






一、什么是泛型?
一般的类和方法,只能使用具体的类型,要么是基本类型,要么是自定义类型。如果要编写可以应用于多种类型的代码,这种刻板的限制对代码的束缚就会很大。——《Java编程思想》
泛型是JDK1.5引入的新的语法,通俗来说,泛型:就是适用于多种类型,即对类型实现了参数化。Ps:泛型这种机制会在编译时期进行类型的检查和转换。
二、泛型的应用场景
在有些时候,我们可能需要实现一个类,类中有一个数组,我们需要让数组可以存放任意类型的数据。这时候应该如何去做呢?
在不认识泛型的情况下,可能有人会说:那我们把数组定义为Object数组就好了(因为所有类默认都继承于这个类)
但是真的可以吗?我们来看下面代码:
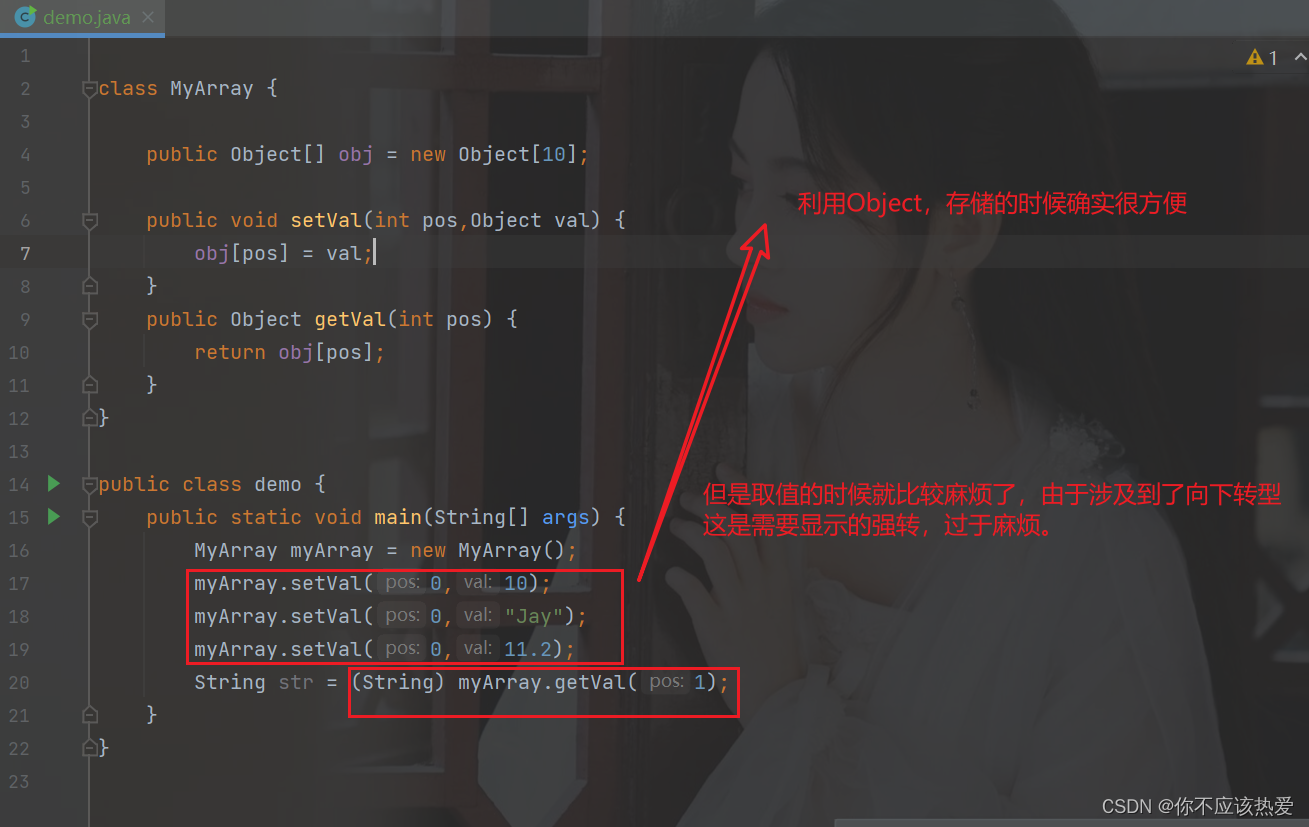
分析:
虽然在这种情况下,当前数组任何数据都能存放, 但是,更多情况下,我们还是希望他只能狗持有一种数据类型,而不是同时持有这么多类型,所以,泛型的主要目的:就是指定当前的容器,要持有什么类型的对象。让编译器取做检查。此时,就需要把类型,作为参数传递,需要什么类型,就传入什么类型。
这是我们就需要引入泛型了:
2.1 泛型的语法
class 泛型类名称<类型形参列表> {
// 这里可以使用类型参数
}
class ClassName<T1, T2, ..., Tn> {
}
class 泛型类名称<类型形参列表> extends 继承类/* 这里可以使用类型参数 */ {
// 这里可以使用类型参数
}
class ClassName<T1, T2, ..., Tn> extends ParentClass<T1> {
// 可以只使用部分类型参数
}代码实例:
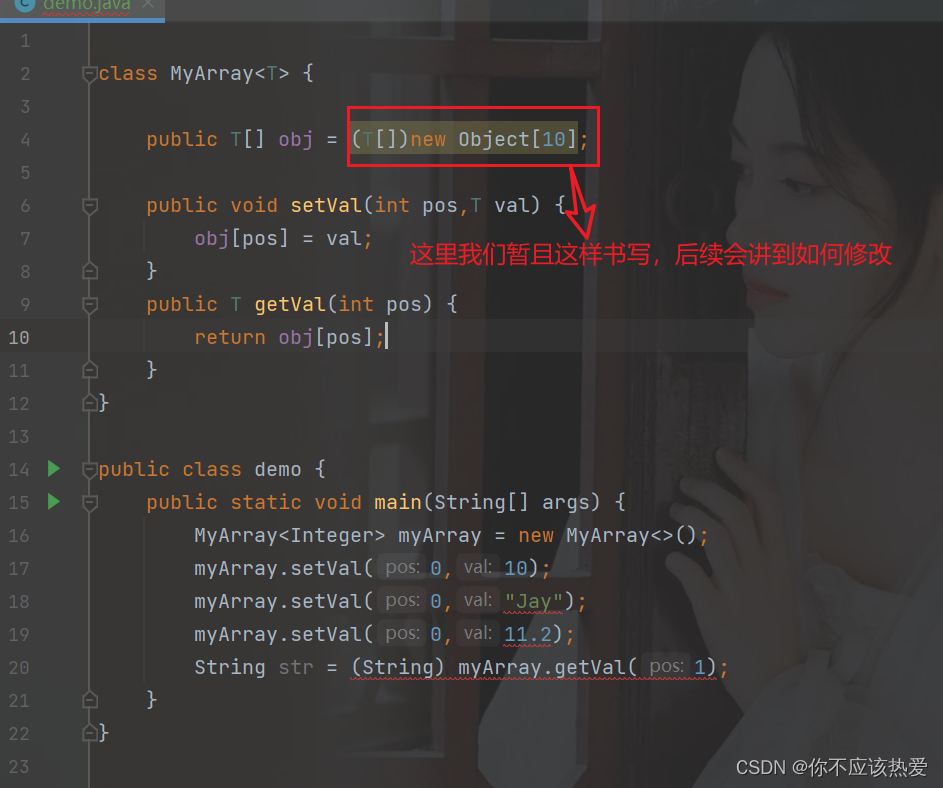
分析:
- 类名后的 <T> 代表占位符,表示当前类是一个泛型类。
- 类型后加入 <Integer> 指定当前类型,这里的类型必须是类类型,不能是基本类型。
- 我们会发现运用泛型:不需要进行强制类型转换。
- 如果存储类型和指定类型不一致,代码编译会报错,这是因为编译器会在存放元素的时候帮助我们进行类型检查。
利用泛型后,我们可以实现类型的参数化:

