







 该博客介绍了南京市历史天气情况统计分析平台的建设,包括天气数据处理,通过折线图展示气温变化;词云制作,使用Jieba分词技术并去除停用词;以及系统功能模块展示,利用Python的tkinter库实现GUI界面,提供多种天气查询和统计功能。
该博客介绍了南京市历史天气情况统计分析平台的建设,包括天气数据处理,通过折线图展示气温变化;词云制作,使用Jieba分词技术并去除停用词;以及系统功能模块展示,利用Python的tkinter库实现GUI界面,提供多种天气查询和统计功能。
资源链接:
【免费】南京市历史天气情况统计分析平台建设资源-CSDN文库
1 天气数据处理
完成气温数据的获取工作后,下一步便是将字符串中的温度转化为数字进行比较,进而得到气温变化示例。
我们对气温数据进行筛选,为了更直观的展现历年高温和低温天气,折线图用于绘制全面的最高气温和最低气温变化,红色折线代表最高温,蓝色折线代表最低温,由于全年的天气数据过多,因此在折线图的横轴只显示以月份的格式显示。
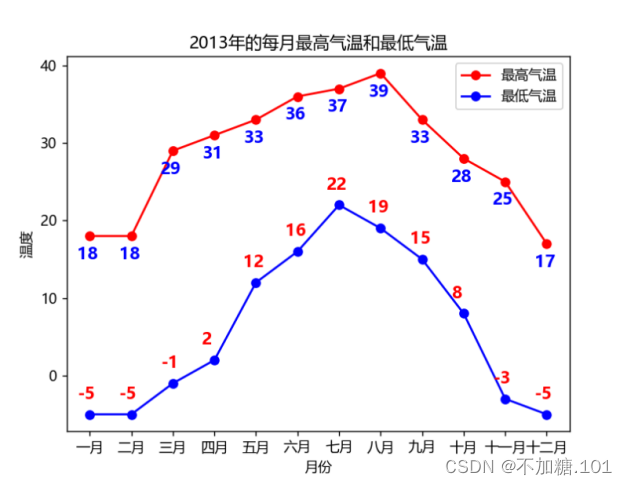
图1 历年各个月份最高最低气温统计示例
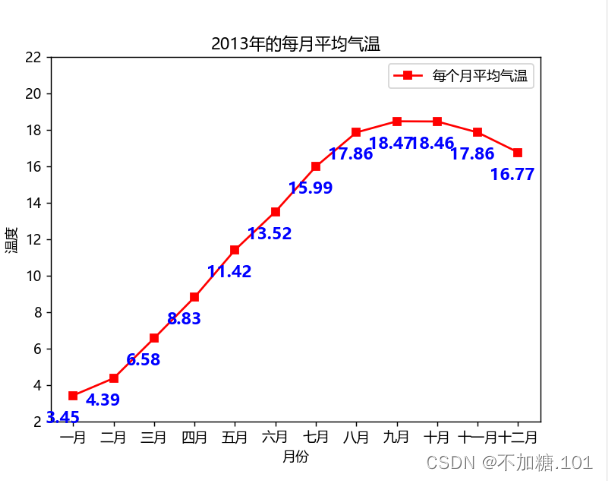
图2 历年平均气温统计示例
2 词云制作
每年关于天气的数据很多,本章阐述的内容是南京市天气的关键词的词云的制作,词云图用于描述南京市天气。
2.1 词云制作和优化
完成词云制作需要解决的问题有对文本中文分词、停用词的去除。下面分别对这两个问题进行分析。
中文分词是制作词云最重要的一部分,我们需要将一个个词语从句子中分离开,本文采用Jieba分词技术,对气象数据进行分词。Jieba库的分词原理:利用一个中文词库,确定汉字之间的关联概率,汉字间概率大的组成词组,形成分词结果。Jieba有三种分词模式:全模式、搜索引擎模式和精确模式,其中精确模式将句子最精确地切开,获得的分词不存在冗余,并且相对于其他两种模式,得到的分词是最接近原文表述的,因此我们选择精确模式来进行中文分词。
具体代码如下:
| def branchword(self): idata = pd.read_excel(self._path) idata['过滤非中文字符'] = idata[self._colnames].astype(str).apply(lambda x: ''.join(x), axis=1).map( lambda x: re.sub('[^\u4e00-\u9fff |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









