






评估并优化检索部分
一、评估检索效果
RAG 系统针对用户输入的一个 query,系统会将其转化为向量并在向量数据库中匹配最相关的文本段,然后根据设定选择 3~5 个文本段落和用户的 query 一起交给大模型,再由大模型根据检索到的文本段落回答用户 query 中提出的问题。在这一整个系统中,将向量数据库检索相关文本段落的部分称为检索部分,将大模型根据检索到的文本段落进行答案生成的部分称为生成部分。
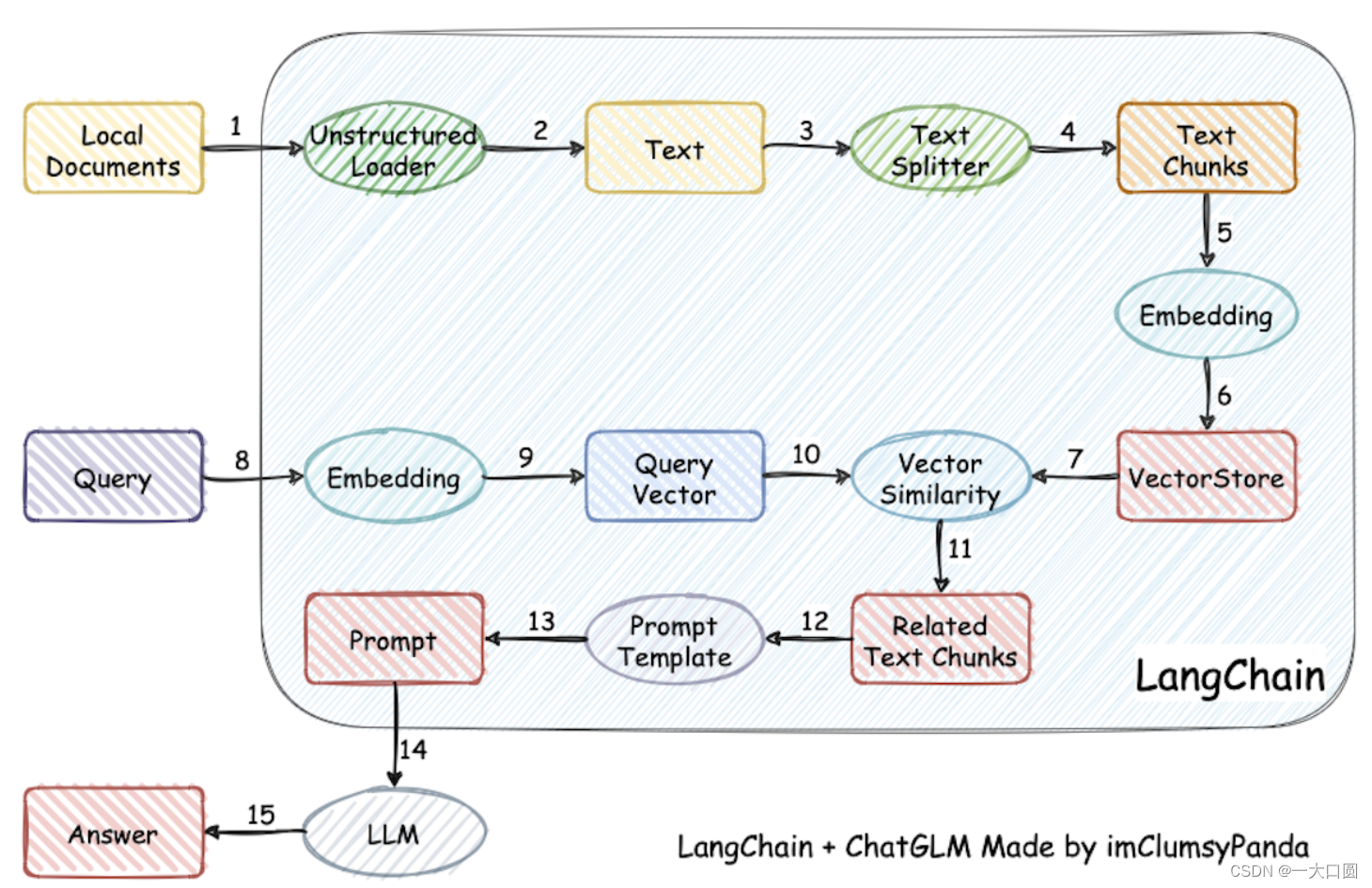
因此,检索部分的核心功能是找到存在于知识库中、能够正确回答用户 query 中的提问的文本段落。因此,定义一个最直观的准确率在评估检索效果:对于 N 个给定 query,我们保证每一个 query 对应的正确答案都存在于知识库中。假设对于每一个 query,系统找到了 K 个文本片段,如果正确答案在 K 个文本片段之一,那么认为检索成功;如果正确答案不在 K 个文本片段之一,我们任务检索失败。
系统的检索准确率可以被简单计算为:
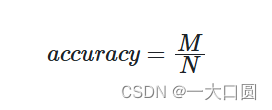
其中,M 是成功检索的 query 数。
通过上述准确率,可以衡量系统的检索能力,对于系统能成功检索到的 query,才能进一步优化 Prompt 来提高系统性能。对于系统检索失败的 query,就必须改进检索系统来优化检索效果。但是在计算如上定义的准确率时,一定要保证每一个验证 query 的正确答案都确实存在于知识库中;如果正确答案本就不存在,应该将 Bad Case 归因到知识库构建部分,说明知识库构建的广度和处理精度还有待提升。
还可以将检索部分建模为一个经典的搜索任务。让我们来看看经典的搜索场景。搜索场景的任务是,针对用户给定的检索 query,从给定范围的内容(一般是网页)中找到相关的内容并进行排序,尽量使排序靠前的内容能够满足用户需求。
import sys
sys.path.append("../C3 搭建知识库") # 将父目录放入系统路径中
# 使用智谱 Embedding API,注意,需要将上一章实现的封装代码下载到本地
from zhipuai_embedding import ZhipuAIEmbeddings
from langchain.vectorstores.chroma import Chroma
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv, find_dotenv
import os
_ = load_dotenv(find_dotenv()) # read local .env file
zhipuai_api_key = os.environ['ZHIPUAI_API_KEY']
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
# 定义 Embeddings
embedding = ZhipuAIEmbeddings()
# 向量数据库持久化路径
persist_directory = '../../data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embedding
)
量化评估:
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
template_v1 = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。最多使用三句话。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
