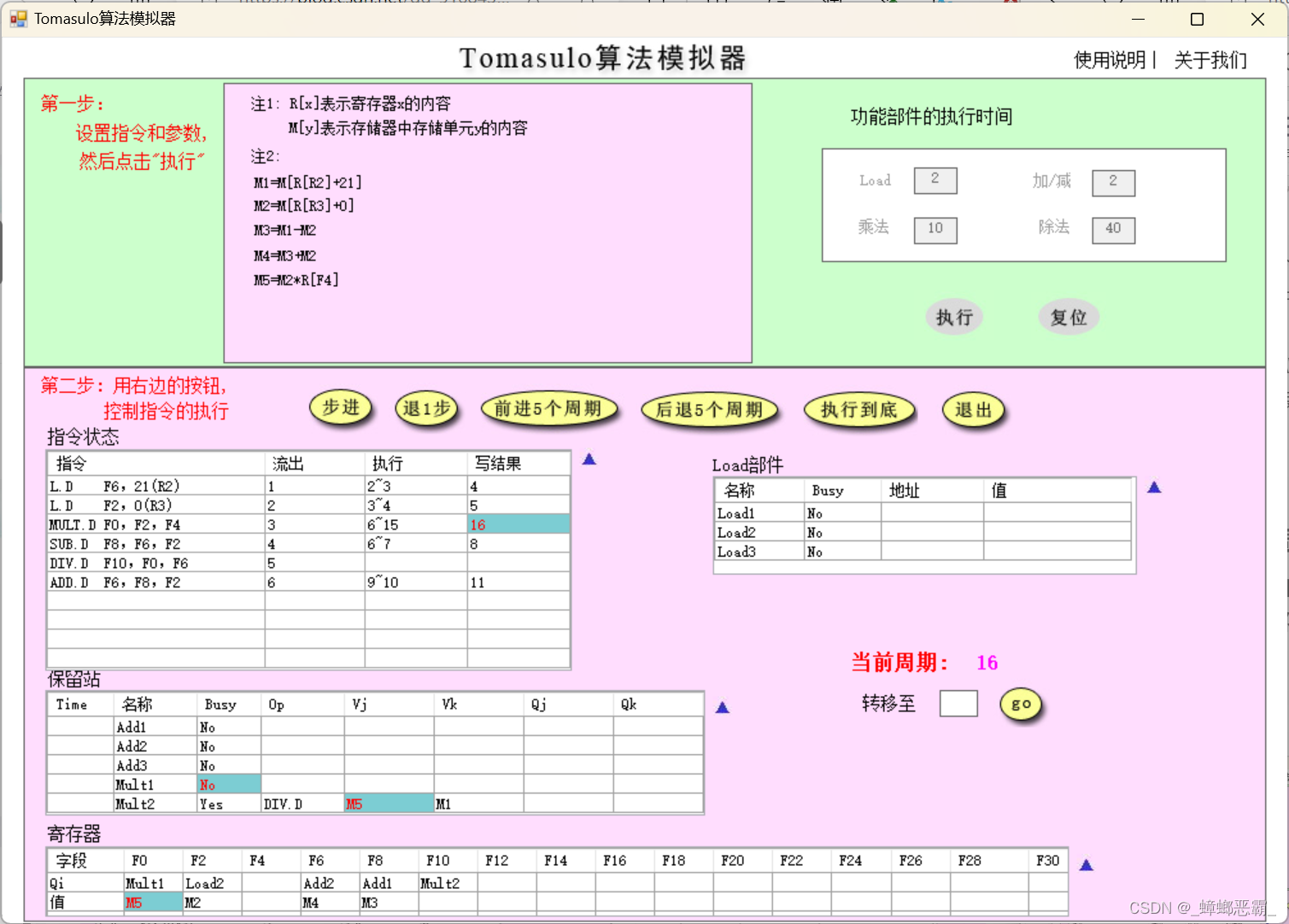
-
指令状态:
- 指令3 MULT.D写回;
- 指令3 MULT.D写回;
-
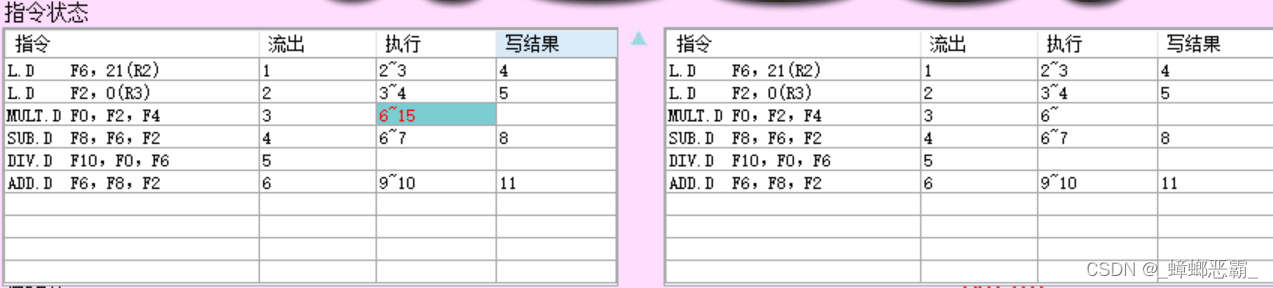
保留站:
- 写回的指令3 MULT.D:保留站MULT1清空释放;
- 指令5 DIV.D-保留站MULT2:CBD将结果广播到指令DIV.D对应的保留站:
- F0-Vj:接收CBD广播的Mult1的写回值M5;
- F6-Vk:寄存器F6是周期5得到的M1
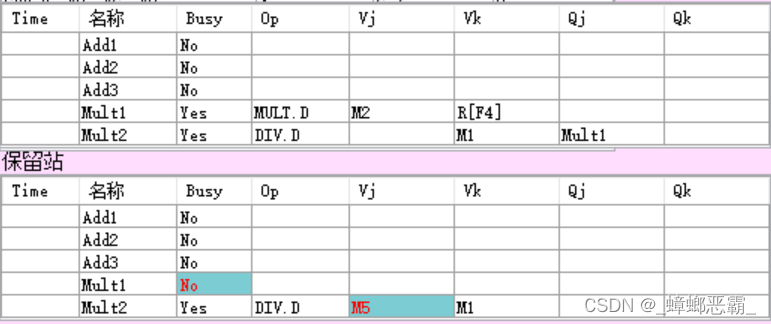
-
寄存器:
- Mult1写入寄存器F0的值为M5;

- Mult1写入寄存器F0的值为M5;
-
Load部件:
- 无操作
5)所有指令刚刚执行完毕的周期
回答所有指令刚刚执行完毕时是第多少周期,同时请截图(最后一条指令写CBD时认为指令流执行结束)
所有指令刚刚执行完毕时是第57周期
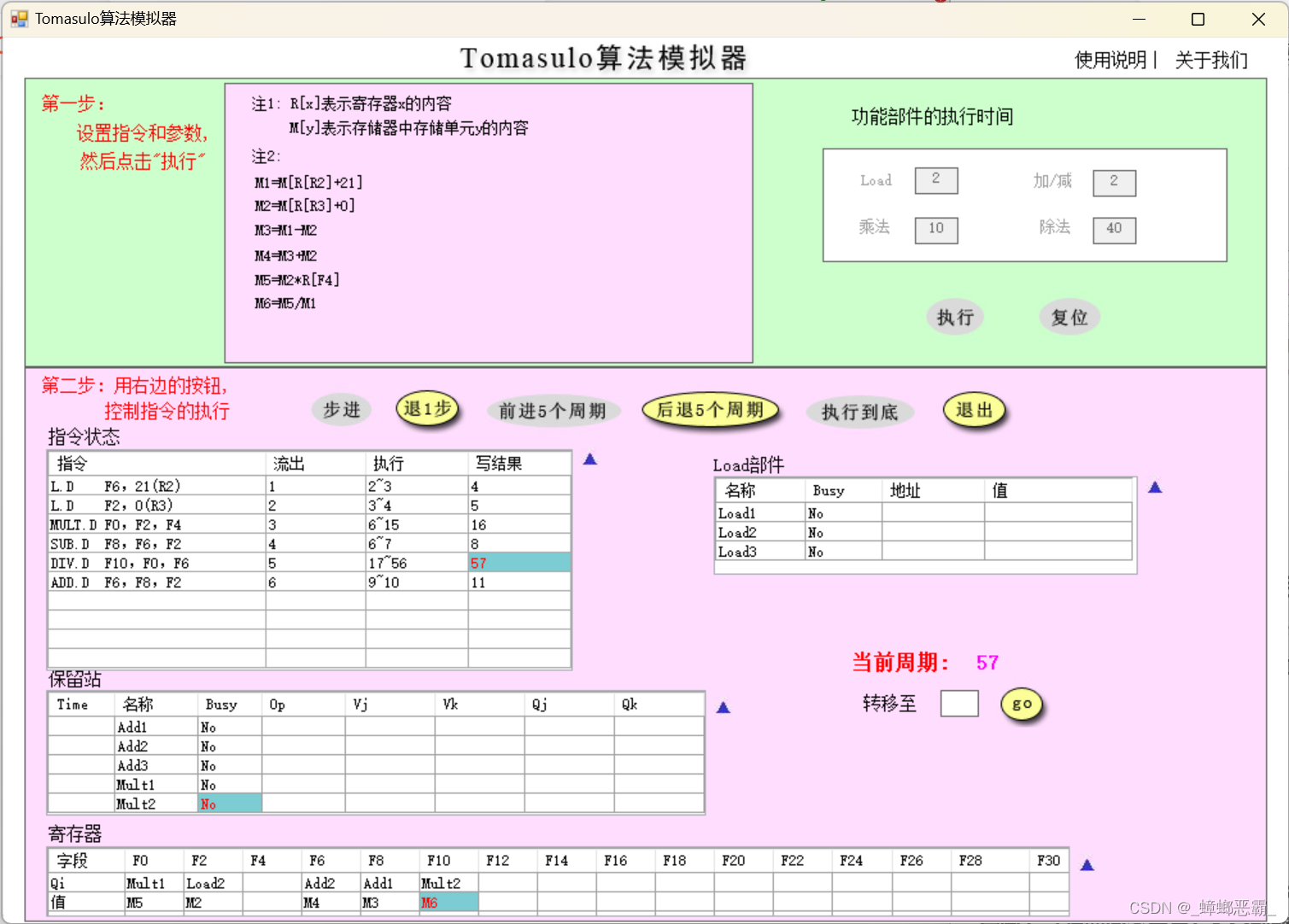
第56周期:DIV.D指令执行完毕;
第57周期:DIV.D指令写结果(最后一条指令写CBD)
2、思考题
1)Tomasulo算法、Score Board算法的异同
Tomasulo算法相比Score Board算法有什么异同?(简要回答两点:1.分别解决了什么相关问题,2.两者分别是分布式还是集中式)
