






目录
在主节点上启动spark集群------------------
单独启动 主节点上单独启动和停止Master-----------------
在从节点上单独启动和停止Worker(Worker指的是slaves配置文件中的主机名)
概念
spark是大规模数据处理的统一分析引擎
特点
高效 速度超Hadoop
使用简单
功能多 通用性
可以运行在多个地方(可以在Hadoop上)
组成模块

搭建
安装包下载
![]()
或者官网 Apache Spark™ - Unified Engine for large-scale data analytics
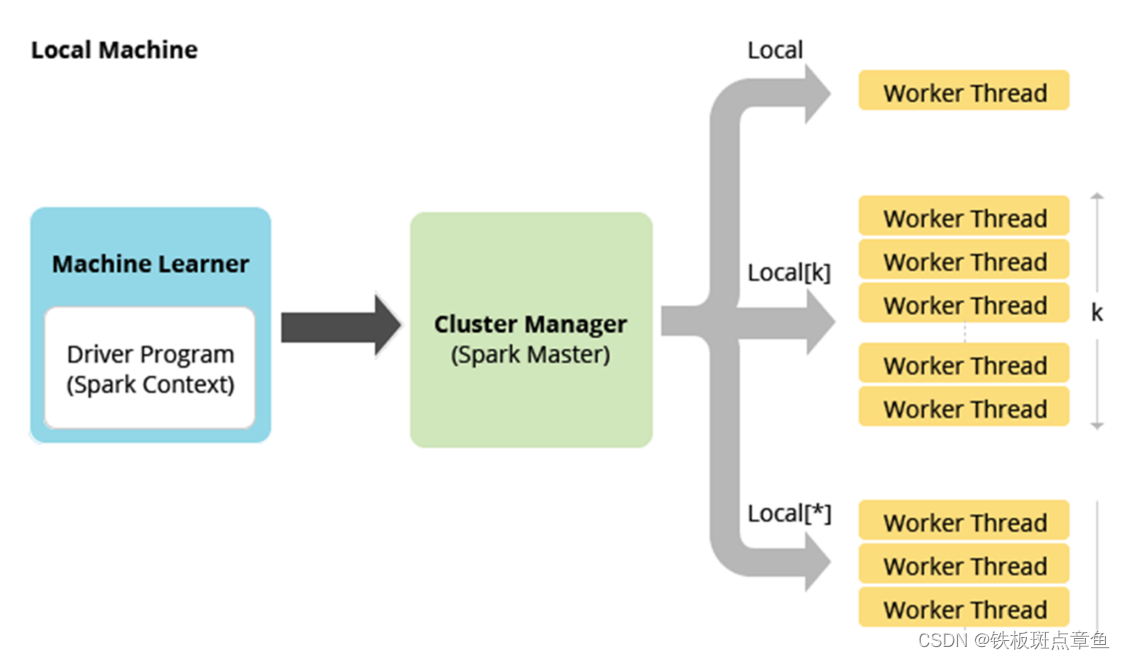
local本地模式(单机版)
准备
1 保证linux里有JDK(Spark源码是Scala编写的,编译成.class文件,运行在JVM之上)
原理
使用本地的多线程 模拟Spark集群中的各个角色
操作
上传安装包
上传到 /export/server目录下
cd /export/server/解压安装包
tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz 修改权限
chown -R root /export/server/spark-3.0.1-bin-hadoop2.7
chgrp -R root /export/server/spark-3.0.1-bin-hadoop2.7
改名(或创建软连接)
ln -s /export/server/spark-3.0.1-bin-hadoop2.7 /export/server/spark测距课程包括境外
测试-运行spark-shell
启动spark交互式窗口
/export/server/spark/bin/spark-shell打开web界面
http://node1:4040
web界面
jobs
使用示例 读取本地文件并计算
vim /root/words.txt
hello me you her
hello me you
hello me
hello执行WordCount
val textFile = sc.textFile("file:///root/words.txt")
val counts = textFile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
counts.collectweb界面jods上刷新 有任务了
详情![]()
关闭
crtl+c
jps(关闭前后 看一遍)
Standalone-独立集群模式
原理
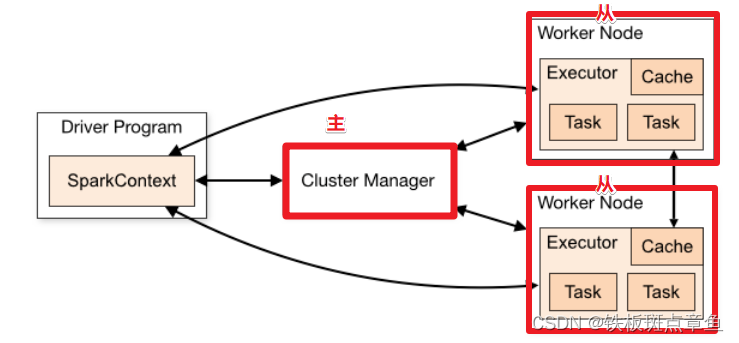
各个节点功能
类似Hadoop YARN 管理集群资源和调度资源
主节点Master
管理整个集群资源,接收提交应用,分配资源给每个应用,运行Task任务
从节点Workers
管理每个机器的资源,分配对应的资源来运行Task
每个从节点分配资源信息给Worker管理,资源信息包含内存Memory和CPU Cores核数
历史服务器(可选)
Spark Application 运行完成以后,保存事件日志数据到HDFS,启动HistoryServer可以查看应用运行相关信息
操作
集群规划
node1:master
ndoe2:worker/slave
