






Sora技术解析与实战
在上次的文章中,我们带大家把Sora的技术路线“掰开了”给串了一遍,这次,我们直接上手代码,力求把Sora的技术路线“揉碎了”给大家展示。
1、AIGC技术基础知识-Stable Diffusion
过去这一年视频生成的发展路径:

不难发现,基于Stable Diffusion视频生成,即将视觉空间的数据映射到隐空间中,通过输入文本(或其他条件)在隐空间训练扩散模型,是当前主流的文生视频模式,那么,我们就抛砖引玉,先给大家看看Stable Diffusion目前已经很成熟的应用——文生图
把目前主流的Stable Diffusion模型运用起来,最重要的三个功能为提示词(prompt),参考图控制(controlnet),微调训练(lora)。
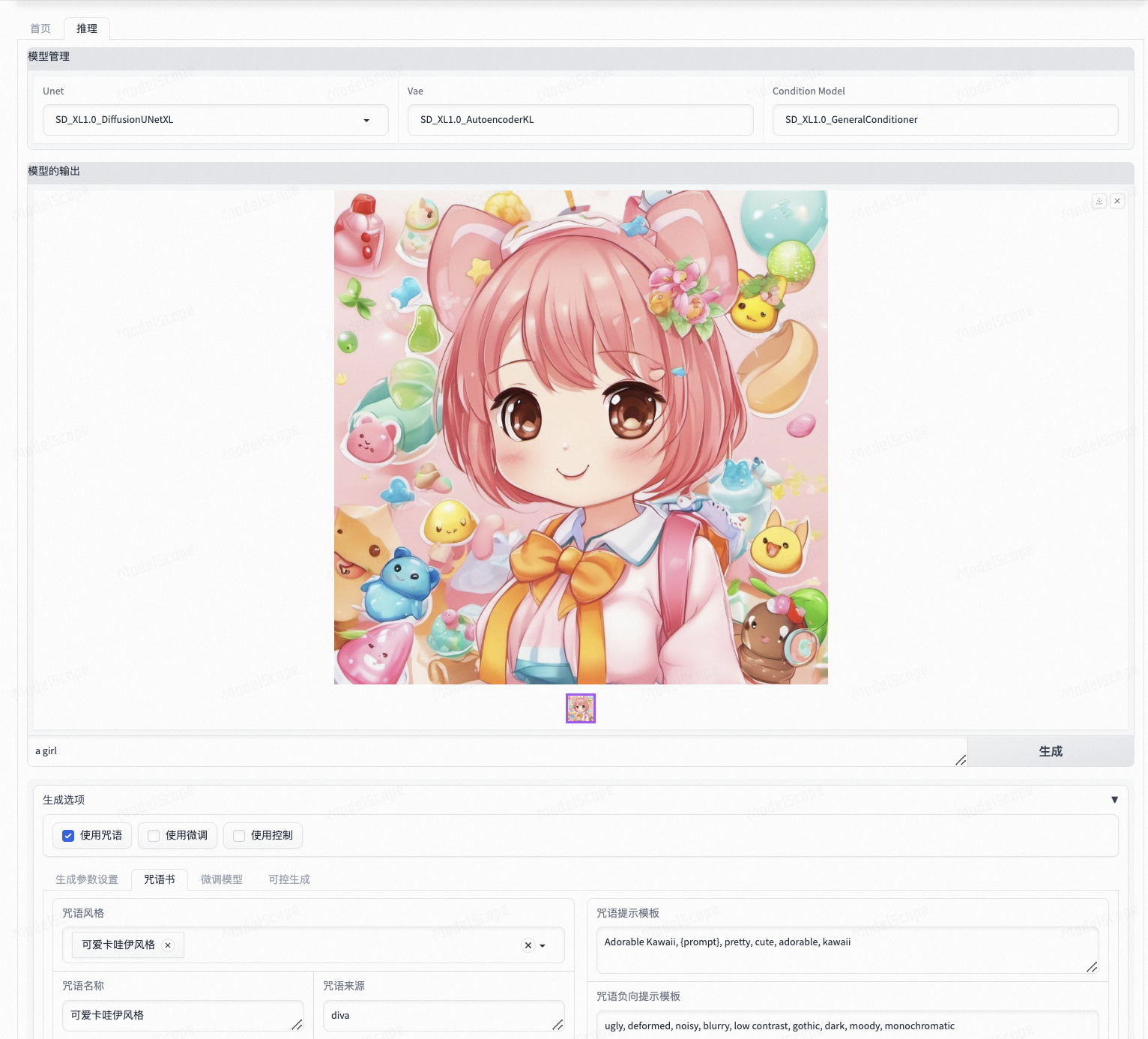
来自https://modelscope.cn/studios/iic/scepter_studio/summary,大家可以进去体验体验,刚才提到的三个功能都有。
当然,来自代码层面的推理实践也给大家安排上了:
1、Stable diffusion模型推理方法:SDXL模型,魔搭社区Pipeline已经集成SDXL模型,可以直接使用
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
import cv2
pipe = pipeline(task=Tasks.text_to_image_synthesis,
model='AI-ModelScope/stable-diffusion-xl-base-1.0',
use_safetensors=True,
model_revision='v1.0.0')
prompt = "Beautiful and cute girl, 16 years old, denim jacket, gradient background, soft colors, soft lighting, cinematic edge lighting, light and dark contrast, anime, art station Seraflur, blind box, super detail, 8k"
output = pipe({'text': prompt})
cv2.imwrite('SDXL.png', output['output_imgs'][0])
2、秒级推理方法1:SDXL-turbo模型是SDXL 1.0的蒸馏版本,SDXL-Turbo基于一种称之为对抗扩散蒸馏(ADD)的新颖的训练方法,这种方法在扩散模型采样可以减少到1到4步,而生成高质量图像。ADD的训练方式使用得分蒸馏,利用大规模扩散模型作为教师模型,并将其与对抗性损失相结合,即使在1-2步的采样步骤的低步骤状态下,使用对抗学习的方式,引入discriminator来辅助生成质量的把控,也可以确保高质量图像的保真度。
from diffusers import AutoPipelineForText2Image
import torch
from modelscope import snapshot_download
model_dir = snapshot_download("AI-ModelScope/sdxl-turbo")
pipe = AutoPipelineForText2Image.from_pretrained(model_dir, torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
prompt = "Beautiful and cute girl, 16 years old, denim jacket, gradient background, soft colors, soft lighting, cinematic edge lighting, light and dark contrast, anime, art station Seraflur, blind box, super detail, 8k"
image = pipe(prompt=prompt, num_inference_steps=1, guidance_scale=0.0).images[0]
image.save("SDXLturbo.png")
3、秒级推理方法2:SDXL+LCM,潜在一致性模型(LCM)受一致性模型(CM)启发,在预训练的LDM上以较少的步骤进行快速推理。LCM-SD系列是在Stable Diffusion的基础上新增Consistency 约束蒸馏的结果,仅通过2-8步的推理即可实现高质量的文本到图片的生成性能。
from diffusers import UNet2DConditionModel, DiffusionPipeline, LCMScheduler
import torch
