







description: 总结Cache与DB的数据一致性相关内容。
缓存一致性的三个障碍
- 当对主数据库的更改未反映在缓存中时
- 更新缓存结果时出现延迟
- 当缓存节点之间不一致时
如何设计缓存更新模式?首先,提出我阅读相关文章时遇到的疑惑。
当我使用搜索引擎(百度 or Google)去搜索缓存与
数据库的数据一致性如何保证时,我会看到三种结果:
- 仅讲解先操作数据库 or 先操作缓存(最多)
- 讲解四种缓存更新策略模式
- 将上述两者结合起来(较少)
在分别阅读完一些前两者的文章后,我就一直在思考
- 四种缓存更新策略模式与操作顺序的关系是什么?(因为看到了类似“四种缓存更新策略广泛用于分布式系统和高性能应用中”,但是又有很多实践操作顺序的文章,比如先写数据库,再更新缓存的“延时双删”策略)
- 为什么很多文章推荐我们去阅读另一种呢?(eg:我看见了一些写操作顺序的文章推荐我去阅读缓存更新策略模式相关文章)
带着上面的两个问题,我去搜索,去尝试写出下面的博客,并在介绍两者后,总结出我对它们的理解。
缓存更新设计模式
1. Cache-Aside
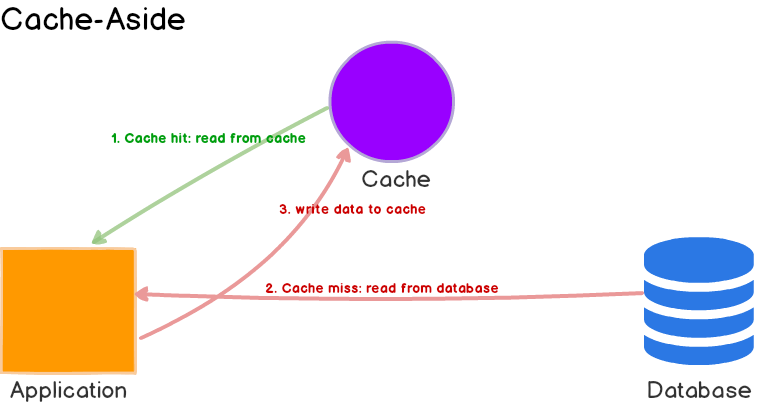
应用程序从缓存中读取数据
- 如果命中,直接返回
- 没有命中,改为从数据库读取,并写回缓存
ps:我在一些博客上会在这里加上写入的设计
- 有的博客说先把数据存到数据库,成功后,再让缓存失效
- 有的博客说仅仅将数据存到数据库(即后面提到的Write-Around)
- 还看见了变体,先淘汰缓存,再写数据库…
在看完这些博客之后,我的理解是:Cache-Aside更多的定义读请求的更新方案,它可以结合不同的写入策略,来保证数据一致性。依据是,在亚马逊的文档和微软的文档中,均只提到了它读请求的更新方案,并未提及必须要有固定的写入策略。
优点
- 使用最少的内存(至少在理论上),因为缓存的项目仅在需要时才获取(延迟加载)
- Memcached 和 Redis 被广泛使用。使用Cache-Aside的系统可以适应缓存故障。如果缓存集群宕机,系统仍然可以通过直接访问数据库来操作。 (尽管如此,如果缓存在峰值负载期间出现故障,也没有多大帮助。响应时间可能会变得很糟糕,在最坏的情况下,数据库可能会停止工作。)
缺点
- 缓存未命中时,延迟较高,因为需要从数据库获取数据。如果缓存未命中太多,会影响系统性能(缓存穿透?)。
- 当使用cache-aside时,写入策略之一是直接将数据写入数据库(Write-Around)。发生这种情况时,缓存可能会与数据库变得不一致。为了解决这个问题,开发人员通常使用生存时间 (TTL) 并继续提供过时的数据,直到 TTL 过期。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6199
6199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