小结:
泛型存在的最大两个意义:
①存放元素的时候会进行类型的检查
②取出元素的时候,会自动帮你进行类型转换(不需要再进行类型的强转)
泛型主要是编译时期的一种机制(擦除机制),运行时期是没有泛型的概念的。
2.2 泛型类的使用
2.2.1 语法
泛型类<类型实参> 变量名; // 定义一个泛型类引用
new 泛型类<类型实参>(构造方法实参); // 实例化一个泛型类对象2.2.2 实例
MyArray<Integer> list = new MyArray<Integer>();注意泛型只能接受类类型,所有基本数据类型必须使用包装类。
当然这里后面的构造方法实参其实是可以省略不写的:
MyArray<Integer> list = new MyArray<>();2.2.3 裸类型(Raw Type)——了解即可
"裸类型"(raw types)通常是指在使用泛型之前的一种方式,其中集合类或类似的数据结构存储的是Object类型的对象。这种方式是为了与旧版Java代码兼容,但它没有明确指定泛型类型参数。例如 MyArrayList 就是一个裸类型:
MyArray list = new MyArray();这是旧版代码,使用裸类型:
Box box = new Box(); // 使用裸类型,不指定具体的类型参数
box.set("Hello"); // 存入字符串
String content = (String) box.get(); // 从盒子中获取数据,需要强制类型转换在上面的代码中,Box 类使用裸类型,没有指定类型参数 T,因此在存入数据和取出数据时需要进行强制类型转换。这种做法在旧版的Java中是可以的,但容易引入类型安全问题。
注意: 我们不要自己去使用裸类型,裸类型是为了兼容老版本的 API 保留的机制
下面的类型擦除部分,我们也会讲到编译器是如何使用裸类型的。
2.3 擦除机制
通过命令: javap -c 查看字节码文件,所有的T都是Object。

