






 本文详细介绍了深度学习的必要性,全连接网络的问题,以及PyTorch库的简介。重点讲解了卷积神经网络的基础知识,包括其进化历程、基本概念、LeNet-5、AlexNet、VGG-16、残差网络和Inception网络。同时还列举了常用的图像数据集,如MNIST、Fashion-MNIST、CIFAR-10等,以及ImageNet在计算机视觉中的重要性。
本文详细介绍了深度学习的必要性,全连接网络的问题,以及PyTorch库的简介。重点讲解了卷积神经网络的基础知识,包括其进化历程、基本概念、LeNet-5、AlexNet、VGG-16、残差网络和Inception网络。同时还列举了常用的图像数据集,如MNIST、Fashion-MNIST、CIFAR-10等,以及ImageNet在计算机视觉中的重要性。
课程小结二:卷积神经网络基础
为什么要“深度”学习
全连接网络问题
全连接网络:链接权过多 ,算的慢,难 收敛,同时可能进入局部极小值,也容易产生过拟合问题
e.g. 输入为 1000×1000图像 ,隐含层有 1M 个节点,则输入隐含层间有
1
×
1
0
12
1×10^{12}
1×1012数量级参数
解决算的慢问题:减少权值连接,每一个节点只连接到上一层的少数神经元,即局部连接网络。
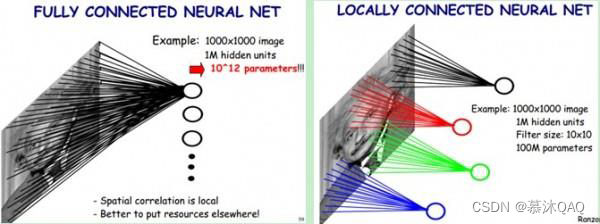
解决难收敛、算的慢问题 :权值过多极易产生过拟合。如何消除?
回想人类解决思路:信息分层处理,每一层在上层提取特征的基础上获取进行再处理,得到更高级别的特征。
深度学习平台简介
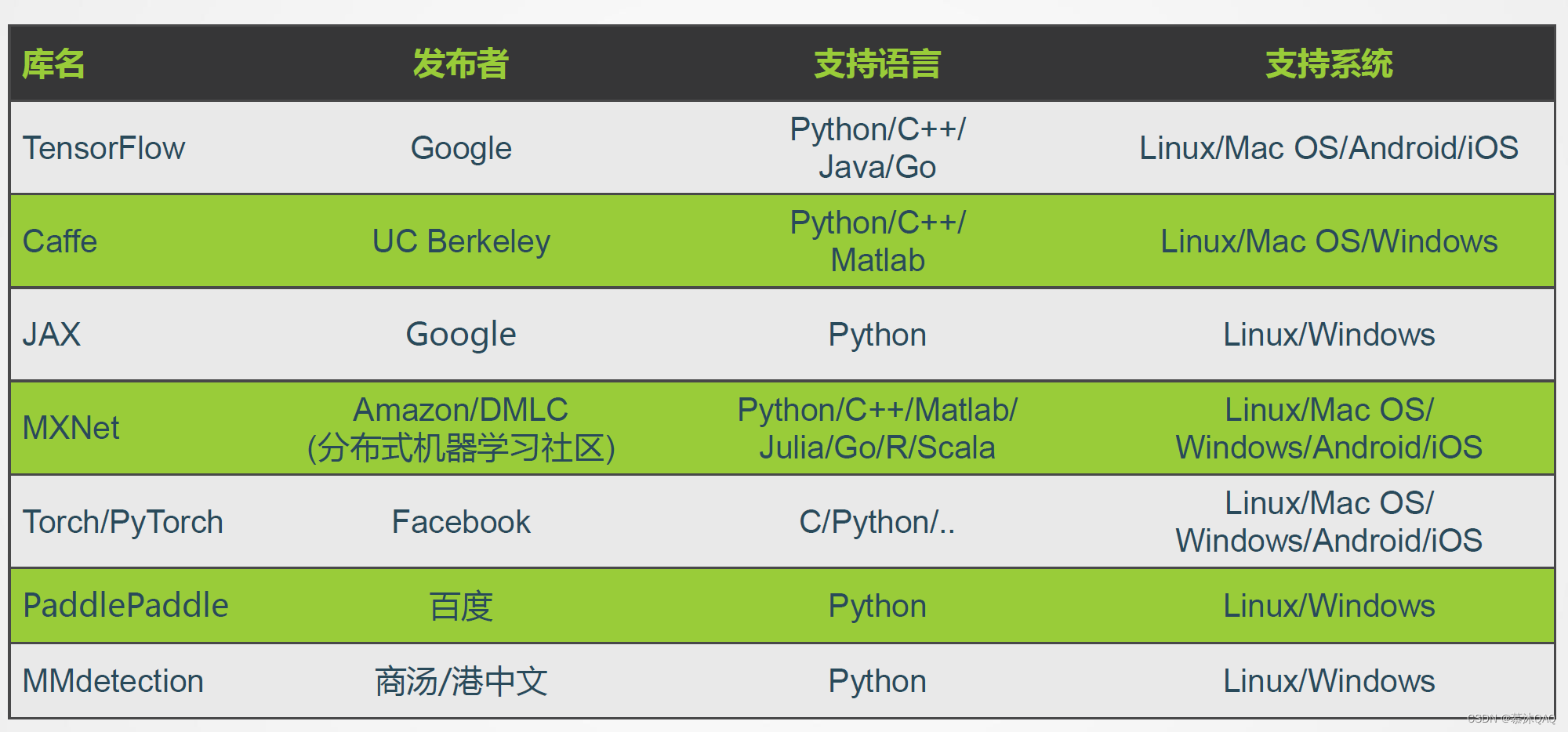
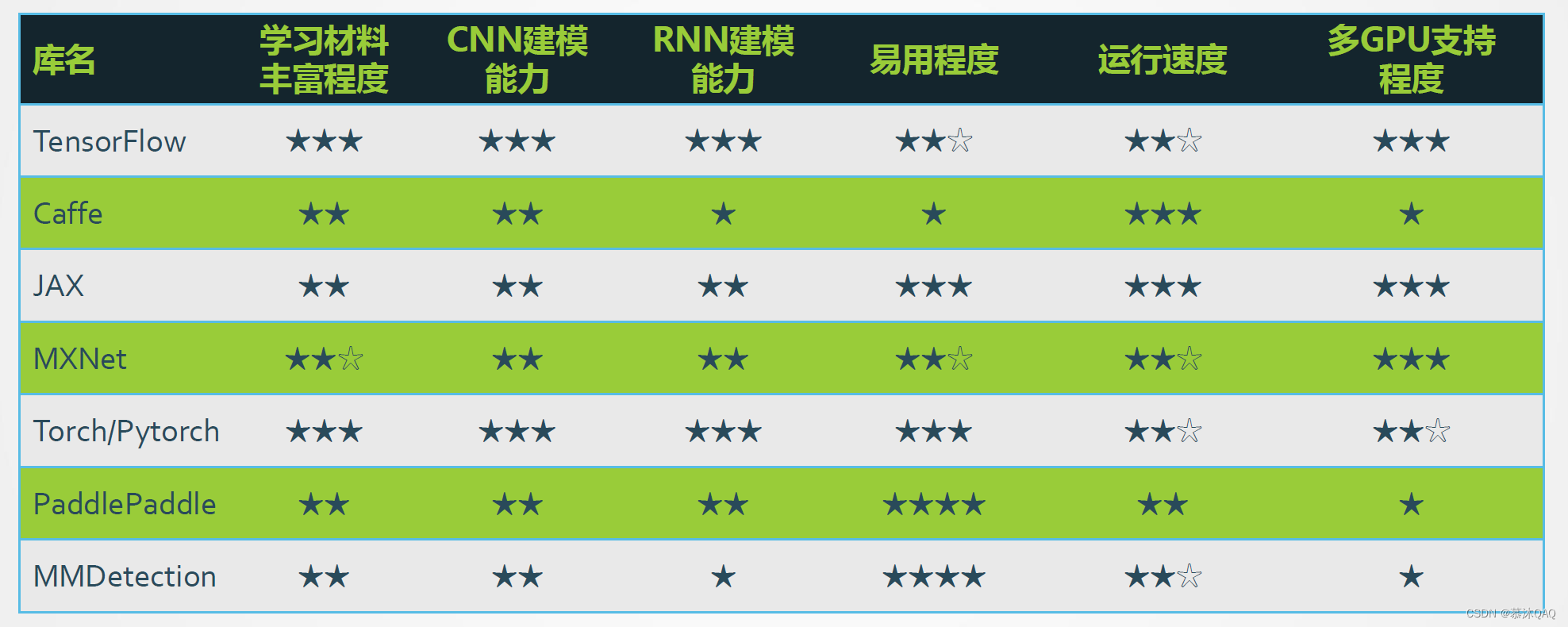
PyTorch 简介
- PyTorch 是一个 Python 的深度学习库 。 它最初由 Facebook 人工智能研究小组开发 而优步的 Pyro 软件则用于概率编程 。
- 最初 PyTorch 由 Hugh Perkins 开发 作为基于 Torch 框架的 LusJIT 的Python 包装器 。 PyTorch 在 Python 中重新设计和实现 Torch 同时为后端代码共享相同的核心 C 库 。