- Tomasulo算法
- WAR相关:在发射时就拷贝数据,贯彻数据流思想——“寄存器名字不重要,寄存器里的数据才重要”;
- WAW相关:只保存最新的写入值,既保证了正确的结果,又减少了不必要的写回操作;
- RAW相关:(与Score Board算法的同)用CDB总线实现了逻辑上的正确,都解决了写后读冒险;
- 结构相关:引入保留站,每条通路可以缓冲多条指令,平缓了指令发射的速度;
- 分布式 :指令状态、相关控制和操作数缓存分布在各个部件中(保留站);
- Score Board算法
- WAR相关:过度纠结寄存器名字,指令在执行之前一直检测的是寄存器堆,一旦数据准备好,就会从寄存器堆中取数;使得后序指令即使计算完结果也可能不能立刻写回寄存器堆;【tag广播】
- WAW相关:过度纠结寄存器名字,会把所有指令的结果都写进寄存器堆,会因为写后写冒险阻塞指令发射;【停滞写回机制】
- RAW相关:执行前需要所有操作数都准备好,解决了写后读冒险;【停滞发射】
- 结构相关:每条通路只能存一条指令,导致经常有指令因为结构冒险而不能发射;
- 集中式:指令状态和相关控制都在记分牌处理;
2)Tomasulo算法如何解决结构冒险、RAW、WAR和WAW相关的数据冒险?
a)结构冒险
- 功能部件都完全流水化,有序访问存储器;
- 引入保留站,每条通路可以缓冲多条指令,平缓了指令发射的速度;