在编译的过程当中,这种讲所有的T都替换为Object这种机制,我们称之为:擦除机制。
注意:Java的泛型机制是在编译期间实现的。编译器生成的字节码在运行期间并不包含泛型的类型信息。
三、泛型的上界
在讲解泛型的上界之前,我们先来思考一个问题:
写一个泛型类,类中有一个方法,求这个数组中的最大值该如何去做?
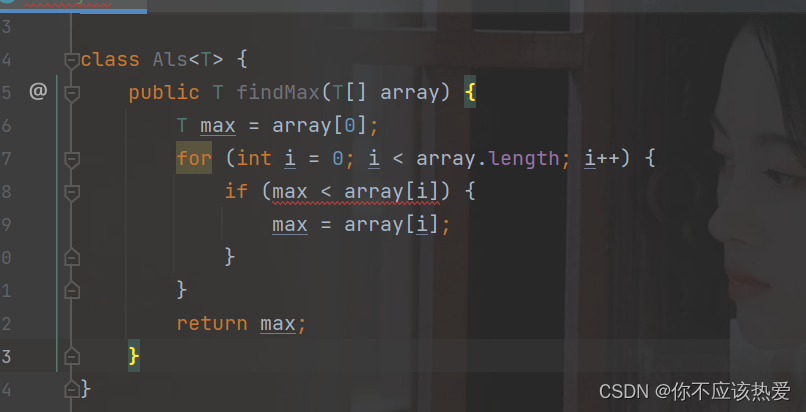
很显然,这种方式是错误的,因为无法确认传入的类型到底是什么,所以不能利用这种简单粗暴的方式进行比较,那应该如何去做呢?
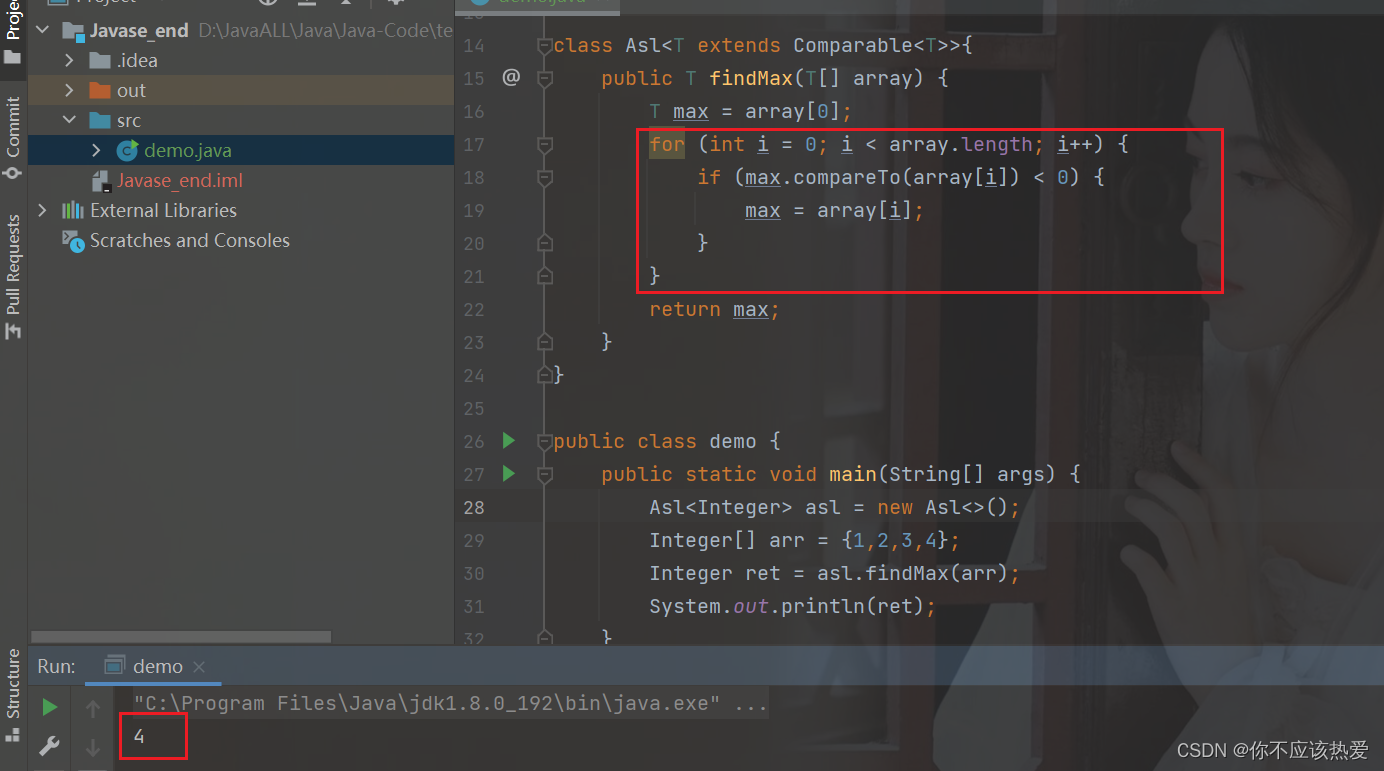
如果当前数组传入给Asl这个泛型类的类型是Integer这种类型,由于在数组取出的时候会进行自动拆箱(下文会讲解)所以这里不需要重写Compareto方法:
关于Compareto方法的补充:
默认的CompareTo方法是根据对象的自然顺序进行比较的。对于基本数据类型的包装类(如Integer、Double、Character等),默认的CompareTo方法会直接比较它们的数值大小。
对于其他类,如果没有重写CompareTo方法,将会使用默认的比较规则。默认规则是比较对象的内存地址,即比较对象在内存中的存储位置。这意味着,如果两个对象的引用不同,它们被认为是不同的对象,即使它们具有相同的属性值。
如果需要自定义对象的比较规则,可以在类中重写CompareTo方法。在重写方法时,可以根据对象的特定属性来定义比较规则,以确定对象的相对顺序。这样就可以根据需要对对象进行排序或比较。
3.1 语法
在定义泛型类时,有时需要对传入的类型变量做一定的约束,这样可以通过类型边界来进行约束。
刚刚上面我们所使用的其实是一种复杂的泛型上界的运用:
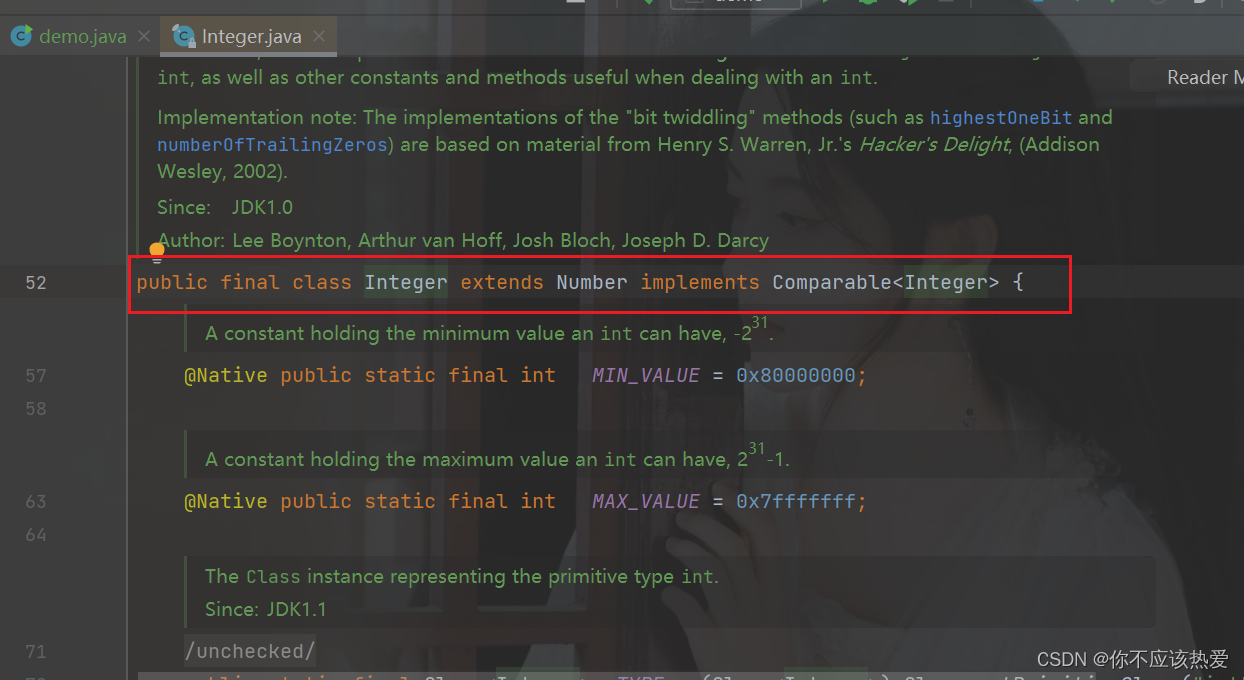
public class MyArray<E extends Comparable<E>> {
...
}其中的 E 必须是 实现这个Comparable<T> 接口的类或其子类。比如我们上面传入的Integer:
以下为泛型上界语法:
class ClassName<T extends UpperBoundType> {
// ...
}
- ClassName是你的泛型类或泛型方法的名称。
- T是泛型类型参数的名称。
- extends关键字用于指定上界。
- UpperBoundType是指定的上界类型,可以是一个类或接口。
- 是哟泛型时,没有指定上界的情况下,在编译时候会由于擦除机制变成Object,如果有上界那么就变成该上界。
需要注意的是:
如果你指定一个类作为上界,那么泛型类型参数必须是该类或其子类。如果你指定一个接口作为上界,那么泛型类型参数必须是实现了该接口的类或其子类。否则将会编译报错。
以下就是自定义类型传入泛型类的情况:
class Asl<T extends Comparable<T>>{
public T findMax(T[] array) {