- 除了 Facebook 之外 Twitter 、 GMU 和 Salesforce 等机构都采用了PyTorch 。
- 到目前 据统计已有 80 的研究采用 PyTorch 包括 Google
PyTorch 基本使用 基本概念
张量(Tensor):是一个物理量,对高维(维数 ≥ 2) 的物理量进行“量纲分析 的一种工具。简单的可以理解为:一维数组称为矢量,二维数组为二阶张量,三维数组为三阶张量……
计算图:用“结点”(nodes )和“线 ”( 的有向图来描述数学计算的图像。“节点” 一般用来表示施加的数学操作,但也可以表示数据输入的起点 输出的终点,或者是读取 写入持久变量的终点。“线”表示“节点”之间的输入 输出关系。这些数据“线”可以输运“ size 可动态调整”的多维数据数组,即“张量”(tensor)
- 使用 tensor 表示数据
- 使用 Dataset 、 DataLoader 读取样本数据和标签
- 使用变量 (Variable) 存储神经网络权值等参数
- 使用计算图 (computational graph) 来表示计算任务
- 在代码运行过程中同时执行计算图
PyTorch 基本使用——简单示例
构建简单的计算图,每个节点将零个或多个tensor 作为输入,产生一个tensor 作为输出。 PyTorch 中,所见即为所得, tensor 的使用和 numpy 中的多维数组类似
import torch
x_const = torch.tensor([1.0, 2.0, 3.0])
y = torch.torch.tensor(3.0 , 4.0 , 5.0)
output = x_const + y
print(x_const, '\n', y, '\n' ,output)
tensor([1.0, 2.0, 3.0])
tensor([3.0, 4.0, 5.0])
tensor([4.0, 6.0, 8.0])
卷积神经网络基础
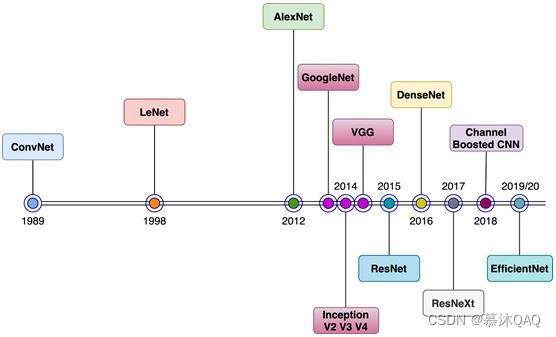
进化史
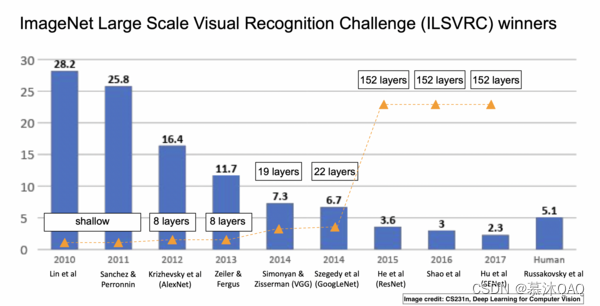
基本概念
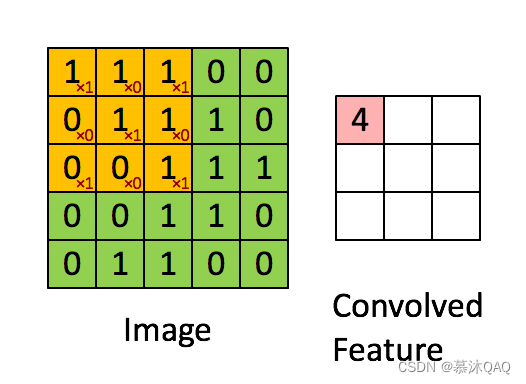
