






- 本文出自AC.HASH团队,AC<=>Adaptive Creator,适应性创作者,旨在能够在未来新领域下创造出新的哈希算法以应对未来局面。
- 产出本文的成员:中原工学院大一在校生
- 我们在OpenHarmony成长计划啃论文俱乐部里,与华为,软通动力,润和软件,拓维信息,深开鸿等公司一起,学习和研究操作系统技术...
- 【本期看点】
- 基于位置隐私感知服务选择合适的虚拟位置以实现K-匿名
- 【智慧场景】
-
目录
3.虚拟位置选择(Dummy-Location Selection,DLS)算法
1.介绍
近年来,随着移动设备的和社交网络的快速发展,出现了很多基于位置服务(LBS)的应用程序,在这些应用程序的帮助下,用户可以很容易地向LBS服务器发送查询,获得与某个兴趣点相关的LBS。例如,用户可以查看附近餐馆,医院或加油站的价格信息等。LBS可以给用户提供便利的同时,不可信的LBS服务器会获取到用户的所有信息,因此,用户的隐私安全需要想办法保护,让用户在享受便利服务的同时保护好自己的隐私。
为了解决隐私问题,在过去的几年中,研究者大多基于位置扰动和混淆,采用例如K-匿名等隐私指标,依赖于可信的第三方,为了实现K-匿名,通过集中式位置匿名器,用户向LBS服务器提交一个与LBS相关的查询,例如标识符,确切位置,兴趣和查询范围,将查询的位置扩大为更大的隐藏区(CR),覆盖很多其他用户(如k-1),不可信的LBS服务器很难区分用户的真实位置和其他k-1个虚拟位置,以达到保护隐私的目的。但这些方法具有一定的局限性,使用k-匿名的方法都依赖于位置匿名器,而位置匿名器只会出现单点故障(一个地方出现故障,整个系统都无法运行)。如果攻击者获得了位置匿名器的控制权,那么这个区域的所有用户的隐私都会受到损害。同时,由于所有提交的查询都必须通过位置匿名器,所以位置匿名器在性能上也有瓶颈。要解决上述问题,目前最好的方法便是生成虚拟位置。
然而现有的大多数选择虚拟位置的方法都是在假设对手没有用户的相关信息(用户与位置,时间相关的查询概率)和与查询相关的信息(用户的性别,社会地位等),然后根据随机游走模型、或虚拟圈/网格模型生成虚拟位置。由于某些对手(如LBS服务器)可能有这样的相关信息,这些虚拟生成算法可能无法很好地工作。例如,一些不正确选择的虚拟位置可能会落在一些不太可能的位置,如湖泊、沼泽和崎岖的山脉等等,并且很容易被对手过滤掉。因此,很难有效保证用户所期望达到的k-匿名性。
2.相关概念
用户可从系统中获取的信息:局部信息和全局信息,局部信息是指用户收集到的信息,全局信息代表系统中的所有查询信息(所有用户在所有位置的查询概率)
我们首先来了解一下信息熵的概念和计算方法。
熵表示“信息”,“意外”,或者“不确定性”的平均水平。(概率低的事件信息更多),例:根据小明平时成绩,期末考到80分以上的概率只有10%,如果他期末真的考到了80分以上,那这个结果会很出乎意料,即带来了更大的信息。信息量随着发生概率单调递减,且不为负值。
假设有两个相互独立的事件A和B,那么A和B同时发生时获得的信息就等于两个事件独立发生时获得的信息和。
条件概率:
可以看出H→P可用对数函数表示。
对于发生概率为10%的事件A,那么A发生的可能原因有10种,可以看作A对应的10种等可能事件(事件集合)中的一种,那么A事件的信息量为,而A事件可以看作所有等可能事件的加权平均,所以B集合中任意一个事件的信息熵为:
可得:
这里由于信息熵的单位为bit,所以底数为2
那么对于随机变量X,它有各种不确定性,包含了个事件,则随机变量X的信息熵为:
量化位置隐私,需要找到对手推断该坐标的准确程度。匿名集的大小是确定隐私程度的一个参数,在将一个用户的真实信息隐藏到其他k-1用户中的模型的基础上,基于熵的度量方法可以很好的衡量位置隐私的不确定性。本文使用熵来衡量匿名度,熵可以看作从所有候选位置中确认单个当前位置的不确定性。每个可能的位置在过去被查询的概率为,那么候选集合中识别个体的熵:
从候选集中识别个体的最高不确定性(即获得最大的熵),当所有k个可能的位置具有相同的概率时,达到最大熵,最大熵为
。
3.虚拟位置选择(Dummy-Location Selection,DLS)算法
基于不依赖于任何可信实体的情况下更好的实现k-匿名的目的,在虚拟位置选择上采用熵值的大小作为判断标准,当虚拟位置生成在与用户真实位置的查询概率相似的单元格中时,使用DLS算法可以达到与最优K-匿名相同的高熵。
该算法的主要目的是生成一组真实的虚拟位置。 假设位置图被划分为 n × n 个大小相等的单元。每个单元格都有一个基于之前查询历史的查询概率,记为,
 其中
其中
(1) 用户需要确定适当的匿名程度k,k越大,隐私保护程度越大,但选择虚拟位置所产生的成本和开销也大。
(2)当提交的k个虚拟位置与服务器端真实位置的查询概率相同时,熵最大。用户读取所有获得的查询概率,根据查询概率的顺序对所有单元格排序,如果多个位置的查询概率与真实位置相同,则把真实位置放在这些位置的最中间。真实位置之前和之后的各k个单元格作为2k个候选,用户从2k个候选中随机选择k-1个单元格,和一个真实位置的单元格组成一个集合,共有m个这样的集合。第j
个集合可以表示为
根据所选单元格的原始查询概率,所包含单元格的归一化查询概率记为
,
为历史查询概率
它们的和为1。虚拟位置的候选并不一定为2k个,集合的大小根据用户需要的匿名程度决定。
这里说到的归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。
基于熵度量实现用户的k-匿名,对于一个特定的集合,利用
计算出在用户决定的匿名程度下熵值最大的集合
虽然DLS算法从熵度量方面可以实现更好的隐私度,但选择的虚拟位置不能保证是分散的,DLS算法在某些场景下仍有暴露用户隐私信息的可能,比如有可能选中的虚拟位置和真实位置都映射到了同一物理位置,由此提出了增强虚拟位置选择(Enhanced-DLS)算法
4.Enhanced-DLS(增强DLS)算法
enhanced-DLS算法同时考虑熵和更大的隐藏区(CR),在有最大熵的同时,尽可能的分散虚拟位置。虚拟选择问题可以表述为多目标优化问题(MOP)。(在有多个选择的时候选择最优的那个)
测量CR
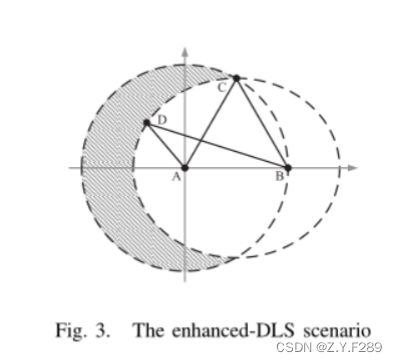
如下图,A为用户的真实位置,B是已被选择的虚拟位置(与A的距离最长),假设第三个虚拟位置有两个选择:C和D,如果根据虚拟位置对之间的距离总和选择,我们可以发现:DA+DB=CA+CB,那么选择C和D是一样的。但是从隐私的角度,我们倾向于选择C,因为C会进一步拓展虚拟位置,我们使用它们的乘法,