T max = array[0];
for (int i = 0; i < array.length; i++) {
if (max.compareTo(array[i]) < 0) {
max = array[i];
}
}
return max;
}
}
class Person implements Comparable<Person> {
public int age;
public Person(int age) {
this.age = age;
}
@Override
public int compareTo(Person o) {
return this.age - o.age;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
'}';
}
}
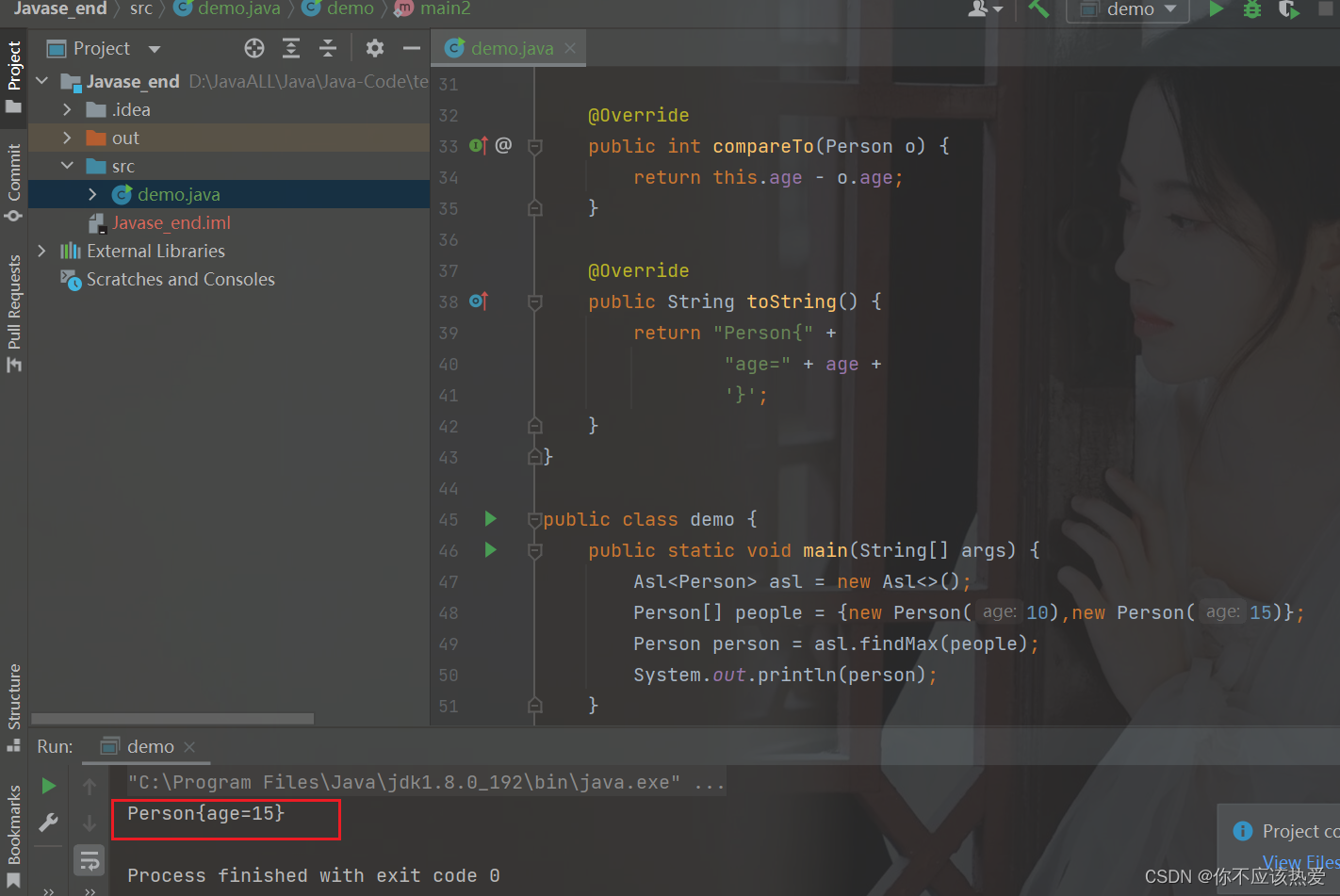
public class demo {
public static void main(String[] args) {
Asl<Person> asl = new Asl<>();
Person[] people = {new Person(10),new Person(15)};
Person person = asl.findMax(people);
System.out.println(person);
}
}运行结果:
分析:这就需要自定义类型实现Comparable接口了,并且需要重写Compareto方法(没有重写的话就默认比较对象的地址了)。
简单示例:
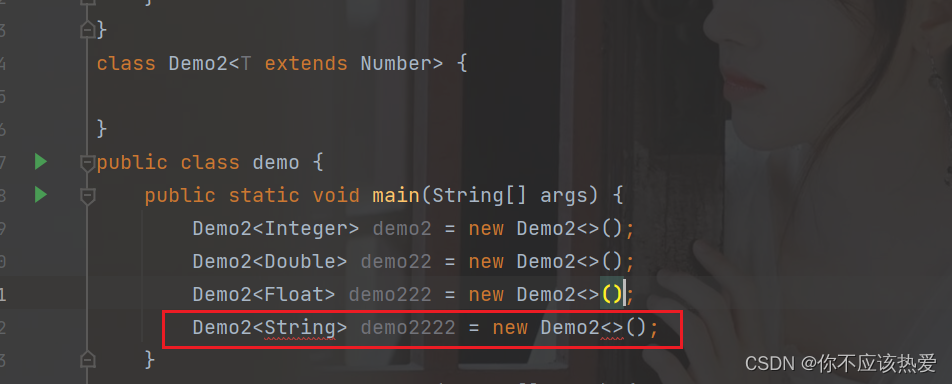
分析:由于String并不是Number的子类,于是编译器会进行报错。
四、泛型的方法
4.1 泛型静态方法
引入:可能有人会说,每次都需要new一下这个泛型类,太麻烦了,能否用static修饰一下,让其变成类方法?
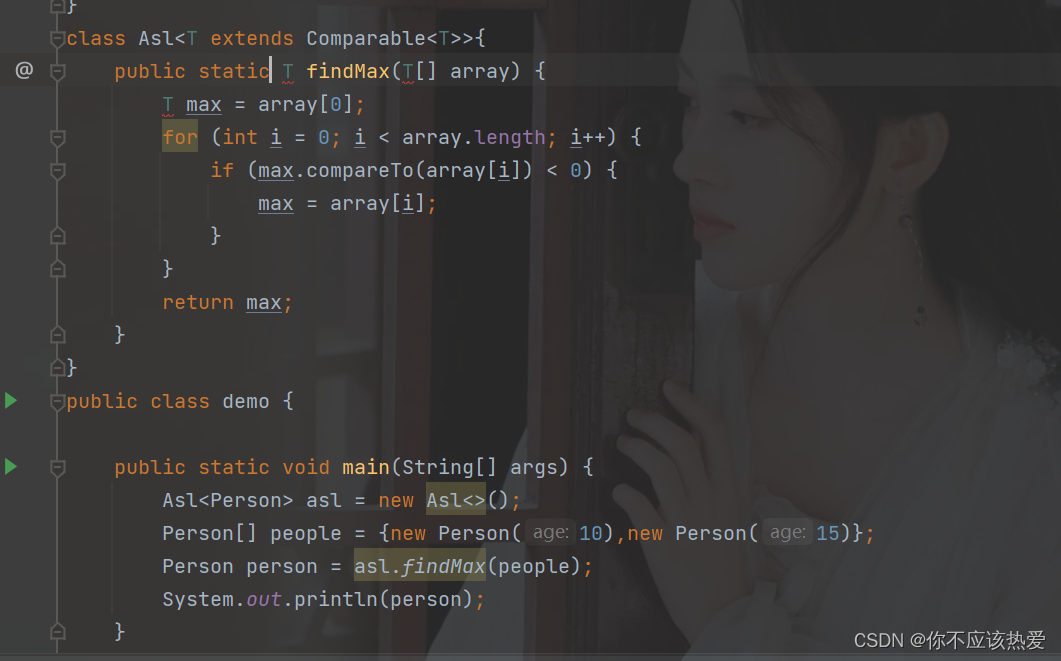
上图所示的这种方式是不行的,因为由于static修饰的方法不依赖于类对象的创建,所以以上面这种方式,这个泛型的类型是无法确认的,所以报错了。
修改方式如下:
class Asl<T extends Comparable<T>>{
public static<T extends Comparable<T>> T findMax(T[] array) {
T max = array[0];
for (int i = 0; i < array.length; i++) {
if (max.compareTo(array[i]) < 0) {
max = array[i];
}
}
return max;
}
}运行代码:
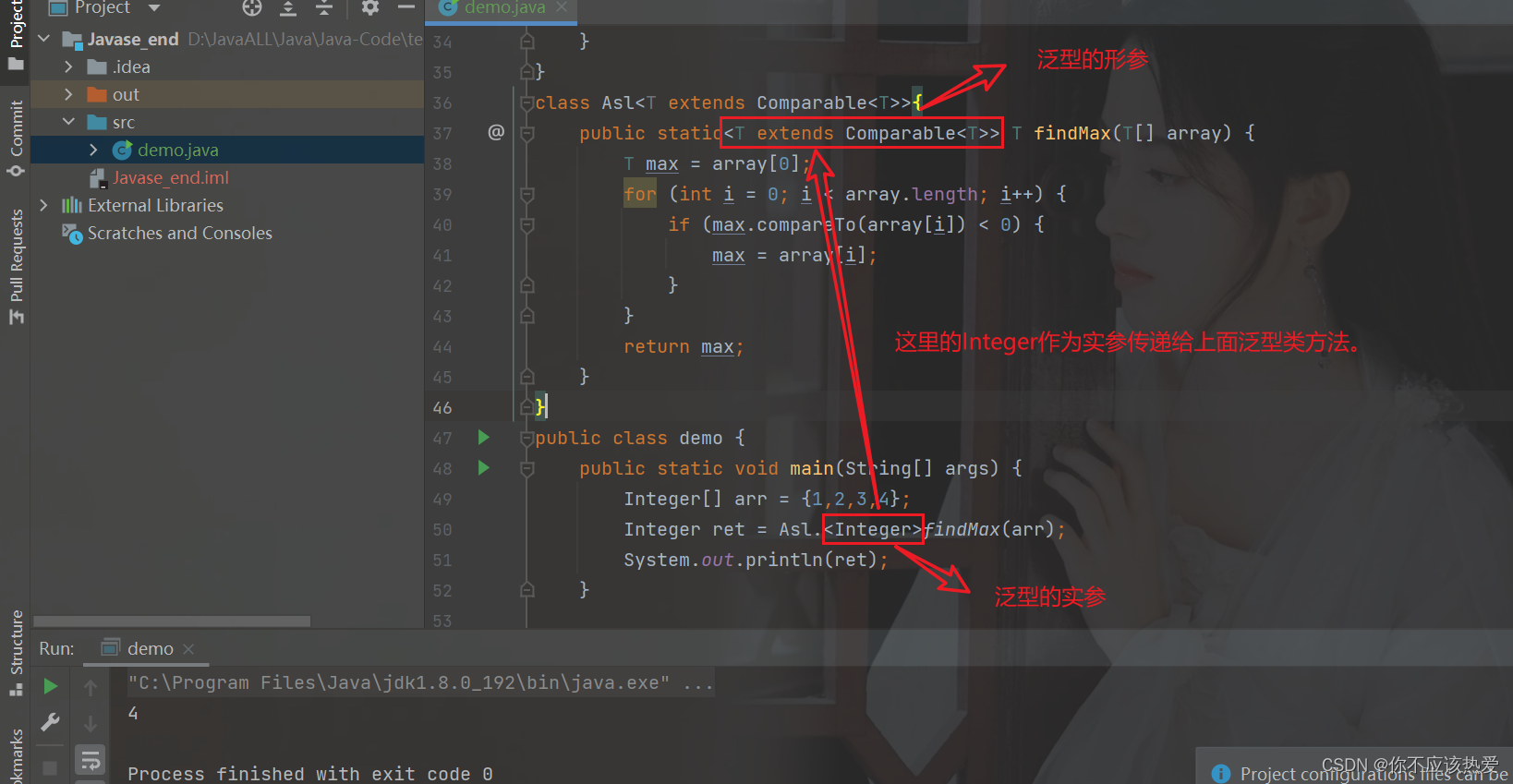
通常会采用下面这种方式,往往这里的实参会忽略不写,Java会根据arr的类型推导出Integer类型。