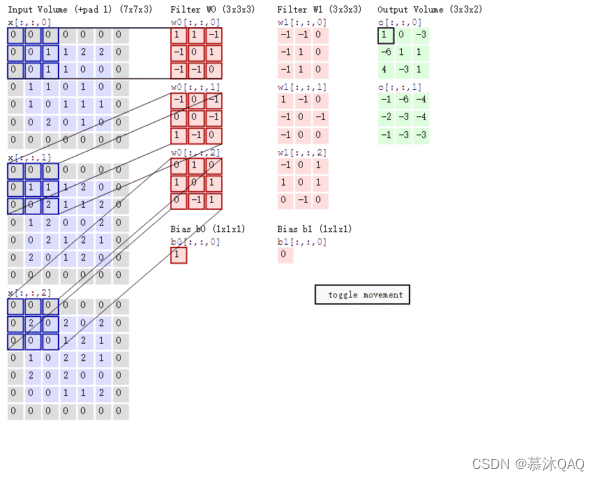
卷积:注意,图像卷积时,根据定义,需要首先把卷积核上下左右转置。此处卷积核(黄色)是对称的,所以忽视。
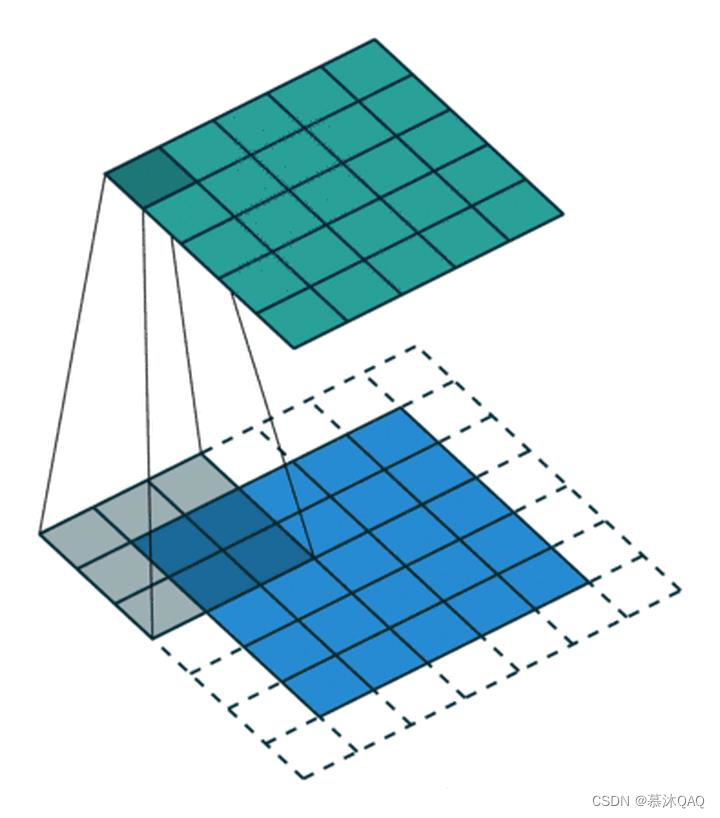
填充(Padding),也就是在矩阵的边界上填充一些值,以增加矩阵的大小,通常用 0 或者复制边界像素来进行填充。
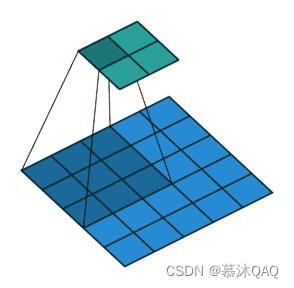
步长 ( Stride):如图步长为 2
多通道卷积:如 RGB
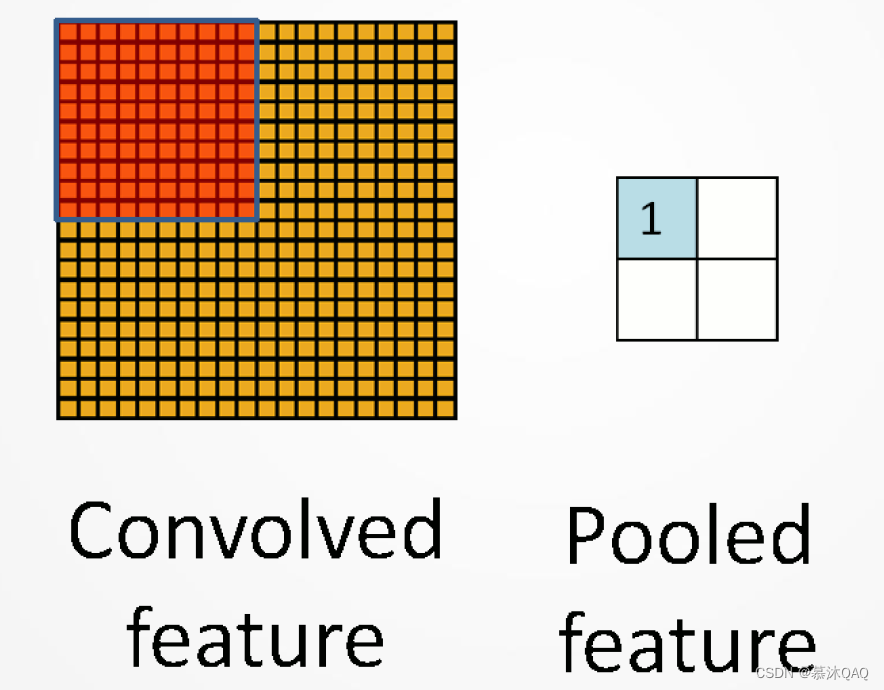
池化思想:使用局部统计特征,如均值或最大值。解决特征过多问题
卷积神经网络结构:
- 构成:由多个卷积层和下采样层构成,后面可连接全连接网络卷
- 卷积层:𝑘个滤波器
- 下采样层:采用 mean 或 max
- 后面:连着全连接网络
学习算法
前向传播:将输入数据通过神经网络的各层进行计算,直至得到最终输出的过程。整个神经网络的前向传播过程就是从输入层开始,通过不断更新权重和偏置,逐层计算得到最终的输出。
误差反向传播:一种用于训练神经网络的算法,它通过计算网络预测输出与实际输出之间的误差,并将误差沿着网络反向传播,以更新网络参数(权重和偏置)。通过有效地传播误差并更新参数,使网络能够逐渐学习到正确的映射关系,从而提高预测准确性。
LeNet-5网络
LeNet-5是由Yann LeCun等人于1998年提出的卷积神经网络(Convolutional Neural Network,CNN)架构,是早期用于手写数字识别的经典模型之一。包括七层,其中包括两个卷积层,两个池化层和三个全连接层。下面是LeNet-5的主要结构:
- 输入层:接受手写数字的图像输入。
- 卷积层:包括6个卷积核,每个卷积核大小为5x5,通过卷积操作提取图像的特征。
- 池化层:使用2x2的最大池化操作,对卷积层的输出进行下采样,减小特征图的尺寸。
- 卷积层:包括16个卷积核,每个卷积核大小为5x5,继续提取更高级别的特征。
- 池化层:使用2x2的最大池化操作,再次对卷积层的输出进行下采样。
