






AlexNet网络架构
AlexNet整体的网络结构包括:1个输入层、5个卷积层、2个全连接层和1个输出层。

输入层(Input Layer)
AlexNet输入图像的尺寸为227*227*3,并非论文中的224*224*3
卷积层(C1)
处理流程是:卷积->ReLU->局部响应归一化->池化
卷积:输入为227*227*3,使用96个11*11*3的卷积核进行卷积,padding=0,stride=4,根据公式:(input_size + 2 * padding - kernel_size) / stride + 1=(227+2*0-11)/4+1=55,得到输出是55*55*96。
ReLU:将卷积层输出的FeatureMap输入到ReLU函数中。
局部响应归一化:局部响应归一化层简称LRN,是在深度学习中提高准确度的技术方法。一般是在激活、池化后进行。LRN对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
LRN公式如下:

a为归一化之前的神经元,b为归一化之后的神经元;N是卷积核的个数,也就是生成的FeatureMap的个数;k,α,β,n是超参数,论文中使用的值是k=2,n=5,α=0.0001,β=0.75。
局部响应归一化后仍为55*55*96。单个GPU上的大小为55*55*48
池化:使用3*3,stride=2的池化单元进行max pooling。(55+2*0-3)/2+1=27, 输出的大小为27*27*48
卷积层(C2)
该层的处理流程是:卷积-->ReLU-->局部响应归一化(LRN)-->池化。
卷积:两组输入均是27x27x48,各组分别使用128个5x5x48的卷积核进行卷积,padding=2,stride=1,根据公式:(input_size + 2 * padding - kernel_size) / stride + 1=(27+2*2-5)/1+1=27,得到每组输出是27x27x128。
ReLU:将卷积层输出的FeatureMap输入到ReLU函数中。
局部响应归一化:使用参数k=2,n=5,α=0.0001,β=0.75进行归一化。每组输出仍然是27x27x128。
池化:使用3x3,stride=2的池化单元进行最大池化操作(max pooling)。注意这里使用的是重叠池化,即stride小于池化单元的边长。根据公式:(27+2*0-3)/2+1=13,每组得到的输出为13x13x128。
卷积层(C3)
该层的处理流程是: 卷积-->ReLU
卷积:输入是13x13x256,使用384个3x3x256的卷积核进行卷积,padding=1,stride=1,根据公式:(input_size + 2 * padding - kernel_size) / stride + 1=(13+2*1-3)/1+1=13,得到输出是13x13x384。
ReLU:将卷积层输出的FeatureMap输入到ReLU函数中。将输出其分成两组,每组FeatureMap大小是13x13x192,分别位于单个GPU上。
卷积层(C4)
该层的处理流程是:卷积-->ReLU
卷积:两组输入均是13x13x192,各组分别使用192个3x3x192的卷积核进行卷积,padding=1,stride=1,根据公式:(input_size + 2 * padding - kernel_size) / stride + 1=(13+2*1-3)/1+1=13,得到每组FeatureMap输出是13x13x192。
ReLU:将卷积层输出的FeatureMap输入到ReLU函数中。
卷积层(C5)
该层的处理流程是:卷积-->ReLU-->池化
卷积:两组输入均是13x13x192,各组分别使用128个3x3x192的卷积核进行卷积,padding=1,stride=1,根据公式:(input_size + 2 * padding - kernel_size) / stride + 1=(13+2*1-3)/1+1=13,得到每组FeatureMap输出是13x13x128。
ReLU:将卷积层输出的FeatureMap输入到ReLU函数中。
池化:使用3x3,stride=2的池化单元进行最大池化操作(max pooling)。注意这里使用的是重叠池化,即stride小于池化单元的边长。根据公式:(13+2*0-3)/2+1=6,每组得到的输出为6x6x128。
全连接层(FC6)
该层的流程为:(卷积)全连接 -->ReLU -->Dropout (卷积)
全连接:输入为6×6×256,使用4096个6×6×256的卷积核进行卷积,由于卷积核尺寸与输入的尺寸完全相同,即卷积核中的每个系数只与输入尺寸的一个像素值相乘一一对应,根据公式:(input_size + 2 * padding - kernel_size) / stride + 1=(6+2*0-6)/1+1=1,得到输出是1x1x4096。既有4096个神经元,该层被称为全连接层。
ReLU:这4096个神经元的运算结果通过ReLU激活函数中。
Dropout:随机的断开全连接层某些神经元的连接,通过不激活某些神经元的方式防止过拟合。4096个神经元也被均分到两块GPU上进行运算。
全连接层(FC7)
该层的流程为:(卷积)全连接 -->ReLU -->Dropout
全连接:输入为4096个神经元,输出也是4096个神经元(作者设定的)。
ReLU:这4096个神经元的运算结果通过ReLU激活函数中。
Dropout:随机的断开全连接层某些神经元的连接,通过不激活某些神经元的方式防止过拟合。
4096个神经元也被均分到两块GPU上进行运算。
输出层(Output Layer)
该层的流程为:(卷积)全连接 -->Softmax
全连接:输入为4096个神经元,输出是1000个神经元。这1000个神经元即对应1000个检测类别。