设 表示真实位置和虚拟位置的集合。MOP可以描述为
其中,
分别表示
的查询概率,
表示虚拟位置对之间的乘积。在MOP中,很难满足所有目标,我们的主要目标是混淆对手以保护用户的隐私,同时能够把特定位置定位给用户。基于这样的目的,提出了一个启发式的MOP解决方案。即选择一个冗余的虚拟位置集来最大化熵,然后从冗余位置集中选择最终的k-1个虚拟位置来最大化CR。启发式解决方案为:通过k-1轮依次选择,
在第一轮被选中,
在第二轮被选中,以此类推。设x为一轮中剩余侯选位置的数量,
表示侯选位置i的权重(在第一轮中为该位置与
的距离,在第m
轮中为该位置与
的距离×
),侯选位置
在本轮被选中的概率为
。
我们再来梳理一下增强DLS算法的过程:根据查询概率对单元格进行排序,在排序后的列表中选出4k个候选的虚拟位置,其中2k个候选在之前,2k个候选在
之后。
利用for循环遍历候选位置列,每一个侯选位置被选择的概率为。最后确定虚拟位置集合。增强DLS算法在保证高熵的同时让虚拟位置的分布更加分散,更好的隐藏真实用户。
5.对手攻击
在算法中,可以使用公钥基础设施 (PKI) 等加密技术来处理对用户和其他实体之间的无线信道的窃听攻击。方案还可以抵抗其他一些攻击,例如共谋攻击和推理攻击。
注:PKI就是利用公开密钥理论和技术建立提供安全服务的、具有通用性的基础设施,是创建、颁发、管理、注销公钥证书所涉及的所有软件、硬件集合体,PKI可以用来建立不同实体间的"信任"关系,它是目前网络安全建设的基础与核心。PKI的主要任务是在开放环境中为开放性业务提供基于非对称密钥密码技术的一系列安全服务,包括身份证书和密钥管理、机密性、完整性、身份认证和数字签名等。
抵抗共谋攻击:被动攻击者可能会与某些用户串通以获取其他用户的额外信息,或与LBS服务器串通以预测合法用户的敏感信息。如果在提交的k个位置中,成功猜测用户真实位置的概率不随合谋群体的规模而增加,则该方案是抗合谋攻击的。
由于DLS算法和增强DLS算法都是在2k/4k个候选中随机选择k-1个单元格,和一个真实位置的单元格组成一个集合,那么有m个这样的集合,也就是说每个位置都具有高度不确定性,即使对手知道 DLS 和增强 DLS 算法的工作原理,他也无法找到真实用户。所以,他只能在截获的k个位置内随机猜测真实的位置。同样,当串通组成员较多时,仍然只能随机猜测,也就是说猜测成功的概率仍然是。
被动攻击者的一种极端情况是,他可以通过破坏LBS服务器以及所有用户来获取全局信息。在这种情况下,他实际上成为了一个活跃的对手,并且可以执行如下所述的推理攻击。
抵抗推理攻击:在这部分分析中,LBS服务器被认为是一个主动的对手。他知道整个地图的查询概率、历史查询和当前查询,包括用户的标识符、真实和虚拟位置的混合、兴趣、查询范围等。基于这些信息,攻击者可以执行推理攻击以获得用户的敏感信息。
对于活跃的对手,他知道所提出的算法(DLS 和增强DLS)以及特定用户的所有历史数据。他可能会尝试反转算法,但这将失败,在 DLS 算法中,我们选择 2k 个候选者来隐藏真实位置的查询概率。一些候选者的查询概率可能略高,而另一些候选者的概率可能略低。DLS的选定虚拟位置是从2k个候选中随机选择的,保证了选择结果的不确定性。在我们的增强DLS算法中,我们也采用这种技术来保证不确定性。也就是说,不同的大小会导致不同的虚拟选择结果。因此,LBS服务器无法通过多次运行我们的算法来推断出真实的位置。
