






目录
5.在Spring Boot中集成Redisson实现布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
上面这句介绍比较全面的描述了什么是布隆过滤器,如果还是不太好理解的话,就可以把布隆过滤器理解为一个set集合,我们可以通过add往里面添加元素,通过contains来判断是否包含某个元素。
2.布隆过滤器的原理
- 首先,建立一个二进制向量,并将所有位设置为0。
- 然后,选定K个散列函数,用于对元素进行K次散列,计算向量的位下标。
- 添加元素:当添加一个元素到集合中时,通过K个散列函数分别作用于元素,生成K个值作为下标,并将向量的相应位设置为1。
- 检查元素:如果要检查一个元素是否存在集合中,用同样的散列方法,生成K个下标,并检查向量的相应位是否全部是1。如果全为1,则该元素很可能在集合中;否则(只要有1个或以上的位为0),该元素肯定不在集合中。

详细讲解一下添加元素:

比如,我们要把你好俩个字存到布隆过滤器里面,他要经历几个步骤?
首先,他会经过三个hash函数(这里也可以是多个hash函数,为了举例就用了三个),这三个hash函数会经过计算得到三个哈希值,然后他会把这三个hash值映射到这个数组里面,比如第一个hash经过一系列运算,会算出这个数组下标为3的位置,他就会把这个位置由0改为1,第二个,第三个同样原理。这样“你好”这个数据就存到布隆过滤器里面了。
查询过程:给插入过程类似,还是通过这三个hash函数算出“你好”这个数据的存入的下标,而且这三个下标的值必须都为1,才能证明“你好”这个数据存入,只要有一个位置不是1,那么这个数据就不存在。这里俩个地方设计的很有深意,一是多个hash函数,第二个就是二进制数据必须都是1,才能证明这个数据存在,下面在介绍。
删除过程:布隆过滤器很难做到删除

举个例子:这个“你好”通过计算得出下标为2,那么他就把下标为2的二进制数据改为了1,但是这个“hello”数据通过一系列的运算的也得出下标为2,那么他就把下标为2的二进制数据改为了1,此时我们不知道下标为2的位置存了“你好”还是“hello”或者有其他数据,因为他们经过相同的哈希运算,得到的相同位置的下标,若此时将下标为2的二进制数据改为0,代表将“你好”这个数据删除了,但是“hello”也存在这个这个位置,所以他在删除时,也将“hello"也删除了,这样就造成数据的误删。
3.空间计算
在布隆过滤器增加元素之前,首先需要初始化布隆过滤器的空间,也就是上面说的二进制数组,除此之外还需要计算无偏hash函数的个数。布隆过滤器提供了两个参数,分别是预计加入元素的大小n,运行的错误率f。布隆过滤器中有算法根据这两个参数会计算出二进制数组的大小l,以及无偏hash函数的个数k。
它们之间的关系比较简单:
- 错误率越低,位数组越长,控件占用较大
- 错误率越低,无偏hash函数越多,计算耗时较长
如下地址是一个免费的在线布隆过滤器在线计算的网址
Bloom Filter Calculator (krisives.github.io)
布隆过滤器的优点:
- 它是由一串二进制数组组成的一个数据,占用空间比较小
- 插入和查询的速度非常快,因为他计算的是哈希值,再由哈希值映射到这个数组的下标
- 保密性比较好,因为存储的都是二进制数据,不存储本身数据
- 时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
布隆过滤器的缺点:
- 很难做删除的操作
- 存在误判(这个数据本身不存在这个集合中,但是这个集合经过一系列的运算,他判断这个数据是存在于这个集合中的),这个缺点是不可避免的,只能减小这个误判的概率。
误判率的底层原理:hash函数就是影响误判率的一个因素,误判率越低,所需要的哈希函数就越多,空间就越大。所以要判断一个数据是否存在,他可能经历多个哈希函数,得出不同位置的下标,将不同下标的位置都设置为1,才能确定这个数据可能存在。
4.布隆过滤器的实现场景:
布隆过滤器可以告诉我们 “某样东西一定不存在或者可能存在”,也就是说布隆过滤器说这个数不存在则一定不存,布隆过滤器说这个数存在可能不存在(误判),利用这个判断是否存在的特点可以做很多有趣的事情。
解决Redis缓存穿透问题(面试重点)
邮件过滤,使用布隆过滤器来做邮件黑名单过滤
对爬虫网址进行过滤,爬过的不再爬
解决新闻推荐过的不再推荐(类似抖音刷过的往下滑动不再刷到)
HBase\RocksDB\LevelDB等数据库内置布隆过滤器,用于判断数据是否存在,可以减少数据库的IO请求
布隆过滤器实现:
导入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>实现:
@Test
void test() {
//insertions: 定义要插入布隆过滤器的数据量,这里是100万。
int insertions = 1000000;
//期望的误判率,即当一个元素实际上不在集合中时,布隆过滤器判断其存在的概率,这里设为2%
double fpp = 0.03;
