







概述
storm介绍
1.1.1流计算
实时获取来自不同数据源的海量数据,经过实时分析处理,获得有价值的信息
1.1.2、什么是storm
Storm是Twitter开源的、分布式的、容错的实时计算系统,遵循Eclipse Public License1.0。Storm通过简单的API使开发者可以可靠地处理无界持续的流数据,进行实时计算。
1.1.3、为什么要用storm
storm集群与hadoop都是批量计算的系统,但是hadoop专注于离线的批处理,而storm可以处理动态的数据,做到实时的流计算。同Hadoop一样Storm也可以处理大批量的数据,然而Storm在保证高可靠性的前提下还可以让处理进行的更加实时;也就是说,所有的信息都会被处理。Storm同样还具备容错和分布计算这些特性,这就让Storm可以扩展到不同的机器上进行大批量的数据处理。他同样还有以下的这些特性:
(1)易扩展性,对于扩展,你只需要添加机器和改变对应的topology(拓扑)设置。Storm使用Hadoop Zookeeper进行集群协调,这样可以充分的保证大型集群的良好运行。
(2) 可保证性,每条信息的处理都可以得到保证。
(3) 简易性,Storm集群管理简易
(4) 通用性,Storm中的topology可以用任何语言设计
1.1.4 storm与hadoop的比较

storm节点及组件
(1)节点
主节点:Nimbus,主要工作运行拓扑,分析元组tuple,收集执行的task,将task分给supervisor。
工作节点:supervisor,有多个处理进程,代理任务给所有的wokr进程,在Nimbus和supervisor之间使用内部的消息系统通信。
(2)组件
Nimbus:master node ,在work node间分发数据,指派task给work node,监控故障
supervisor:接收nimbus的指令,有多个work进程,监视work进程,完成task
work process:执行相关的task,本身不执行,创建executor(执行线程),可以有多个执行线程
executor:执行线程
task:处理数据
zookeeper:维持状态
storm设计思想
Storm设计思想包括Streams、Spouts、Bolts、Topology和StreamGroupings
Streams:Storm将流数据Stream描述成一个无限的Tuple序列,这些Tuple序列会以分布式的方式并行地创建和处理

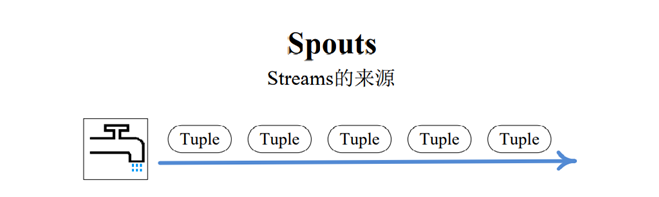
Spout会从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,发送到Stream中
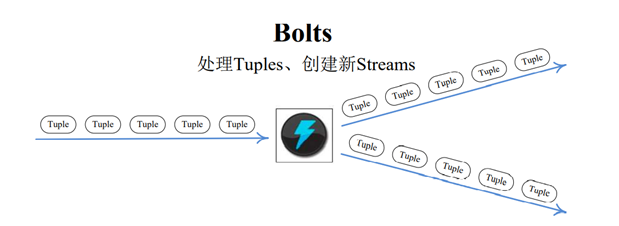
经过Steams抽象的Bolt即可以处理Tuple,也可以将处理后的Tuple作为新的Streams发送给其他Bolt
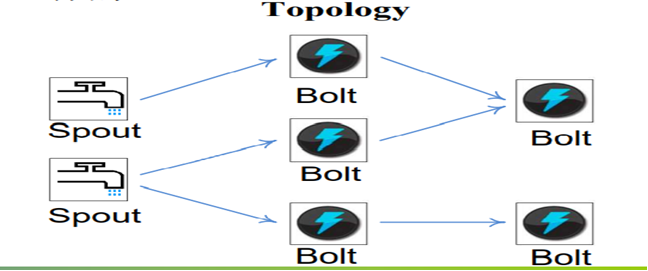
Storm将Spouts和Bolts组成的网络抽象成Topology,它可以被提交到Storm集群执行
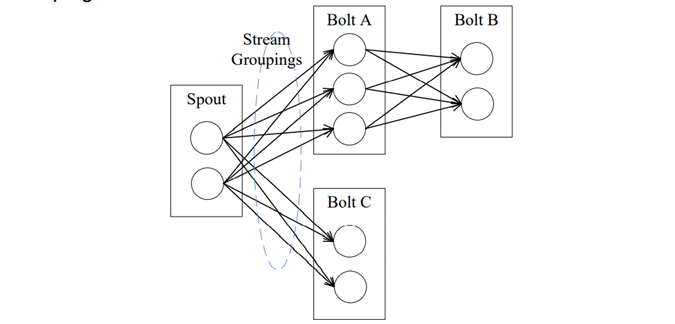
Storm中的Stream Groupings用于告知Topology如何在两个组件间进行Tuple的传送
环境搭建
4.1创建docker容器
容器搭建
因为是采用伪分布设计,这一步是必须的,如果有很多的机器用于分布式计算,这一步可以省略。才有伪分布的原因是为了更好地学习与掌控,降低学习成本。
分别搭建了主节点storm-master,两个从节点storm-slave1和storm-slave2
#!/bin/bash networkcreate -d bridge --subnet 172.25.0.0/16 strom-net
docker run -itd--name storm-master --network storm-net -h storm-master ubuntu
docker exec -itstorm-master /bin/bash
docker run -itd--name storm-slave1 --network storm-net -h storm-slave1 ubuntu
docker run -itd--name storm-slave2 --network storm-net -h storm-slave2 ubuntu

期末了,等期末后再更新















 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