- 全连接层:包括三个全连接层,分别包含120个、84个和最终的输出层10个神经元。在全连接层中,将卷积层和池化层提取的特征进行扁平化,然后通过神经网络进行分类。
- 输出层:包含10个神经元,对应10个手写数字的类别,使用softmax函数进行多类别分类。
基本卷积神经网络
AlexNet
AlexNet是由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年提出的深度卷积神经网络模型。它是首个在大规模图像识别竞赛ImageNet上取得显著突破的深度学习模型,标志着深度学习技术在计算机视觉领域的兴起。
- 深度和宽度:相较于之前的模型,AlexNet更深、更宽。它包含5个卷积层和3个全连接层,共8层神经网络结构。
- ReLU激活函数:AlexNet首次引入了ReLU作为激活函数,加速了网络的训练速度。
- Dropout正则化:在全连接层中,随机地将一部分神经元的输出置为零,以减少过拟合。
- 局部响应归一化:有助于增强特征的鲁棒性。
- 数据增强:在训练过程中,使用了数据增强技术,如随机裁剪、水平翻转等,以增加训练数据的多样性,提高模型的泛化能力。
VGG-16
VGG-16是由牛津大学的Visual Geometry Group (VGG)团队在2014年提出的深度卷积神经网络模型。它的名称“VGG-16”表示该模型包含16个卷积和全连接层。
- 结构简单一致:VGG-16的网络结构非常简单和一致,由16层深度的卷积层和全连接层组成,卷积层之后跟随最大池化层,以减小特征图的空间大小。
- 小卷积核:VGG-16采用了小尺寸的3x3卷积核,使得网络更深但参数量不至于过大,这有助于提升模型的表征能力。
深度堆叠:VGG-16在深度方面超越了以往的模型,采用连续的多个卷积层堆叠在一起,从而能够提取更加丰富和复杂的特征。 - 全连接层:VGG-16包含三个全连接层,用于将卷积层提取的特征映射到输出类别。这些全连接层在结构上与AlexNet相似,但参数更多。
残差网络
残差网络(Residual Network,ResNet)是由微软亚洲研究院的Kaiming He等人在2015年提出的一种深度卷积神经网络架构。ResNet通过引入残差块(Residual Block)来解决深度神经网络训练过程中的梯度消失和梯度爆炸问题,从而允许构建更深的网络。