4.2 泛型方法的另一种写法

五、通配符
? 用于在泛型的使用,即为通配符。
5.1 通配符解决什么问题?
通配符是主要目的是提高代码的灵活性,以便更容易编写通用的、可复用的代码。
同时也解决了泛型无法协变的原因。(下文泛型的上界会提及)
List<? extends Number> ln = new ArrayList<Integer>();泛型 T 是确定的类型,一旦你传了我就定下来了,比如下图,如果是直接使用String的话,那么Integer就无法传入。而通配符则更为灵活或者说是不确定,更多的是用于扩充参数的范围。
观察以下代码:

由于fun方法参数被写死了,所以导致fun方法报错。那么该如何修改呢?
可能有人会说,那么我在写一个fun方法,实现方法的重载不就可以了吗?

其实是不行的,因为其实在编译器角度来看,这两个其实是相同的方法,可以通过以下代码验证:

分析:
可以看到两个类名其实是一样的,代码编译器并不会因为传入的类型不同而将其看出两种不同的参数,所以不能构成方法的重载。
Ps:没有重写toString方法,那么默认的toString方法会返回一个由类名、"@"和对象的哈希码组成的字符串。这个哈希码是通过hashCode()方法生成的。
引入通配符来解决

运行结果:
需要注意的是:虽然可以利用通配符解决上述问题,但是并不是设置其中的值。
这是因为:在使用 ?时,由于不确定类型,所以无法修改。

5.2 通配符的上界
通配符也有上界,可以限制传入的类型必须是上界这个类或者是这个类的子类。
语法:
<? extends 上界>
<? extends Number>//可以传入的实参类型是Number或者Number的子类 示意图如下:
示例:
class Food {
}
class Fruit extends Food {
}
class Apple extends Fruit {
}
class Banana extends Fruit {
}
class Plate<T> { // 设置泛型
private T plate ;
public T getPlate() {
return plate;
}
public void setPlate(T plate) {
this.plate = plate;
}
}
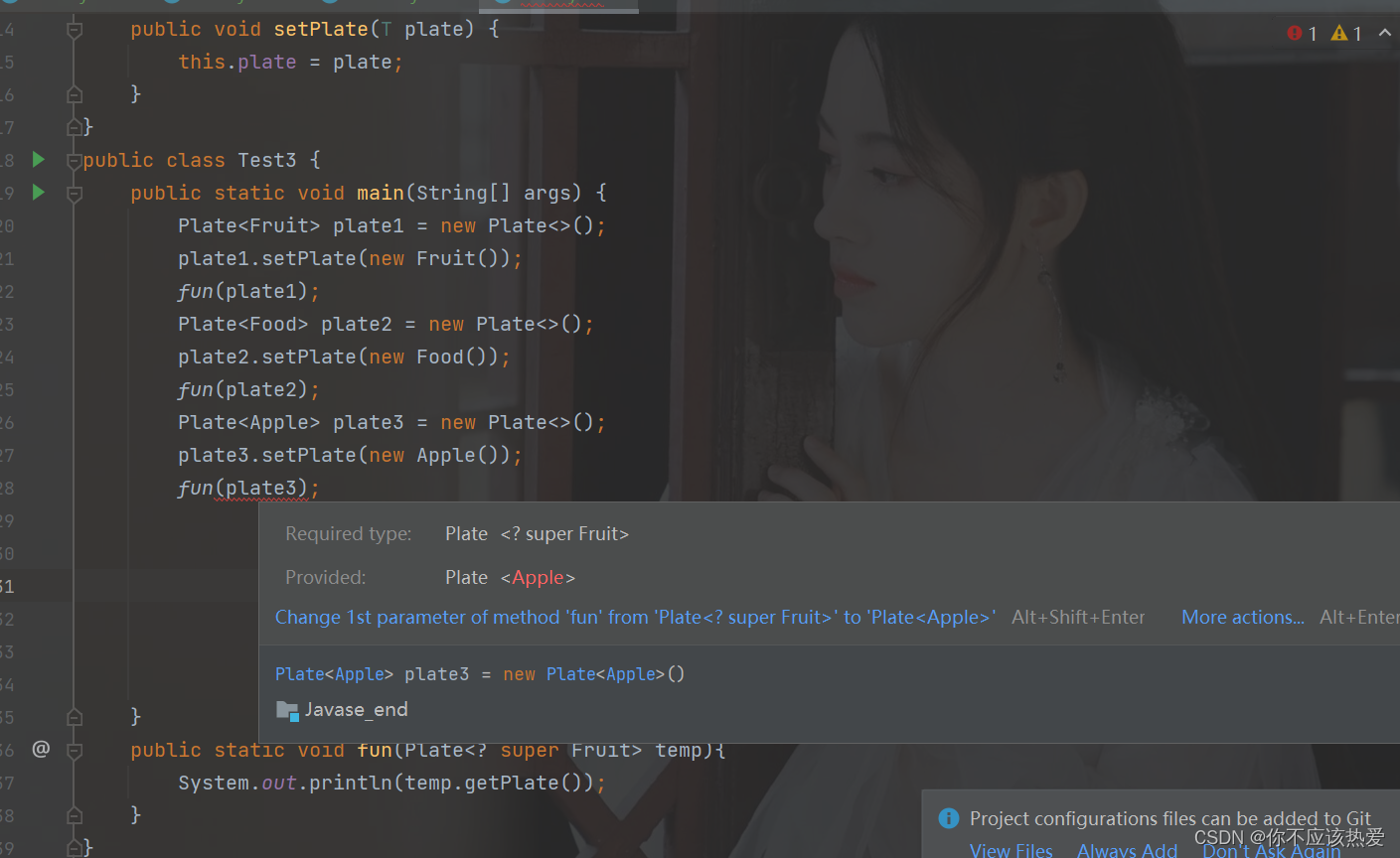
public class Test3 {
public static void main(String[] args) {
Plate<Apple> plate1 = new Plate<>();
plate1.setPlate(new Apple());
fun(plate1);
Plate<Banana> plate2 = new Plate<>();
plate2.setPlate(new Banana());
fun(plate2);
}
public static void fun(Plate<? extends Fruit> temp){
System.out.println(temp.getPlate());
}
}
这里由于通配符的存在,解决了泛型无法协变的原因:Plate<Apple> plate1可以传递给Plate<? extends Fruit>。