//初始化一个存储string数据的布隆过滤器,默认误判率是0.03
//使用Guava库的BloomFilter.create方法创建一个针对字符串的布隆过滤器,指定字符集为UTF-8,预期插入元素数量和误判率
BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), insertions, fpp);
//用于存放所有实际存在的key,用于是否存在
//创建一个HashSet sets 来存放所有实际插入的唯一字符串,以便后续验证布隆过滤器的判断是否准确
Set<String> sets = new HashSet<>(insertions);
//这行代码是用来创建一个初始容量为 insertions 的 HashSet 集合。这里的 insertions 是之前定义的一个变量,值为1000000,代表预计要插入到集合中的元素数量。
//用于存放所有实际存在的key,用于取出
List<String> lists = new ArrayList<>(insertions);
//生成100万个随机UUID作为字符串插入到布隆过滤器和sets集合中,同时记录到lists列表
for (int i = 0; i < insertions; i++) {
String uuid = UUID.randomUUID().toString();
bf.put(uuid);
sets.add(uuid);
lists.add(uuid);
}
//统计正确命中的次数(rightNum
int rightNum = 0;
//误判的次数(wrongNum)
int wrongNum = 0;
for (int i = 0; i < 10000; i++) {
// 0-10000之间,可以被100整除的数有100个(100的倍数)
String data = i % 100 == 0 ? lists.get(i / 100) : UUID.randomUUID().toString();
//这里用了 might ,看上去不是很自信,所以如果布隆过滤器判断存在了,我们还要去 sets 中实锤
if (bf.mightContain(data)) {
if (sets.contains(data)) {
rightNum++;
continue;
}
wrongNum++;
}
}
System.out.println("误判数为:"+wrongNum);
//计算误判率
BigDecimal percent = new BigDecimal(wrongNum).divide(new BigDecimal(9900), 2, RoundingMode.HALF_UP);
//.divide(...): 这是 BigDecimal 类的一个方法,用于执行除法运算。传入的参数包括:
//第一个参数是要除的数,即 wrongNum,表示误判的次数。
//第二个参数是除数,即9900,表示理论上应判定为不存在的查询总数。
//第三个参数2指定了小数点后保留的位数,这里要求结果保留两位小数。
//第四个参数RoundingMode.HALF_UP指定了舍入模式。HALF_UP是最常见的舍入方式,即四舍五入。如果结果的小数部分大于或等于0.5,则向上舍
BigDecimal bingo = new BigDecimal(9900 - wrongNum).divide(new BigDecimal(9900), 2, RoundingMode.HALF_UP);
System.out.println("在100W个元素中,判断100个实际存在的元素,布隆过滤器认为存在的:" + rightNum);
System.out.println("在100W个元素中,判断9900个实际不存在的元素,误认为存在的:" + wrongNum + ",命中率:" + bingo + ",误判率:" + percent);
}
5.在Spring Boot中集成Redisson实现布隆过滤器
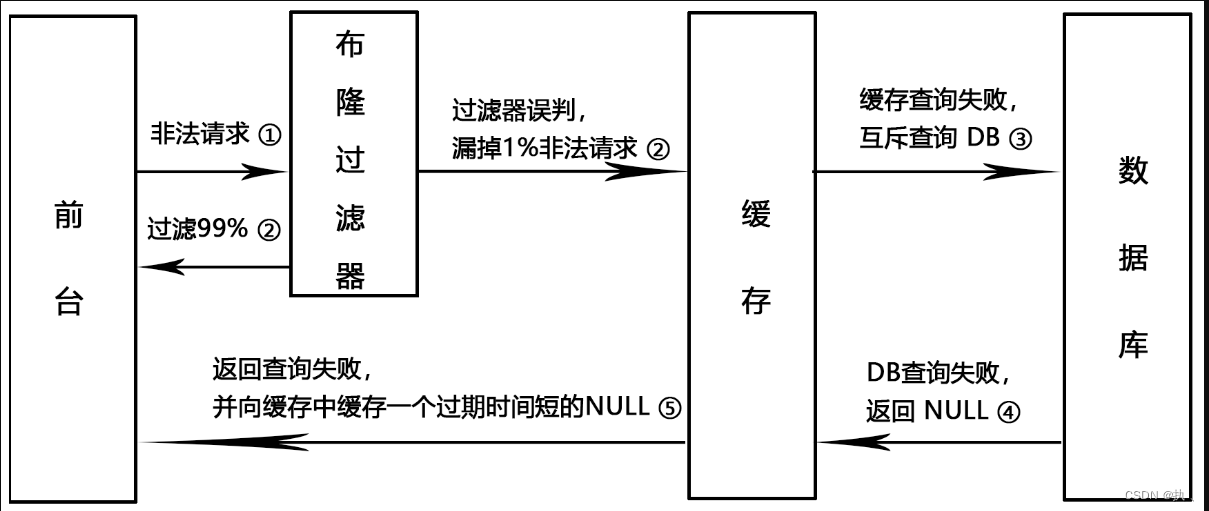
6、Redisson实现布隆过滤器
6.1导入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>配置application.properties
#Redis服务器地址
spring.redis.host=localhost
#Redis连接端口
spring.redis.port=6379在RedisConfig加入配置类
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private String port;
@Bean
public RedissonClient redisson() {
//创建配置
Config config = new Config();
config.useSingleServer().setAddress("redis://" + host + ":" + port);
//根据config创建出RedissonClient实例
