






Kafka集群
Kafka中的核心概念
1. Broker
- Kafka 的服务器节点。
- 每个 Broker 是 Kafka 集群的一部分,负责接收消息、存储消息、服务客户端请求。
- 一个集群可以包含多个 Broker。
- 每个 Broker 有唯一的 ID。
2. Topic
- Kafka 中的消息分类单位,类似“消息队列的队列名”。
- 生产者将消息发送到某个 Topic,消费者从这个 Topic 拉取消息。
- 一个 Topic 可以被分成多个 分区(Partition)。
3. Partition(分区)
- Topic 的物理分段,每个 Partition 是一个有序、不可变的消息队列。
- 每条消息在 Partition 中有一个唯一的编号:offset。
- 分区可以分布在多个 Broker 上,实现负载均衡。
4. Offset
- 每条消息在其所属分区中的编号,是消息的唯一标识。
- 消费者通过 offset 确定从哪里继续读取消息。
- 生产者有offset,消费者也有offset
5. Producer(生产者)
- 负责向 Kafka 的 Topic 写入消息。
- 可以指定消息发送到哪个 Topic 和 Partition。
6. Consumer(消费者)
- 从 Kafka 的 Topic 中拉取消息进行处理。
- 多个消费者可以组成一个 消费者组(Consumer Group)。
7. Consumer Group(消费者组)
- Kafka 的消费模型基础:一个组内的每个消费者只消费 Topic 的某个分区。
- 保证同一个消息不会被组内多个消费者重复消费(负载均衡)。
- 组与组之间是广播消费:每个组都能消费 Topic 的全部消息。
8. Zookeeper / Kafka Raft (KRaft)
- Kafka 旧版本使用 Zookeeper 进行集群管理(如 Broker 注册、Topic 元数据存储)。
- 从 Kafka 2.8 开始引入 KRaft(Kafka Raft Metadata Mode),替代 Zookeeper,简化架构。
9. Replication(副本)
-
Kafka 的高可用机制,每个 Partition 可以配置多个副本。
- 一个是 leader,负责读写;
- 其余是 follower,负责同步数据。
-
如果 leader 宕机,会自动选举一个 follower 作为新 leader。
10. Retention(保留策略)
- Kafka 会按时间或空间策略保留消息,默认是 保留 7 天。
- 超过时间或大小的旧消息会被自动删除。
11. Log(日志)
- 每个 Partition 实质上是一个追加写入的 commit log 文件。
- 消息在磁盘中顺序写入,效率非常高。
12. ISR(In-Sync Replica)同步副本集
-
定义:当前和 leader 保持同步的副本列表,包含 leader 和其 follower 中进度跟得上的副本。
-
只有在 ISR 中的副本才被认为是“健康的”。
-
ISR 是 Kafka 高可用的基础:当 leader 崩溃时,会从 ISR 中选出新的 leader。
-
示意:
- 一个 Partition 有 3 个副本:
broker-1(leader)、broker-2、broker-3 - 如果
broker-2和broker-3的数据都追上了 leader 的最新消息,它们就都在 ISR 中
- 一个 Partition 有 3 个副本:
13. LEO(Log End Offset)日志末尾偏移量
-
定义:一个副本中,下一条要写入消息的位置(偏移量)。
-
可以理解为“当前日志的结尾”。
-
例子:如果一个副本的最后一条消息 offset 是 12,则它的 LEO 是 13。
-
各副本都有自己的 LEO,Kafka 用它来判断是否副本落后 leader。
14. HW(High Watermark)高水位
-
定义:一个 Partition 中,所有 ISR 副本都确认写入的最大 offset,消息复制的进度。
-
消费者最多只能消费到 HW 之前的消息,因为这些消息已被多个副本确认,不会丢失。
-
Kafka 会不断更新 HW,以保证消息可靠性和顺序性。
- LEO:你写到哪了?
- HW:哪些是“所有副本都写好了”的数据?
