







数据采集 - 爬虫
1.什么是爬虫
通过爬虫代码或者爬虫工具来获取互联网上公开的数据
2.为什么学爬虫
获取分析数据(不需要深入研究这一项技术)
3.爬虫学什么
1)获取网络数据 - requests、selenium、scrapy(最好,但不好用)
2)解析数据 - 提取有效数据(正则表达式、基于css选择器的解析器 -bs4、基于xpath的解析器)
3)保存数据 - excel、csv、数据库
4.一般爬什么
手机app(手机电脑同一网段使用抓包工具)、微信小程序、网页数据
5.常见反爬
1)设备检测 - 浏览器伪装
2)账号检测 - 登录反爬
3)封ip - 代理ip
4)数据加密(字体加密)
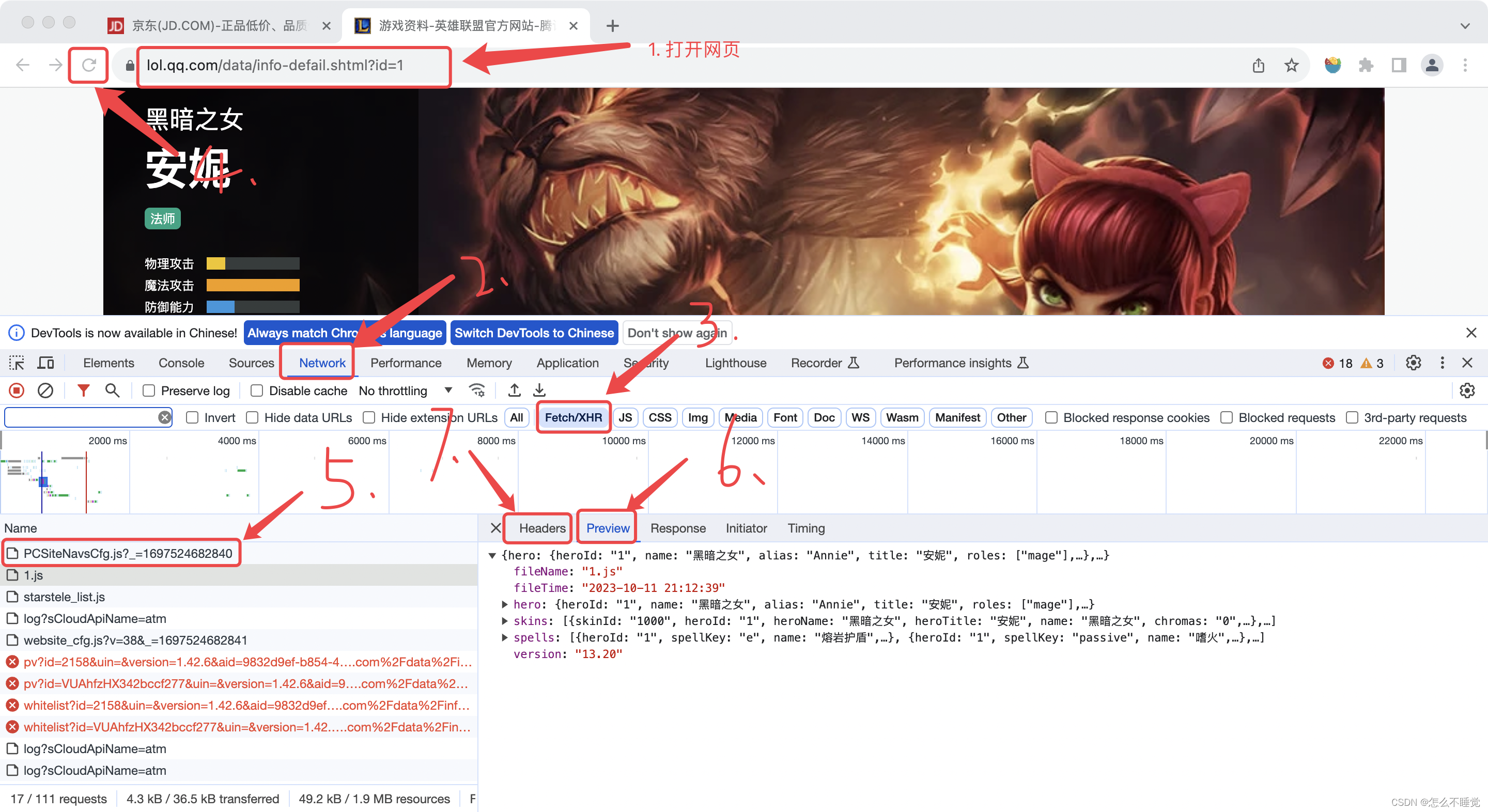
6.requests的基本用法
import requests
from re import *
# 1.对网页地址发送请求,返回一个响应(服务器返回给客户端的信息)对象
response = requests.get('https://cd.zu.ke.com/zufang')
# 2.获取请求结果(字符串)
result = response.text
# print(result) 这里记得打印获取的数据先查看是否成功并从终端复制源代码8
# 3.解析数据(正则)
titles = findall(r'<a class="twoline" target="_blank" href=".+">\s*(.+)</a>',result)
prices = findall(r'<span class="content__list--item-price"><em>(\d+)</em> 元/月</span>',result)
# print(titles)
# print(prices)
houses = map(lambda i1,i2:{'title':i1.strip(),'price':int(i2)},titles,prices)
print(list(houses))
7.浏览器伪装
import requests
# 1.创建一个headers添加浏览器信息
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
}
# 2.发送请求的时候发送浏览器信息(伪装成一个浏览器发请求)
response = requests.get('https://movie.douban.com/', headers=headers)
# 3.获取请求结果
print(response.text)















 6510
6510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