return Redisson.create(config);
}
@Bean //主动注册了一个名字为redisTemplate的bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory){
RedisTemplate<Object, Object> template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer jackson = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper mapper = new ObjectMapper();
//启用默认类型推理,将类型信息作为属性写入json
//就是把类型的全类名写入JSON
mapper.activateDefaultTyping(mapper.getPolymorphicTypeValidator(),ObjectMapper.DefaultTyping.NON_FINAL);
jackson.setObjectMapper(mapper);
template.setKeySerializer(RedisSerializer.string());
template.setValueSerializer(jackson);
template.setHashKeySerializer(RedisSerializer.string());
template.setHashValueSerializer(jackson);
return template;
}
6.2使用
controller
@RestController
@RequestMapping("/api/user")
public class UserController {
@Autowired
UserService userService;
@GetMapping("/findById")
public User findById(Integer id){
return userService.findById(id);
}
@PostMapping("/addUser")
public Integer addUser(@RequestBody User user){
return userService.addUser(user);
}
}service
package com.zhy.service;
import cn.hutool.core.util.ObjectUtil;
import com.zhy.dao.UserDao;
import com.zhy.model.User;
import lombok.extern.slf4j.Slf4j;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
@Service
@Slf4j
public class UserService {
@Autowired
RedissonClient redissonClient;
@Resource(name = "redisTemplate")
RedisTemplate<String,User> redisTemplate;
private RBloomFilter<Integer> bloomFilter = null;
@Autowired
UserDao userDao;
@PostConstruct // 项目启动的时候执行该方法,也可以理解为在spring容器初始化的时候执行该方法
public void init() {
// 启动项目时初始化bloomFilter
List<User> userList = userDao.queryUserAll();
//参数:布隆过滤器的名字
bloomFilter = redissonClient.getBloomFilter("userFilter");
// 初始化布隆过滤器 预计数据量 误判率
bloomFilter.tryInit(1000L, 0.01);
//将数据添加到过滤器中和缓存中
//开启多线程,快速添加到过滤器中
ExecutorService service = Executors.newCachedThreadPool();
for (int i = 0; i < 5; i++) {
service.execute(()->{
for (User user : userList) {
bloomFilter.add(user.getId());
}
});
}
}
public User findById(Integer id) {
// 根据布隆过滤器判断用户是否存在
//如果一定不存在,则一定不存在,如何存在,则可能存在
if (!bloomFilter.contains(id)) {
log.debug("为非法的key");
return null;
}
//查询缓存
User user = redisTemplate.opsForValue().get("user:" + id);
