






Collection:

Collection 不唯一,无序
List 不唯一,有序
Set 唯一,无序
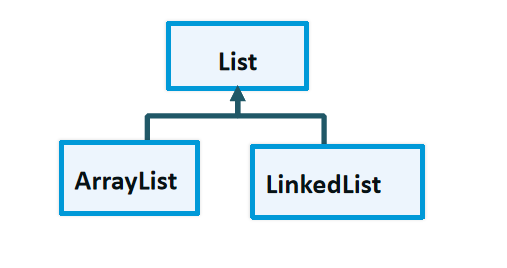
ArrayList:内部使用长度可变的数组,遍历查询效率高
LinkedList:采用双向链表实现,增删改效率比较高
ArrayList:
常用方法:

ArrayList方法实例:
public static void main(String[] args) {
List list = new ArrayList();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("马六");
System.out.println("大小为"+list.size());
//指定位置插入,后面的会往后走
list.add(3,"陈梦雨");
System.out.println(list);
//循环打印集合信息
for(Object obj:list){
System.out.println("循环打印"+obj);
}
//根据下标获取集合中的元素
Object aa = list.get(1);
System.out.println(aa);
String bb = (String) list.get(2);
System.out.println(bb);
System.out.println("第三个"+list.get(3));
//查找集合中是否存在指定元素
boolean ccc = list.contains("马六");
System.out.println(ccc);
//根据下标删除
list.remove(2);
//根据元素删除,删除后,后面的会自动补过来
list.remove("张三");
//清空所有内容
list.clear();
System.out.println("清空后集合长度:"+list.size());
//判断是否为空
System.out.println("判断集合是否为空:"+list.isEmpty());
}LinkedList类:
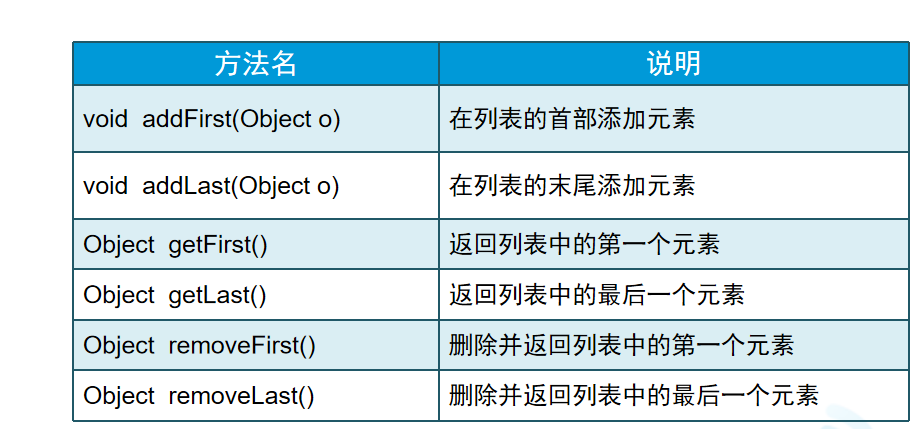
LinkedList:采用双向链表实现,增删改效率比较高