Softmax:这1000个神经元的运算结果通过Softmax函数中,输出1000个类别对应的预测概率值。
AlexNet创新之处
Data Augmentation
在本文中,作者采用了两种数据增强(data augmentation)方法,分别是:
- 镜像反射和随机剪裁
- 改变训练样本RGB通道的强度值
镜像反射和随机剪裁的做法是,先对图像做镜像反射,然后在原图和镜像反射的图(256×256)中随机裁剪227×227的区域。
改变训练样本RGB通道的强度值,做法是对RGB空间做PCA(主成分分析),然后对主成分做一个(0, 0.1)的高斯扰动,也就是对颜色、光照作变换,结果使错误率又下降了1%。
激活函数ReLU

反向传播中,ReLU有输出的部分,导数始终为1。而且ReLU会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
局部响应归一化
局部响应归一化(LRN)对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
Dropout
dropout是神经网络中比较常用的抑制过拟合的方法。在神经网络中Dropout通过修改神经网络本身结构来实现,对于某一层的神经元,通过定义的概率将神经元置为0,这个神经元就不参与前向和后向传播,就如同在网络中被删除了一样,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新。在下一次迭代中,又重新随机删除一些神经元(置为0),直至训练结束。
在AlexNet网络中,全连接层FC6、FC7就使用了Dropout方法。
Dropout也可以看成是一种模型组合,每次生成的网络结构都不一样,通过组合多个模型的方式能够有效地减少过拟合,Dropout只需要两倍的训练时间即可实现模型组合(类似取平均)的效果,非常高效。
重叠池化
在以前的CNN中普遍使用平均池化层(average pooling),AlexNet全部使用最大池化层 max pooling。避免了平均池化层的模糊化的效果,并且步长比池化的核的尺寸小,这样池化层的输出之间有重叠,提升了特征的丰富性。重叠池化可以避免过拟合,这个策略贡献了0.3%的Top-5错误率。
双GPU训练
双GPU网络的训练时间比单GPU网络更少。
端到端训练
AlexNet网络,CNN的输入直接是一张图片,而当时比较多的做法是先使用特征提取算法对RGB图片进行特征提取。AlexNet使用了端对端网络,除了将每个像素中减去训练集的像素均值之外,没有以任何其他方式对图像进行预处理,直接使用像素的RGB值训练网络。
模型代码
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
# 特征提取层(卷积层)
self.features = nn.Sequential(
# Conv1
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2),# 输入通道数 输出通道数[3, 244, 244]->[48, 55, 55]
nn.ReLU(inplace=True), #inplace=True:对上一层Conv2d中传递下来的tensor直接进行修改,不用多存储一份变量
nn.MaxPool2d(kernel_size=3, stride=2), # [48, 27, 27]
# Conv2
nn.Conv2d(48, 128, kernel_size=5, stride=1, padding=2),# [128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),# [128, 13, 13]
# Conv3
nn.Conv2d(128, 192, kernel_size=3, stride=1, padding=1),# [192, 13, 13]
nn.ReLU(inplace=True),
# Conv4
nn.Conv2d(192, 192, kernel_size=3, stride=1, padding=1),# [192, 13, 13]
nn.ReLU(inplace=True),
# Conv5
nn.Conv2d(192, 128, kernel_size=3, stride=1, padding=1),# [128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)# [128, 6, 6]
)
# 全连接层
self.classifier = nn.Sequential(
# FC_1
nn.Dropout(p=0.5),
nn.Linear(128*6*6, 2048),# in_features[128, 6, 6], out_features[2048]
nn.ReLU(inplace=True),
# FC_2
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
# FC_3
nn.Linear(2048, num_classes)
)
if init_weights:
self._initialize_weights() #初始化权重
def forward(self, x):
x=self.features(x)
x=torch.flatten(x,start_dim=1) #进入FC前,flatten函数将向量拉平
x=self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
if __name__ == "__main__":
model = AlexNet()
print(model)训练集
