










前言
在前面的Mall项目脚手架整合中涉及到的Elasticsearch的内容仅仅只是在表面给出了一个在SpringBoot中的使用示例,但其实对于Elasticsearch的一些基础概念和底层的原理并没有过多的涉及,这种学习方式是浮躁的,所以这篇文章荔枝会对其中欠缺的基础知识进行梳理补充,希望还没接触Elasticsearch的小伙伴可以先看看荔枝的这篇文章分享!
文章目录
三、SpringBoot项目中使用Elasticsearch来搜索聚合
一、为何Elasticsearch搜得快?倒排索引!
在正式学习Elasticsearch的搜索功能之前,我们需要对Elasticsearch有个大致的了解:Elasticsearch是一个开源的、高扩展的、分布式的、提供多用户能力的全文搜索引擎,同时也是一个基于 Lucene 搜索的服务器,能够近乎实时地存储和搜索数据。也就是说,它足够快!!!至少,在数据搜索上比传统的关系型数据库快。这是由Elasticsearch底层的数据结构来决定的,Elasticsearch的底层数据结构是倒排索引。
性能体现:
- Elasticsearch的数据会存入磁盘中,在向Elasticsearch中写入数据默认分词,生成倒排索引并存在内存中,相比于MySQL少了许多IO操作;
- 利用位图Bitmap来优化多字段的查询,而不是采用遍历,提升查询速度;
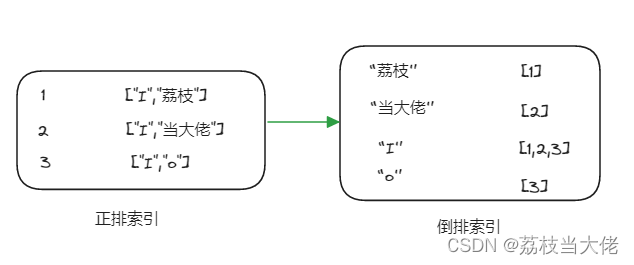
正排索引和倒排索引
正排索引就是我们日常说的那种索引比如:index=1对应的词是 [ “你好” ] ;那么倒排索引就是index=“你好”对应索引[1],更直观的区分大家可以看一下荔枝画的图。
Elasticsearch的索引结构和MySQL引擎的底层数据结构性能对比可以参见大佬的文章:https://zhuanlan.zhihu.com/p/266116262
二、必备知识
前面已经对Elasticsearch有了一定了解,下面还需要明确几个概念。
2.1 基本概念
- Near Realtime(近实时):Elasticsearch是一个近乎实时的搜索平台,这意味着从索引文档到可搜索文档之间只有一个轻微的延迟(通常是一秒钟)。
- Cluster(集群):群集是一个或多个节点的集合,它们一起保存整个数据,并提供跨所有节点的联合索引和搜索功能。每个集群都有自己的唯一集群名称,节点通过名称加入集群。
- Node(节点):节点是指属于集群的单个Elasticsearch实例,存储数据并参与集群的索引和搜索功能。可以将节点配置为按集群名称加入特定集群,默认情况下,每个节点都设置为加入一个名为Elasticsearch的群集。
- Index(索引):索引是一些具有相似特征的文档集合,类似于MySql中数据库的概念。
- Type(类型):类型是索引的逻辑类别分区,通常,为具有一组公共字段的文档类型,类似MySql中表的概念。
注意:在Elasticsearch 6.0.0及更高的版本中,一个索引只能包含一个类型。 - Document(文档):文档是可被索引的基本信息单位,以JSON形式表示,类似于MySql中行记录的概念。
- Shards(分片):当索引存储大量数据时,可能会超出单个节点的硬件限制,为了解决这个问题,Elasticsearch提供了将索引细分为分片的概念。分片机制赋予了索引水平扩容的能力、并允许跨分片分发和并行化操作,从而提高性能和吞吐量。
- Replicas(副本):在可能出现故障的网络环境中,需要有一个故障切换机制,Elasticsearch提供了将索引的分片复制为一个或多个副本的功能,副本在某些节点失效的情况下提供高可用性。