- 消费者只能读 HW 之前的。
Kafka集群搭建
分别在不同的机器上搭建Broker节点,但是由于个人资源有限没有多台集群,因此使用一天机器来模拟搭建Kafka集群,对于Kafka集群的搭建有两种模式一个是依赖于Zookeeper,另一个是KRaft模式。我将分别使用不同的方式进行集群的搭建。
Kafka+Zookeeper
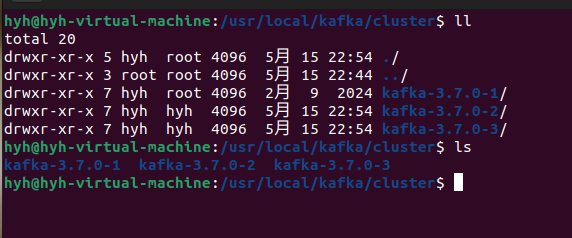
(1)首先在Kafka官网下载好Kafka的压缩包,解压到指定文件夹,cp 二份总共有三个节点。
(2)安装Zookeeper,可以参考这篇文章Zookeeper安装。
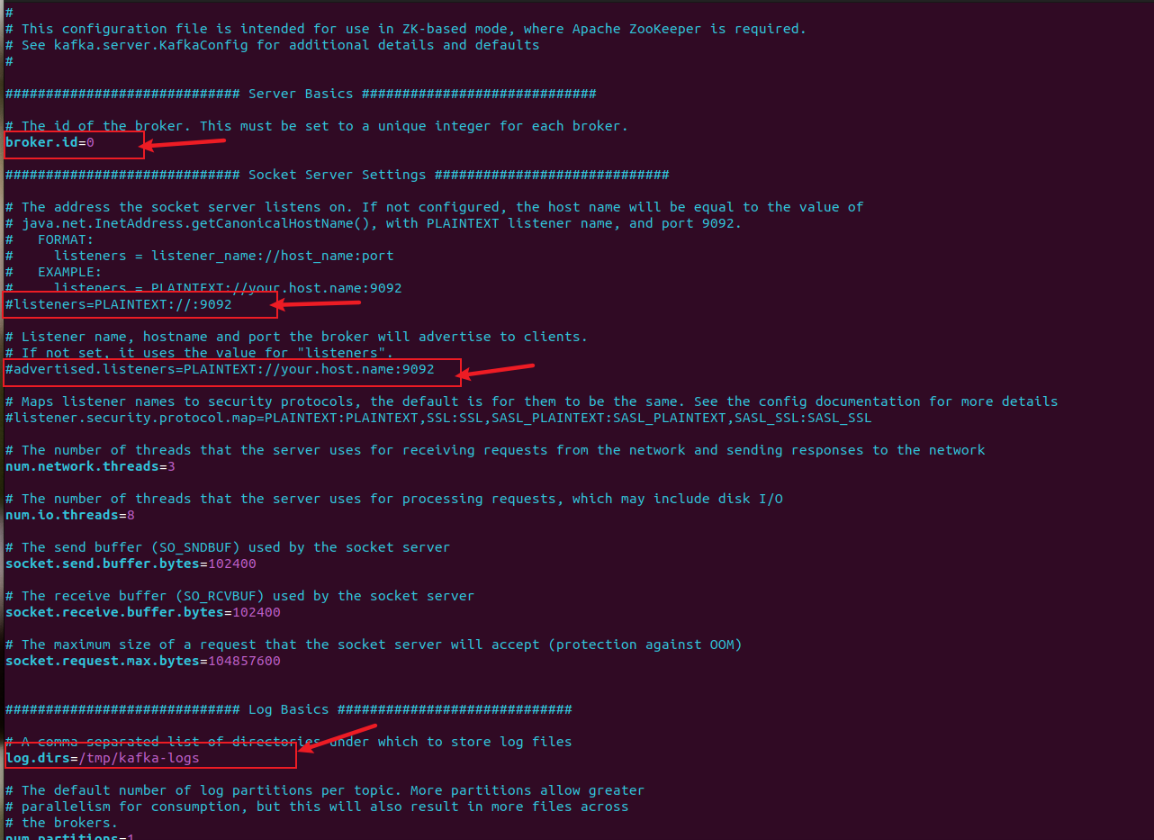