from modelscope import snapshot_download
model_dir_lcm = snapshot_download("AI-ModelScope/lcm-sdxl",revision = "master")
model_dir_sdxl = snapshot_download("AI-ModelScope/stable-diffusion-xl-base-1.0",revision = "v1.0.9")
unet = UNet2DConditionModel.from_pretrained(model_dir_lcm, torch_dtype=torch.float16, variant="fp16")
pipe = DiffusionPipeline.from_pretrained(model_dir_sdxl, unet=unet, torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.to("cuda")
prompt = "Beautiful and cute girl, 16 years old, denim jacket, gradient background, soft colors, soft lighting, cinematic edge lighting, light and dark contrast, anime, art station Seraflur, blind box, super detail, 8k"
image = pipe(prompt, num_inference_steps=4, guidance_scale=8.0).images[0]
image.save("SDXLLCM.png")
4、秒级推理方法3:stable-cascade模型基于Würstchen架构构建,与稳定扩散等其他模型的主要区别在于它在更小的潜在空间中工作。潜在空间越小,推理速度就越快,训练成本也就越低。潜在空间有多小?稳定扩散使用压缩因子 8,从而将 1024x1024 图像编码为 128x128。Stable Cascade 的压缩系数为 42,这意味着可以将 1024x1024 图像编码为 24x24,同时保持清晰的重建。然后在高度压缩的潜在空间中训练文本条件模型。与稳定扩散 1.5 相比,该架构的先前版本实现了 16 倍的成本降低。
import torch
from modelscope import snapshot_download
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
device = "cuda"
num_images_per_prompt = 1
stable_cascade_prior = snapshot_download("AI-ModelScope/stable-cascade-prior")
stable_cascade = snapshot_download("AI-ModelScope/stable-cascade")
prior = StableCascadePriorPipeline.from_pretrained(stable_cascade_prior, torch_dtype=torch.bfloat16).to(device)
decoder = StableCascadeDecoderPipeline.from_pretrained(stable_cascade, torch_dtype=torch.float16).to(device)
prompt = "Beautiful and cute girl, 16 years old, denim jacket, gradient background, soft colors, soft lighting, cinematic edge lighting, light and dark contrast, anime, art station Seraflur, blind box, super detail, 8k"
negative_prompt = ""
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
for i, img in enumerate(decoder_output):
img.save(f"stablecascade_{i+1}.png")
#Now decoder_output is a list with your PIL images
5、秒级推理方法4:
import torch
from diffusers import StableDiffusionXLPipeline, UNet2DConditionModel, EulerDiscreteScheduler
from modelscope.hub.file_download import model_file_download
