






目录
入门知识
xpath是在XML文档中搜索内容的一门语言(html是xml的一个子集)
通过节点之间的关系查找数据
节点

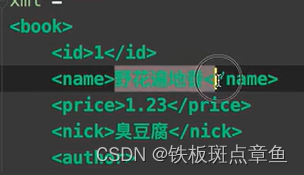
book id 等都是节点 book是id name父节点 name是 book字节 id book 等是兄弟节点
xpath解析
安装库
from lxml import etree加载xml
tree=etree.XML(xml内容)etree.HTML etree.parse(文件)
xpath查找节点
res=tree.xpath("/book/name")找book下name节点
text()返回节点文本
res=tree.xpath("/book/name/text()")#拿文本多个标签(节点相同) res是所有文本
隔行拿(递归)//

想一次拿到周...... 和下面的热热热
res=tree.xpath("/book/author//nick/text()")递归拿author 目录下所有 的nick(子 孙 )
*通配符任意的目录
只拿热1和热2
res=tree.xpath("/book/author/*/nick/text()")*是任意的
根据索引 相同标签取第几个
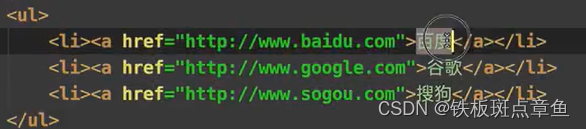
res=tree.xpath("/html/body/ul/li[1]/text()")xpath索引从1开始
根据属性和属性值找[@属性=’属性值‘]
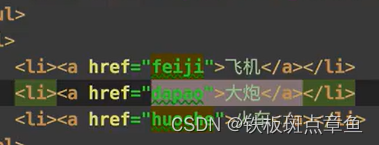
tree.xpath('/ol/li/a[@href='dapao']/text())一行多个标签 前面的标签在前写 也可以只写第一个标签然后text
./相对查找(路径)
如上假设 aa是查找的三个li(标签)
.是i的路径
for i in aa: 再次查找必须
aa.xpath('./')查找属性值@属性"
aa.xpath('./a/@href')拿标签a属性的值
多行标签相同 拿多行
确定网页显示 对应源代码位置 检查快捷拿xpath代码
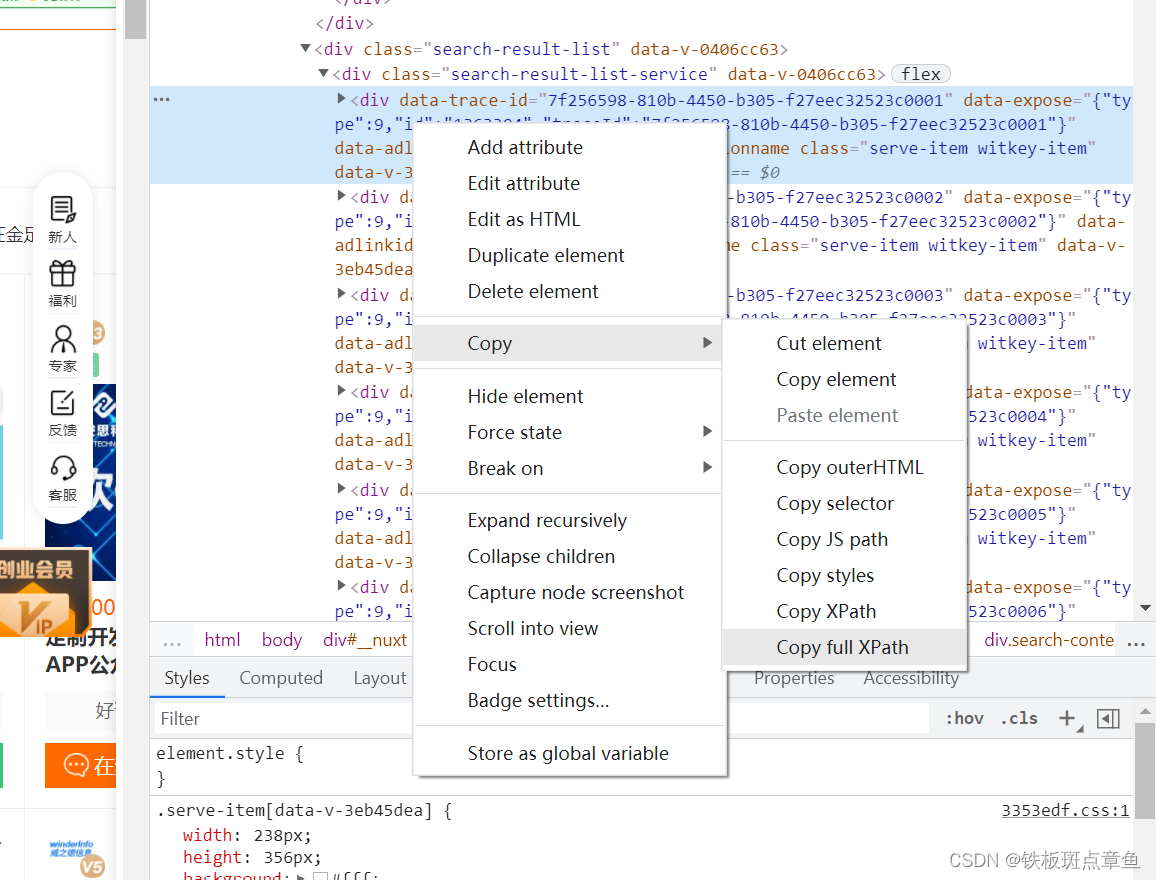
是上面的 没有all
检查 点击左上角箭头 再在页面上试试
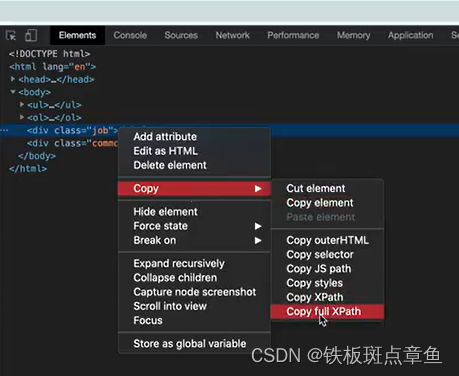
复制