6.基于WiFi接入点的解决方案
在提出的 DLS 和增强 DLS 算法中,需要知道诸如用户查询概率之类的辅助信息,通过这些信息可以选择更为合适的虚拟位置以实现k匿名性。使用 WiFi 接入点 (AP) 来收集查询概率,用户可以随时随地发送查询,查询以h(x,y),I,r,othersi 的格式生成,其中 (x,y) 表示用户的确切位置,I表示查询兴趣,r为查询范围,其他包括用户的身份等。我们可以实现一个查询概率的共享方案,当用户进入一个AP的通信范围开始,用户可以从AP获得查询概率并将这些信息与他自己的信息合并,同时可以根据用户自己的意愿,可以将他手中的(部分)查询概率分享给AP,这样的方法扩大了每个用户的查询概率,共享之间的时间间隔也可以更改。
对于每个兴趣I,每个AP内区域内的原始查询概率是按照正态分布生成。AP收集其覆盖范围内的查询,并根据查询中的位置(x,y)将它们记录到不同的单元格中。当新用户加入时,共享方案也在AP上运行。与不同用户多次共享后,AP将有其他AP的查询概率。那么,对于用户来说就能够从单个AP中获得更多有用的信息。实验结果显示,当使用Levy walk模型时,8km × 8km地图上的所有ap大约需要4小时才能收集到单个兴趣点99%的部分信息(即获得大致的全局信息)。
7.不同方案比较
最优方案代表理论上的理性情况,在用户发送查询需求时,可将用户的位置信息随机生成k-1个虚拟位置,连同自己的位置一起发送给LBS服务器。然后,用户认为暴露真实位置的概率为。而在随机方案(基线方案)中,往往由于有些的特殊的地理原因或者服务器有关于地图中位置查询概率的相关信息,有了这些信息,服务器推测出真实位置的概率为
,其中
表示由于有较低查询概率,可过滤的虚拟位置的数量,结果,熵从
显著下降到了
。
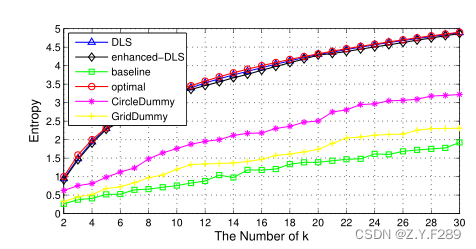
(1)在我们评估k与隐私级别之间的关系时,我们可以发现,如下图所示,基线方案是最糟糕的,因为它忽略了对手可能会利用一些侧信息(例如,查询概率)。因此,选择的虚拟位置可能会落入一些查询概率非常低的单元中,并被对手过滤掉。GridDummy的性能接近于基线方案,因为GridDummy选择虚拟的位置作为网格的顶点(√k ×√k),一旦地图被选择,这些顶点就会固定,因此它的熵取决于地图中当前查询的概率。CirDummy方案的性能比基线方案稍好一些。原因是所有选择的虚拟位置始终在一个虚拟圆内,小区域内查询概率的变化不会太大。与基线方案、GridDummy方案和CirDummy方案相比,由于DLS和增强DLS方案可以获得更高的隐私级别,这与最优方案相似,因为我们的算法从具有相似查询概率的单元中选择虚拟位置,以保证较高的熵。而对比DLS和增强DLS,我们可以看到DLS的熵比增强DLS好一点。这是因为增强DLS牺牲了一些熵来最大化CR。
(2)若我们以距离与k的乘积作为衡量标准,如下图所示,(a)表示基线方案虚拟地点选择,(b)表示增强DLS算法虚拟地点选择,黑色区域表示真实用户的位置,红色区域表示虚拟位置。
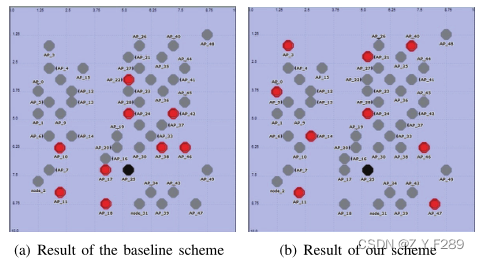
图1
我们可以看出 (a)中位置的距离较近,覆盖的CR也较小。我们再来评估k对每对用户的距离乘积以及查询区域的影响,如下图所示