(3)修改Kafka的配置文件,重点修改如下图,我这有三个Kafka分别取broker.id为1、2、3,端口号分别为9091、9092、9093,日志路径为/tmp/kafka-logs/cluster/kafka-3.7.0-1、-2、-3,最后还需要指定Zookeeper的地址。建议大家配置完仔细检查一遍。
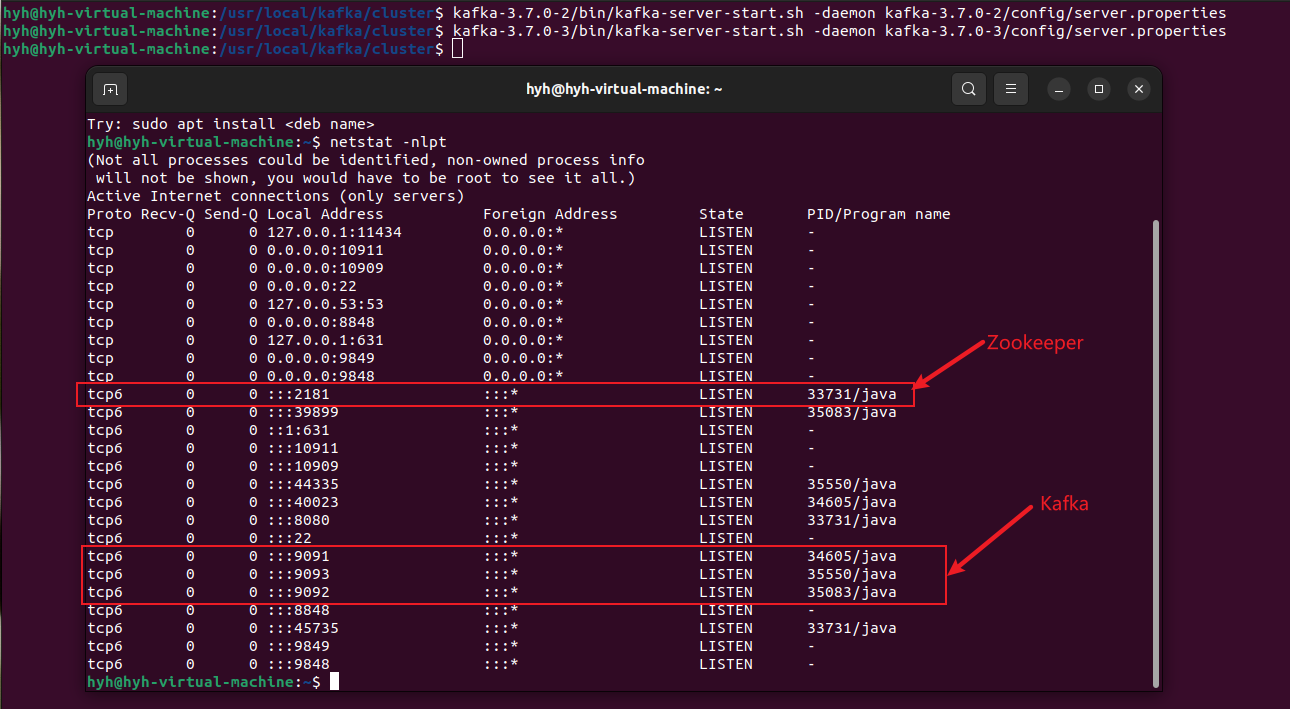
(4)启动
先启动Zookeeper,在分别启动三台Kafka,查看端口占用情况。
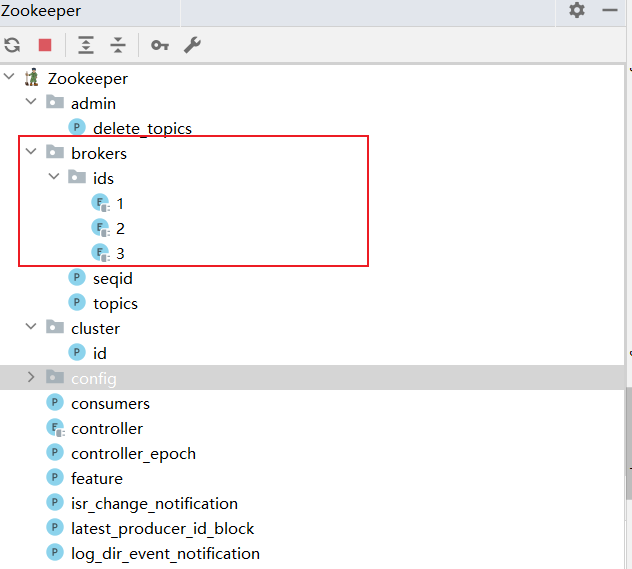
(5)可以看到Zookeeper已经成功和各个KafkaBroker节点建立连接。
使用KRaft管理