- 有结构冲突不发射;
b)RAW
- 原理:通过监测Common Data Bus,跟踪每个源操作数当前是否可用;
- 解释:
- 仅当所有源操作数可用时才允许指令进入执行阶段;
- 否则等待;
- 举例:本实验中的问题2)-b);MUL.D F0, F2, F4与L.D F2, 0 (R3)关于F2即为RAW的数据冒险
L.D F6, 21(R2)
L.D F2, 0 (R3)
MUL.D F0, F2, F4
SUB.D F8, F6, F2
DIV.D F10,F0, F6
ADD.D F6, F8, F2
c)WAR
- 原理:使用硬件寄存器重命名技术;
- 解释:对于同一寄存器的两条指令,前者读该寄存器,后者写该寄存器;
- 前者指令:发射时就拷贝数据,贯彻数据流思想——“寄存器名字不重要,寄存器里的数据才重要”。
- Busy为yes:标记上对应的指令的保留站编号,
- 否则:直接从寄存器取; - 后者指令:写操作的目的寄存器和前者读的已经不同名
- 前者指令:发射时就拷贝数据,贯彻数据流思想——“寄存器名字不重要,寄存器里的数据才重要”。
- 举例:(直接从寄存器取)本实验中SUB.D F8, F6, F2与ADD.D F6, F8, F2关于F6即为WAR的数据冒险
L.D F6, 21(R2)
L.D F2, 0 (R3)
MUL.D F0, F2, F4
