






前言:聚合查询除了包含简单的聚合函数外(count,sum,avg,max,min),还包含group by 和 having 语句。
-
group by 语句
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
顾名思义:就是把具有相同类型的数据放在一起
用法: group by 列名
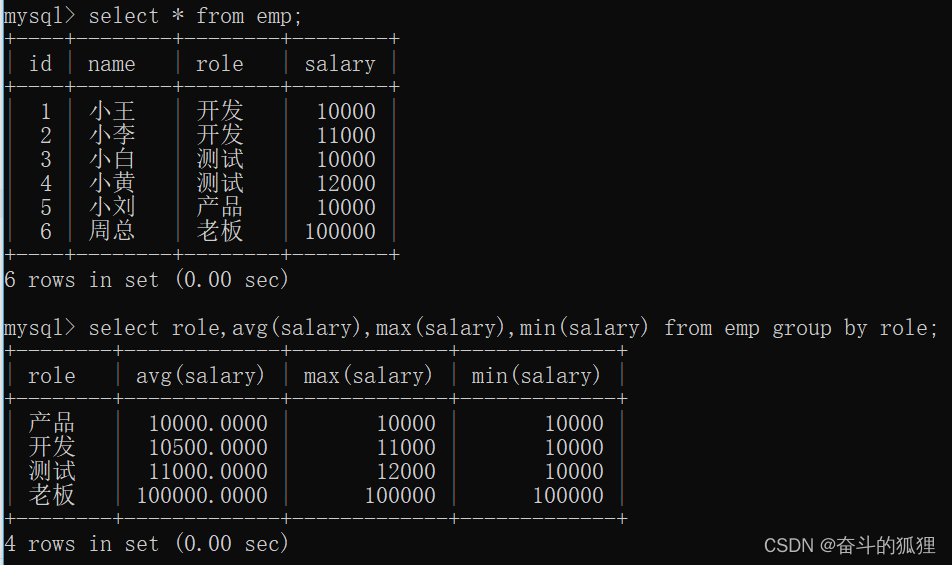
举例:查询每个岗位,最高薪资,最低薪资,以及平均薪资。
具体效果:
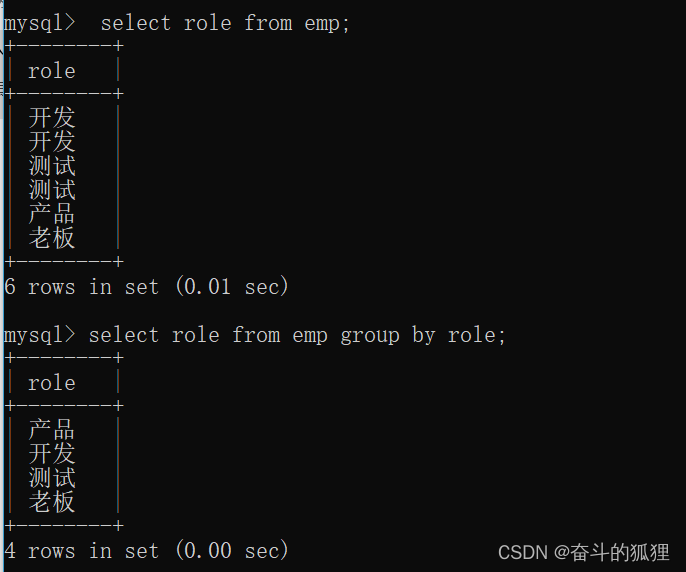
在第二个使用 group by 的表中 :产品(代表一个记录),开发(代表两个记录),测试(代表两个记录),老板(代表一个记录)。
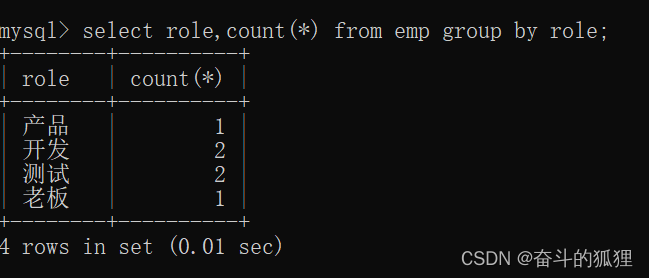
这里使用count(*)便可佐证上述所说。
回到我们最初的问题,查询每个岗位,最高薪资,最低薪资,以及平均薪资:
小插曲:
如果直接使用group by 进行查询(没有搭配聚合函数):
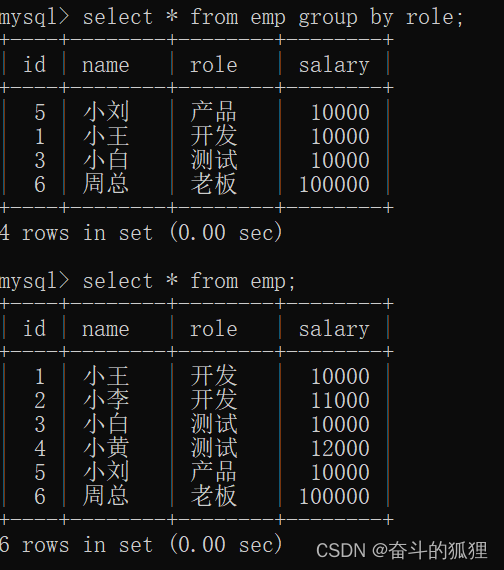
