






目录
1.3 下载好solr 解压后我们开启solr 使用solr自带服务器
1.4solr集成spring — 使用 java代码的曾删改查
solrDeom.zip - 蓝奏云linux中配置可能遇到的问题 linux 搭建可以会遇到的问题 集合 可能遇到的问题.zip - 蓝奏云
1.solr的使用 与配置
linux下部署solr 视频教学 部署到tomcat中
windows 部署 solr教学视频 部署到tomcat中
1.1 solr中开启服务
首先我们需要去下载solr 压缩包 地址
推荐下载
9版本以下的 8以上的版本 与我7版本有所不同 不支持mysql直接导入数据
9.0前版本下载
/dist/琉森/索尔特/索尔的索引 (apache.org)
1.2介绍solr 与用途
其实我们大多数人都使用过Solr,也许你不会相信我说的这句话,但是事实却是如此啊 ! 每当你想买自己喜欢的东东时,你可能会打开某宝或者某东,像这样一搜,就能搜到很多东西,你知道你看到的这些数据都来自哪儿吗?百度一下你就知道!这些数据来自哪儿吗?等你了解完Solr后你就知道答案啦!

现实生活中我们都知道大多数网站或应用都必须具有某种搜索功能,问题是搜索功能往往是巨大的资源消耗并且它们由于沉重的数据库加载而拖垮你的应用的性能。
这就是为什么转移负载到一个外部的搜索服务器是一个不错的主意,Apache Solr是一个流行的开源搜索服务器,它通过使用类似REST的HTTP API,这就确保你能从几乎任何编程语言来使用solr。
Solr是一个开源搜索平台,用于构建搜索应用程序。 它建立在Lucene(全文搜索引擎)之上。 Solr是企业级的,快速的和高度可扩展的。 使用Solr构建的应用程序非常复杂,可提供高性能。
为了在CNET网络的公司网站上添加搜索功能,Yonik Seely于2004年创建了Solr。并在2006年1月,它成为Apache软件基金会下的一个开源项目。并于2016年发布最新版本Solr 6.0,支持并行SQL查询的执行。
Solr可以和Hadoop一起使用。由于Hadoop处理大量数据,Solr帮助我们从这么大的源中找到所需的信息。不仅限于搜索,Solr也可以用于存储目的。像其他NoSQL数据库一样,它是一种非关系数据存储和处理技术。
总之,Solr是一个可扩展的,可部署,搜索/存储引擎,优化搜索大量以文本为中心的数据。
二. 那有人可能会说搜索这玩意儿数据库本身就支持啊,干嘛还要搞个什么solr?其实正如上面solr的介绍中所说的那样.
2.1 solr本身也可以看成数据库,(no sql类型),但它比数据库搜索速度更快,所以在项目中我们一般把搜搜的部分交给solr,就像我们在京东首页所看到的商品信息,并不是来自数据库,而是来源于sorl的索引库
2.1 数据库本身不能实现分词效果,而只能使用模糊查询,但是模糊查询非常低效,查询速度比较慢,由于在实际生活中,一般搜索是用的比较多的,这样数据库压力自然就很大,所以我们就让供专业的solr来做搜索功能
1.3 下载好solr 解压后我们开启solr 使用solr自带服务器
1.我们来看一下 solr 的目录结构
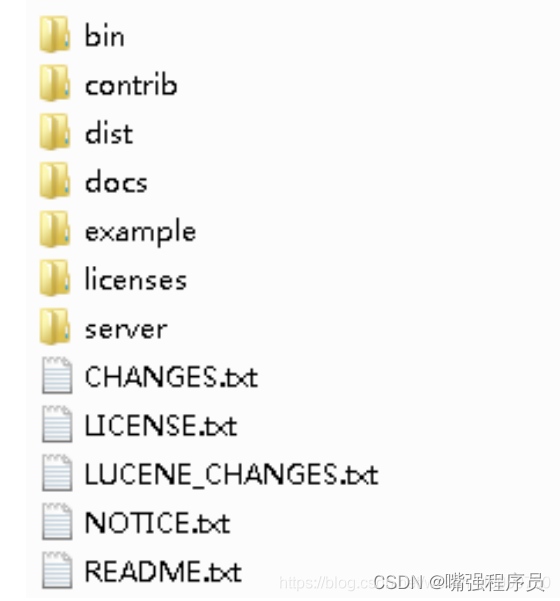
1.bin:是脚本的启动目录 2.contrib:第三方存放的目录 3.dist:编译打包后存放目录,即构建后的输出产物存放的目录 4.docs:solr文档的存放目录 5.example:示范例子的存放目录,这里展示了DIH,即数据导入处理的例子 该目录包含了多个实例
-
licenses:权限相关的
-
server:即solr搜索引擎框架,基于jetty web服务器开发的。包含jetty服务器的配置。 (这个目录就类似于一个包含了tomcat服务器,里面有一个基于solr的web工程)
2.我们打开cmd 窗口 进入solr目录的bin目录开启服务 与一些配置
先确认环境的JAVA_HOME是否配好。如果没配好,solr启动会有问题。(可省略)
启动solr [cmd] : solr start -p 8984 重启solr [cmd]:solr restart -p 8984 停止 solr [cmd]:solr stop -p 8984
访问localhost:8984如果启动成功,会自动跳转到solr的访问页面
修改配置文件:修改3个配置文件
1.Solrconfig.xml搜索requestHandler 标签,在同一级别粘贴如下内容:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>2.managed-schema在文件底部添加字段配置(对应数据库表字段)
<field name="test_name" type="text_ik" indexed="true" stored="true" />
<field name="test_geom" type="my_rpt" indexed="true" stored="true" />
3.添加data-config.xml
目录:solr-8.7.0\server\solr\test(你的solr-core目录下)
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource" driver="org.mysql.Driver" url="jdbc:mysql://localhost:3306/mysql"
user="mysql" password="xxxxxx" />
<document>
<entity name="test" query="SELECT id,name,addr FROM public.test">
<field column="id" name="id" />
<field column="name" name="test_name" />
<field column="addr" name="test_addr" />
</entity>
</document>
</dataConfig>datasource标签配置数据源 Document配置表 field是表中字段名 name属性为别名
添加依赖jar包:添加4个jar包
1.3 数据库驱动