实例:猪八网
区别html
html与xml不能混用 源代码开头会有
思路

只需用上文快捷拿该块的(检查)
找一大块与一小块分界
指上面一大块 下面一小块
再删掉切片
join函数
’sep‘.jion(text)
以sep为分隔符 拼接text中的元素
实操
.xpath()里最好不要有(//*[@id="__layout"]/div/div[3]/div/div[3]/div[4]/div[1]/div[1])
像这样id
步骤
先
鼠标图标定位到这一块
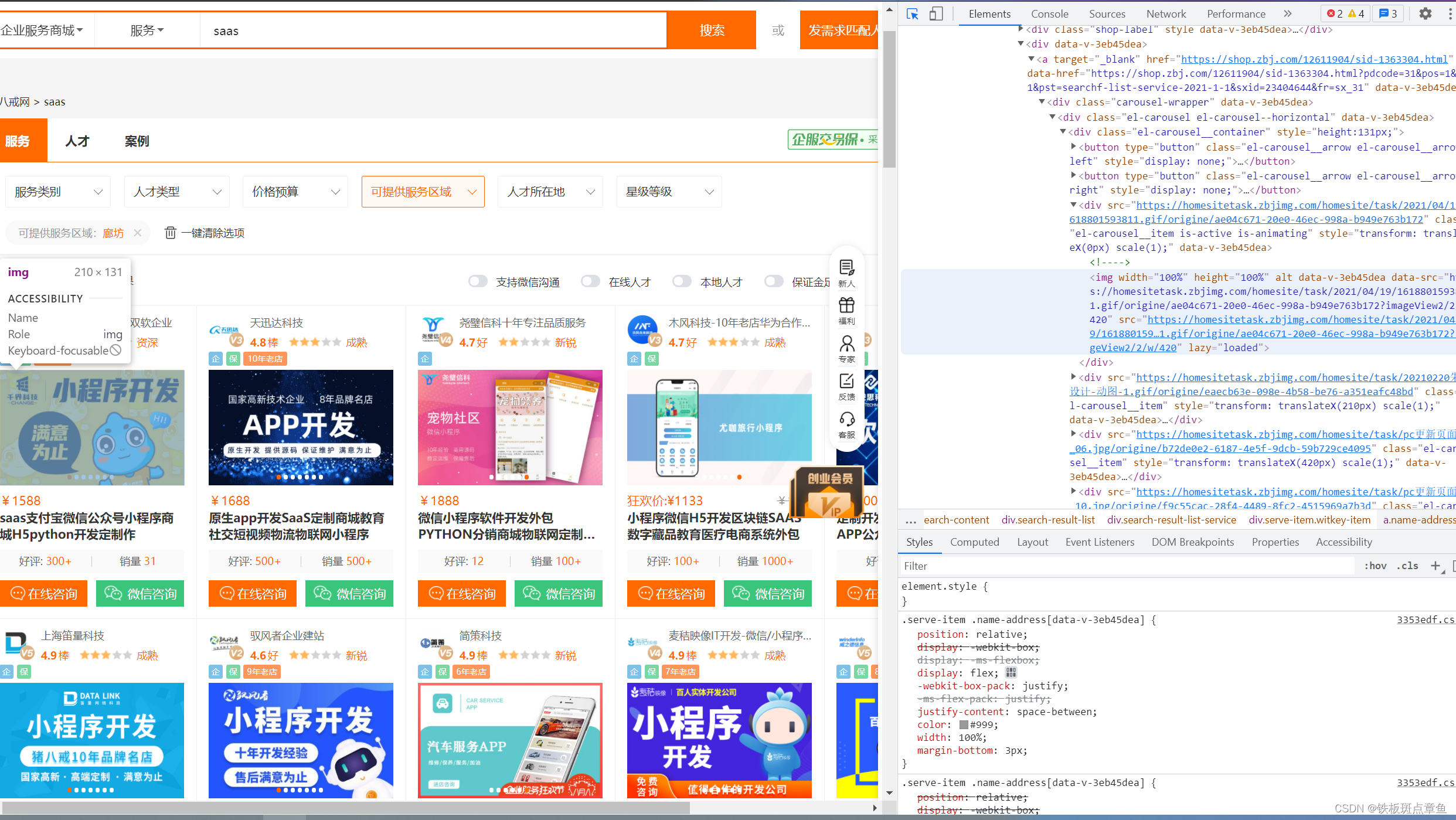
再找到一小块与一大块分界处
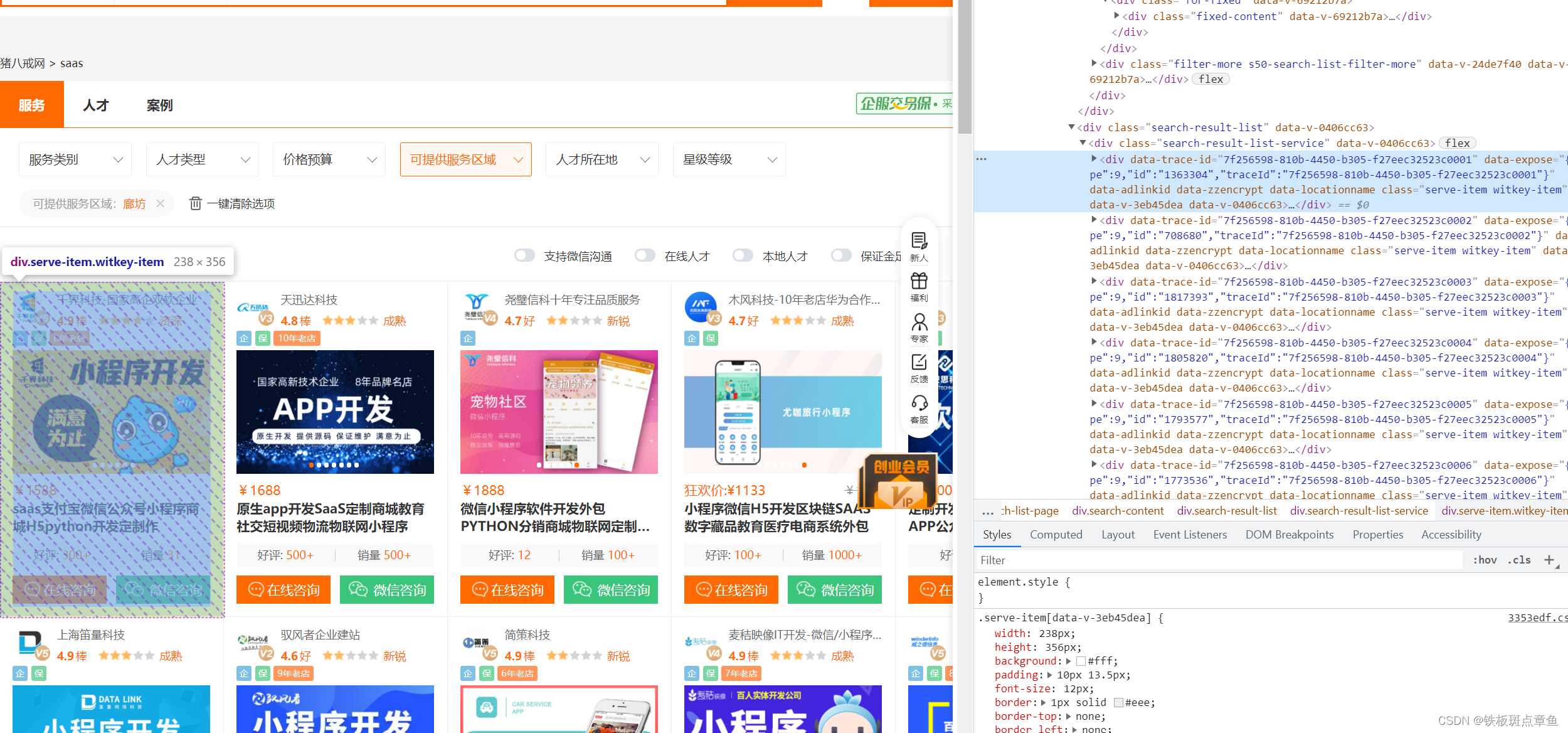