- 解决梯度消失问题:通过跳跃连接,使得梯度能够更容易地传播回较浅的层次,从而减轻了梯度消失问题。
- 允许训练更深的网络:由于梯度能够更好地传播,ResNet允许构建更深层次的神经网络,从而提升了模型的表达能力。
- 更快的收敛速度:相较于传统的深层网络,ResNet在训练过程中收敛更快。
Inception网络
Inception网络是由Google Brain团队在2014年提出的一种深度卷积神经网络结构,旨在解决深度神经网络中的计算量和参数数量的问题。Inception网络的核心思想是同时使用不同大小的卷积核和池化操作,以捕获不同尺度的特征。
- Inception模块:Inception网络使用了一系列称为Inception模块的结构。这些模块包含了多个不同尺寸的卷积核和池化操作,并行地处理输入特征图,然后将它们的输出在通道维度上拼接起来。这样的设计使得网络可以同时学习到不同尺度的特征。
- 1x1卷积核的使用:在Inception模块中,1x1卷积核用于降低输入特征图的通道数,从而减少计算量和参数数量。此外,1x1卷积还有助于引入非线性变换,增强网络的表达能力。
- 全局平均池化:在网络的最后阶段,通常使用全局平均池化来将特征图的空间维度降为1x1,然后通过全连接层进行分类。这样的设计使得网络更加简单,减少了过拟合的风险。
- 网络深度和宽度:Inception网络可以通过增加模块的数量和深度来提升性能,同时由于1x1卷积的使用,网络的宽度(即通道数)可以适当增加而不至于引入过多的参数。
附录:常用数据集
MNIST数据集
MNIST数据集是一个广泛用于机器学习和深度学习的经典数据集之一。它由手写数字的灰度图像组成,包括0到9这10个数字,每个数字对应着一个类别。每张图像的尺寸为28x28像素,采用灰度图像表示。
训练集:包含了60,000张手写数字图像,每张图像都标注有对应的数字标签,用于训练机器学习模型。
测试集:包含了10,000张手写数字图像,同样每张图像都标注有对应的数字标签,用于评估模型的性能。
Fashion-MNIST 数据集