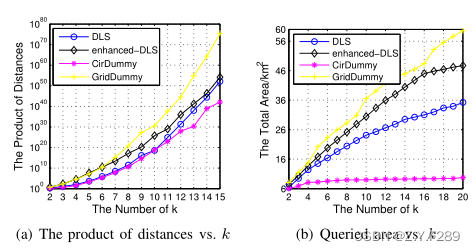
图2
由于所有提交的位置(包括真实位置和虚拟位置)都会影响每对用户的距离乘积和覆盖区域的大小。为简单起见,特定单元格中的用户被视为单元格中心的用户。我们可以观察到,GridDummy算法的距离和查询区域的乘积最大,因为在该算法中生成的虚拟位置会覆盖尽可能多的地图区域,但根据上文我们知道,该算法的整体隐私保护程度较低,而CirDummy算法的性能并不是很好,因为它依赖于随机选择的虚拟圆半径。一般来说,半径越大,距离乘积越大,查询的区域也越大,反之亦然。最后,我们忽略了基线方案的查询区域,因为它只是在整个地图中随机选择虚拟位置,而不考虑辅助信息。根据图2(a),综合来看增强DLS算法的性能更好一些。图2(b)表示了不同方案查询的区域。在仿真中,我们以查询范围r = 1km为例。随着k的增加,DLS算法和增强DLS算法的覆盖面积都变大。而增强DLS算法性能更好,因为它使用了一种贪婪的方法来尽可能地扩展虚拟位置。因此,当k > 12时,它可以将查询区域扩大近20%或更多。
(3)由于用户可以从单个AP或多个AP中获得查询概率,我们引入参数σ来描述获得的部分信息,而不是全局信息。在我们的评估中,我们使用50个AP, σ = 0.5表示用户知道25个AP的查询概率。我们在图3中展示了σ对熵和距离乘积的影响。在接下来的模拟中,我们设k = 10, r = 1km, σ从0.1改变到1.0。图3(a)显示了σ对熵的影响。可以看出,增强DLS算法与最优方案具有相似的熵值,两者都优于基线方案。这是因为我们总是选择具有类似查询概率的单元格。由于DLS算法与增强DLS算法具有相似的熵值,所以情况并没有如图3(a)那样。在图8(b)中,我们可以看到不同的σ对距离积的影响。当单元格数量较少时,我们必须从它们中选择候选者,即使它们彼此很接近。而评估结果表明,增强DLS算法优于DLS算法。
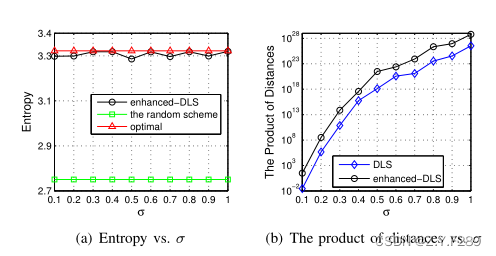
图3
8.总结
DLS算法基于获得的辅助信息,以熵值作为K-匿名水平的衡量,可达到最优K-匿名,基于DLS算法,研究者为解决DLS算法中对虚拟位置不能确保分散的问题提出了增强DLS算法,同时考虑了高熵和隐藏区域(CR),尽量保证了达到高熵的同时所选择的虚拟位置被尽可能的扩展,最后提出了一个基于AP的解决方案来实现我们的想法。根据不同方案的比较,表明了所提出的DLS算法在熵值方面可以显著提高隐私等级。增强的DLS算法可以在保持与DLS算法相似的隐私级别的同时扩大隐藏区域。该方法是从增强位置的不确定性,使攻击者不能确定用户的真实位置。
参考文献
[1]Niu B, Li Q, Zhu X, et al. Achieving k-anonymity in privacy-aware location-based services[C]//IEEE INFOCOM 2014-IEEE conference on computer communications. IEEE, 2014: 754-762.
如有侵权请及时联系删除


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