from modelscope import snapshot_download
from safetensors.torch import load_file
base = snapshot_download("AI-ModelScope/stable-diffusion-xl-base-1.0")
repo = "AI-ModelScope/SDXL-Lightning"
ckpt = "sdxl_lightning_4step_unet.safetensors" # Use the correct ckpt for your step setting!
# Load model.
unet = UNet2DConditionModel.from_config(base, subfolder="unet").to("cuda", torch.float16)
unet.load_state_dict(load_file(model_file_download(repo, ckpt), device="cuda"))
pipe = StableDiffusionXLPipeline.from_pretrained(base, unet=unet, torch_dtype=torch.float16, variant="fp16").to("cuda")
# Ensure sampler uses "trailing" timesteps.
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing")
# Ensure using the same inference steps as the loaded model and CFG set to 0.
pipe("A girl smiling", num_inference_steps=4, guidance_scale=0).images[0].save("sdxllightning.png")
微调lora叠加推理
from diffusers import AutoPipelineForText2Image
from modelscope import snapshot_download
import torch
model_dir=snapshot_download("YorickHe/majicmixRealistic_v6")
lora_dir = snapshot_download("PaperCloud/zju19_dunhuang_style_lora")
pipeline = AutoPipelineForText2Image.from_pretrained(f"{model_dir}/v7", torch_dtype=torch.float16).to("cuda")
pipeline.load_lora_weights(lora_dir, weight_name="dunhuang.safetensors")
prompt = "1 girl, close-up, waist shot, black long hair, clean face, dunhuang, Chinese ancient style, clean skin, organza_lace, Dunhuang wind, Art deco, Necklace, jewelry, Bracelet, Earrings, dunhuang_style, see-through_dress, Expressionism, looking towards the camera, upper_body, raw photo, masterpiece, solo, medium shot, high detail face, photorealistic, best quality"
#Negative Prompt = """(nsfw:2), paintings, sketches, (worst quality:2), (low quality:2), lowers, normal quality, ((monochrome)), ((grayscale)), logo, word, character, bad hand, tattoo, (username, watermark, signature, time signature, timestamp, artist name, copyright name, copyright),low res, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans, extra fingers, fewer fingers, strange fingers, bad hand, mole, ((extra legs)), ((extra hands))"""