SUB.D F8, F6, F2
DIV.D F10,F0, F6
ADD.D F6, F8, F2
-
前者SUB.D F8, F6, F2的F6:直接从寄存器取
- 后者ADD.D F6, F8, F2的F6
- 写操作的目的寄存器重命名,跟前者的F6不同
- 写操作的目的寄存器重命名,跟前者的F6不同
- 后者ADD.D F6, F8, F2的F6
-
韩金轮的例子:这里我们关注寄存器F12,及除法指令,后两条加法指令:
-
指令:
- 错误的情况:因为乱序执行下,指令8的ADD更快,指令5的DIV更慢;所以 指令8的ADD的F12先写回,而指令7的ADD错误地接收了指令8写回的F12;
- 正确的情况:即使乱序执行下, 指令8的ADD的F12先写回,但指令7的ADD应等待指令5的DIV写回的F12;
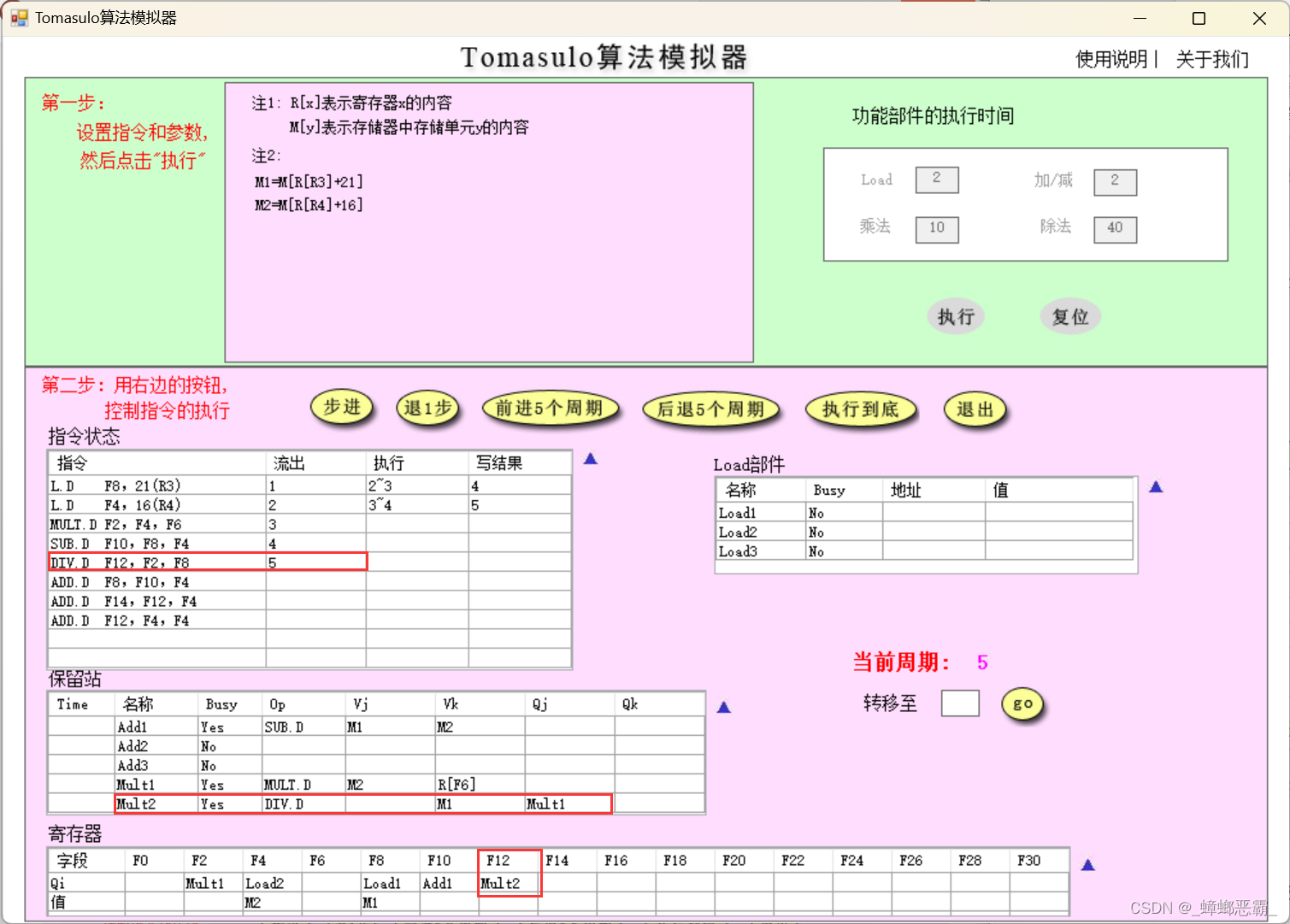
-
周期5的时候的寄存器F12-Mult2:(指令DIV.D F12,F2,F8流出,F12的保留站设为Mult2)
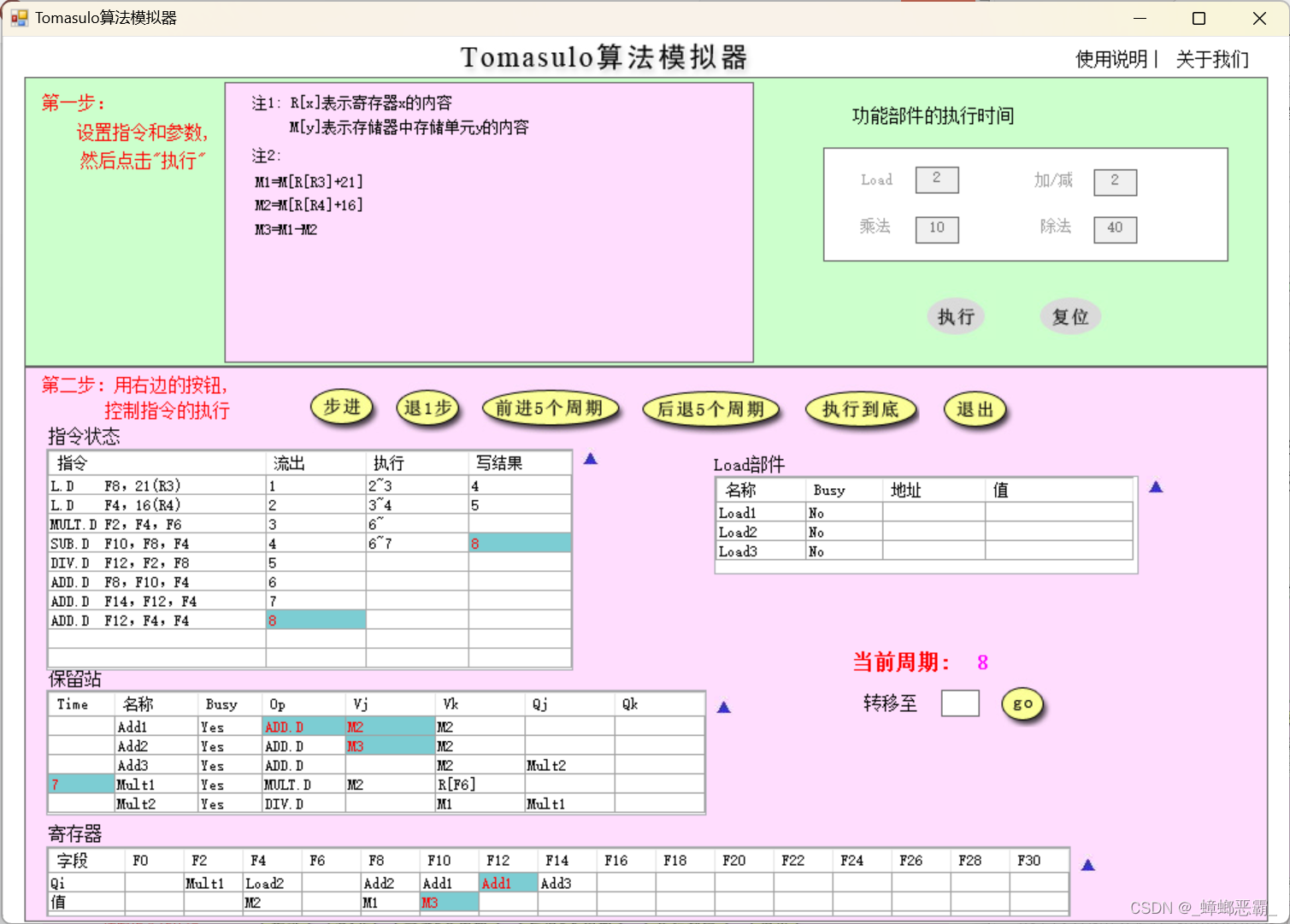
-
周期8的时候的寄存器F12-Add1:(指令8 ADD.D F12,F4,F4流出,F12的保留站设为Add1)
-
周期11的时候的寄存器F12-M5:(指令8 ADD.D F12,F4,F4写回,F12的值为M5,状态为非Busy)