下载数据集:https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
数据集包含:玫瑰、雏菊、向日葵、郁金香、蒲公英5类。
数据划分
对数据集中的train进行了划分,按照9:1的比例划分为train和valid
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向你解压后的flower_photos文件夹
cwd = os.getcwd()
data_root = os.path.join(cwd, "flower_data")
origin_flower_path = os.path.join(data_root, "flower_photos")
assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 建立保存训练集的文件夹
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 建立保存验证集的文件夹
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()训练
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from model import AlexNet
import os
import json
import time
# 选择训练硬件
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("训练方式为:",device)
# 定义训练集和测试集的数据转换方式
preprocess = { # dict, "key":"value"
"train": transforms.Compose([
transforms.RandomResizedCrop((224, 224)),# 使用224*244的窗口随机裁剪
transforms.RandomHorizontalFlip(),# 水平翻转
transforms.ToTensor(),# PIL Image转Tensor,自动[0, 255]归一化到[0, 1]
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))# 对数据进行归一化 参数1为mean 参数2为std
# 图片为3通道所以mean和std也是3通道的
]),
"valid": transforms.Compose([
transforms.Resize((224,244)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))# 标准化,即减均值,除以标准差
])
}
# 返回表示当前工作目录的 unicode 字符串
data_root = os.getcwd()
img_path = data_root + "/flower_data/"
# 定义训练、验证集路径和预处理方式
train_dataset = datasets.ImageFolder(root=img_path + "train", transform=preprocess["train"])
valid_dataset = datasets.ImageFolder(root=img_path + "valid", transform=preprocess["valid"])
train_num = len(train_dataset)
valid_num = len(valid_dataset)
# 定义class类别标签的list
classes_dict = train_dataset.class_to_idx
# 将上面的字典中key和value翻转
cls_dict = dict((val,key) for key, val in classes_dict.items())
# 将cls_dict这个字典写进json文件中
json_str = json.dumps(cls_dict, indent=4) # 将字典转化为字符串
# 将json_str这个变量写入硬盘,名称为:class_indices.json
with open('class_indices.json','w') as json_file:
json_file.write(json_str)
batch_size = 32
# 加载数据集、验证集 train_loader是可迭代对象
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# print(iter(train_loader).next()) 打印第一个batch(batch_size张图片的数据,末尾是batch_size张图片的标签)
valid_loader = DataLoader(dataset=valid_dataset, batch_size=batch_size, shuffle=True)
# 查看预处理后验证集图片
# test_data_iter = iter(valid_loader)
# test_img, test_label = test_data_iter.next()# test_img中含有batch_size个图片(经过预处理后的图片),test_label中含有batch_size个标签
# print(test_img, test_label)
# 取出第0张图片,进行属性的查看和可视化
# print(test_img[0].size(), type(test_img[0])) # torch.Size([3, 224, 224]) <class 'torch.Tensor'>
# print(test_label[0], test_label[0].item(), type(test_label[0])) # tensor(4) 4 <class 'torch.Tensor'> —— Tensor格式可以通过.item()转化为numpy的格式
# 显示图片
def imshow(img):