image = pipeline(prompt).images[0]
image.save("sdlora.png")
2、Transformers技术解析+实战(LLM)
Attention
Attention = 注意力,从两个不同的主体开始。
直观理解

Effective Approaches to Attention-based Neural Machine Translation,这篇论文告诉了我们两种注意力的计算方式,感兴趣的可以看看,毕竟现在大家谈自注意力机制谈得多,但是他的前人作了什么铺垫却鲜有人知,但能帮你很好地理解注意力。
Attention Is All You Need,大名鼎鼎的Transformer,本文就不再赘述其精妙之处了,感兴趣可以读读论文。
现在,我们只用一个核心的SelfAttention模块(可支持Single-Head或Multi-Head),来学习理解Attention机制
以下是self-attention模块的搭建
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
assert config.hidden_dim % config.num_heads == 0
self.wq = nn.Linear(config.hidden_dim, config.hidden_dim, bias=False)
self.wk = nn.Linear(config.hidden_dim, config.hidden_dim, bias=False)
self.wv = nn.Linear(config.hidden_dim, config.hidden_dim, bias=False)
self.att_dropout = nn.Dropout(config.dropout)
def forward(self, x):
batch_size, seq_len, hidden_dim = x.shape
q = self.wq(x)
k = self.wk(x)
v = self.wv(x)
q = q.view(batch_size, seq_len, self.config.num_heads, self.config.head_dim)
k = k.view(batch_size, seq_len, self.config.num_heads, self.config.head_dim)
v = v.view(batch_size, seq_len, self.config.num_heads, self.config.head_dim)
q = q.transpose(1, 2)
k = k.transpose(1, 2)
v = v.transpose(1, 2)
# (b, nh, ql, hd) @ (b, nh, hd, kl) => b, nh, ql, kl
att = torch.matmul(q, k.transpose(2, 3))
att /= math.sqrt(self.config.head_dim)
score = F.softmax(att.float(), dim=-1)
score = self.att_dropout(score)
# (b, nh, ql, kl) @ (b, nh, kl, hd) => b, nh, ql, hd
attv = torch.matmul(score, v)
attv = attv.view(batch_size, seq_len, -1)
return score, attv
开始写模型
class Model(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.emb = nn.Embedding(config.vocab_size, config.hidden_dim)
self.attn = SelfAttention(config)
self.fc = nn.Linear(config.hidden_dim, config.num_labels)
def forward(self, x):
batch_size, seq_len = x.shape
h = self.emb(x)
attn_score, h = self.attn(h)
h = F.avg_pool1d(h.permute(0, 2, 1), seq_len, 1)
h = h.squeeze(-1)
logits = self.fc(h)
return attn_score, logits
模型我们现在搭建完了,为了帮助大家有更深的理解,我还为大家准备了一个基于简单Transformer练手的项目,为了节约篇幅,这里就不过多展开了,项目的源码、数据集的获取可以看文末链接。
LLaMA

这个是拥有以下结构的一个大语言模型
- Tokenize
- Decoding