node3:worker/slave
修改配置文件 配置worker
cd /export/server/spark/confmv slaves.template slavesvim slaves删除localhost
node2
node32,3配置为worker
配置master
cd /export/server/spark/conf
mv spark-env.sh.template spark-env.shvim spark-env.sh增加如下内容(最后插入)
## 设置JAVA安装目录
JAVA_HOME=/export/server/jdk1.8.0_241
## HADOOP软件配置文件目录,读取HDFS上文件和运行Spark在YARN集群时需要,先提前配上
HADOOP_CONF_DIR=/export/server/hadoop-3.3.0/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop-3.3.0/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
SPARK_MASTER_HOST=node1
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
JAVA 和Hadoop如果不一样要改为自己的
(echo $JAVA_HOME)
分发到其他机器
cd /export/server/scp -r spark-3.0.1-bin-hadoop2.7 root@node2:$PWDscp -r spark-3.0.1-bin-hadoop2.7 root@node3:$PWD分发完创建一个软连接(改名)node2 node3
ln -s /export/server/spark-3.0.1-bin-hadoop2.7 /export/server/spark测试--运行
在主节点上启动spark集群------------------
/export/server/spark/sbin/start-all.sh在主节点上停止spark集群
/export/server/spark/sbin/stop-all.shjps
node1 多了个master
node2、node3上多了个worker
单独启动 主节点上单独启动和停止Master-----------------
start-master.shstop-master.sh在从节点上单独启动和停止Worker(Worker指的是slaves配置文件中的主机名)
start-slaves.shstop-slaves.sh集群的停止
/export/server/spark/sbin/stop-all.shweb界面(重要)
spark: 4040 任务运行job web-ui界面端口
spark: 8080 spark集群web-ui界面端口
spark: 7077 spark提交任务时的通信端口
hadoop: 50070集群web-ui界面端口
hadoop:8020/9000(老版本) 文件上传下载通信端口
启动spark-shell 测试任务
启动spark-shell
/export/server/spark/bin/spark-shell --master spark://node1:7077提交一个任务测试