2.Solr导入数据依赖jar包:solr-dataimporthandler-8.7.0.jar 获取目录:solr-8.7.0\dist(根目录下的dist目录) 目标目录:solr-8.7.0\server\solr-webapp\webapp\WEB-INF\lib 3.ik分词jar包:ik-analyzer-8.3.0.jar 下载地址:https://github.com/magese/ik-analyzer-solr
创建solr_core 主要有两种方式: 1.创建目录,拷贝配置文件 2.命令行(cmd)创建(推荐): solr create -c 名字
配置中文分詞插件 插件下载地址:https://github.com/magese/ik-analyzer-solr/releases/tag/v8.3.0
放置在指定目录:solr-8.7.0\server\solr-webapp\webapp\WEB-INF\lib 在WEB-INF目录下创建classes目录,拷贝插件包内的配置文件 修改你创建的solr_core目录下managed-schema配置文件 举例:solr-8.7.0\server\solr\test\conf 这里的test是我定义的solr_core的名字,即当前项目使用的solr_core是test managed-schema配置文件,新增内容:
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>验证安装是否成功: 注意需要 先重启 solr
1.介绍 搜索的参数配置

1.4solr集成spring — 使用 java代码的曾删改查
1.在spring搭建好的基础上加入solr 依赖包
<!-- solr -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.4.0</version>
</dependency>
<!--solr 依赖的jar包-->
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>在 spring的核心配置文件中加入
<!-- solr 配置 -->
<bean id="builder" class="org.apache.solr.client.solrj.impl.HttpSolrClient.Builder">
</bean>
<bean id="solr" class="org.apache.solr.client.solrj.impl.HttpSolrClient">
<constructor-arg name="builder" value="builder" />
<property name="baseURL" value="http://localhost:8983/solr/corengoods" />
</bean>接下来我们来测试一下 查询操作的使用
package com.zking.solr;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.client.solrj.response.UpdateResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.Bean;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.io.IOException;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations={"classpath*:applicationContext*.xml"})
public class SolrUtil {
@Autowired
// @Qualifier("solr")
private SolrClient client;
/**
* 查询文档
* */
@Test
public void query() throws IOException, SolrServerException {
//声明查询对象,并设置查询条件
SolrQuery query=new SolrQuery();
/* query.set("q","appName:有没有什么关于机械的玩意");*/
query.setQuery("title:java");
//执行查询
QueryResponse response=client.query(query);
//获取查询结果,文档集
SolrDocumentList documentList=response.getResults();
for (SolrDocument document:documentList){
System.out.println("查询到的APP名称:"+document.get("appName"));
System.out.println("文档的ID:"+document.get("title"));
System.out.println(document.get("content"));
}
}
}曾加与修改操作
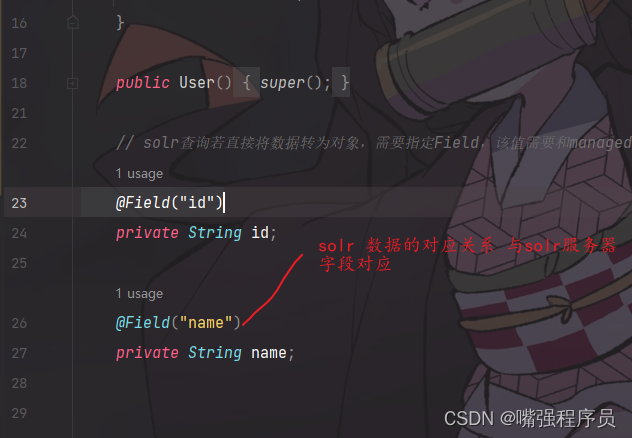
两种 新增与修改方式 (修改其实 就是solr中id相同 会直接覆盖)
@Test
public void addBean() throws Exception {
User user = new User("6", "小美眉");
solrClient.addBean(user);
solrClient.commit();
}
/**
* 新增或更新文档
* */
@Test
public void save() throws IOException, SolrServerException {
SolrInputDocument document=new SolrInputDocument(); //注意是SolrInputDocument,而非SolrDocument
//可为文档指定id,即addField("id","文档id"),如果id相同则操作为更新。
document.addField("id","123");
document.addField("appName","谁是机械狗");