- Transformer Block
这个大模型可以说是Transformer的再升级版,我们用numpy手搓了一个,具体的代码实现同见文末链接
这部分的“习题解答”
一些习题,期待大家未来即将成为NLP/大模型工程师的时候,可以用它准备面试
- 理解Attention:
Attention机制是一种用于深度学习模型的技术,允许模型在处理序列数据时更关注输入的不同部分,而不是一概而论地对所有信息平等对待。通过分配不同的权重给输入序列的不同位置,Attention机制可以在不同时间步上集中注意力,提高模型对关键信息的感知能力。 - 乘性Attention和加性Attention的不同:
- 乘性Attention使用元素乘积来计算注意力权重,通常通过计算两个向量的点积,然后进行softmax操作。
- 加性Attention通过将两个向量连接并通过一个学习的权重矩阵进行线性变换,然后应用非线性激活函数(如tanh),最终通过另一个权重向量计算得到注意力权重。
- Self-Attention采用Dot-Product Attention的原因:
- Dot-Product Attention计算简单,计算效率高。
- 对于自注意力机制,将查询、键、值的维度相同,通过点积计算可以实现相似性度量。
- Self-Attention中的Scaled因子的作用:
- Scaled是为了缓解点积计算中的数值过大问题,通过除以sqrt(d_k)来平衡梯度的尺度,有助于更稳定的训练。
- Multi-Head Self-Attention中,Multi越多越好吗:
- 不一定,增加头数可以提供更多的表达能力,但也增加了计算开销。适当数量的头有助于模型学习多个不同的注意力方向,但过多的头可能导致过拟合。
- Multi-Head Self-Attention中,增加head_dim和减少head_dim的影响:
- 增加head_dim会增加每个头的表达能力,减小head_dim会减少计算负担。具体影响取决于任务和模型的复杂性,需要进行实验来确定最佳设置。
- 为什么对Attention weights应用Dropout,一般需要Dropout的地方,推理时Dropout如何执行,Dropout的理解:
- Dropout有助于防止过拟合,通常应用于注意力权重,可以在训练时随机将一些权重设为零。在推理时,通过调整权重来补偿丢失的信息。
- Self-Attention的qkv初始化时,bias的设置:
- 通常,初始化为零,有时也可以根据任务进行调整。对于自注意力,bias的作用是引入偏置以确保网络在初始化时不是完全对称的。
- 其他变种的Attention和优化改进:
- Transformer中的位置编码、Relative Attention等。
- 一些变种可能采用不同的计算方法、增加记忆能力、引入外部信息等。
- Attention的缺点和不足:
- 计算开销大,尤其在序列较长时。
- 对序列顺序敏感,可能需要特殊处理。
- 注意力权重的解释性较弱。
- Deep Learning中Deep的理解和多个Attention的效果:
- "Deep"指的是模型的层数。多个Attention可以提供更丰富的表示能力,有助于捕捉数据的复杂结构和关系。
- Deep和Wide在设计模型架构时的考虑:
- "Deep"用于学习复杂的特征层次结构,"Wide"用于学习稀疏但重要的特征组合。
- 在设计模型时需要平衡深度和宽度,具体取决于任务和数据。
LLM部分
-
Tokenize的理解和方式:
Tokenize是将文本分割成词语或子词的过程。有几种方式,包括基于空格分割、基于字符分割、基于词根的分割,以及更复杂的词嵌入模型,如BERT中的WordPiece或SentencePiece。 -
Tokenizer模型的理想特点:
- 高效:能够迅速处理大量文本。
- 泛化性:适应不同语种和领域。
- 准确:能够正确识别复杂词汇和专有名词。
- 可扩展:能够轻松应对新词汇和变化。
-
特殊Token(开始和结束标记)的作用:
- 开始标记:为模型提供序列开始的信息,引导生成过程。
- 结束标记:表明序列的结束,帮助模型确定生成何时结束。
模型不能自动学习它们,因为它们是序列生成的先验知识,有助于模型更好地理解序列的结构。
-
LLM为何是Decoder-Only的:
LLM中的任务通常是生成下一个词,因此只需关注输入序列的信息,不需要同时处理未来信息。Decoder-Only结构更轻量,更适合语言模型任务。 -
RMSNorm和LayerNorm的区别:
RMSNorm是一种归一化方法,类似于LayerNorm,但其缩放因子是基于每个通道的平方均值的平方根。相较于LayerNorm,RMSNorm在某些情况下更稳定。 -
残差连接在LLM中的体现和原因:
残差连接是指将输入直接添加到输出,有助于信息传递和梯度流动。在LLM中,残差连接用于跨层传递信息,帮助缓解梯度消失问题,加速训练。 -