直接提交(按照上面的local模式) 不行 worker是node2 node3 其上没有数单词数那个文件
先上传文件到hdfs
hadoop fs -put /root/words.txt /wordcount/input/words.txt目录如果不存在可以创建
hadoop fs -mkdir -p /wordcount/input结束后可以删除测试文件夹
hadoop fs -rm -r /wordcount执行
val textFile = sc.textFile("hdfs://node1:8020/wordcount/input/words.txt")val counts = textFile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)counts.collectcounts.saveAsTextFile("hdfs://node1:8020/wordcount/output47")查看结果
http://node1:50070/explorer.html#/wordcount/output47/
查看spark任务web-ui
http://node1:4040/jobs/
StandlonaHA高可用
原理
主Master只有一个 再加一个
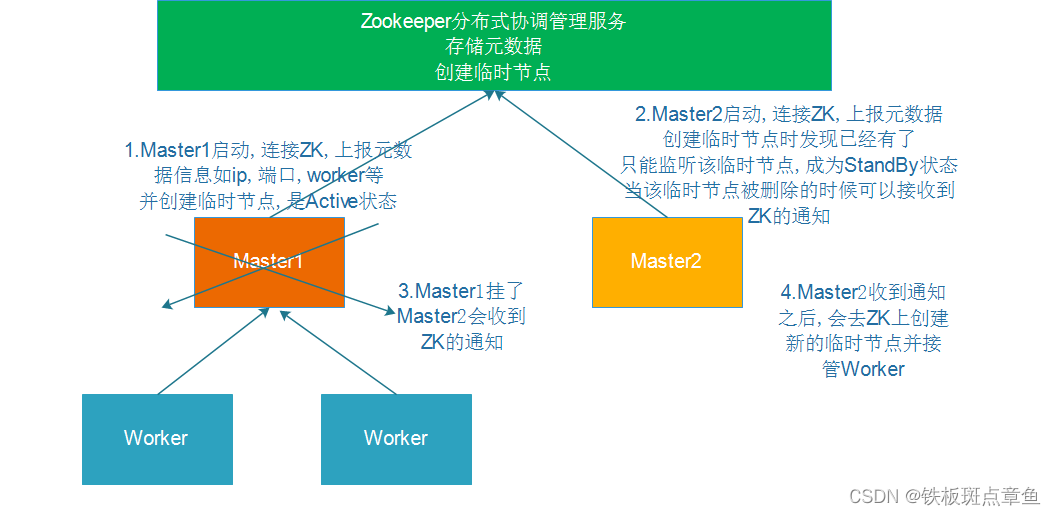
操作
停止集群
/export/server/spark/sbin/stop-all.sh
node1上配置
vim /export/server/spark/conf/spark-env.sh去掉注释
#SPARK_MASTER_HOST=node1最后加上(一行)
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"分发配置
cd /export/server/spark/confscp -r spark-env.sh root@node2:$PWDscp -r spark-env.sh root@node3:$PWD启动
启动zk服务(先要去配置zookeeper)
/opt/module/zookeeper/apache-zookeeper-3.5.6-bin/bin/zkServer.sh start
(node1 node2 node3都要)
zkServer.sh statuszkServer.sh stopzkServer.sh startnode1上启动Spark集群执行
/export/server/spark/sbin/start-all.sh在node2上再单独只起个master:两个master
/export/server/spark/sbin/start-master.sh
查看WebUI
模拟node1宕机
jps
kill -9 进程id(这里是Master的进程号)
再次查看web-ui
http://node1:8080/(刷新 挂了)
http://node2:8080/(ALIVE)
测试-WordCount
/export/server/spark/bin/spark-shell --master spark://node1:7077,node2:7077spark上运行