分片Shards
有关索引的分片这里可以类比于MySQL的分库,大家可能对于分片之间调度比较感兴趣。在Elasticsearch中,一个索引可以被分割成多个shard,每个shard实际上是一个自包含的索引,可以独立存在于Elasticsearch集群中的任何一个节点上。这种分片的设计是为了满足分布式系统的需求,使得数据的存储和查询可以在多个节点上进行分布式处理,从而提高系统的扩展性和性能。
搜索数据在分片上的调度
Elasticsearch内部使用了一种叫做路由的机制来确定搜索的数据在哪个分片上。当文档被索引到Elasticsearch中时,会根据一种算法计算出一个路由值,这个值决定了文档应该存储在哪个分片上。同样的,当用户发起搜索请求时,Elasticsearch会根据同样的路由算法来确定搜索请求应该被发送到哪个分片上。这个路由算法会考虑到分片的数量以及文档的路由值,以确保数据在分片之间的均匀分布。这意味着,Elasticsearch能够自动管理和调度数据在不同的分片之间,从而实现了数据的分布式存储和查询。
2.2 Elasticsearch Query DSL
Elasticsearch提供了基于JSON的完整查询DSL(特定于域的语言)来定义查询。使用ElasticSearch的时候,避免不了使用DSL语句去查询,就像使用关系型数据库的时候要学会SQL语法一样,下面先来看看基础的操作:
2.2.1 基础CRUD
集群操作
//集群状态查看
GET /_cat/health?v
//节点状态查看
GET /_cat/nodes?v索引操作
//查看所有索引信息
GET /_cat/indices?v
//创建索引
PUT /lzddl
//删除索引
DELETE /lzddl文档操作
//查看文档字段类型
GET /lzddl/_mapping
//在索引中添加文档
PUT /lzddl/doc/1
{
"name": "lzddl great"
}
//查看索引中的文档
GET /lzddl/doc/1
//修改索引中的文档
POST /lzddl/doc/1/_update
{
"doc": { "name": "Jane Doe" }
}
//删除索引中的文档
DELETE /lzddl/doc/12.2 重点:搜索操作
重点理解这一部分的DSL语句十分重要,这关系到我们能否在下项目中自定义一些复杂的搜索,毕竟衍生查询提供的方法体的功能确实比较单一了。
match_all:搜索全部数据
这里的query后跟着的是查询条件、from和size其实是分页参数
GET /lzddl/_search
{
"query": { "match_all": {} },
"from": 0,
"size": 10
}sort:搜索排序
GET /lzddl/_search
{
"query": { "match_all": {} },
"sort": { "balance": { "order": "desc" } }
}_source
搜索并返回指定字段的内容,比如这里仅返回A和B字段
GET /lzddl/_search
{
"query": { "match_all": {} },
"_source": ["A", "B"]
}条件搜索
使用match表示匹配条件,例如搜索出A为1的文档:
GET /lzddl/_search
{
"query": {
"match": {
"A": 1
}
}
}需要注意的是:对于数值类型
match操作使用的是精确匹配,对于文本类型使用的是模糊匹配!