document.addField("appAPK","com.xxx.xxx");
document.addField("appId",66);
UpdateResponse responseAdd=client.add(document); //这里也不一样,不像以往版本的提交
client.commit(); //提交
System.out.println("save一篇文档成功");
}
删除操作
/**
* 删除文档
* */
@Test
public void delete() throws IOException, SolrServerException {
client.deleteByQuery("appName:删除所有关于机械的文档记录"); //这是根据查询条件删除,也可根据id删除
client.commit();
System.out.println("删除成功");
}高级查询加权重设置
在很多时候,我们可能会需要增加某一个字段的权重,以合理的显示搜索结果。
例如:有一个schma,有三个字段:chapterId,title,content。 我们希望某一个关键字如果在title中匹配了,就要优先显示,而在content中匹配了,就放在搜搜结果的后面。当然,如果两者同时匹配当然没什么好说的了。看看solr中如何做到吧。 title:(test1 test2)^4 content:(test1 test2) 给title字段增加权重,优先匹配。
package com.zking.solr.utils;
import com.zking.solr.model.TestModel;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.Map;
@Component
public class SolrUtils {
@Autowired
private SolrClient solrClient;
public List<TestModel> query( String str ) throws Exception {
// 构造搜索条件
SolrQuery solrQuery = new SolrQuery();
// 设置搜索关键词
solrQuery.setQuery(str);
//过滤条件
// solrQuery.setFilterQueries("title:java");
// 设置排序
// solrQuery.setSort("id", SolrQuery.ORDER.desc);
// 设置分页信息
solrQuery.setStart(0);
solrQuery.setRows(10000);
//设置权重 !!!!!!!!!!!!!!!------------------------------------------
solrQuery.set("df", "keyvalue");
solrQuery.set("defType","dismax");
//权重 默认为 1
solrQuery.set("qf","content title^10");//这里必须包含查询条件title
// solrQuery.setParam("q.op", "AND");
// 设置高亮
solrQuery.setHighlight(true); // 开启高亮组件
solrQuery.addHighlightField("title");// 高亮字段
solrQuery.addHighlightField("content");// 高亮字段
solrQuery.setHighlightSimplePre("<span style=\"color: red;\">");// 标记,高亮关键字前缀
solrQuery.setHighlightSimplePost("</span>");// 后缀
// System.out.println(System.currentTimeMillis());
// 执行查询
QueryResponse response = solrClient.query(solrQuery);
// System.out.println(System.currentTimeMillis());
// 获取查询结果 通过映射
List<TestModel> users = response.getBeans(TestModel.class);
// 将高亮的标识写进对象的name字段上
Map<String, Map<String, List<String>>> map = response.getHighlighting();
for (Map.Entry<String, Map<String, List<String>>> highlighting : map
.entrySet()) {
for (TestModel user : users) {
if (!highlighting.getKey().equals(user.getId().toString())) {
continue;
}
List<String> title = highlighting.getValue().get("title");
//判断获取字段不可为空 才更换为高亮段
user.setTitle(title==null? user.getTitle():title.toString());
List<String> content = highlighting.getValue().get("content");
user.setContent(content==null? user.getContent():content.toString());
break;
}
}
return users;
}
}源码分享
solrDeom.zip - 蓝奏云
linux中配置可能遇到的问题
solrDeom.zip - 蓝奏云
笔记分享
https://wwn.lanzoul.com/b037hzfha
密码:cnvm














 4656
4656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









