






一、Scrapy框架
1.介绍
Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的开源爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,可以灵活完成各种需求。
2.Scrapy 框架的架构
如下图所示:
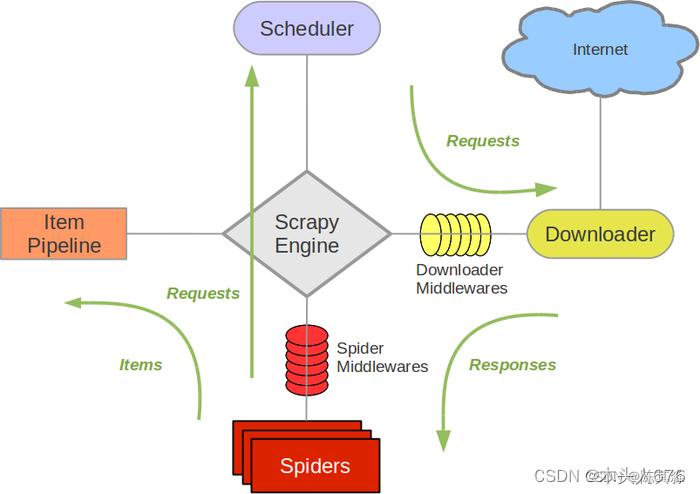
其中各个组件含义如下:
- Scrapy Engine(引擎):负责 Spiders、Item Pipeline、Downloader、Scheduler 之间的通信,包括信号和数据传输等。
- Item(项目):定义爬取结构的数据结构,爬取的数据会被赋值成该对象。
- Scheduler(调度器):负责接收引擎发送过来的 Request 请求,并按照一定的方式进行整理排列和入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载引擎发送的所有 Requests;并将其获取到的 Responses 交还给引擎,由引擎交给 Spider 来处理。
- Spiders(蜘蛛):负责处理所有 Responses,从中分析提取数据,获取 Item 字段需要的数据,并将需要跟进的 URL 提交给引擎,再次进入调度器。
- Item Pipeline(项目管道):负责处理 Spiders 中获取到的 Item 数据,并进行后期处理(比如清洗、验证和存储数据)。
- Downloader Middlewares(下载中间件):是一个可以自定义扩展下载功能的组件,主要是处理引擎与下载器之间的请求及响应。
- Spider Middlewares(蜘蛛中间件):是一个可以自定义扩展 Scrapy Engine 和 Spiders 中间通信的功能组件,主要是处理 Spiders 输入的响应和 Spiders 输出的请求。
3.Scrapy框架工作原理
Scrapy 的工作流程如下:
- 引擎接收到用户定义的初始请求,并将其传递给调度器。
- 调度器将请求排队,并按照一定的策略选择下一个要处理的请求,然后将其发送给下载器。
- 下载器下载网页内容,并将下载到的页面内容返回给引擎。
- 引擎将下载到的页面内容发送给相应的爬虫进行解析,提取出目标数据。
- 爬虫将提取到的数据提交给管道进行后续处理,比如数据清洗、存储等操作。
- 如果有新的请求需要处理,引擎将它们发送给调度器,重复上述过程,直到没有新的请求需要处理为止。
3. 创建新的 Scrapy 项目
要创建一个新的 Scrapy 项目,首先确保你已经安装了 Scrapy。然后在命令行中执行以下命令:
scrapy startproject myproject
这会在当前目录下创建一个名为 myproject 的新项目
执行这些步骤后,你将拥有一个全新的Scrapy项目,可以在其中编写和运行你的爬虫代码。如果你想要创建新的爬虫,可以使用 genspider 命令来生成。例如:
cd myproject
scrapy genspider example example.com 这将在 spiders 目录中创建一个名为 example 的新爬虫,用于爬取 example.com 网站的数据。
4. 项目文件结构及作用
- scrapy.cfg:它是 Scrapy 项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容。
- items.py:它定义了 Item 数据结构,所有 Item 的定义都可以放在这里
- pipeline.py:它定义了 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放在这里
- settings.py:它定义了项目的全局配置
- middlewares.py:它定义了 Spider Middlewares 和 Downloader Middlewares 的实现
- spiders:其内包含了一个个 Spider 的实现,每个 Spider 都有一个文件
二、实践:使用 Scrapy 爬取豆瓣电影 Top250
1.定义数据模型
在 Scrapy 中,我们使用 Item 对象来表示爬取到的数据。为了清晰地组织数据,我们需要定义一个数据模型来描述我们感兴趣的信息。在这个项目中,我们主要关注豆瓣电影 Top250 页面中的电影信息,因此我们创建一个名为 MovieItem 的数据模型来存储这些信息。
# File: your_project/items.py
import scrapy
class MovieItem(scrapy.Item):
# 定义了要爬取的关键信息字段
ranking = scrapy.Field() # 排名
name = scrapy.Field() # 电影名
introduce = scrapy.Field() # 简介
star = scrapy.Field() # 星级
comments = scrapy.Field() # 评论数
describe = scrapy.Field() # 描述2.编写爬虫
在这一部分,我们将创建一个 Spider 来爬取豆瓣电影 Top250 页面中的信息。我们将使用 Scrapy 提供的功能来轻松地提取页面中的数据,并将其存储到先前定义的数据模型中。
# File: your_project/spiders/douban_top250.py
import scrapy
from ..items import MovieItem
class DoubanTop250Spider(scrapy.Spider):
"""
该 Spider 用于爬取豆瓣电影 Top250 页面的信息。
"""
name = 'douban_top250' # Spider 的名称
allowed_domains = ['movie.douban.com'] # 允许爬取的域名