match_phrase:短语匹配搜索
GET /bank/_search
{
"query": {
"match_phrase": {
"address": "my house"
}
}
}组合搜索
这里在query中使用了布尔查询的方式来表示满足条件的情况,下面是几种条件满足的逻辑:
must:同时满足
must_not:同时不满足
should:表示满足其中任意一个
GET /lzddl/_search
{
"query": {
"bool": {
"must": [
{ "match": { "address": "A" } },
{ "match": { "address": "B" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}
过滤搜索
搜索过滤,使用filter来表示,例如过滤出balance字段在20000 — 30000的文档;
GET /lzddl/_search
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}搜索聚合
对搜索结果进行聚合,使用aggs来表示,类似于MySql中的group by,例如对state字段进行聚合,统计出相同state的文档数量;
GET /lzddl/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}嵌套聚合
对state字段进行聚合,统计出相同state的文档数量,再统计出balance的平均值,最后按按balance的平均值降序排列。
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": {
"average_balance": "desc"
}
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}三、SpringBoot项目中使用Elasticsearch来搜索聚合
在SpringBoot中操作Elasticsearch往往的是Spring Data JPA中提供的工具类,在荔枝上一篇有关Elasticsearch的文章中:有提及相关的操作类ElasticsearchRepository,通过继承该类我们可以获得CrudRepository中的数据操作方法,也可以在继承类中通过衍生查询的方式来定义一些简单的CRUD方法。但是对于像过滤搜索、搜索聚合等方式还是需要Elasticsearch提供的核心包中的操作类比如:NativeSearchQueryBuilder、QueryBuilders等,具体的功能荔枝觉得还是直接来看几个场景下的代码就能很好的理解了。
荔枝文章:https://blog.csdn.net/qq_62706049/article/details/133717184
为了更好的理解,荔枝觉得有必要将对应的Elasticsearch Query DSL语句和代码进行对比来学习。
3.1 综合搜索
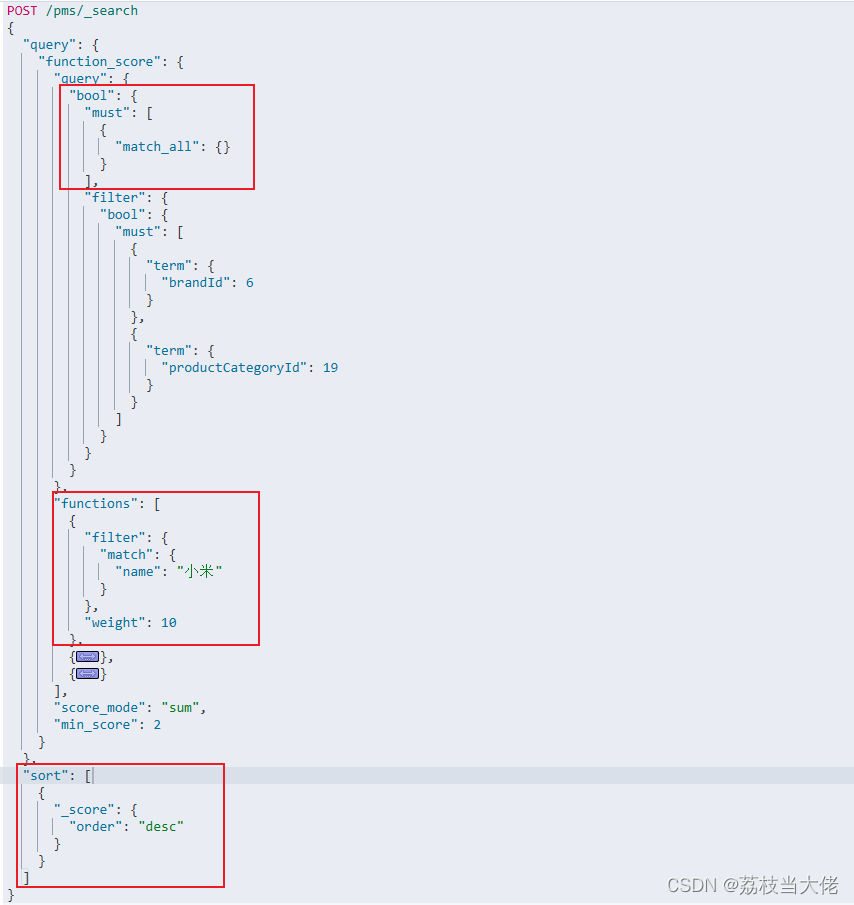
POST /pms/_search
{
"query": {
"function_score": {
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": {
"bool": {
"must": [
{
"term": {
"brandId": 6
}
},
{
"term": {
"productCategoryId": 19
}
}
]
}
}
}
},
"functions": [
{
"filter": {
"match": {
"name": "小米"
}
},
"weight": 10
},
{
"filter": {
"match": {
"subTitle": "小米"
}
},
"weight": 5
},
{
"filter": {
"match": {
"keywords": "小米"
}
},
"weight": 2
}
],
"score_mode": "sum",
"min_score": 2
}
},
"sort": [
{
"_score": {
"order": "desc"
}
}
]
} 有点长,借助Kibana来看看DSL结构:
实现类中的对应方法:
@Override
public Page<EsProduct> search(String keyword, Long brandId, Long productCategoryId, Integer pageNum, Integer pageSize,Integer sort) {
Pageable pageable = PageRequest.of(pageNum, pageSize);
//该类会构造Query DSL语句
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
//分页
nativeSearchQueryBuilder.withPageable(pageable);
//过滤,在nativeSearchQueryBuilder前加一个过滤器,只有满足了布尔查询的文档才会被返回
if (brandId != null || productCategoryId != null) {
//布尔查询,允许组合多个子查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if (brandId != null) {
boolQueryBuilder.must(QueryBuilders.termQuery("brandId", brandId));