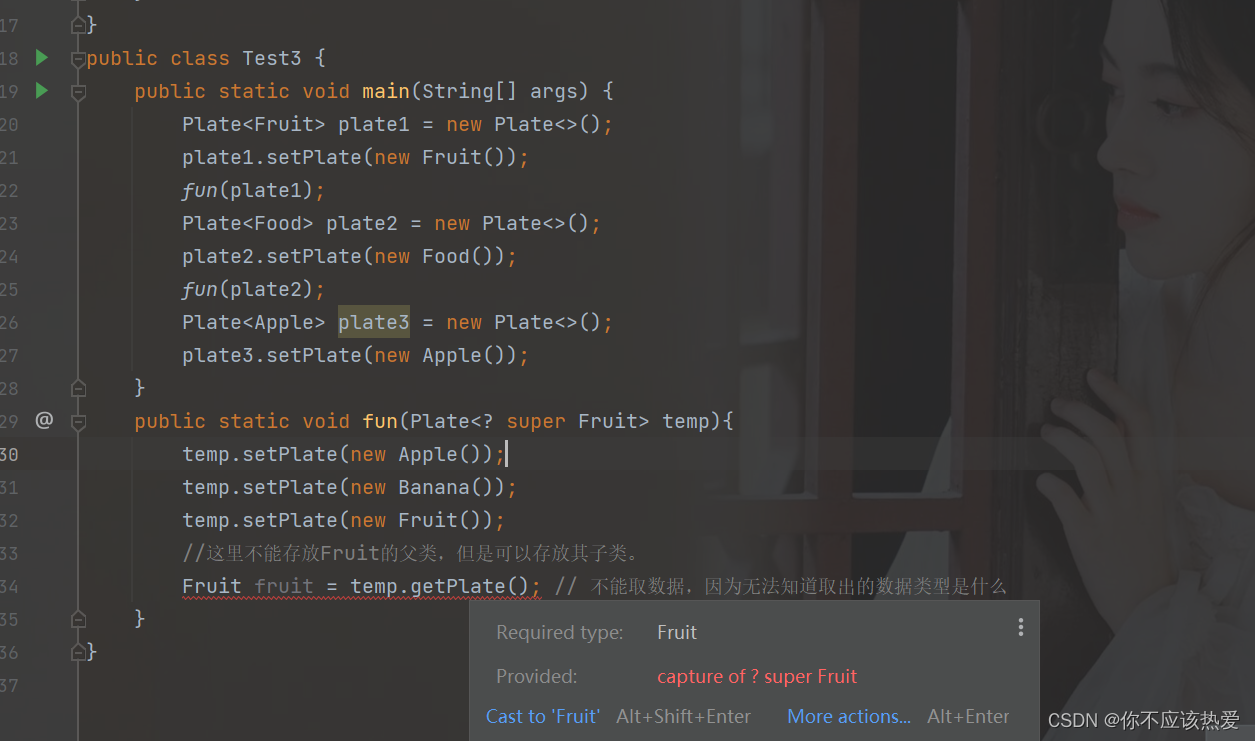
分析:观察以上代码,在使用 ? extends E时,并不知道什么对象符合那个未知的E的子类型,所以无法支持写入,但是由于通配符解决了泛型无法协变的问题,所以这里可以进行接收。但是在方法内部无法进行设置。
另外,虽然无法进行修改,但是可以取里面的数据:
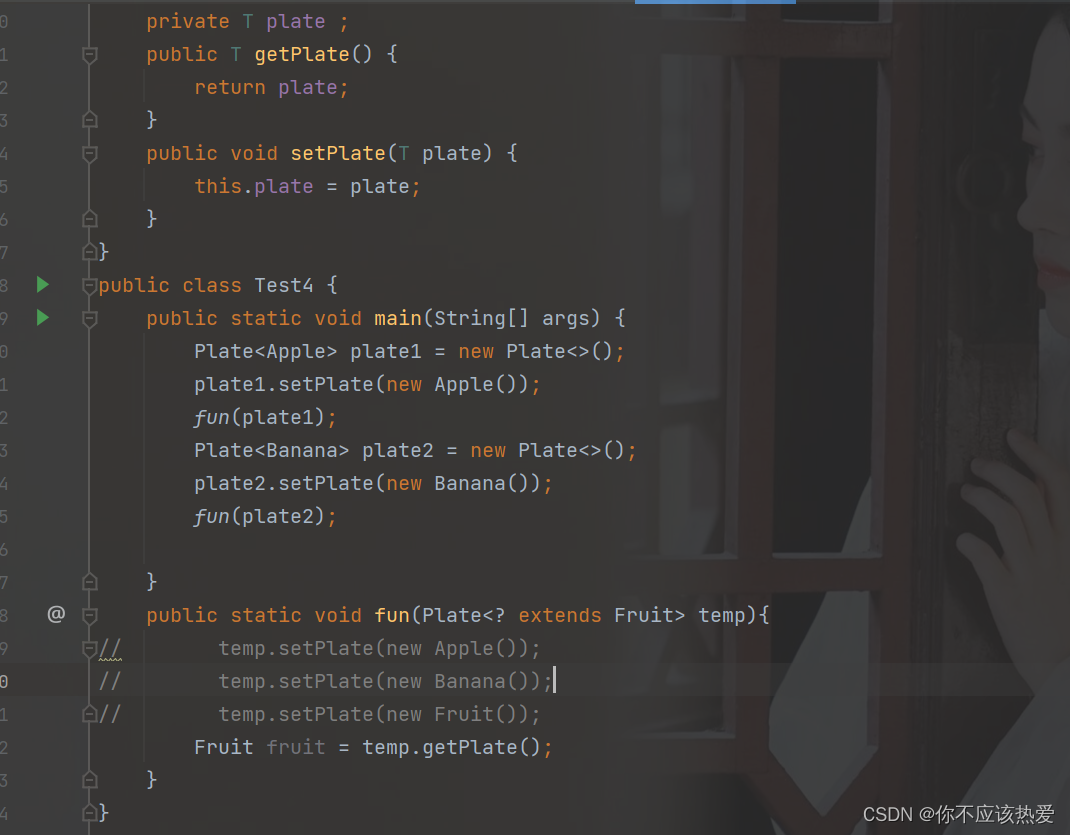
这是因为通配符上界限制了传递进来的参数必须是Fruit或者其子类。
结论:
使用通配符上界可以读取数据,这是因为读取的对象一定是Furit或者是其子类,但是并不适合写入数据,因为不能确定类所持有的对象具体是什么,为了安全,使用通配符上界不能进行写入。
这里的思想跟泛型上界差不多,可以配合理解:
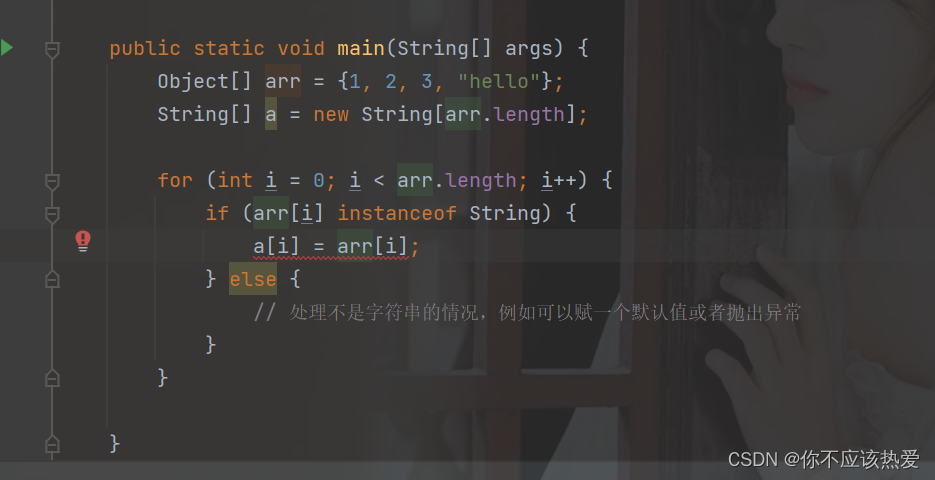
数据存入到Object数组中时,由于Object是所有类的父类,在存入的时候都是可以存的,但是在取出的时候,由于是Object数组,在赋值给String类型数组时候还是需要进行强制类型转换->转换为String类型的值。
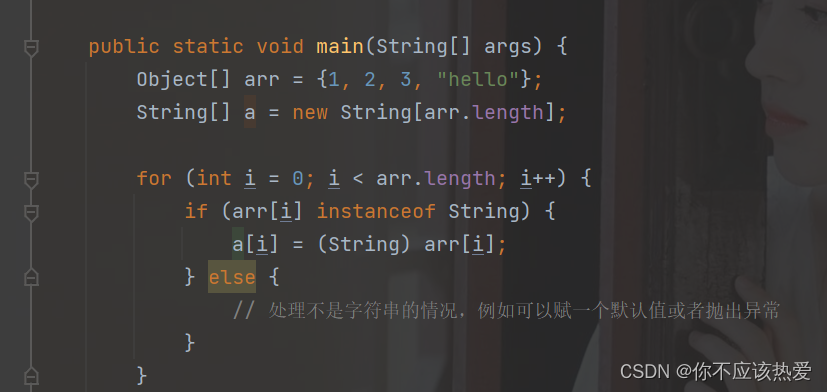
5.2 通配符的下界
与泛型不同,通配符可以拥有下界,语法层面上与通配符的上界的区别是把关键字extends改为super。
语法