start_urls = ['https://movie.douban.com/top250'] # 起始 URL
def parse(self, response):
"""
解析页面响应,提取电影信息并存储到 MovieItem 对象中
:param response: 爬取到的页面响应
:return: MovieItem 对象
"""
# 使用 XPath 选择器提取电影信息
movies = response.xpath('//div[@class="item"]')
for movie in movies:
item = MovieItem() # 创建 MovieItem 对象来存储电影信息
# 提取电影排名信息
item['ranking'] = movie.xpath('div[@class="pic"]/em/text()').get()
# 提取电影名称
item['name'] = movie.xpath('div[@class="info"]/div[@class="hd"]/a/span[@class="title"]/text()').get()
# 提取电影简介
item['introduce'] = movie.xpath('div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span[@class="inq"]/text()').get()
# 提取电影星级评分
item['star'] = movie.xpath('div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').get()
# 提取电影评论数
item['comments'] = movie.xpath('div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[last()]/text()').get()
# 提取电影描述信息
item['describe'] = movie.xpath('div[@class="info"]/div[@class="bd"]/p[@class=""]/text()').get()
yield item # 将 MovieItem 对象传递给 Scrapy 引擎
# 继续爬取下一页数据
next_page = response.xpath('//span[@class="next"]/a/@href').get()
if next_page:
yield scrapy.Request(response.urljoin(next_page), callback=self.parse)在上述代码中,我们使用了 XPath 选择器来定位 HTML 页面中的元素,并提取我们感兴趣的信息。XPath 是一种用于在 XML 文档中导航和选择节点的语言。通过编写 XPath 表达式,我们可以精确定位到页面中的特定元素,从而提取我们需要的数据。
3.中间件设置
有时为了应对网站的反爬虫机制,我们需要对 Scrapy 的下载中间件进行一些设置,以伪装请求并防止被识别为爬虫。在这个项目中,我们可以通过设置随机的 User-Agent 和使用 IP 代理来模拟不同的用户和 IP 地址发送请求。
首先,我们需要在中间件中添加随机 User-Agent 的设置。我们可以在 middlewares.py 文件中创建一个类,名为 RandomUserAgentMiddleware,用于为每个请求随机选择一个 User-Agent,并将其添加到请求头中。
# File: your_project/middlewares.py
import random
class user_agent(object):
def process_request(self, request, spider):
# user agent 列表
USER_AGENT_LIST = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]
agent = random.choice(USER_AGENT_LIST) # 从上面列表中随机抽取一个代理
request.headers['User-Agent'] = agent # 设置请求头的用户代理在上述代码中,我们创建了一个名为 RandomUserAgentMiddleware 的类,它的 process_request 方法用于处理每个请求,为每个请求随机选择一个 User-Agent,并将其添加到请求头中。其中 USER_AGENT_LIST 是在 settings.py 中定义的用户代理列表。
最后,我们需要在 settings.py 文件中启用这些中间件,并设置它们的优先级:
# File: your_project/settings.py
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.user_agent': 543,
}4.数据存储
当我们选择将数据存储到 CSV 文件中时,我们需要在 Scrapy 项目中编写一个专门的 Pipeline,负责将爬取到的数据写入 CSV 文件中。下面是一个示例:
# File: your_project/pipelines.py
import csv
class CSVPipeline:
"""
Pipeline 类,用于将爬取到的数据存储到 CSV 文件中
"""
def __init__(self, csv_file_path):
"""
初始化方法,设置 CSV 文件路径
"""
self.csv_file_path = csv_file_path
@classmethod
def from_crawler(cls, crawler):
"""
类方法,从 Scrapy 配置中获取 CSV 文件路径
"""
return cls(
csv_file_path=crawler.settings.get('CSV_FILE_PATH')
)
def open_spider(self, spider):