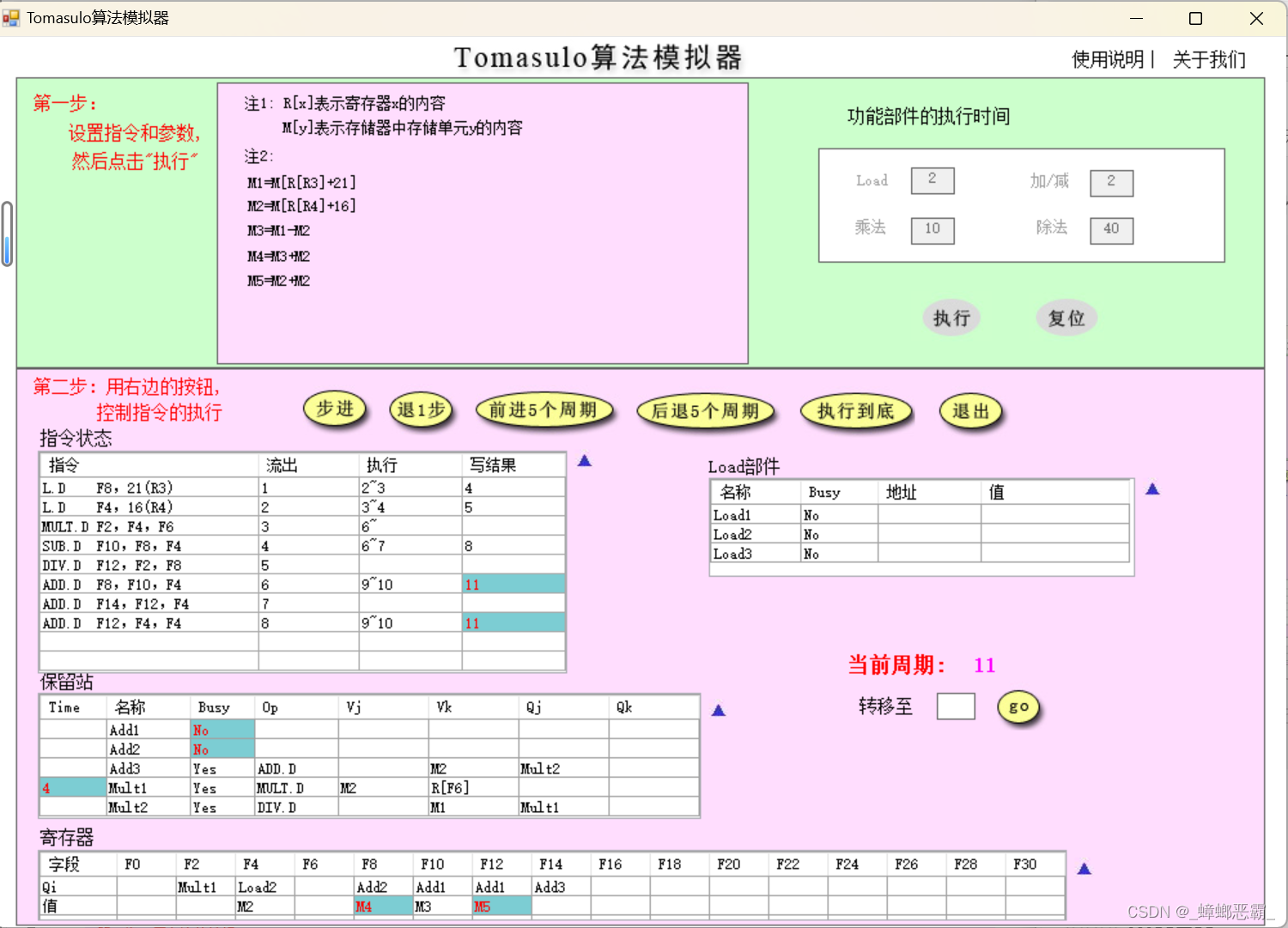
-
这里的正确处理正体现了Tomasulo算法解决WAR相关的数据冒险:指令7 ADD.D F14,F12,F4(保留站Add3)的F12-Vj没有错误地取 指令8写回到寄存器的F12-M5,而是正确地等待指令5 DIV.D F12,F2,F8的F12,保留站中的Qj-Mult2,直到周期57:
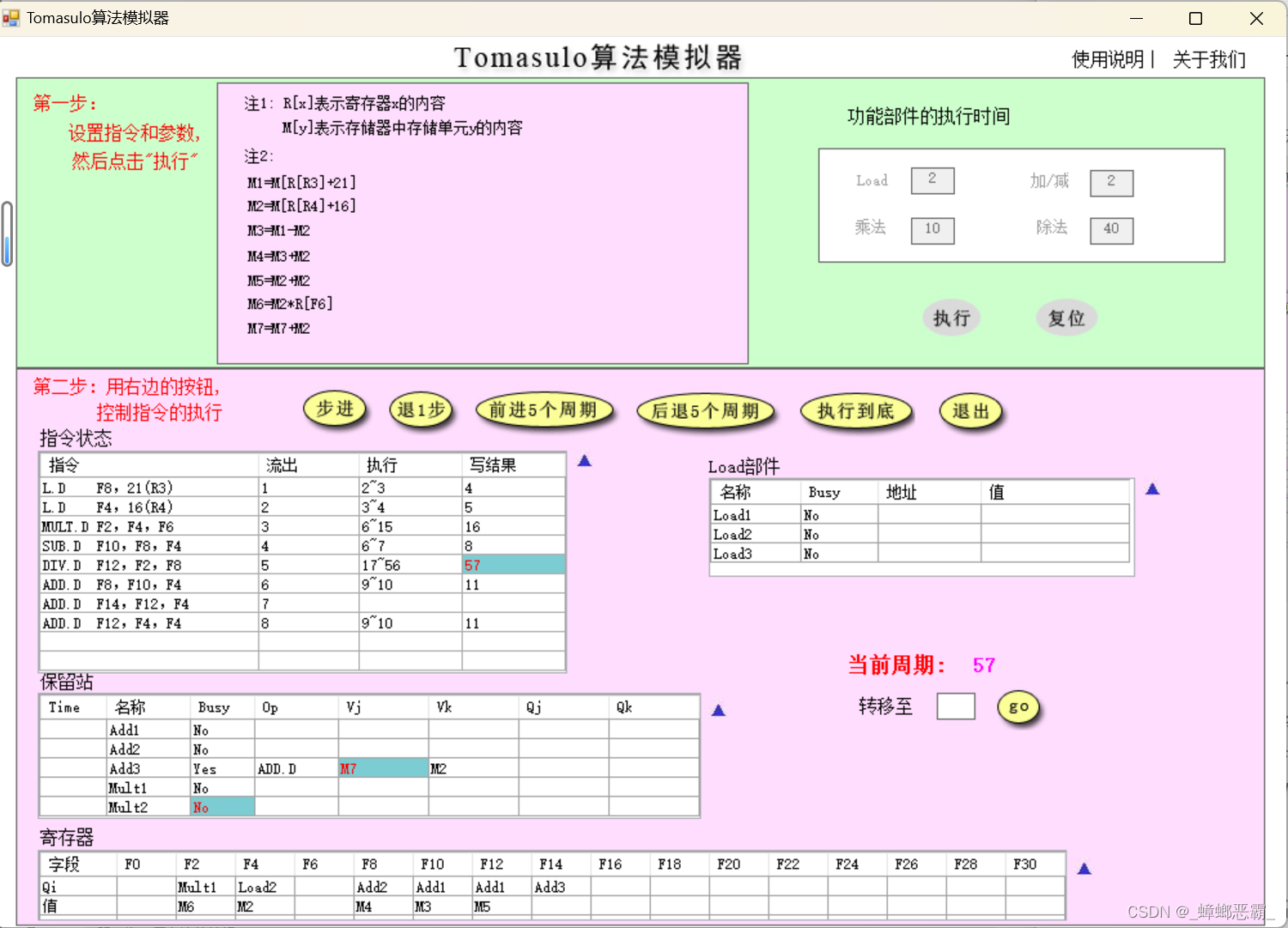
-
-
这里的寄存器F12最终是先写回的指令8 ADD.D F12,F14,F4的M5,而非后写回的指令5 DIV.D F12,F2,F8的M7(M7没有覆盖掉M5),也体现了WAW的处理;
d)WAW
- 原理:使用硬件寄存器重命名技术;
- 解释:只保存最新的写入值,既保证了正确的结果,又减少了不必要的写回操作
- 对于同一寄存器写的两个指令:后者对RS中该寄存器的保留站的写入会覆盖前者;
- 故该寄存器只会响应后者完成时的广播CDB信号,使得最终寄存器的值是后者的写回值;
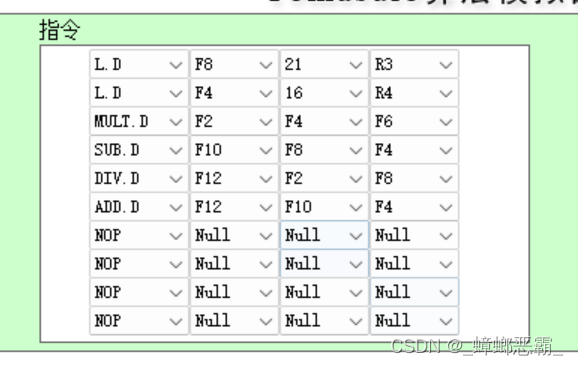
- 举例:韩金轮的例子:这里我们关注寄存器F12,及最后的除法指令,加法指令:
-
指令:
- 错误的情况:因为乱序执行下,指令6的ADD更快,指令5的DIV更慢;所以 指令6的ADD的F12先写回,而指令5的DIV后写回的F12;最终F12中是指令5的DIV后写回的F12;