//判断缓存中是否存在
log.debug("开始查询缓存");
if (ObjectUtil.isNotEmpty(user)){
return user;
}
log.debug("开始查询数据库");
User user1 = userDao.selectById(id);
redisTemplate.opsForValue().set("user:"+id,user1);
return user1;
}
public Integer addUser(User user) {
userDao.insert(user);
// 新生成key的加入布隆过滤器,此key从此合法
bloomFilter.add(user.getId());
return user.getId();
}
}黑名单service
@Resource(name = "redisTemplate")
HashOperations<String, String,String> hashOperations; //黑名单
private static String PRODUCT_BLACK_LIST = "product.black.list";
public Product findByPid(Integer pid) {
String key = "product." + pid;
// 查询黑名单中是否有该key
Boolean b = hashOperations.hasKey(PRODUCT_BLACK_LIST, key);
if(b){
throw new RuntimeException("商品不存在");
}
//如果黑名单没有该key,先查缓存
Product product1 = redisTemplate.opsForValue().get("product." + pid);
if (ObjectUtil.isNotEmpty(product1)) {
return product1;
}
//缓存不存在,查询数据库
log.debug("缓存不存在,查询数据库");
Product product2 = productDao.selectById(pid);
if(ObjectUtil.isEmpty(product2)){
//在将该商品加入黑名单中
hashOperations.put(PRODUCT_BLACK_LIST,key, DateUtil.now());
throw new RuntimeException("商品不存在");
}
//将查询出来的数据放到redis中;
redisTemplate.opsForValue().set("product." + pid, product2);
return product2;
}dao
User selectById(Integer id);
void insert(User user);
List<User> queryUserAll();model
@Data
public class User {
private Integer id;
private String name;
private Integer sex;
private Integer age;
}
UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.zhy.dao.UserDao">
<select id="queryUserAll" resultType="com.zhy.model.User">
select * from user
</select>
<select id="selectById" resultType="com.zhy.model.User">
select * from user where id=#{id}
</select>
<insert id="insert">
insert into user (name,sex,age) values(#{name},#{sex},#{age})
<selectKey keyProperty="id" resultType="integer" keyColumn="newId" order="AFTER">
SELECT LAST_INSERT_ID() as newId
</selectKey>
</insert>
</mapper>数据库
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL COMMENT '用户名',
`sex` int DEFAULT NULL COMMENT '0 男 1 女',
`age` int DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=106 DEFAULT CHARSET=utf8mb3 COLLATE=utf8_bin ROW_FORMAT=DYNAMIC;














 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