Fashion-MNIST数据集是一个用于机器学习和深度学习的经典数据集之一,它是MNIST数据集的一个替代版本。Fashion-MNIST数据集包含手写图像,代表服装和配件,而不是手写数字。Fashion-MNIST数据集包含了10个类别的灰度图像,分别是T恤/上衣、裤子、套头衫、裙子、外套、凉鞋、衬衫、运动鞋、包和短靴。每个类别包含了约6,000张训练图像和1,000张测试图像。
Fashion-MNIST数据集被设计用于在机器学习和深度学习领域中对图像分类算法进行基准测试。与MNIST数据集类似,Fashion-MNIST数据集相对较小且简单,使得它成为学习和验证机器学习算法的理想选择。
CIFAR-10 数据集
CIFAR-10数据集是一个广泛用于机器学习和计算机视觉领域的经典数据集之一。它由加拿大计算机科学家Alex Krizhevsky、Vinod Nair和Geoffrey Hinton在2009年创建。CIFAR-10数据集包含了10个类别的彩色图像,代表了10个不同类别的物体或动物,包括飞机、汽车、鸟类、猫、鹿、狗、蛙、马、船和卡车。每个类别有约6,000张图像,总共包含60,000张图像。
CIFAR-10数据集被广泛用于图像分类、目标识别和图像分割等计算机视觉任务的基准测试。由于数据集的规模适中,使得它成为学习和验证机器学习模型的理想选择。
PASCAL VOC数据集
PASCAL VOC数据集是一个用于目标检测、图像分割和图像分类任务的常用数据集之一。它起源于PASCAL Visual Object Challenge(PASCAL VOC)比赛,该比赛于2005年至2012年期间举办,旨在推动计算机视觉领域的研究和发展。PASCAL VOC数据集涵盖了20个常见物体类别,包括人、车辆、动物、家具等。每个图像都配有对应的标注信息,标注信息通常包括物体边界框(Bounding Box)的位置和类别标签。此外,对于图像分割任务,还提供了每个像素的语义分割标注。除了目标检测和图像分类任务外,PASCAL VOC数据集还提供了分割任务的挑战,即要求模型对图像中的每个像素进行分类,从而实现物体的像素级别分割。
MS COCO数据集
MS COCO数据集是一个用于目标检测、图像分割和图像标注任务的大型图像数据集。它由微软公司发布,旨在推动计算机视觉领域的研究和发展。MS COCO数据集包含了80个不同的物体类别,涵盖了人类、动物、交通工具、家具等多个领域。包含了超过10万张图像,每张图像都配有详细的标注信息,包括物体边界框的位置和类别标签,以及像素级别的语义分割标注。除了物体边界框和语义分割标注外,MS COCO数据集还提供了一些更复杂的标注任务,如图像描述和关键点检测,这使得该数据集更具挑战性。