<? super 下界>
<? super Integer> //代表 可以传入的实参的类型是Integer或者Integer的父类类型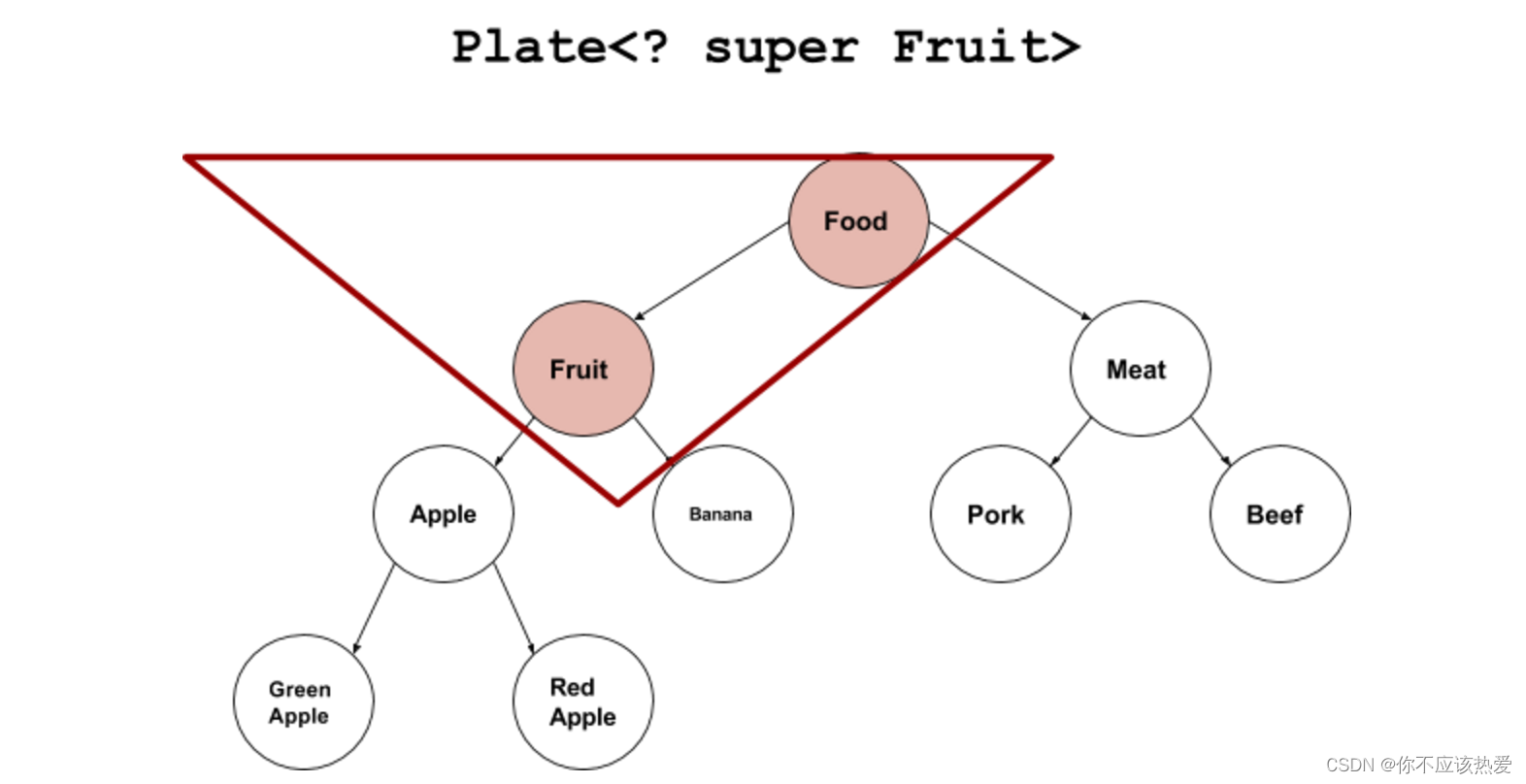
示例:
分析:由于下界是Fruit,所以只能传递Fruit类或者其父类。 如果传递的非这两个,就会编译报错。
结论:
使用通配符下界可以写数据,当然能够写入的数据对象是下界以及下界的子类,但是不能读取数据,因为无法确认取出的数据是什么。
六、包装类
在Java中,由于基本类型不是继承自Object,为了在泛型代码中可以支持基本类型,Java给每个基本类型都对应了一个包装类型。
6.1 基本数据类型和对应的包装类
| 基本数据类型 | 包装类 |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
除了 Integer 和 Character, 其余基本类型的包装类都是首字母大写。
6.2 装箱和拆箱
装箱(装包):将基本数据类型变成对应的包装类型。
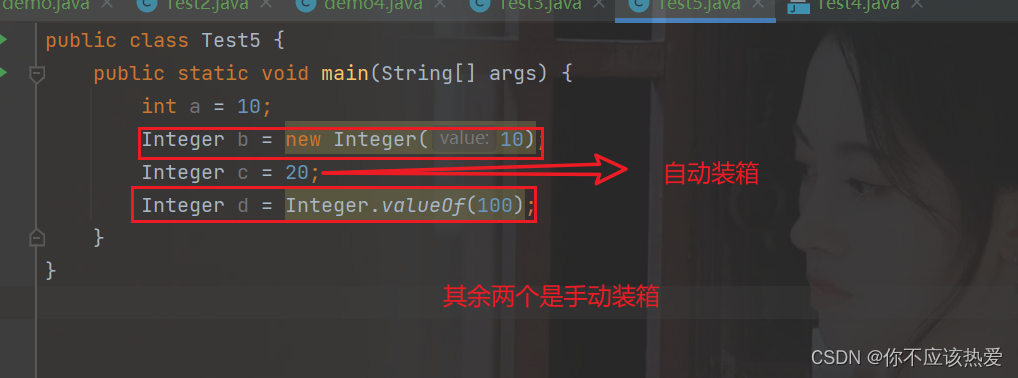
我们可以查看字节码文件来验证:
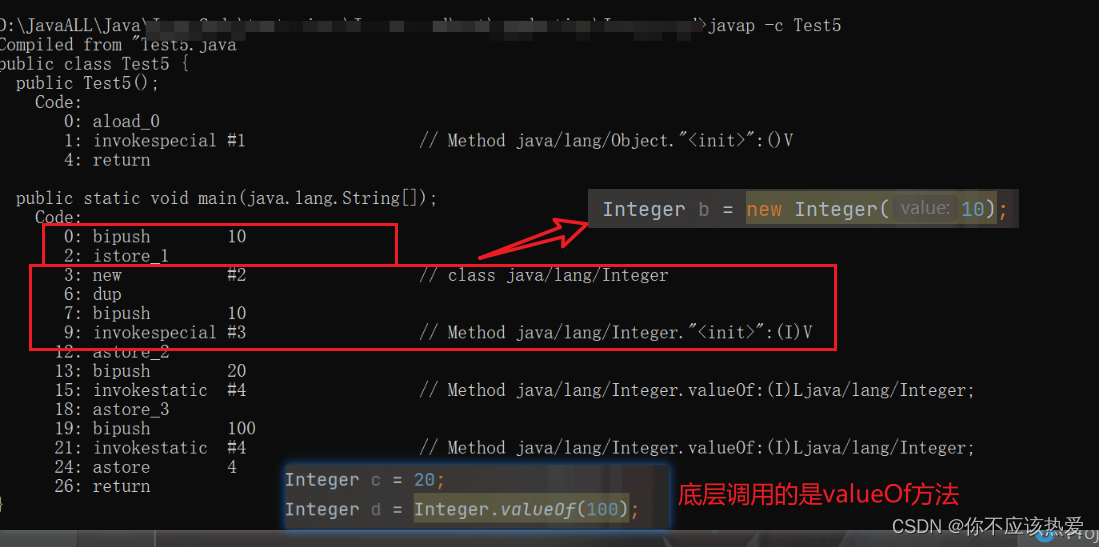
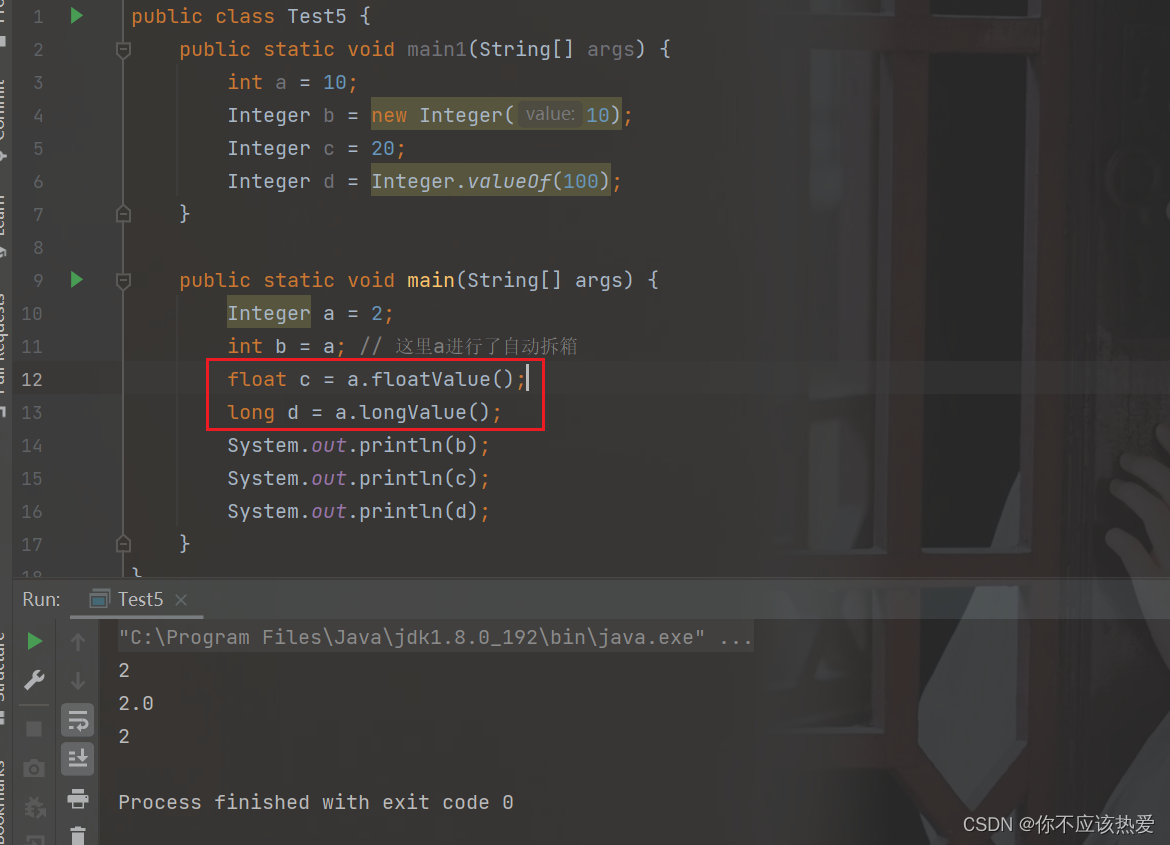
拆箱(拆包):将包装类型转换为基本数据类型。