img = img / 2 + 0.5 # 反归一化
npimg = img.numpy() # tensor转为numpy,才可正常显示
plt.imshow(np.transpose(npimg, (1, 2, 0))) # 因为图片的size()为[3, 224, 224],所以我们需要把它变为[224, 224, 3])
plt.show()
model = AlexNet(num_classes=5, init_weights=True)
model.to(device)
loss_function = nn.CrossEntropyLoss()
# optimizer = optim.SGD(params=model.parameters(), lr=8e-4, momentum=0.9, weight_decay=5e-4)
optimizer = optim.Adam(model.parameters(),lr=8e-4)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.8, patience=10, threshold=0.001)
save_path = "./[flower_data]AlexNet.pth"
num_epoch = 200
# 开始训练
best_acc = 0.0
lr_values = []
train_acc_values = []
train_loss_values = []
val_acc_values = []
val_loss_values = []
for epoch in range(num_epoch):
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
# train
model.train()
running_loss = 0.0
t1 = time.perf_counter()
for step, data in enumerate(train_loader, start=0):
imgs, labels = data
imgs = imgs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(imgs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
_, train_pred = torch.max(outputs, 1)
train_acc += (train_pred.detach() == labels.detach()).sum().item()
train_loss += loss.item()
train_acc_epoch = train_acc / len(train_dataset)
train_acc_values.append(train_acc_epoch)
train_loss_values.append(train_loss/len(train_loader))
lr_values.append(optimizer.param_groups[0]['lr'])
#valid
model.eval()
with torch.no_grad():
for val_data in valid_loader:
val_imgs, val_labels = val_data
val_imgs = val_imgs.to(device)
val_labels = val_labels.to(device)
outputs = model(val_imgs)
# print(outputs.size()) # torch.Size([32, 5])
loss = loss_function(outputs, val_labels)
_, val_pred = torch.max(outputs, 1)
val_acc += (val_pred.cpu() == val_labels.cpu()).sum().item()
val_loss += loss.item()
val_acc_epoch = val_acc / len(valid_dataset)
val_acc_values.append(val_acc_epoch)
val_loss_values.append(val_loss/len(valid_loader))
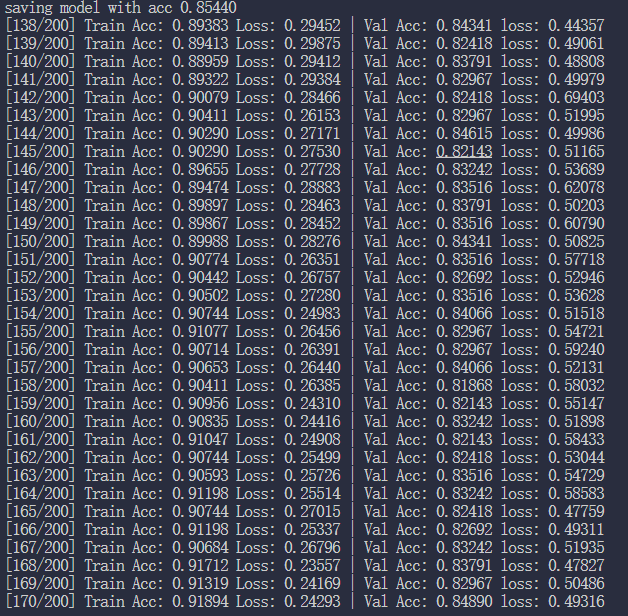
print(f'[{epoch+1:03d}/{num_epoch:03d}] Train Acc: {train_acc/len(train_dataset):3.5f} Loss: {train_loss/len(train_loader):3.5f} | Val Acc: {val_acc/len(valid_dataset):3.5f} loss: {val_loss/len(valid_loader):3.5f}')
# 保存不同epoch中验证集准确率最高的那个
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), save_path)
print(f'saving model with acc {best_acc/len(valid_dataset):.5f}')
scheduler.step(val_acc/len(valid_dataset))
print("Training Finished!")
