







数据量不是很多 800W条。
in ( select 字段1 from 视图) 子查询语句, 用时 11秒
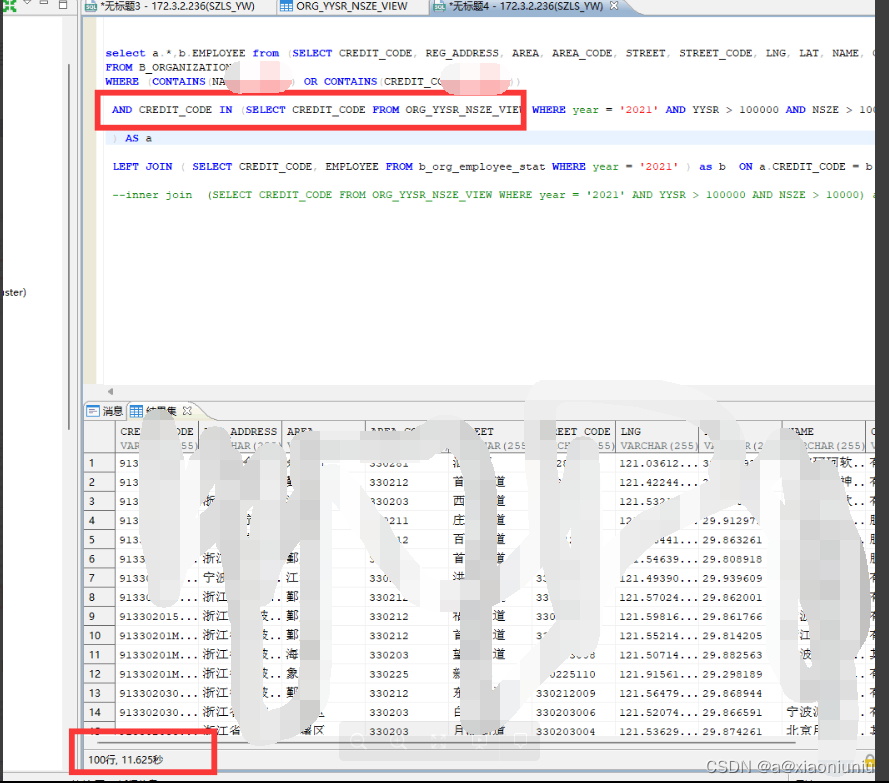
改成 inner join 视图,用时 3秒,
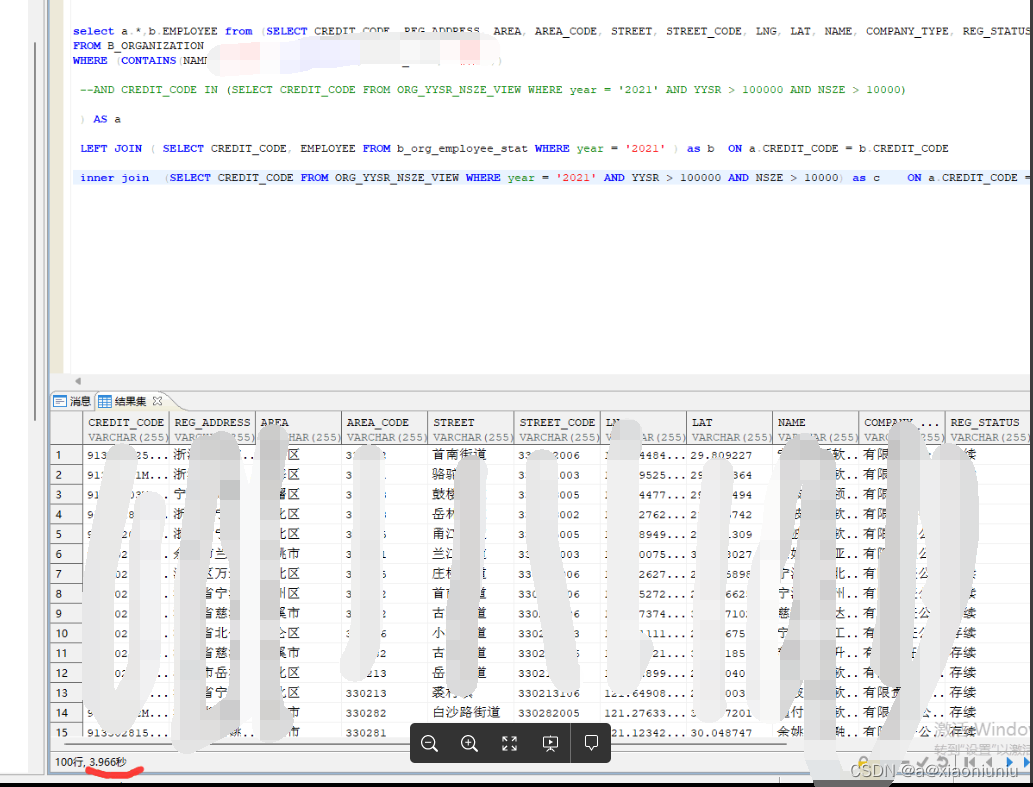
改成 inner join 物理表,关联两次 ,去掉嵌套查询,用时 1秒
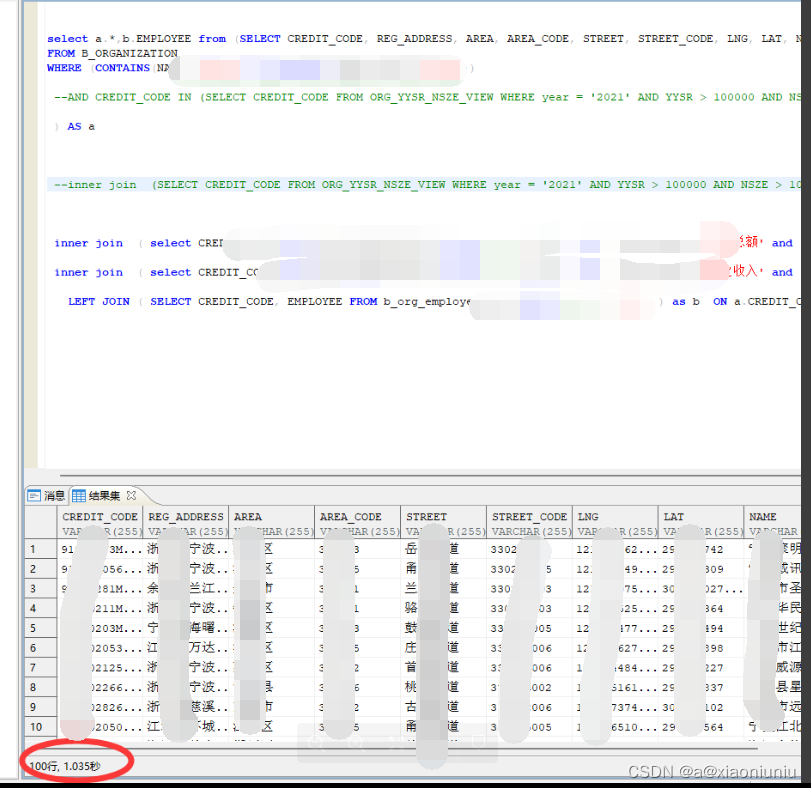
几种写法差异很大,分析原因,具体看执行计划。执行计划是优化的重中之重,我们可以看到语句执行顺序,有没有走索引,检索的数据量等。这里不展开细说。
大致列几点:
1、视图烂用
我们都知道视图是虚拟表,使用视图查询数据时,数据库会从真实表中取出对应的数据。那么再过滤之前他会有一个 生产临时数据过程,如果数据量比较大会消耗过多时间。
2 、索引烂用
建立索引的规划:
- 经常查询的列
- 连接条件列
- 谓词经常出现的列(where)
- 查询是返回表的一小部分数据。
不适合做索引的情况:
- 经常增删的列
- 表的数据量小
- 列上的有大量的null
- 列上的数据有限(例如:报表种 index_name ,它只有5种类型) ,删除此索引后,速度提高了一半
3、 in ( select 语句 少用)
- Inner join 内连接,在两张表进行连接查询时,只保留两张表中完全匹配的结果集,达到和 select in 一样的效果
4、left join 语句
把数据量少的表放到前面,有where条件的尽量放到左边处理















 2168
2168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