- 正确的情况:即使乱序执行下,指令6的ADD的F12先写回,而指令5的DIV后写回的F12;最终F12中也应当是指令6的ADD写回的F12;
-
周期5的时候的寄存器F12-Mult2:(指令5 DIV.D F12,F2,F8流出,F12的保留站设为Mult2)
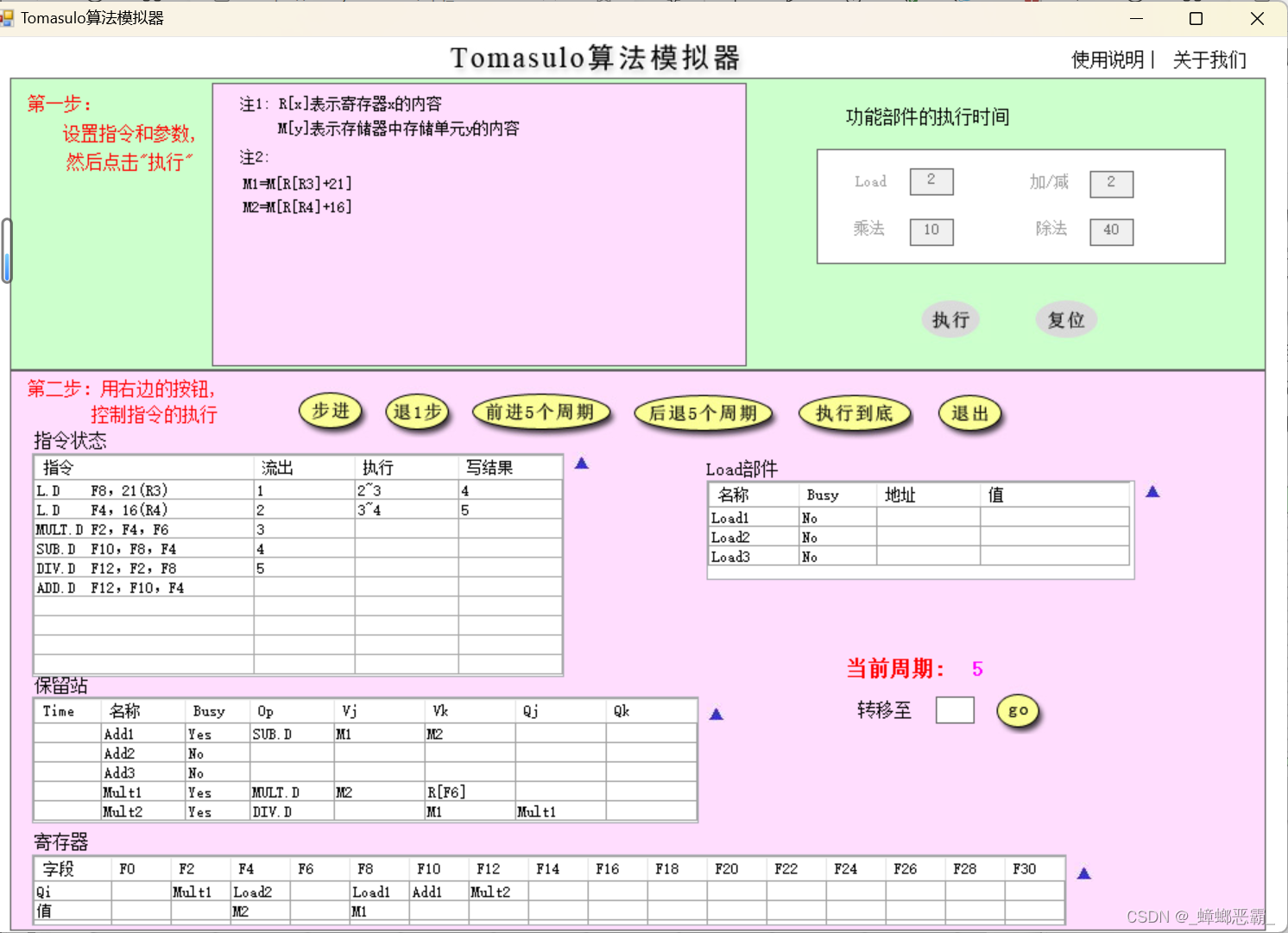
-
周期6的时候的寄存器F12-Add2:(指令6 ADD.D F12,F10,F4流出,F12的保留站设为Add2)
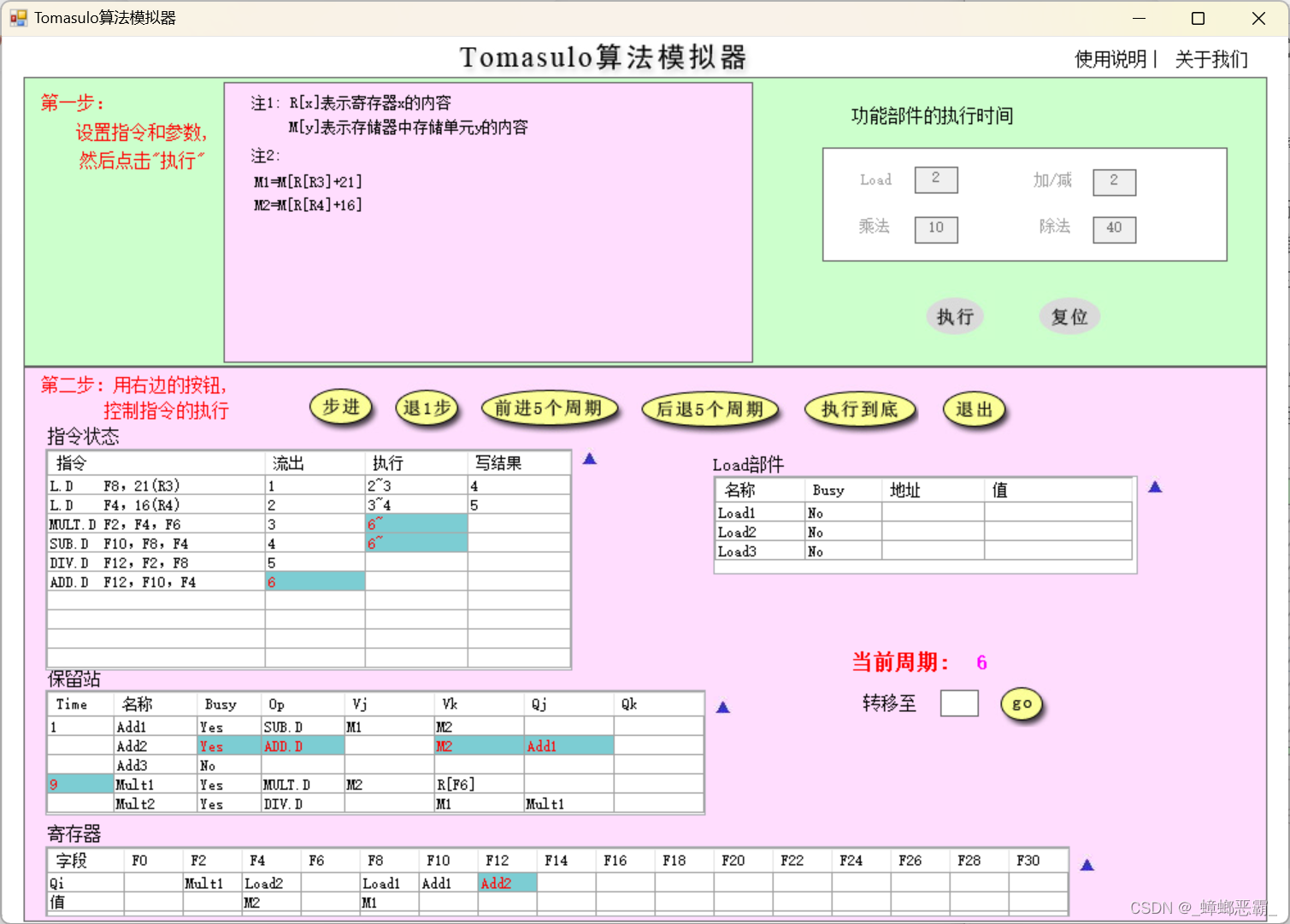
-
周期12的时候的寄存器F12-M4:(指令6 ADD.D F12,F10,F4写回,F12的值设为M4)
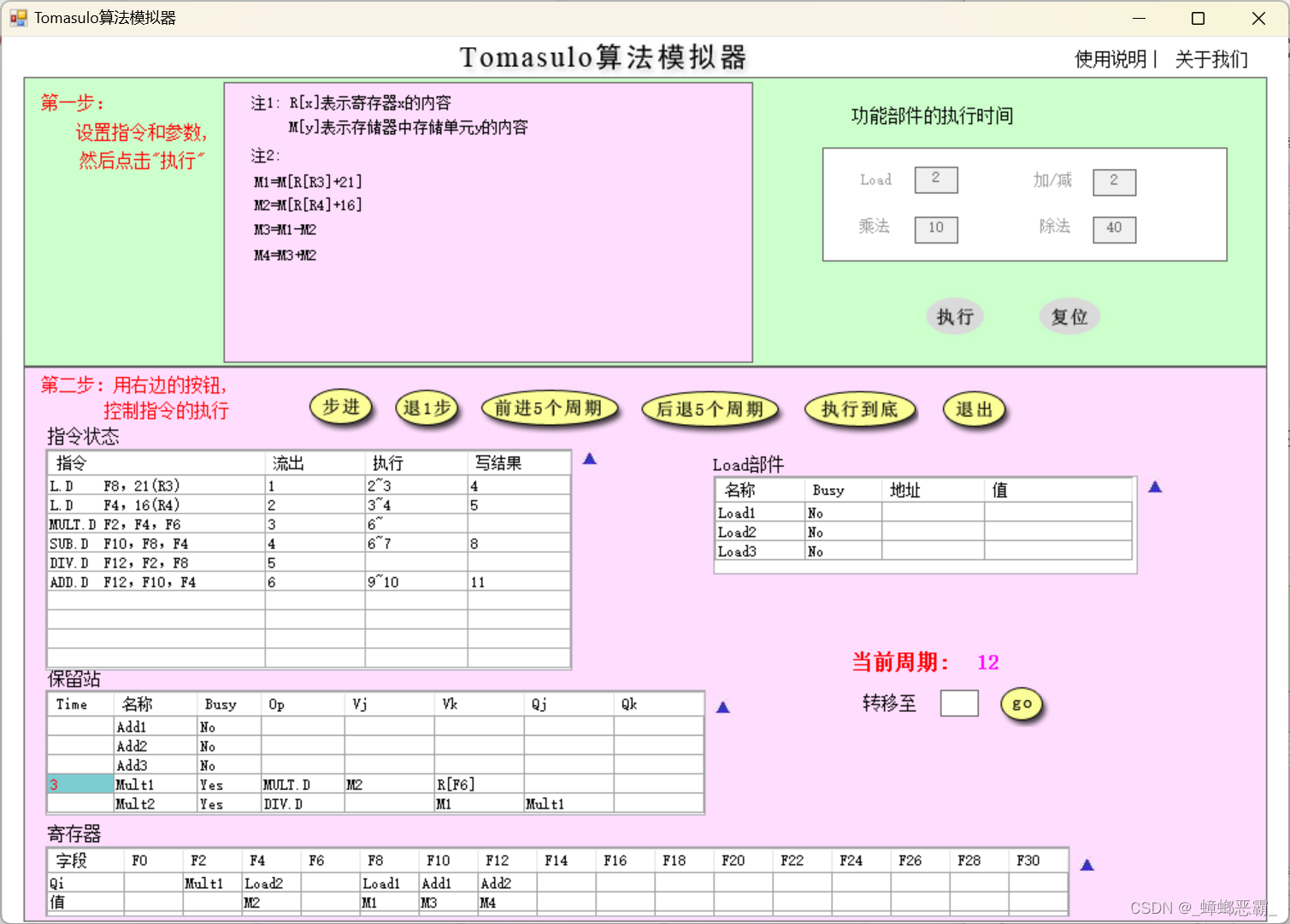
-
周期57的时候的寄存器F12-M4:(指令5 DIV.D F12,F2,F8写回,但F12的值仍为M4)
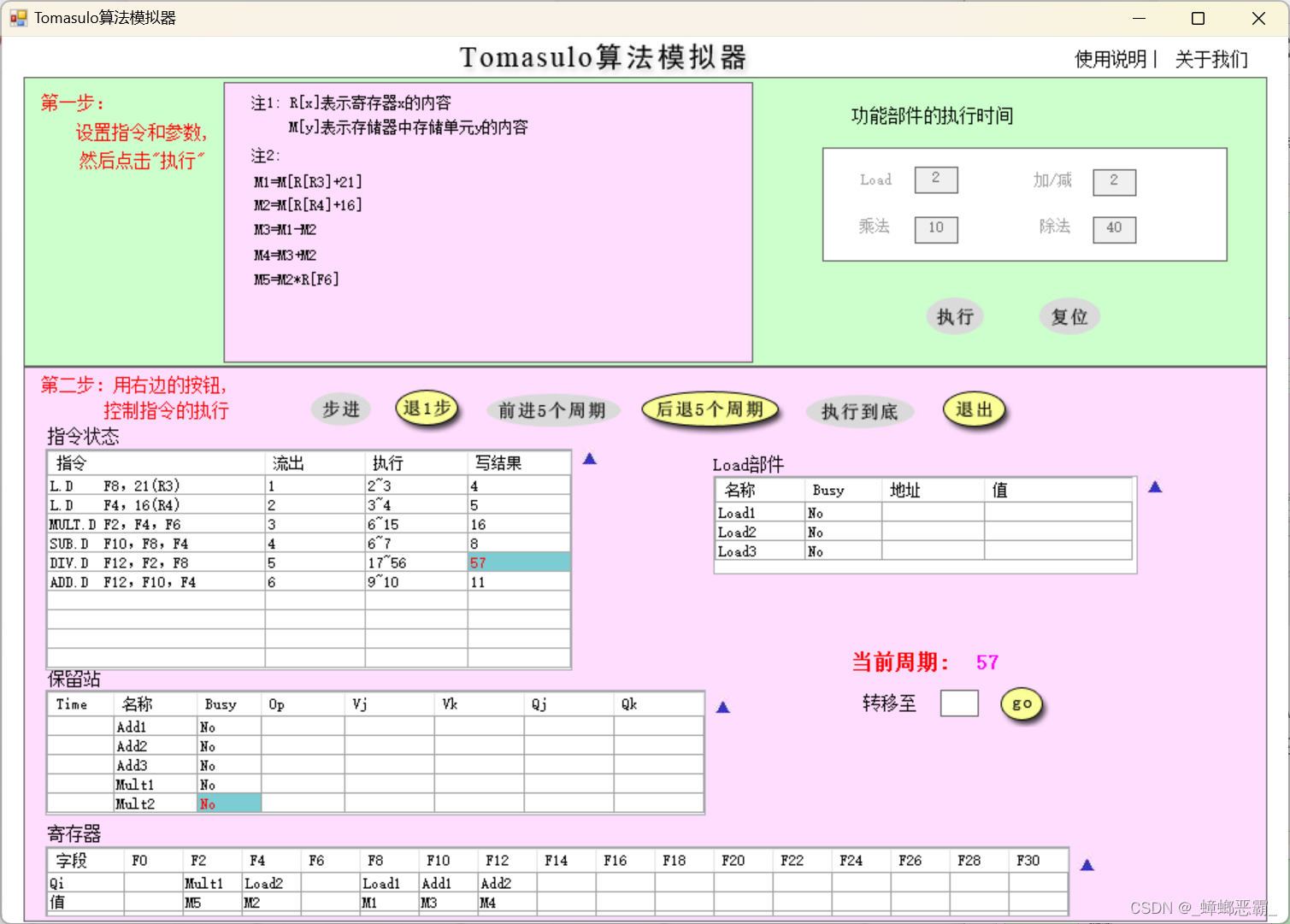
-
四、一些注意
1.寄存器的Busy
- 问题的发现:
- 在问题2)-b)-寄存器部分引入了;
- 寄存器的Busy
- 寄存器的表格不止三行:
- 下面分别是周期4、5、6的寄存器图