PreNormalization和PostNormalization的影响和为何LLM使用PreNormalization:
- PreNormalization:归一化和子层操作之前。
- PostNormalization:归一化和子层操作之后。
PreNormalization更有利于梯度传播,有助于更稳定的训练,因此在LLM中更常见。
-
FFN为何先扩大后缩小:
先扩大后缩小的结构有助于捕获不同层次的特征。扩大维度可以增加模型对局部信息的感知,而缩小维度则有助于提取全局信息,从而更好地捕获序列中的模式。 -
LLM为何需要位置编码和几种位置编码方案:
由于Transformer没有处理序列中的顺序信息,需要通过位置编码来提供位置信息。常见的编码方式包括绝对位置编码、相对位置编码和学习位置编码。 -
RoPE相较于其他位置编码的改进:
RoPE(Relative Positional Encoding)能够更好地捕捉序列中不同位置之间的相对关系,有助于提高模型在长序列上的性能。 -
设计位置编码方案时要考虑的因素:
- 对不同位置的区分度。
- 是否引入了不同位置的相对关系。
- 是否可学习,以适应不同任务。
-
将LLM中的设计加入Self-Attention模型的效果提升:
class SelfAttentionLayerWithRMSNorm(nn.Module): def __init__(self, input_size, num_heads): super(SelfAttentionLayerWithRMSNorm, self).__init__() self.self_attention = MultiHeadSelfAttention(input_size, num_heads) self.rms_norm = RMSNorm(input_size) def forward(self, x, mask=None): attn_output = self.self_attention(x, mask) norm_output = self.rms_norm(attn_output + x) return norm_output class TransformerModelWithRMSNorm(nn.Module): def __init__(self, vocab_size, embed_size, num_heads, num_layers): super(TransformerModelWithRMSNorm, self).__init__() self.embedding = nn.Embedding(vocab_size, embed_size) self.transformer_layers = nn.ModuleList([ SelfAttentionLayerWithRMSNorm(embed_size, num_heads) for _ in range(num_layers) ]) self.fc_output = nn.Linear(embed_size, vocab_size) def forward(self, x, mask=None): embedded = self.embedding(x) for layer in self.transformer_layers: embedded = layer(embedded, mask) output = self.fc_output(embedded) return output 代码演示了如何将RMSNorm整合到Self-Attention部分的Transformer模型中。
3、基于Transformers,diffusion技术解析+实战
Latte:用于视频生成的潜在扩散变压器
Latte提出了一种新颖的潜在扩散变压器,用于视频生成。Latte 首先从输入视频中提取时空标记,然后采用一系列 Transformer 块对潜在空间中的视频分布进行建模。为了对从视频中提取的大量标记进行建模,从分解输入视频的空间和时间维度的角度引入了四种有效的变体。为了提高生成视频的质量,我们通过严格的实验分析确定了 Latte 的最佳实践,包括视频剪辑补丁嵌入、模型变体、时间步级信息注入、时间位置嵌入和学习策略。我们的综合评估表明,Latte 在四个标准视频生成数据集(即 FaceForensics、SkyTimelapse、UCF101 和 Taichi-HD)上实现了最先进的性能。此外, Latte也 扩展到文本到视频生成 (T2V) 任务,其中 Latte 取得了与最新 T2V 模型相当的结果。我们坚信,Latte 为未来将 Transformer 纳入视频生成扩散模型的研究提供了宝贵的见解。
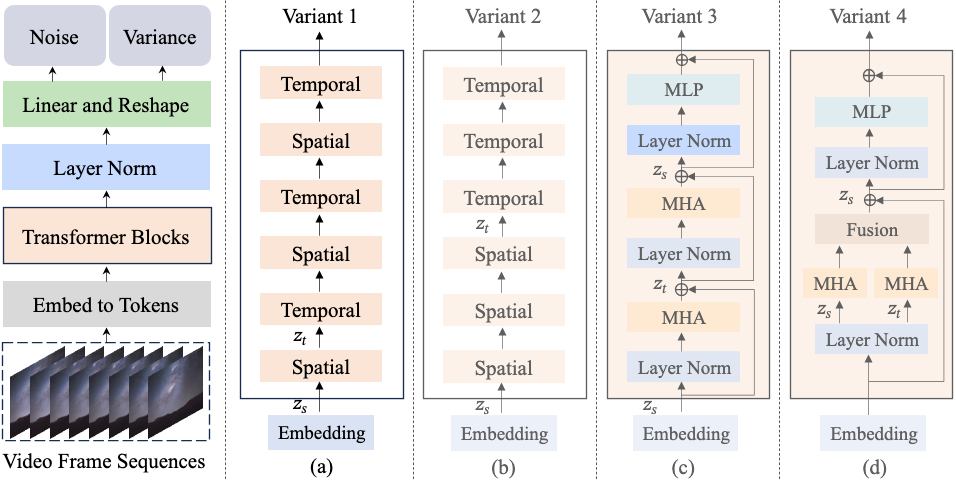
GitHub链接: GitHub - Vchitect/Latte: Latte: Latent Diffusion Transformer for Video Generation.
