







文章目录
循环单链表是单链表的另一种形式,其结构特点链表中最后一个结点的指针域不再是结束标记,而是指向整个链表的第一个结点,从而使链表形成一个环。
循环单链表的表尾结点的next指针总是指向头结点。
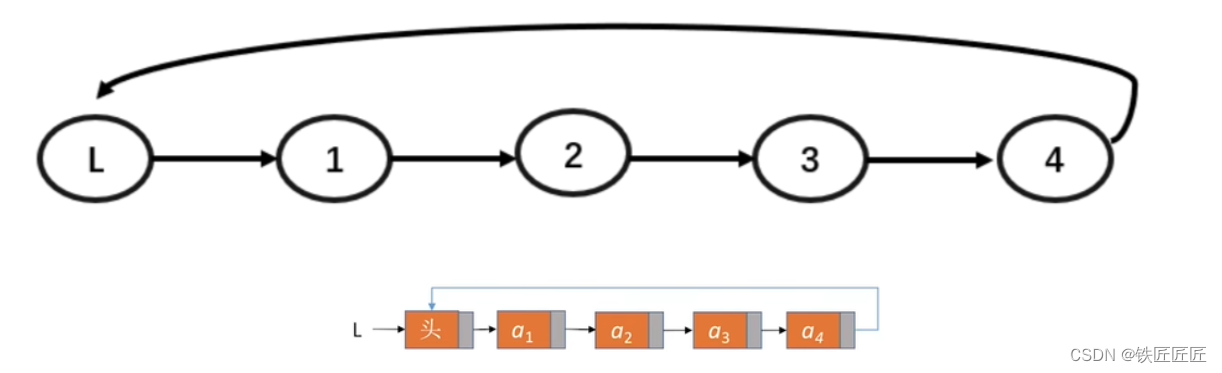
所以在初始化循环单链表的时候,需要记得将头结点的next指针指向头结点自己:
#include <stdio.h>
#include "stdlib.h"
typedef struct Node
{
int data;
struct Node *next;
}Node;
/*所以在初始化循环单链表的时候,需要记得将头结点的next指针指向头结点自己:*/
Node* InitList()
{
Node* list = (Node*)malloc(sizeof(Node));
list -> data = 0;
list -> next = list;
return list;
}
void headInsert(Node* list, int data)
{
Node* node = (Node*)malloc(sizeof(Node));
node -> data = data;
node -> next = list -> next;
list -> next = node;
list -> data++;
}
void tailInsert(Node* list, int data)
{
Node* head = list;
Node* node = (Node*)malloc(sizeof(Node));
node -> data = data;
while(list -> next != head)
{
list = list -> next;
}
node -> next = head;
list -> next = node;
head ->data ++;
}
void delete(Node* list, int data)
{
Node* preNode = list;
Node* node = list -> next;
while(node != list)
{
if(node -> data == data)
{
preNode -> next = node->next;
free(node);
list -> data --;
break;
}
preNode = node;
node = node -> next;
}
}
void printfList(Node* list)
{
Node* head = list;
list = list -> next;
while(list != head)
{
printf("%d->", list -> data);
list = list -> next;
}
printf("\n");
}
void main()
{
Node* list = InitList();
headInsert(list,1);
headInsert(list,2);
headInsert(list,3);
headInsert(list,3);
tailInsert(list,4);
tailInsert(list,5);
tailInsert(list,6);
printfList(list);
delete(list,3);
printfList(list);
}
判断结点是否是循环单链表的表尾结点
只需判断该结点的next指针是否指向头结点即可,因为循环链表的最后一个结点的next指针总是指向头结点的:
判断循环单链表是否为空
只要判断头结点的next指针是否指向自己就可以了,因为循环链表的最后一个结点的next指针总是指向头结点的,如果为空,那就只能是头结点的next指针指向自己了:
循环单链表有一些重要的性质:
1、从一个结点出发,无论这个结点位于链表的哪里,都可以找到其他任何一个结点,而单链表不行。
2、在一些情况下,我们需要频繁对链表的头部和尾部进行操作,此时使用循环单链表就很有用,原因是对于单链表,已知头结点,想找到最后一个结点的话,时间复杂度是O(n);但是对于循环单链表,我们可以一开始就把头指针指向尾结点,这样找到尾结点所需时间复杂度是O(1),因为尾结点的next指针总是指向头结点,所以找到头结点的时间复杂度也是O(1)。因此,循环单链表在这种情况下的表现明显优于普通的单链表。
往期回顾
1.【第一章】《线性表与顺序表》
2.【第一章】《单链表》
3.【第一章】《单链表的介绍》
4.【第一章】《单链表的基本操作》















 1010
1010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