(1)修改KRaft下的配置文件,需要分别按下列格式修改不同节点上的配置文件。
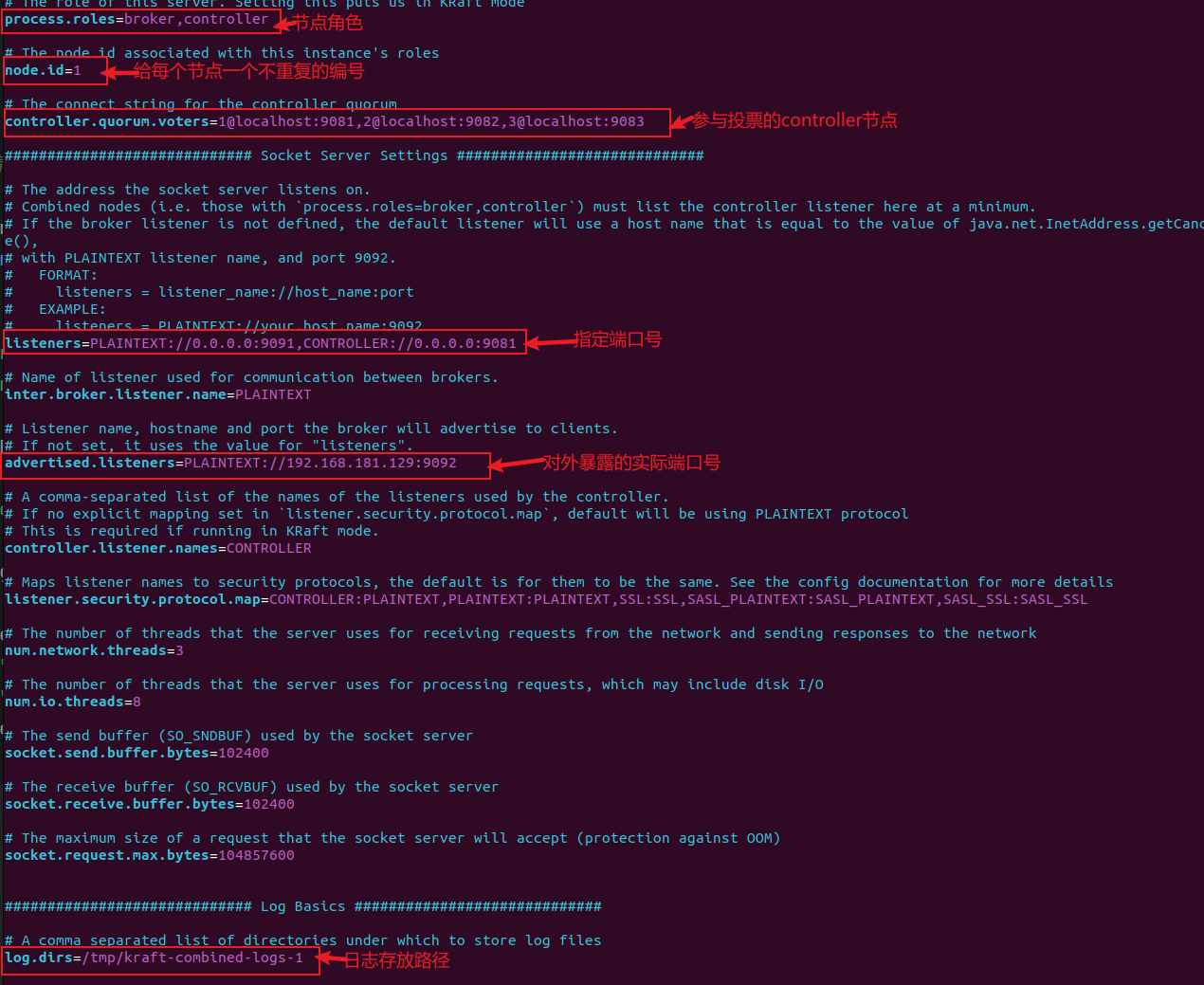
(2)分别启动不同的节点
# 生成集群ID
KAFKA_CLUSTER_ID=$(bin/kafka-storage.sh random-uuid)
echo $KAFKA_CLUSTER_ID
# 格式化,4.0.0版本没有Zookeeper启动脚本因此只存在一个配置文件在config/server.properties,根据情况自行修改
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