# 查看梯度
for name, param in model.named_parameters():
if param.requires_grad and param.grad is not None:
print(name, param.grad.abs().mean().item())
plt.figure()
plt.plot(train_loss_values, label='Train Loss', color='blue')
plt.plot(val_loss_values, label='Validation Loss', color='orange')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
plt.figure()
plt.plot(train_acc_values, label='Train Accuracy', color='blue')
plt.plot(val_acc_values, label='Validation Accuracy', color='orange')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.show()
plt.figure()
plt.plot(lr_values, label='Learning Rate')
plt.xlabel('Epoch')
plt.ylabel('lr')
plt.title('Learning Rate')
plt.legend()
plt.show()结果与优化
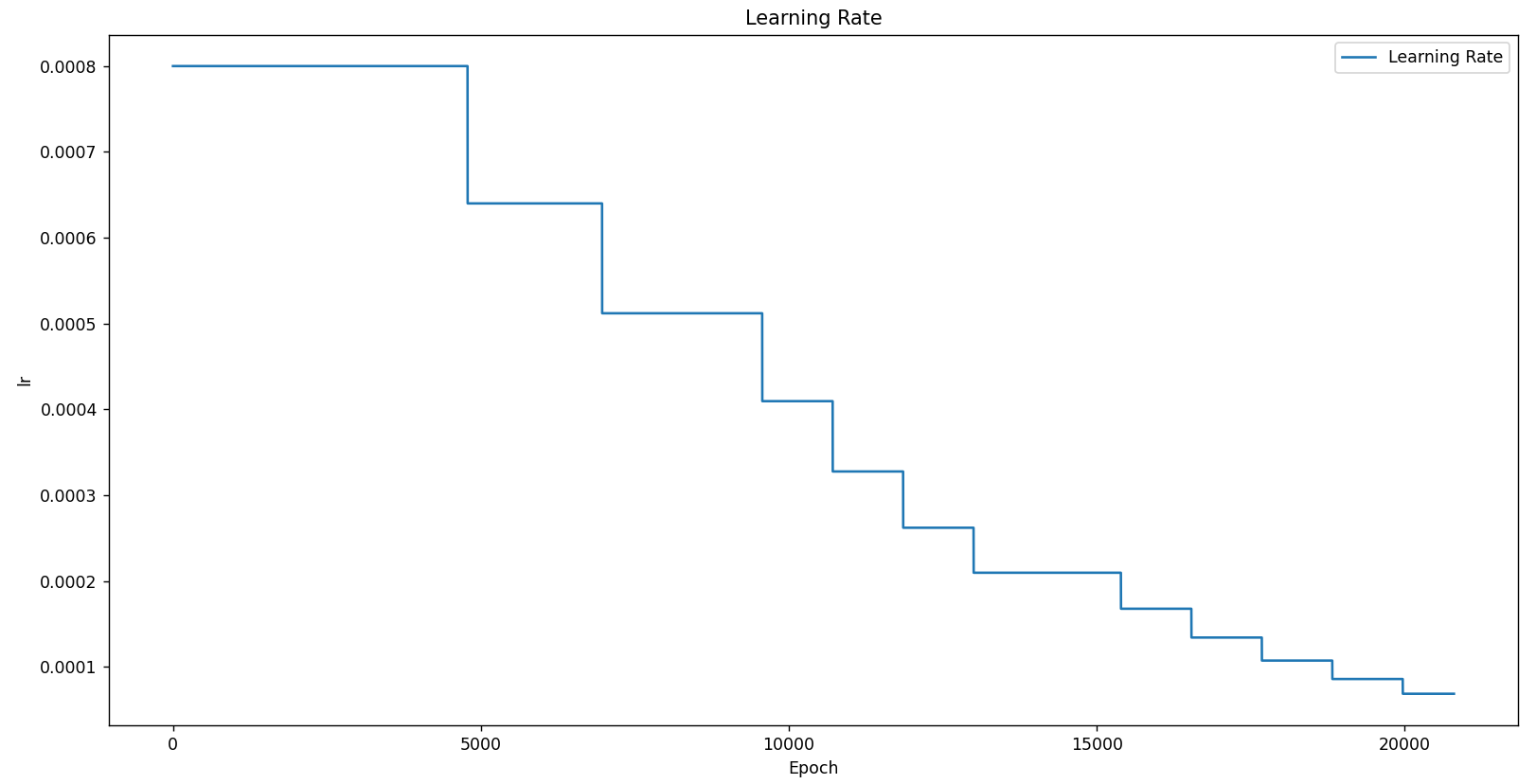