- 上面的单元格只能拉到这个程度,写出来是这样的:(周期4、5、6的寄存器)
| 字段 | F0 | F2 | F4 | F6 | F8 | F10 |
|---|---|---|---|---|---|---|
| Qi | Mult1 | Load2 | Load1 | Add1 | ||
| 值 | M1 | |||||
| Busy | yes | yes | yes |
| 字段 | F0 | F2 | F4 | F6 | F8 | F10 |
|---|---|---|---|---|---|---|
| Qi | Mult1 | Load2 | Load1 | Add1 | Mult2 | |
| 值 | M2 | M1 | ||||
| Busy | yes | yes | yes |
| 字段 | F0 | F2 | F4 | F6 | F8 | F10 |
|---|---|---|---|---|---|---|
| Qi | Mult1 | Load2 | Add2 | Add1 | Mult2 | |
| 值 | M2 | M1 | ||||
| Busy | yes | yes | yes | yes |
- 当Busy是yes的时候,指令会等待相应寄存器的保留站Qi;
- 否则,指令直接取相应寄存器的值;
2.F6不是R6
一开以为F6和R6是同一个寄存器,所以有如下的疑问(还以为模拟器有问题)。问了老师,说F6和R6不是同一个寄存器,就能解释的通了:
下面的图中标出的FP Registers是寄存器Ri;而结果寄存器Fi在该图中未标出:
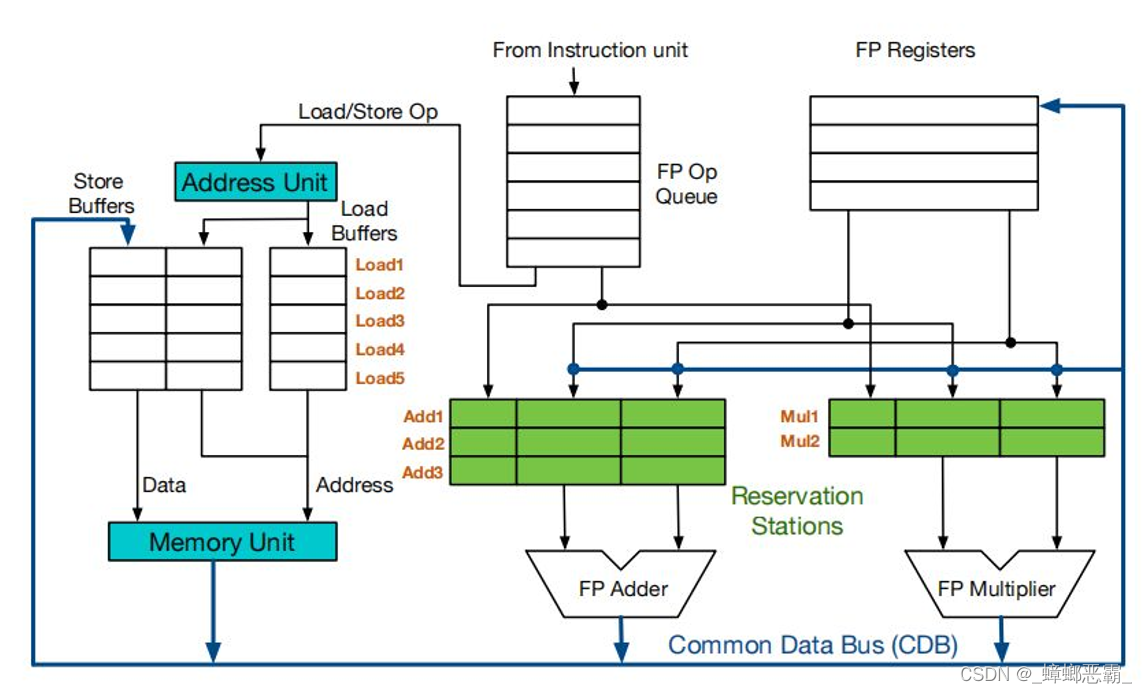
不妨带着“F6和R6是同一个寄存器”的想法去看下面的问题,可能对RAW相关有更深的理解:
- PPT中的Tomasulo算法是把Load部件也看做保留站的,故而也有相应的Vj/Vk,Qj/Qk:
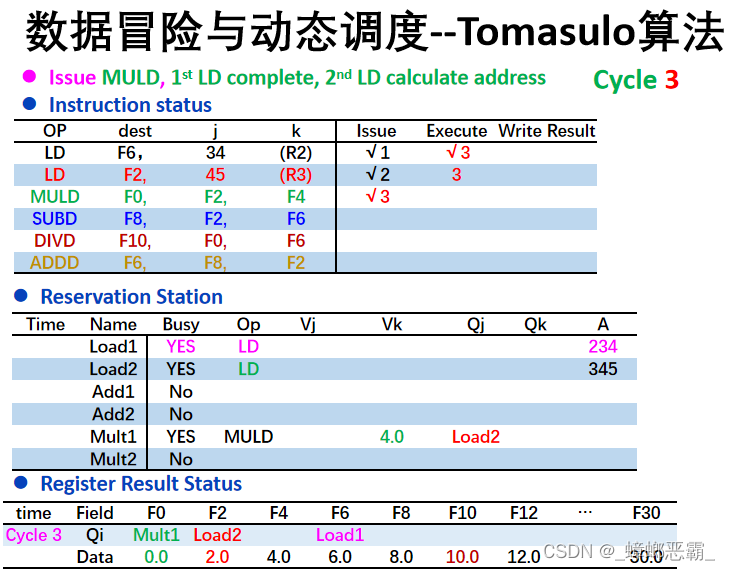
-而《Tomasulo算法模拟器使用方法》中的介绍,好像也是把Load看成保留站的:

-
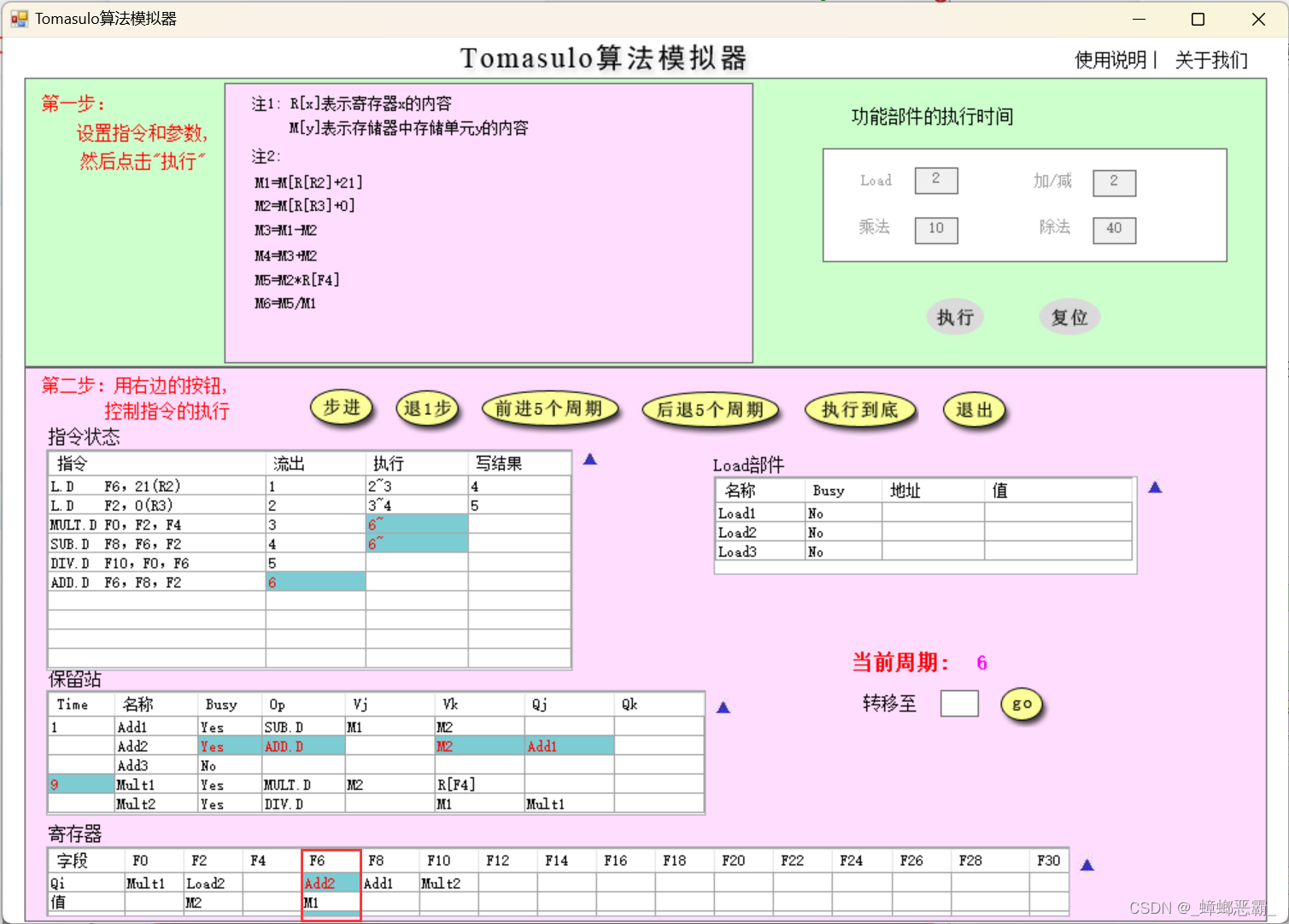
然而问题是:当修改指令如下时
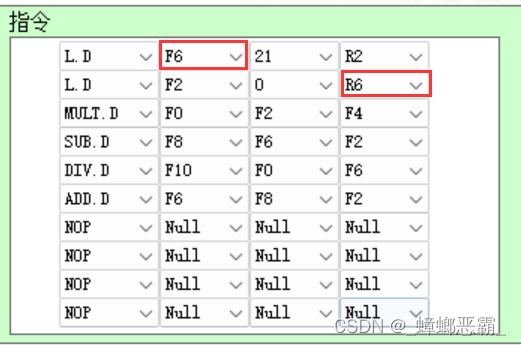
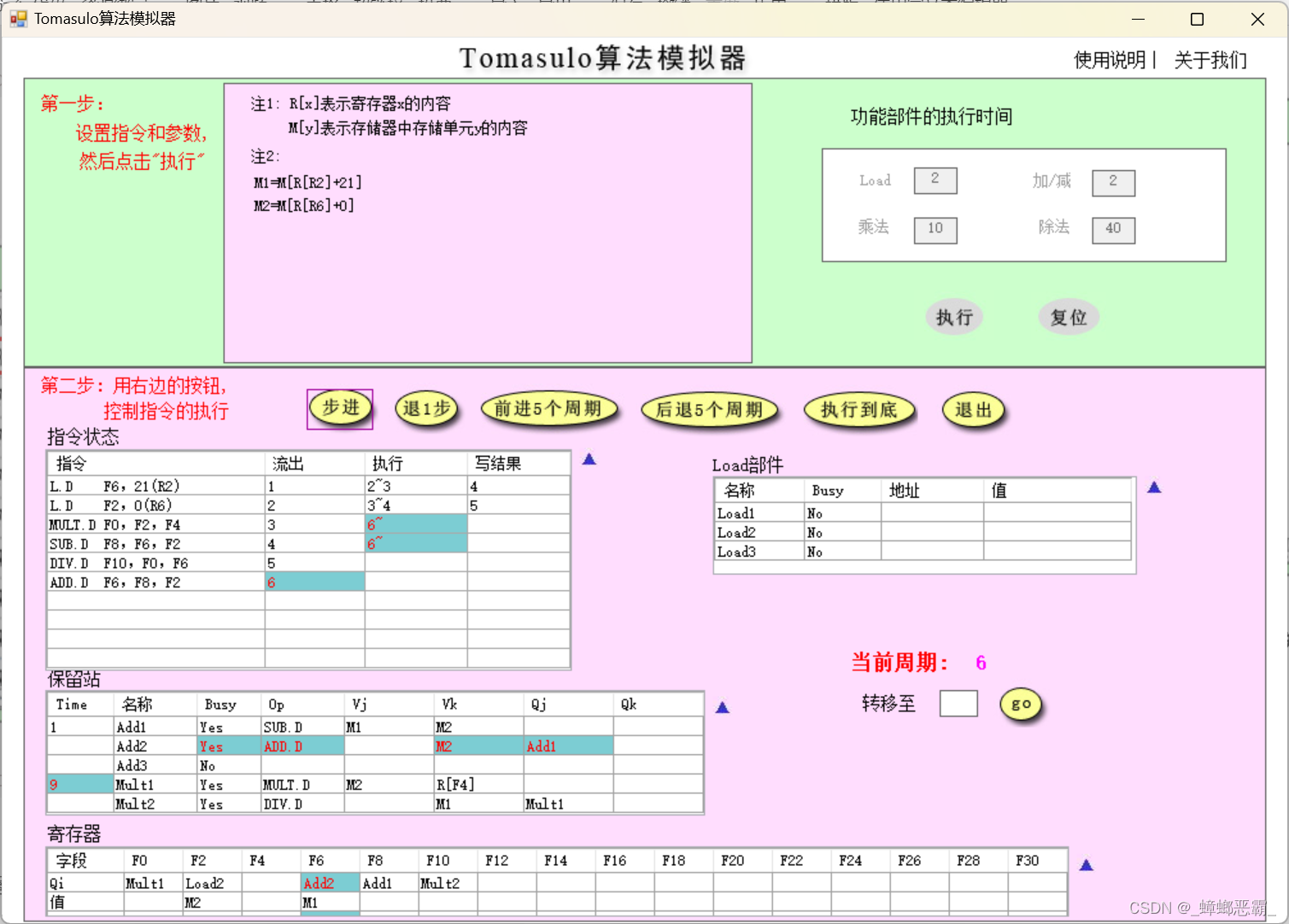
- 正确的情况:应当会有两条Load指令关于寄存器R6的RAW相关,按理说第二条Load指令会等待第一条Load指令的写回,到周期5才开始执行:
- 但实际第二条Load指令在周期3就开始执行:















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