"""
在 Spider 开始爬取时调用,打开 CSV 文件并写入表头
"""
self.csv_file = open(self.csv_file_path, 'w', newline='', encoding='utf-8')
# 创建 CSV 写入器,并写入表头,这里的表头根据 MovieItem 的字段来确定
self.csv_writer = csv.DictWriter(self.csv_file, fieldnames=['ranking', 'name', 'introduce', 'star', 'comments', 'describe'])
self.csv_writer.writeheader()
def close_spider(self, spider):
"""
在 Spider 结束爬取时调用,关闭 CSV 文件
"""
self.csv_file.close()
def process_item(self, item, spider):
"""
处理每个 Item 对象,将其写入 CSV 文件中
"""
# 使用 CSV 写入器将 Item 写入 CSV 文件
self.csv_writer.writerow(item)
return item接下来,我们需要在 Scrapy 项目的 settings.py 文件中设置 CSV 文件的路径:
# File: your_project/settings.py
CSV_FILE_PATH = 'douban_movies.csv'最后,我们需要在 settings.py 中启用该 Pipeline:
# File: your_project/settings.py
ITEM_PIPELINES = {
'your_project.pipelines.CSVPipeline': 300,
}最后只需输入以下代码启动Scrapy就行了:
scrapy crawl douban_top250三、使用正则表达式从电影介绍详情中提取指定信息
1.定义数据模型
对于本项目,我们打算爬取豆瓣电影页面,因此需要定义一个数据模型来存储电影信息。
首先,我们将创建一个名为 ZhengzeItem 的类,该类继承自 Scrapy 的 Item 类。这个类将包含两个字段,在添加完数据模型后,我们需要修改数据管道以适应新的数据模型并存储到 CSV 文件中。以下是对 items.py 和 pipelines.py 文件的修改说明:
import scrapy
class ZhengzeItem(scrapy.Item):
"""
数据模型:定义了爬取电影详情页面所需的字段
Fields:
title (str): 电影标题
parenthesis_content (str): 电影剧情简介中带括号的内容
"""
# 电影标题
title = scrapy.Field()
# 电影剧情简介中带括号的内容
parenthesis_content = scrapy.Field()import csv
class CSVPipeline:
"""
数据管道:将爬取的电影信息存储为 CSV 文件
"""
def __init__(self, settings):
self.settings = settings
self.file = None
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
return cls(settings)
def open_spider(self, spider):
self.file = open(self.settings.get('CSV_FILE_PATH'), 'w', newline='', encoding='utf-8')
self.writer = csv.writer(self.file)
self.writer.writerow(['Title', 'Parenthesis Content'])
def close_spider(self, spider):
if self.file:
self.file.close()
def process_item(self, item, spider):
title = str(item.get('title', ''))
parenthesis_content = str(item.get('parenthesis_content', ''))
self.writer.writerow([title, parenthesis_content])
return item2.编写爬虫
当编写爬虫时,首先要考虑的是如何访问每个电影的详情页面。在这个项目中,我们需要访问豆瓣电影网站上排名前250的电影的详情页面。
正则表达式
当提取电影简介中的括号内内容时,我们需要使用正则表达式来匹配括号中的文本。但是,并非所有电影简介都包含括号,因此我们需要处理这种情况,以避免出现错误。
import re
if synopsis:
# 定义正则表达式来匹配带括号的内容,使用多行模式(re.DOTALL)
parenthesis_pattern = r'(([^)]*))' # 匹配括号内的内容
parenthesis_matches = re.findall(parenthesis_pattern, synopsis, re.DOTALL)
# 对每个匹配到的括号内容字符串调用 strip() 方法去除空格,并生成新的列表
parenthesis_matches_stripped = [match.strip() for match in parenthesis_matches]
else:
parenthesis_matches_stripped = []通过这种方式,我们可以确保在提取电影简介中的括号内内容时,代码能够正确处理各种情况,包括简介为空或简介中没有括号的情况。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