通过观察:第一个表里面的每个记录,其实是相对应每组的第一个记录(开发有两条记录,第一个记录是小王,测试有两条记录,第一个是小白)——这其实是并不合理的。
得出结论:
在进行分组查询的时候,只有用来分组的这一列(role),可以被直接查询(也就是上述的情况),其他的列,则必须搭配聚合函数查询。
Having 语句
group by 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 where 语句,而需要用 having。
前言:通关以下两个案例希望能帮到你:
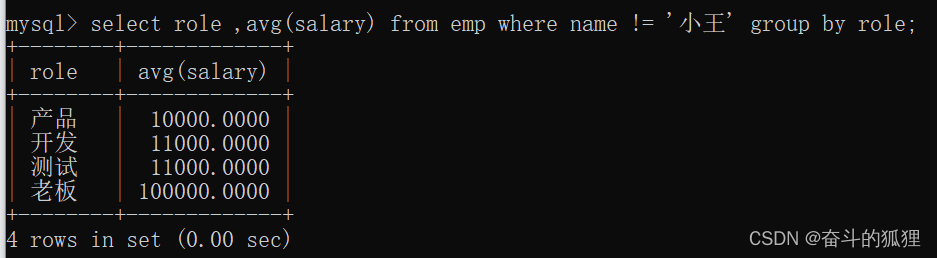
1、查询每个岗位的平均薪资(要求:除去 小王 这个记录) ——先筛选,再进行分组
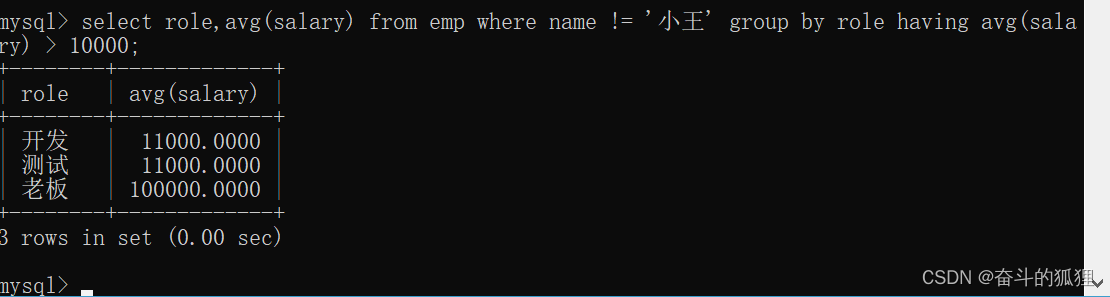
2、查询平均薪资 > 10000 的岗位 ——先分组,再进行筛选
第一个问题:
第二个问题:

当然:having 和 where 是可以共同使用的。——即分组前进行筛选,分组后进行筛选。
问:除小王以外,每个人的平均薪资,以及薪资大于10000的岗位。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