被Twitter上广泛传播的论文《Scalable diffusion models with transformers》也被认为是Sora技术背后的重要基础。而这项研究的发布遇到了一些坎坷,曾经被CVPR2023拒稿过。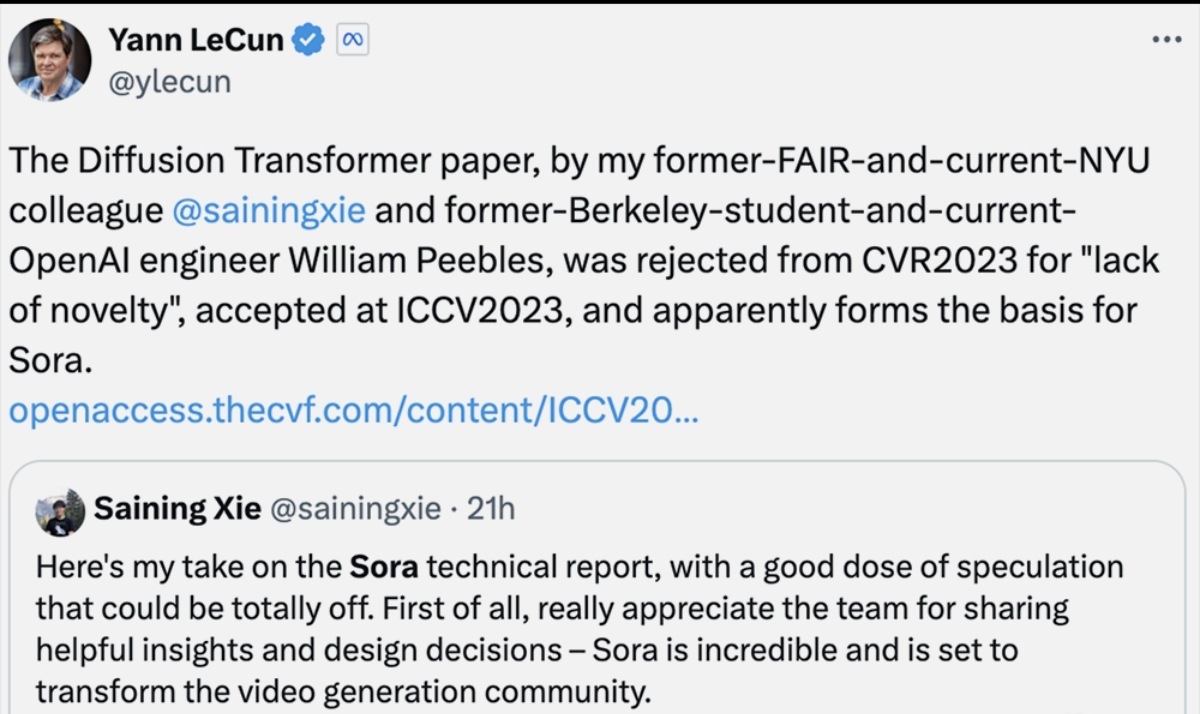
然DiT被拒了,我们看到来自清华大学,人民大学等机构共同研究的CVPR2023的论文U-ViT《All are Worth Words: A ViT Backbone for Diffusion Models》,2022年9月发表,这项研究设计了一个简单而通用的基于vit的架构(U-ViT),替换了U-Net中的卷积神经网络(CNN),用于diffusion模型的图像生成任务。

该项研究现已开源,欢迎大家关注:
GitHub链接: https://github.com/baofff/U-ViT
论文链接:https://arxiv.org/abs/2209.12152
模型链接:https://modelscope.cn/models/thu-ml/imagenet256_uvit_huge
但是,正如作者所说的,Sora将基于Transformers的diffusion model scale up成功,不仅需要对底层算法有专家级理解,还要对整个深度学习工程体系有很好的把握,这项工作相比在学术数据集做出一个可行架构更加困难。
4、声音生成TTS技术解析与实战
韵律建模SAMBERT声学模型