SGD(0.87363)
optimizer = optim.SGD(params=model.parameters(), lr=8e-4, momentum=0.9, weight_decay=5e-4)使用SGD lr=8e-4 epoch=200结果如下:



adam(0.83791)
optimizer = optim.Adam(model.parameters(), lr=8e-4)



SGD+ReduceLROnPlateau(0.86264)
optimizer = optim.SGD(params=model.parameters(), lr=8e-4, momentum=0.9, weight_decay=5e-4)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.9, patience=15, threshold=0.001)

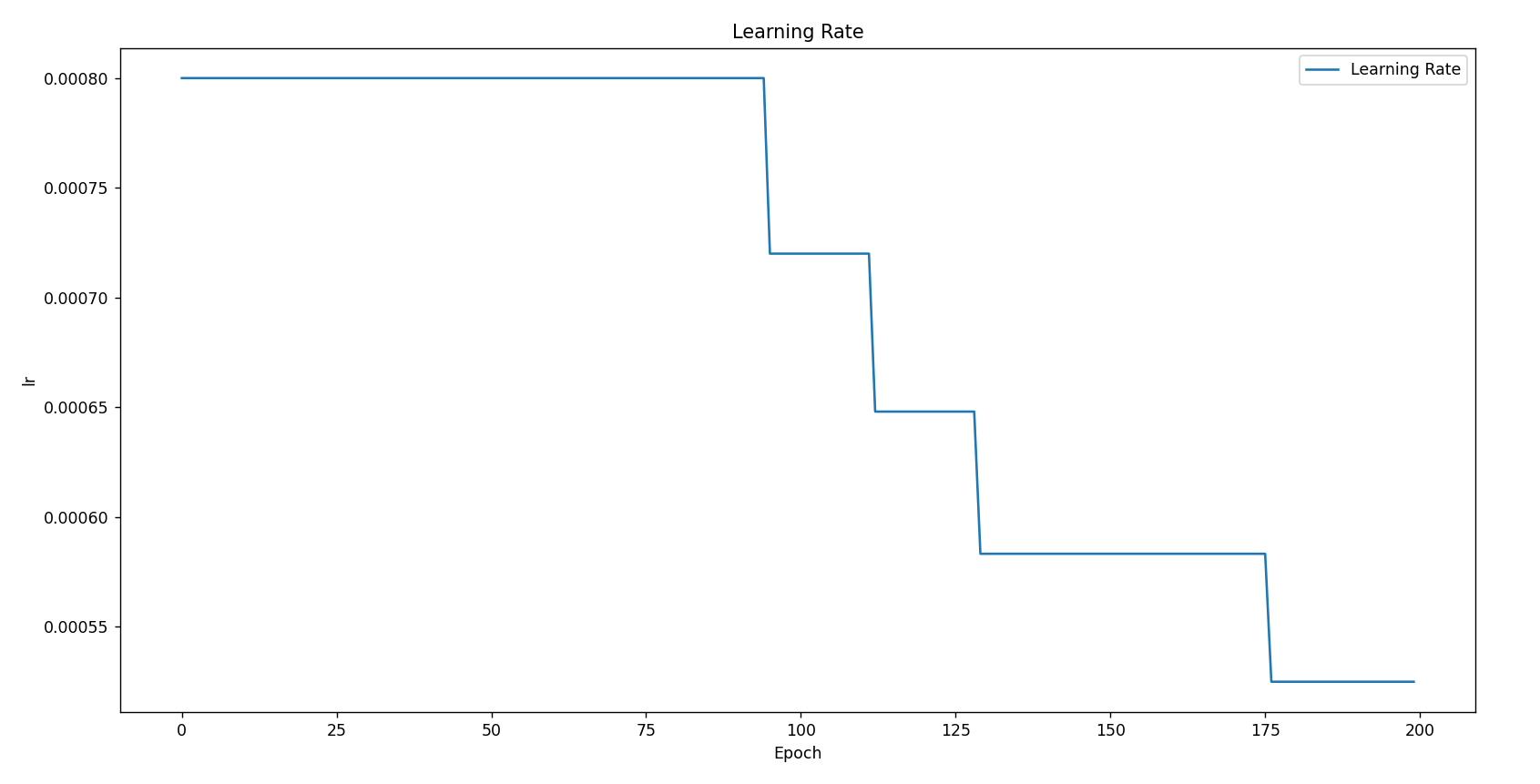


adam+ReduceLROnPlateau(0.85440)
optimizer = optim.Adam(model.parameters(),lr=8e-4)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.8, patience=10, threshold=0.001)

















 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









