






本次项目网页url
北京新发地: http://www.xinfadi.com.cn/priceDetail.html
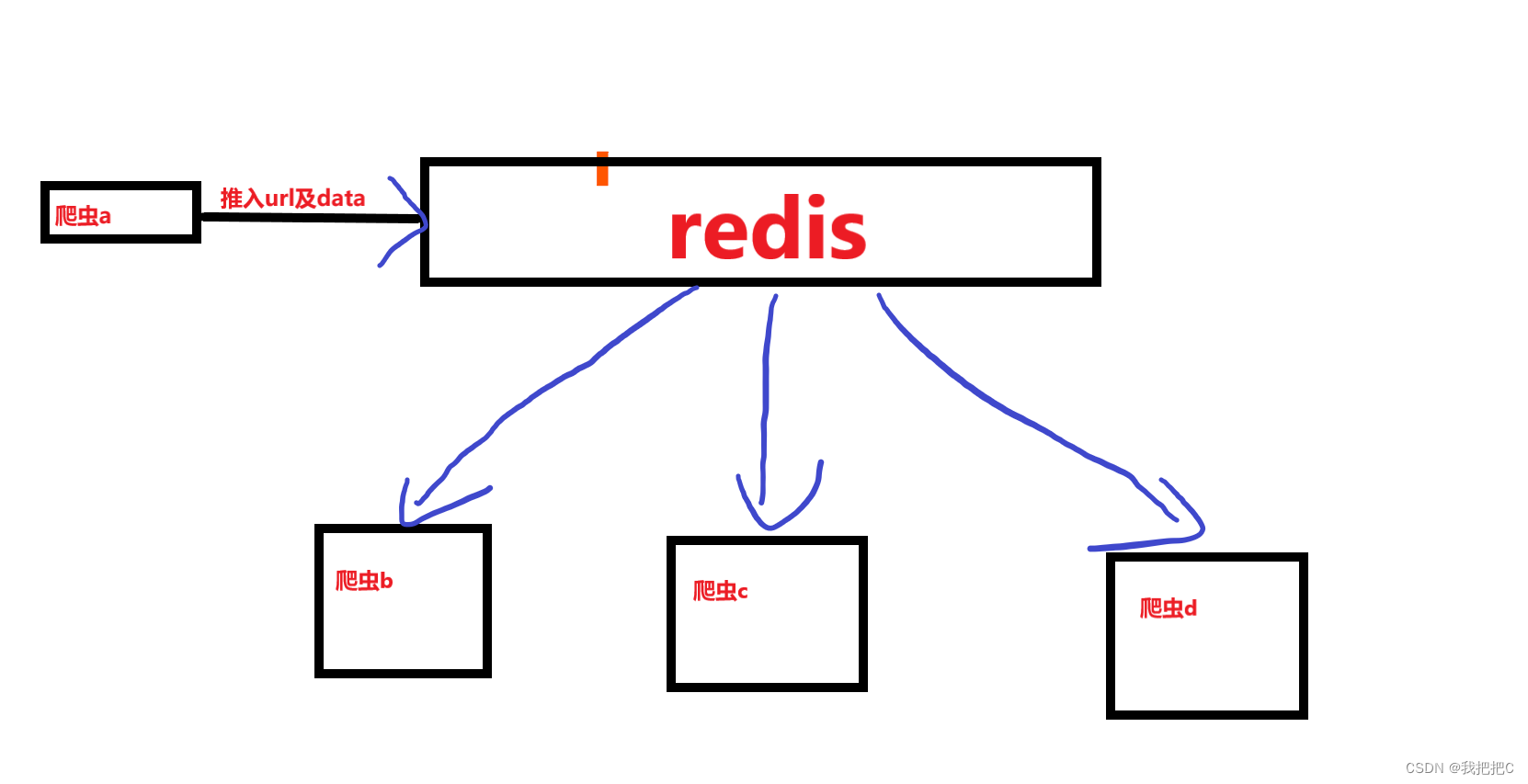
我们首先创建一个爬虫用于收集url与请求的data然后b,c,d使用RedisCrawlSpider来对数据进行分布式爬取
在此篇中我们仅介绍爬虫a
一.获取当天所有菜品数据
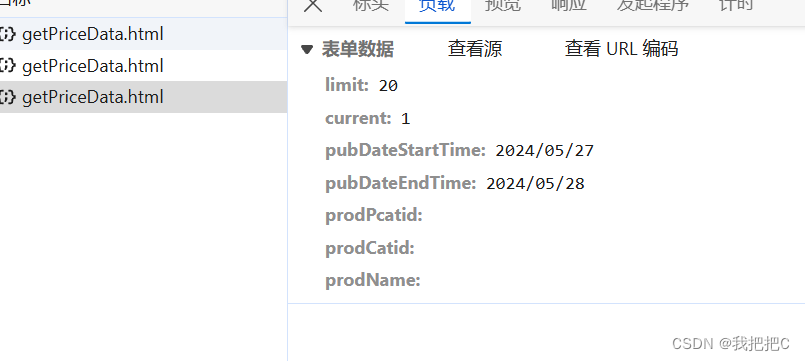
这是一条请求的负载我们只需要对pubDateStartTime和pubDateEndTime进行更改就能够获取指定日期的菜品数据
i = datetime.datetime.now()
endtime=str(i.year)+'/'+"{:02d}".format(i.month)+'/'+"{:02d}".format(i.day)
这两行代码将获取今日日期并将其格式化为我们需要的格式
我们已经搞定了data现在我们发送请求分析数据
data1={
'limit': '20',
'current': '1',
'pubDateStartTime': starttime,
'pubDateEndTime': endtime,
'prodPcatid': '',
'prodCatid': '',
'prodName': ''
}
category = requests.post("http://www.xinfadi.com.cn/getPriceData.html",data=data1).json()
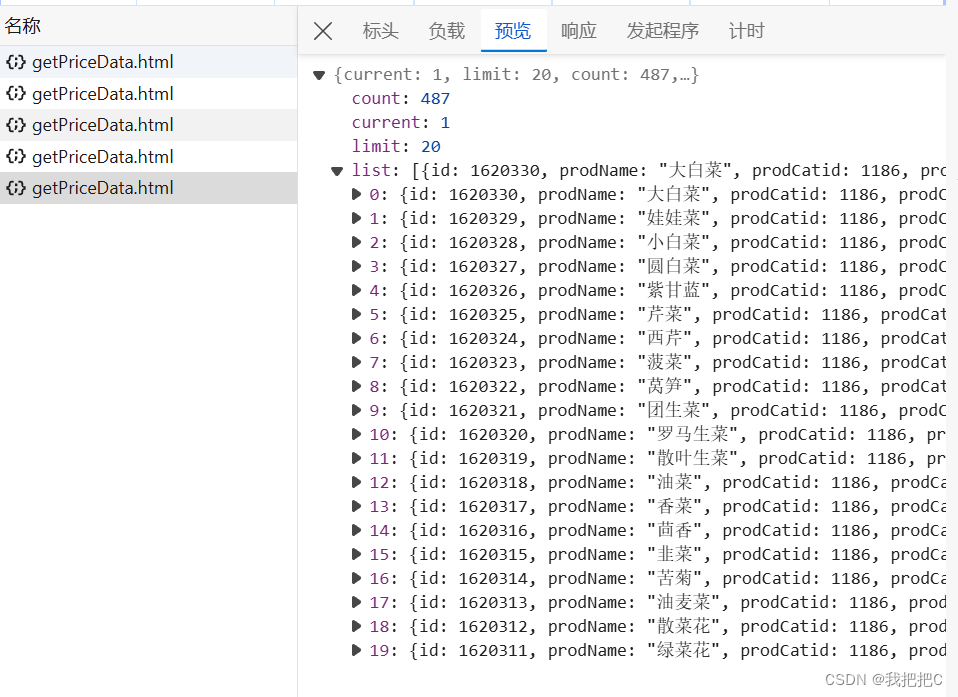
我们将获取到这些数据我们看到只有20条因为我们data中的limit设置为20
在返回的数据中我们可以发现count: 487意味着所有数据为487条所以我们只需要将data中的limit修改为count即可一次请求获取全部数据
二.构建请求用的json数据包并推入redis
我们在上一步已经获取了当日所以菜品信息