问题: {question}
"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template_v1)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
print("问题一:")
question = "南瓜书和西瓜书有什么关系?"
result = qa_chain({"query": question})
print(result["result"])
print("问题二:")
question = "应该如何使用南瓜书?"
result = qa_chain({"query": question})
print(result["result"])template_v2 = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。你应该使答案尽可能详细具体,但不要偏题。如果答案比较长,请酌情进行分段,以提高答案的阅读体验。
{context}
问题: {question}
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template_v2)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
print("问题一:")
question = "南瓜书和西瓜书有什么关系?"
result = qa_chain({"query": question})
print(result["result"])
print("问题二:")
question = "应该如何使用南瓜书?"
result = qa_chain({"query": question})
print(result["result"])自动评估:
def multi_select_score_v1(true_answer : str, generate_answer : str) -> float:
# true_anser : 正确答案,str 类型,例如 'BCD'
# generate_answer : 模型生成答案,str 类型
true_answers = list(true_answer)
'''为便于计算,我们假设每道题都只有 A B C D 四个选项'''
# 先找出错误答案集合
false_answers = [item for item in ['A', 'B', 'C', 'D'] if item not in true_answers]
# 如果生成答案出现了错误答案
for one_answer in false_answers:
if one_answer in generate_answer:
return 0
# 再判断是否全选了正确答案
if_correct = 0
for one_answer in true_answers:
if one_answer in generate_answer:
if_correct += 1
continue
if if_correct == 0:
# 不选
return 0
elif if_correct == len(true_answers):
# 全选
return 1
else:
# 漏选
return 0.5二、优化检索的思路
Bad Case 归因和可行的优化思路:
1. 知识片段被割裂导致答案丢失
2. query 提问需要长上下文概括回答
3. 关键词误导
4. 匹配关系不合理















 242
242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