ImageNet数据集
ImageNet数据集是一个用于图像识别和分类任务的大型图像数据集,由斯坦福大学的李飞飞(Fei-Fei Li)教授及其研究团队创建。该数据集旨在推动计算机视觉领域的研究和发展,是深度学习研究中最具影响力的数据集之一。包含了数百万张图像,覆盖了几千个不同的物体类别。每个类别都有成千上万张图像,这使得数据集具有很高的多样性和覆盖范围。涵盖了各种各样的物体类别,包括动物、植物、人类、建筑等,涵盖了世界上大部分常见的物体和场景。每张图像都配有详细的标注信息,包括物体类别的标签和边界框的位置。这些标注信息是通过人工标注和众包技术得到的,具有较高的准确性和可靠性。
ISLVRC 2012子数据集
ILSVRC2012子数据集是ImageNet数据集的一个子集,用于举办ILSVRC 2012比赛。ILSVRC是一个图像分类竞赛,旨在评估计算机视觉模型在大规模图像数据集上的分类准确性。包含了1000个不同的物体类别,涵盖了各种各样的物体和场景,如动物、植物、日常物品、交通工具等。该子数据集包含了数百万张图像,其中包括训练集、验证集和测试集。训练集用于训练模型,验证集用于调优模型的超参数,测试集用于评估模型的性能。图像的分辨率较高,通常为几百像素至数千像素之间,这使得数据集具有一定的挑战性。每张图像都配有对应的类别标签,标签是从1000个类别中选择的一个,用于评估模型在图像分类任务上的性能。
总结
经典网络 ::以“一个或多个卷积层 一个池化层“作为一个基本单元进行堆叠,在网络尾部使用全连接层,最后以 Softmax 为分类器,输出结果。
**残差网络 **:在普通网络的基础上,将浅层的激活项通过支路直接传向深层,克服深层神经网络中梯度消失的问题,为训练极深的神经网络提供便利。
数据集:常见的数据集包括 VOC 和 COCO;ImageNet 较大















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