}
if (productCategoryId != null) {
boolQueryBuilder.must(QueryBuilders.termQuery("productCategoryId", productCategoryId));
}
nativeSearchQueryBuilder.withFilter(boolQueryBuilder);
}
//搜索
if (StrUtil.isEmpty(keyword)) {
nativeSearchQueryBuilder.withQuery(QueryBuilders.matchAllQuery());
} else {
List<FunctionScoreQueryBuilder.FilterFunctionBuilder> filterFunctionBuilders = new ArrayList<>();
filterFunctionBuilders.add(new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.matchQuery("name", keyword),
ScoreFunctionBuilders.weightFactorFunction(10)));
filterFunctionBuilders.add(new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.matchQuery("subTitle", keyword),
ScoreFunctionBuilders.weightFactorFunction(5)));
filterFunctionBuilders.add(new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.matchQuery("keywords", keyword),
ScoreFunctionBuilders.weightFactorFunction(2)));
FunctionScoreQueryBuilder.FilterFunctionBuilder[] builders = new FunctionScoreQueryBuilder.FilterFunctionBuilder[filterFunctionBuilders.size()];
filterFunctionBuilders.toArray(builders);
FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(builders)
.scoreMode(FunctionScoreQuery.ScoreMode.SUM)
.setMinScore(2);
nativeSearchQueryBuilder.withQuery(functionScoreQueryBuilder);
}
//排序
if(sort==1){
//按新品从新到旧
nativeSearchQueryBuilder.withSorts(SortBuilders.fieldSort("id").order(SortOrder.DESC));
}else if(sort==2){
//按销量从高到低
nativeSearchQueryBuilder.withSorts(SortBuilders.fieldSort("sale").order(SortOrder.DESC));
}else if(sort==3){
//按价格从低到高
nativeSearchQueryBuilder.withSorts(SortBuilders.fieldSort("price").order(SortOrder.ASC));
}else if(sort==4){
//按价格从高到低
nativeSearchQueryBuilder.withSorts(SortBuilders.fieldSort("price").order(SortOrder.DESC));
}else{
//按相关度
nativeSearchQueryBuilder.withSorts(SortBuilders.scoreSort().order(SortOrder.DESC));
}
nativeSearchQueryBuilder.withSorts(SortBuilders.scoreSort().order(SortOrder.DESC));
NativeSearchQuery searchQuery = nativeSearchQueryBuilder.build();
LOGGER.info("DSL:{}", searchQuery.getQuery().toString());
SearchHits<EsProduct> searchHits = elasticsearchRestTemplate.search(searchQuery, EsProduct.class);
if(searchHits.getTotalHits()<=0){
return new PageImpl<>(ListUtil.empty(),pageable,0);
}
//这里的getContent其实就是将searchHits里面的每一个数据转换成EsProduct对象
List<EsProduct> searchProductList = searchHits.stream().map(SearchHit::getContent).collect(Collectors.toList());
return new PageImpl<>(searchProductList,pageable,searchHits.getTotalHits());