观察字节码文件可以知道,int b = a 是调用了intValue进行拆箱。

当然我们可以进行显示的拆箱操作:
6.3 关于Integer的经典面试题
观察以下代码,思考运行结果是什么?
public class Test6 {
public static void main(String[] args) {
Integer a = 100;
Integer b = 100;
Integer c = 200;
Integer d = 200;
System.out.println(a == b);
System.out.println(c == d);
}
}
运行结果如下:
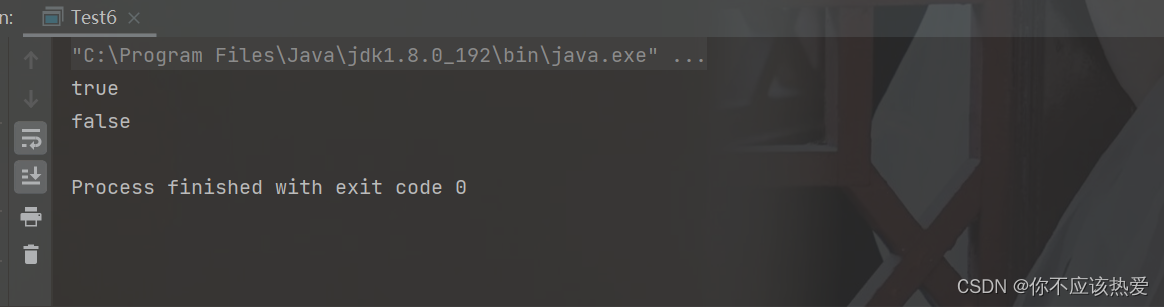
为什么呢?
这是因为涉及到了装箱的问题,从上面我们可以得知,Integer a = 10 会进行自动装箱,相当于是调用了valueOf方法,我们来看看valueOf方法的内部实现:


我们可以得知,Integer的值如果是 -128到 127 之间的话
否则会重新new一个对象,当然地址就不一样了。
也就是说如果值在这个范围的话就会返回这里数组中的值,如果是-128那么就返回这个数组的第0项。(-128+(- (- 128)))= 0。















 108
108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