常用方法:
链表本身不具备下标功能,但 LinkedList 类提供了下标访问方法以便于与 List 接口兼容。 所以LinkedList可以使用get()方法用来获取特定值。
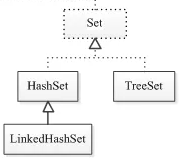
Set接口:
Set接口存储一组唯一,无序的对象
Set接口不存在get()方法,因为没有下标
set接口下有两个实现类分别是HashSet和TreeSet
HashSet:
- 底层结构:基于哈希表(
HashMap),不保持元素的顺序。 - 性能:提供常数时间复杂度的
add,remove, 和contains操作,适用于快速访问。 - 特点:不保证元素的顺序,元素顺序可能会改变。对于需要不重复元素且对顺序无关的情况,
HashSet非常合适。
TreeSet:
- 底层结构:基于红黑树(自平衡的二叉搜索树),保持元素的排序。
- 性能:提供对
add,remove, 和contains操作的对数时间复杂度,适用于需要排序或范围查询的场景。 - 特点:自动对元素进行排序(自然顺序或通过提供的
Comparator),使得可以遍历元素时按升序排列。
迭代器Iterator:
通过迭代器Iterator实现遍历
1.通过Set接口创建迭代器
2. hasNext(): 判断是否存在另一个可访问的元素
3.next(): 返回要访问的下一个元素
Set<String> set = new HashSet<>();
set.add("A");
set.add("B");
set.add("C");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}方法2:增强型for循环
Set<String> set = new HashSet<>();
set.add("A");
set.add("B");
set.add("C");
for (String item : set) {
System.out.println(item);
}Set接口如何判断加入对象是否已经存在呢?
采用对象的equals()方法比较两个对象是否相等,因为存放的是对象引用(地址
HashSet是Set接口常用的实现类
Set newsTitleSet = new HashSet();Map:
Map接口专门处理键值映射数据的存储,可以根据键实现对值的操作
最常用的实现类是HashMap
Map集合中的键具有唯一性,当向集合中添加已存在的键值元素时,会覆盖之前已存在的键值元素
Map接口常用方法:
put() 方法。如果键存在则覆盖值。如果键不存在,它会插入一个新的键值对。

Map<String, String> map = new HashMap<>();
//增加集合元素
map.put("CN","中华人民共和国");
map.put("US","美利坚合众国");
map.put("RU","俄罗斯联邦");
map.put("SB","日本");
//通过key获取对应的值
System.out.println("CN对应的国家是:"+map.get("CN"));
//获取集合大小
System.out.println("Map中共有"+map.size()+"组数据");
//判断是否存在这个key
System.out.println("Map中包含FR的key吗?"+map.containsKey("FR"));
//打印map
System.out.println("Map集合打印"+map);
// 删除指定键对象映射的键值对元素
map.remove("SB");
//再增加一遍相同的键,值会覆盖
map.put("SB","日本");
//返回键的集合
Set Allkeys = map.keySet();
//返回值的集合
Set Allvalues = map.values();
//通过Set来获得迭代器
//先把所有的key都放进Set集合中
Set keys = map.keySet();
Iterator it = keys.iterator();
while(it.hasNext()){
Object next = it.next();
System.out.println(next+"对应的值是"+map.get(next));
}
//清空Map中的数据
map.clear();
}
}Map的遍历:
HashMap本身没有实现Iterable接口,因此不能直接通过iterator()方法进行迭代。keySet()、values()或entrySet(),这些集合实现了Iterable接口,因此可以获取相应的Iterator进行迭代。- 因为Map有键和值,所以不能用for增强循环,
- 在没定义泛型之前,map中的对象都可以放Object类型
方法1:通过迭代器Iterator实现遍历
//通过Set来获得迭代器
//先把所有的key都放进Set集合中
Set keys = map.keySet();
Iterator it = keys.iterator();
while(it.hasNext()){
Object next = it.next();
System.out.println(next+"对应的值是"+map.get(next));
}方法2:增强型for循环
因为map集合中有键和值,所以不能用for增强循环遍历
for (Object obj:map){
}Iterator接口:
Iterator接口是Java集合框架中的一员,但它与Collection、Map接口有所不同,Collection接口与Map接口主要用于存储元素,而Iterator主要用于迭代访问(即遍历)Collection中的元素,因此Iterator对象也被称为迭代器。
专门实现集合的遍历的,可以用于List和Set集合,不能用于HashMap
主要的两个方法:
| hasNext() | 判断是否存在下一个可访问的元素,是则返回true |
| next() | 返回要访问的下一个元素 |
使用Iterator遍历Arraylist集合:
首先通过调用ArrayList集合的iterator()方法获得迭代器对象,然后使用hashNext()方法判断集合中是否存在下一个元素,如果存在,则调用next()方法将元素取出,否则说明已到达了集合末尾,停止遍历元素。
ArrayList list = new ArrayList();
list.add("张三");
list.add("李四");
list.add("王五");
Iterator it= list.iterator();
while (it.hasNext()){
String name = (String) it.next();//这个是Object类,要转为String类
System.out.println(name);
}
}
在调用Iterator的next()方法之前,迭代器的索引位于第一个元素之前,不指向任何元素,当第一次调用迭代器的next()方法后,迭代器的索引会向后移动一位,指向第一个元素并将该元素返回,当再次调用next()方法时,迭代器的索引会指向第二个元素并将该元素返回,以此类推,直到hasNext()方法返回false,表示到达了集合的末尾终止对元素的遍历。
remove方法:
list.remove();直接这样就可以,不需要在remove中再添加其他的
while (it.hasNext()){
String aa=it.next();
if (!sets.add(aa)){
//添加失败
list.remove();
}
}在 LinkedList 的 Iterator 中调用 remove() 方法时,不需要传递要删除的元素,因为 Iterator 已经持有当前遍历到的元素。在 Iterator 的 remove() 方法调用时,它会删除当前 Iterator 位置的元素。
泛型集合:
集合中可以存储任意类型的对象元素,但是当把一个对象存入集合后,集合会“忘记”这个对象的类型,将该对象从集合中取出时,这个对象的编译类型就统一变成了Object类型。换句话说,在程序中无法确定一个集合中的元素到底是什么类型,那么在取出元素时,如果进行强制类型转换就很容易出错。
所以就可以限制在集合中存储的对象
把数据类型当作参数进行传递
格式:
ArrayList<参数化类型> list = new ArrayList<参数化类型>();传递的数据类型必须是引用数据类型。基本数据类型报错,不过可以使用基本数据类型的包装类。