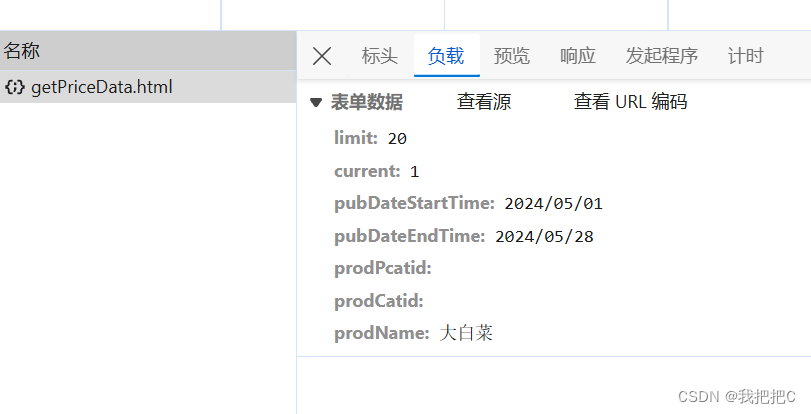
这是我们对大白菜三十天内价格信息进去请求的data其中我们只需要更改limit,time及prodname就可获取我们想要的数据
urls='http://www.xinfadi.com.cn/getPriceData.html'
for i in result["list"]:
print(i)
form_data={
"limit": "999",
"current": "1",
"pubDateStartTime":f"{histytime}",
"pubDateEndTime":f"{endtime}",
"prodPcatid":"",
"prodCatid":"",
"prodName":f"{i['prodName']}"
}
dict={"url":f"{urls}","form_data":f"{json.dumps(form_data)}","meta":""}
v = r.lpush('xinfadi',json.dumps(dict) )
3.源码
import datetime
import json
import requests
import redis
# 建立Redis 链接
r = redis.Redis(host='localhost', port=6379, db=0)
i = datetime.datetime.now()
s=i+datetime.timedelta(days=-1)
h=i+datetime.timedelta(days=-30)
endtime=str(i.year)+'/'+"{:02d}".format(i.month)+'/'+"{:02d}".format(i.day)
starttime=str(s.year)+'/'+"{:02d}".format(s.month)+'/'+"{:02d}".format(s.day)
histytime=str(h.year)+'/'+"{:02d}".format(h.month)+'/'+"{:02d}".format(h.day)
print(starttime,endtime)
data1={
'limit': '20',
'current': '1',
'pubDateStartTime': starttime,
'pubDateEndTime': endtime,
'prodPcatid': '',
'prodCatid': '',
'prodName': ''
}
category = requests.post("http://www.xinfadi.com.cn/getPriceData.html",data=data1).json()
number=category["count"]
print(number)
data1["limit"]=number
result=requests.post("http://www.xinfadi.com.cn/getPriceData.html",data=data1).json()
#print(result)
urls='http://www.xinfadi.com.cn/getPriceData.html'
for i in result["list"]:
print(i)
form_data={
"limit": "999",
"current": "1",
"pubDateStartTime":f"{histytime}",
"pubDateEndTime":f"{endtime}",
"prodPcatid":"",
"prodCatid":"",
"prodName":f"{i['prodName']}"
}
dict={"url":f"{urls}","form_data":f"{json.dumps(form_data)}","meta":""}
v = r.lpush('xinfadi',json.dumps(dict) )
















 2118
2118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