}从上面的代码结构和图对比着来看,其实还是比较简单的,大致的框架流程是这样的:
- 首先我们需要创建一个可以构造DSL的构造器对象
//该类会构造Query DSL语句
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();- 因为DSL中有bool查询,所以我们需要通过为构造器对象的withFilter()方法添加过滤器
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();- 搜索的function拼接和分数的计算
FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(builders)
.scoreMode(FunctionScoreQuery.ScoreMode.SUM)
.setMinScore(2);
nativeSearchQueryBuilder.withQuery(functionScoreQueryBuilder);- 排序的设置
nativeSearchQueryBuilder.withSorts(SortBuilders.scoreSort().order(SortOrder.DESC));- 调用build方法生成查询语句并通过ElasticsearchRestTemplate.search()方法来搜索
NativeSearchQuery searchQuery = nativeSearchQueryBuilder.build();对照着来看总算是看懂了哈哈!接下来上难度看看搜索聚合的操作是怎样的。
3.2 搜索聚合
搜索聚合指的是根据关键字搜索聚合出该关键字商品的分类和品牌信息,首先我们还是得来看DSL语句:

再来看看Java代码:
@Override
public EsProductRelatedInfo searchRelatedInfo(String keyword) {
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
//搜索条件
if(StrUtil.isEmpty(keyword)){
builder.withQuery(QueryBuilders.matchAllQuery());
}else{
builder.withQuery(QueryBuilders.multiMatchQuery(keyword,"name","subTitle","keywords"));
}
//聚合搜索品牌名称
builder.withAggregations(AggregationBuilders.terms("brandNames").field("brandName"));
//聚合搜索分类名称
builder.withAggregations(AggregationBuilders.terms("productCategoryNames").field("productCategoryName"));
//聚合搜索商品属性,去除type=0的属性
AbstractAggregationBuilder aggregationBuilder = AggregationBuilders.nested("allAttrValues","attrValueList")
.subAggregation(AggregationBuilders.filter("productAttrs",QueryBuilders.termQuery("attrValueList.type",1))
.subAggregation(AggregationBuilders.terms("attrIds")
.field("attrValueList.productAttributeId")
.subAggregation(AggregationBuilders.terms("attrValues")
.field("attrValueList.value"))
.subAggregation(AggregationBuilders.terms("attrNames")
.field("attrValueList.name"))));
builder.withAggregations(aggregationBuilder);
NativeSearchQuery searchQuery = builder.build();
SearchHits<EsProduct> searchHits = elasticsearchRestTemplate.search(searchQuery, EsProduct.class);
return convertProductRelatedInfo(searchHits);
}其实DSL语句相较于3.1而言知识多了“aggs”部分子查询的内容,因此在搜索聚合的时候需要调用NativeSearchQueryBuilder类对象的withAggregations方法添加子查询!
总结
技术的操作学习起来其实不难,难的是底层的知识的理解,这是重要的!也是大厂看重的!这也是荔枝接下来一段时间要去努力做的,希望能在未来收获不一样的自己!
今朝已然成为过去,明日依然向往未来!我是荔枝,在技术成长之路上与您相伴~~~
如果博文对您有帮助的话,可以给荔枝一键三连嘿,您的支持和鼓励是荔枝最大的动力!
如果博文内容有误,也欢迎各位大佬在下方评论区批评指正!!!















 23万+
23万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