Collections算法类:
Collections和Collection不同,前者是集合的操作类,后者是集合接口
Collections提供的常用静态方法,所以可以直接用Collections调用
- sort():排序,升序
- max():查找最大值
- min():查找最小值
- reverse():降序
- binarySearch(集合 , 内容):查询指定内容是否存在
List<Integer> list = new LinkedList<>();
list.add(77);
list.add(88);
list.add(99);
list.add(11);
list.add(66);
//获得集合中最大的值
int max = Collections.max(list);
System.out.println("max:"+max);
//获得集合中最小的值
int min = Collections.min(list);
System.out.println("min:"+min);
//升序
Collections.sort(list);
System.out.println(list);
//降序
Collections.reverse(list);
System.out.println("降序"+list);
//查询指定内容是否存在
int i = Collections.binarySearch(list, 77);
System.out.println("i===="+i);
重写ComparaTo方法:
让当前对象重写compareTo方法
负数放左边
正数放右边
等于0按照默认排序
通过sort方法调用comparaTo方法:
重写 compareTo 方法后,Collections.sort 调用它是因为 sort 方法需要一个排序规则。compareTo 方法提供了对象的自然排序顺序,sort 方法通过调用 compareTo 来比较对象,从而决定它们在排序中的顺序。这使得 Collections.sort 能够按 compareTo 方法定义的逻辑对对象进行排序。
Collections.sort(lists);Collections排序:
Collections类可以对集合进行排序、查找和替换操作实现一个类的对象之间比较大小,该类要实现Comparable接口重写compareTo()方法
@Override
public int compareTo(Student stu) {
if (this.score> stu.getScore()){
return 0;//不换
} else if (this.score< stu.getScore()) {
return 1;//换
}else {
return -1;//都相同就不换
}
}this延申:
this.的意思是new一个对象,但是不能老是new对象,但是新的对象不能老是变,所以就用this,然后这个this就是指成员变量,也是默认对象
















 2630
2630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