val textFile = sc.textFile("hdfs://node1:8020/wordcount/input/words.txt")val counts = textFile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)counts.collectcounts.saveAsTextFile("hdfs://node1:8020/wordcount/output47_2")spark-On-Yarn用的多
原理


操作-准备工作
关闭之前的Spark-Standalone集群
/export/server/spark/sbin/stop-all.sh(jps kill -9 (Master)node2
jps node3)(不知道用不用做)
配置Yarn历史服务器并关闭资源检查
vim /export/server/hadoop/etc/hadoop/yarn-site.xml<configuration>
<!-- 配置yarn主节点的位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 设置yarn集群的内存分配方案 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<!-- 开启日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>(配置了需要分发并重启yarn)
cd /export/server/hadoop/etc/hadoopscp -r yarn-site.xml root@node2:$PWDscp -r yarn-site.xml root@node3:$PWD/export/server/hadoop/sbin/stop-yarn.sh/export/server/hadoop/sbin/start-yarn.sh配置Spark的历史服务器和Yarn的整合
cd /export/server/spark/confmv spark-defaults.conf.template spark-defaults.confvim spark-defaults.conf添加内容
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/sparklog/
spark.eventLog.compress true
spark.yarn.historyServer.address node1:18080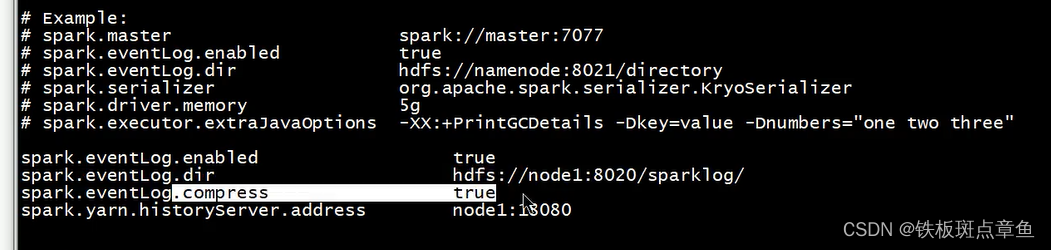
vim /export/server/spark/conf/spark-env.sh## 配置spark历史日志存储地址
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"注意:sparklog需要手动创建
hadoop fs -mkdir -p /sparklog修改日志级别
cd /export/server/spark/conf
mv log4j.properties.template log4j.propertiesvim log4j.properties
分发-可选,如果只在node1上提交spark任务到yarn,那么不需要分发
cd /export/server/spark/conf
scp -r spark-env.sh root@node2:$PWD
scp -r spark-env.sh root@node3:$PWD