1. Backbone采用Self-Attention-Mechanism(SAM),提升模型建模能力。
2. Encoder部分采用BERT进行初始化,引入更多文本信息,提升合成韵律。
3. Variance Adaptor对音素级别的韵律(基频、能量、时长)轮廓进行粗粒度的预测,再通过decoder进行帧级别细粒度的建模;并在时长预测时考虑到其与基频、能量的关联信息,结合自回归结构,进一步提升韵律自然度.
4. Decoder部分采用PNCA AR-Decoder[@li2020robutrans],自然支持流式合成。
接下来上手一个实践,是来自SambertHifigan个性化语音合成-中文-预训练-16k · 模型库 (modelscope.cn)的案例,数据集可以在此获取
运行TTS-AutoLabel自动标注
from modelscope.tools import run_auto_label
input_wav = "./test_wavs/"
output_data = "./output_training_data/"
ret, report = run_auto_label(input_wav=input_wav, work_dir=output_data, resource_revision="v1.0.7")
基于PTTS-basemodel微调
from modelscope.metainfo import Trainers
from modelscope.trainers import build_trainer
from modelscope.utils.audio.audio_utils import TtsTrainType
pretrained_model_id = 'damo/speech_personal_sambert-hifigan_nsf_tts_zh-cn_pretrain_16k'
dataset_id = "./output_training_data/"
pretrain_work_dir = "./pretrain_work_dir/"
# 训练信息,用于指定需要训练哪个或哪些模型,这里展示AM和Vocoder模型皆进行训练
# 目前支持训练:TtsTrainType.TRAIN_TYPE_SAMBERT, TtsTrainType.TRAIN_TYPE_VOC
# 训练SAMBERT会以模型最新step作为基础进行finetune
train_info = {
TtsTrainType.TRAIN_TYPE_SAMBERT: { # 配置训练AM(sambert)模型
'train_steps': 202, # 训练多少个step
'save_interval_steps': 200, # 每训练多少个step保存一次checkpoint
'log_interval': 10 # 每训练多少个step打印一次训练日志
}
}
# 配置训练参数,指定数据集,临时工作目录和train_info
kwargs = dict(
model=pretrained_model_id, # 指定要finetune的模型
model_revision = "v1.0.6",
work_dir=pretrain_work_dir, # 指定临时工作目录
train_dataset=dataset_id, # 指定数据集id
train_type=train_info # 指定要训练类型及参数
)
trainer = build_trainer(Trainers.speech_kantts_trainer,
default_args=kwargs)
trainer.train()
体验模型合成效果
import os
from modelscope.models.audio.tts import SambertHifigan
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
model_dir = os.path.abspath("./pretrain_work_dir")
custom_infer_abs = {
'voice_name':
'F7',
'am_ckpt':
os.path.join(model_dir, 'tmp_am', 'ckpt'),
'am_config':
os.path.join(model_dir, 'tmp_am', 'config.yaml'),
'voc_ckpt':
os.path.join(model_dir, 'orig_model', 'basemodel_16k', 'hifigan', 'ckpt'),
'voc_config':
os.path.join(model_dir, 'orig_model', 'basemodel_16k', 'hifigan',
'config.yaml'),
'audio_config':
os.path.join(model_dir, 'data', 'audio_config.yaml'),
'se_file':
os.path.join(model_dir, 'data', 'se', 'se.npy')
}
kwargs = {'custom_ckpt': custom_infer_abs}
model_id = SambertHifigan(os.path.join(model_dir, "orig_model"), **kwargs)
inference = pipeline(task=Tasks.text_to_speech, model=model_id)
output = inference(input="今天的天气真不错")
import IPython.display as ipd
ipd.Audio(output["output_wav"], rate=16000)
参考链接
-
sora-tutorial/docs/chapter2/chapter2_2/attention-llm/attention/attention.ipynb at main · datawhalechina/sora-tutorial · GitHub,文中提到的Transformer项目
-
sora-tutorial/docs/chapter2/chapter2_2/attention-llm/llm/llm.ipynb at main · datawhalechina/sora-tutorial · GitHub,文中提到的LLM手搓案例
-
【AI+X组队学习】Sora原理与技术实战:基于Transformers diffusion的 视频生成技术解析+实战介绍】 https://www.bilibili.com/video/BV1px421y7qU/?share_source=copy_web&vd_source=5c57be483caf55b4999079e963ad6eec
-
【AI+X组队学习】Sora原理与技术实战:声音生成TTS技术解析与实战】 https://www.bilibili.com/video/BV1py421i7Ha/?share_source=copy_web&vd_source=5c57be483caf55b4999079e963ad6eec


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