# 启动Kafka,daemon用于指定后台启动
bin/kafka-server-start.sh -daemon config/kraft/server.properties
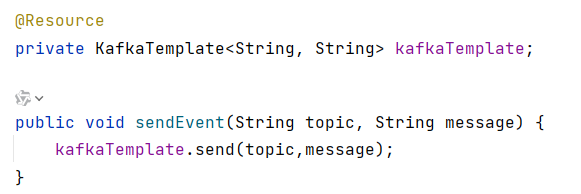
在SpringBoot中使用Kafka集群
在SpringBoot像kafka集群发送信息,设置三个分区,每个分区有三个replic副本,副本数不能超过集群Broker数。
@Configuration
public class KafkaConfig {
@Bean
public NewTopic topic() {
//创建一个一个名为cluster-topic的topic,分区数为3,副本数为3
return new NewTopic("cluster-topic", 3, (short) 3);
}
}
查看kafka集群状态
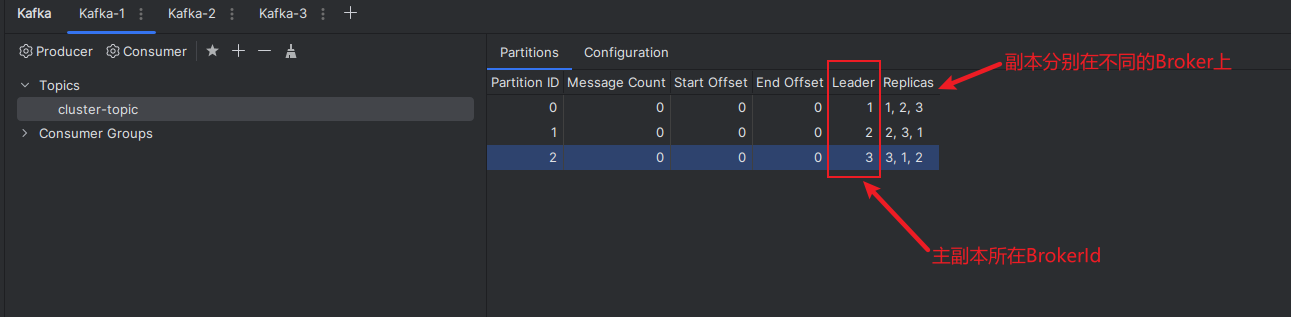
向集群发送消息

查看集群状态,发送成功

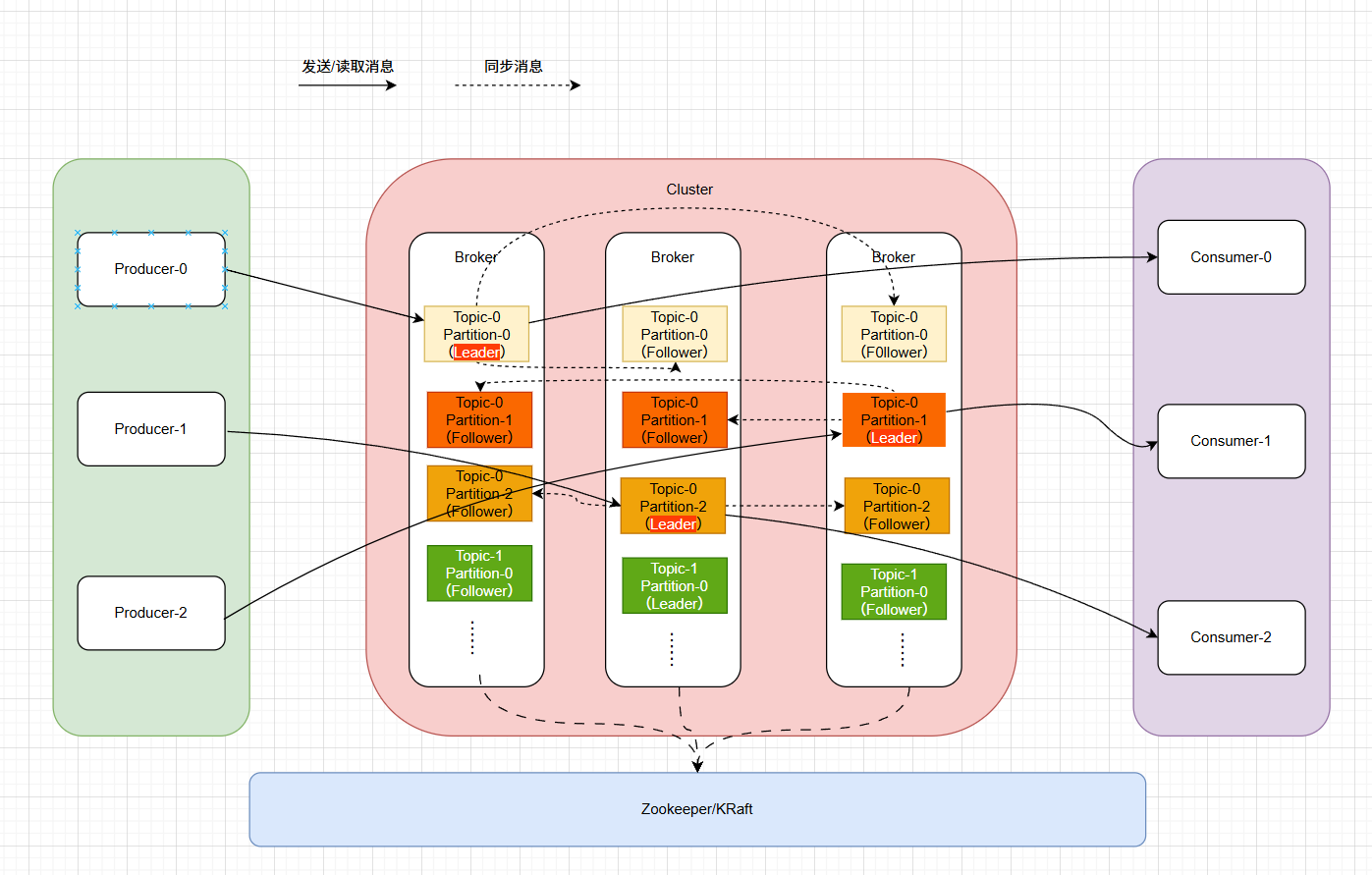
Kafka集群架构
小结
- 分布式架构:通过分区和副本实现数据分片,支持高吞吐量和线性扩展。
- 持久化存储:消息按分区顺序持久化到磁盘,支持数据回溯和重复消费。
- 高可用性:通过副本机制(Leader/Follower)自动故障转移,避免单点故障。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