scp -r spark-defaults.conf root@node2:$PWD
scp -r spark-defaults.conf root@node3:$PWD
scp -r log4j.properties root@node2:$PWD
scp -r log4j.properties root@node3:$PWD
配置依赖的Spark 的jar包
在HDFS上创建存储spark相关jar包的目录
hadoop fs -mkdir -p /spark/jars/上传$SPARK_HOME/jars所有jar包到HDFS
hadoop fs -put /export/server/spark/jars/* /spark/jars/在node1上修改spark-defaults.conf
vim /export/server/spark/conf/spark-defaults.conf添加内容
spark.yarn.jars hdfs://node1:8020/spark/jars/*分发同步-可选
cd /export/server/spark/confscp -r spark-defaults.conf root@node2:$PWDscp -r spark-defaults.conf root@node3:$PWD启动服务
启动HDFS和YARN服务,在node1执行命令
start-dfs.shstart-yarn.sh或者
start-all.sh启动MRHistoryServer服务,在node1执行命令
mr-jobhistory-daemon.sh start historyserver启动Spark HistoryServer服务,,在node1执行命令
/export/server/spark/sbin/start-history-server.shUI页面
MRHistoryServer服务WEB UI页面
Spark HistoryServer服务WEB UI页面
操作-spark任务提交
client模式-了解
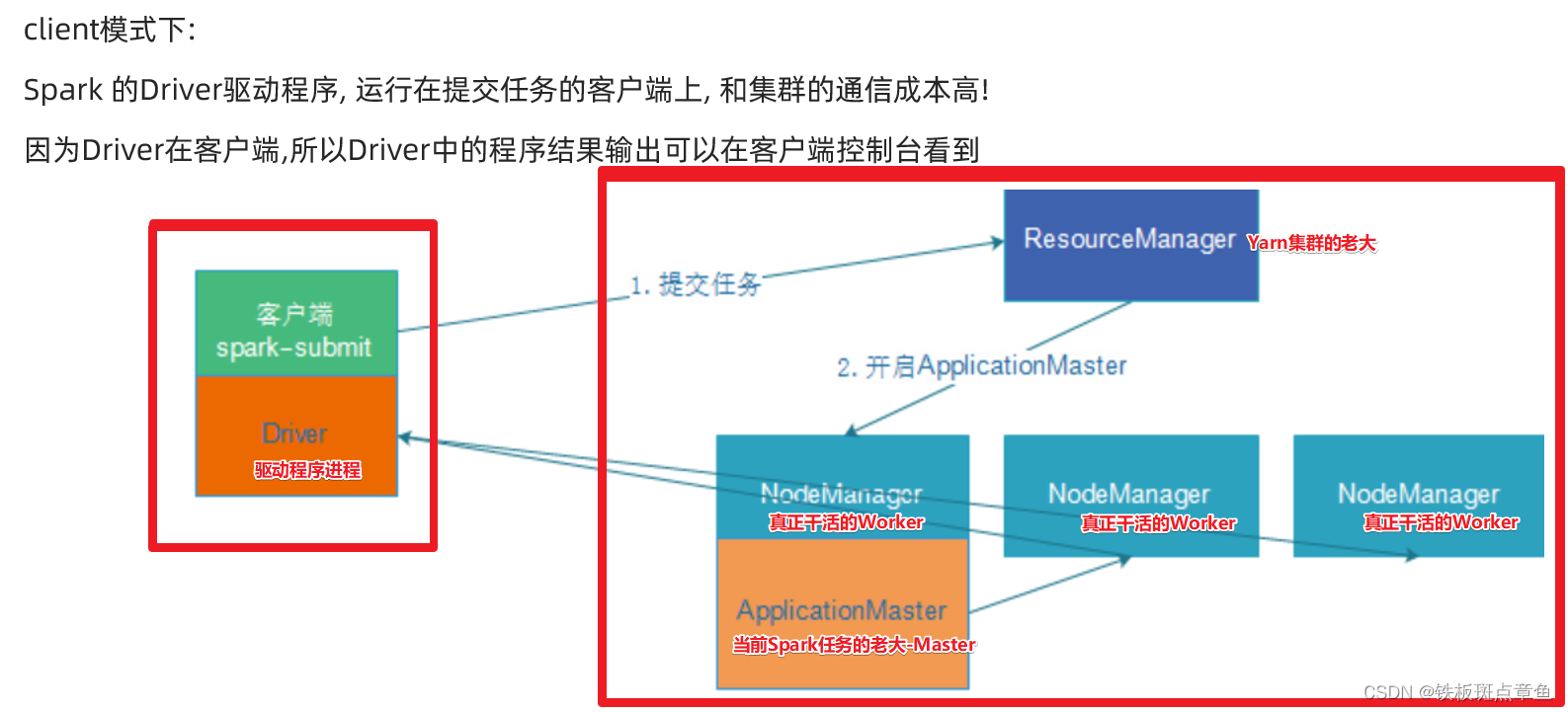
1需要Yarn集群
2历史服务器
3提交任务的客户端工具-spark-submit命令
4待提交的spark任务/程序的字节码--(自己不会创建可以用示例程序)
示例程序--求圆周率
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--driver-cores 1 \
--executor-memory 512m \
--num-executors 2 \
--executor-cores 1 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar \
10查看web界面
cluster模式-开发使用
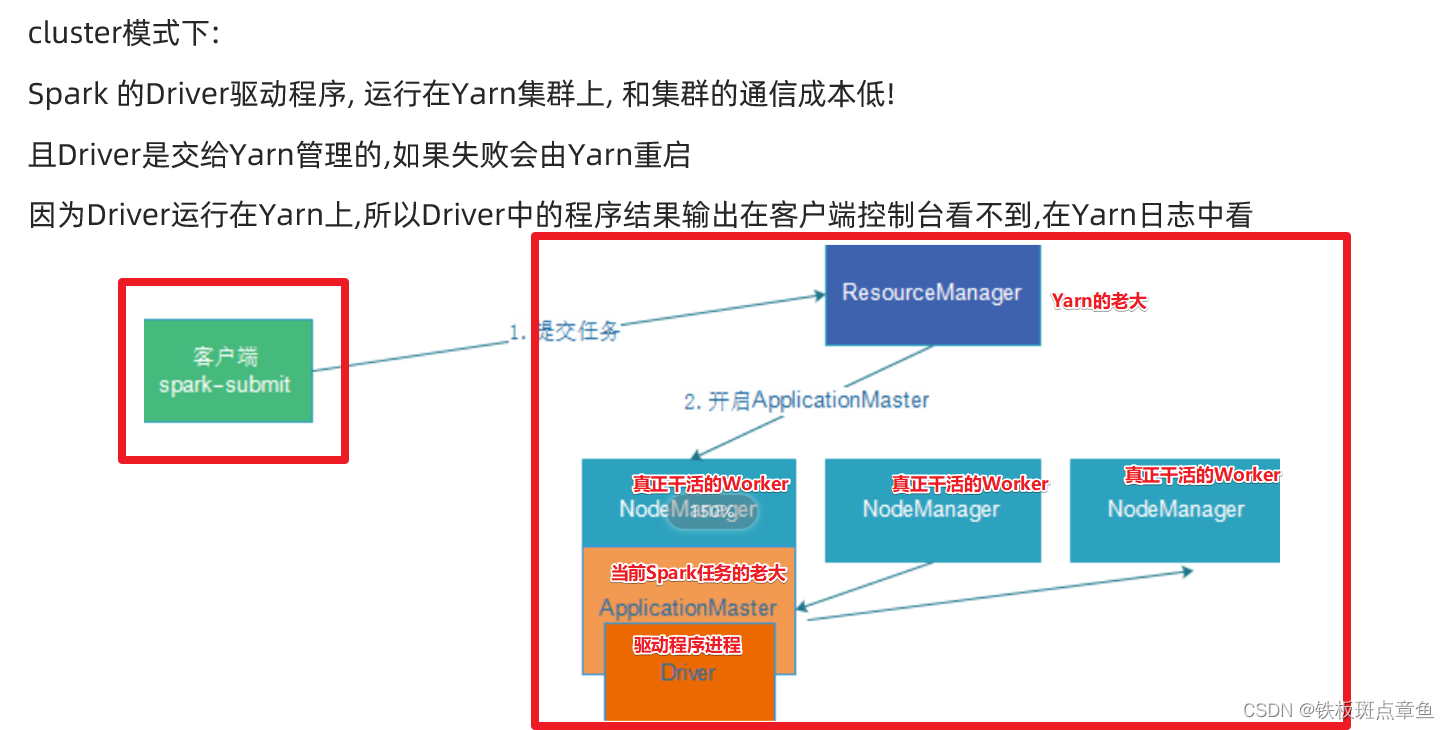
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 1 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar \
10














 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