复制这个xpath xpath一下 去掉索引(取每一块)
然后for循环 xpath ./ 展开一个个找(copy all xpath删前面的快速找)(自己输入路径)注意输入路径时的[9]索引 如第几个div
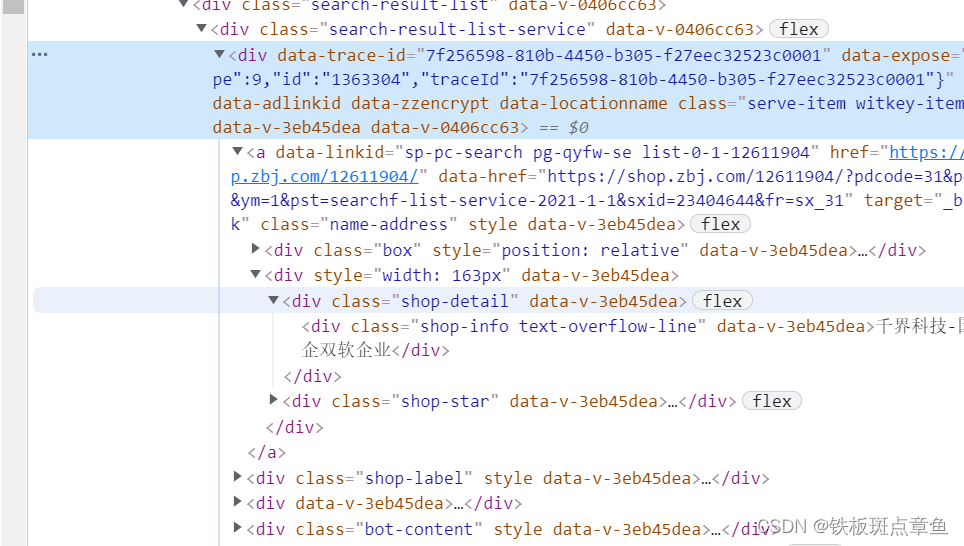
名字出现,分割的解决
我们在网站上搜索的是saas(里)
则输出的标题中无法saas 会用,代替

代码
import requestsfrom lxml import etreeurl='https://langfang.zbj.com/search/service/?kw=saas&r=1'#获取页面reps=requests.get(url)tree=etree.HTML(reps.text)yikuai=tree.xpath('//*[@id="__layout"]/div/div[3]/div/div[3]/div[4]/div[1]/div')#找一块for i in yikuai: titlb=i.xpath('./a/div[2]/div[1]/div/text()')#找的时候可以直接 copy all xpath!!!!! price=i.xpath('./div[3]/div[1]/span/text()')#注意索引!!!!重要 nier=i.xpath('./div[3]/a/text()')














 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









