







Java开发 - 尚硅谷JDBC学习笔记
- 序言
- 请认真看代码块里的注释,这个是帮助理解代码和原理的最有用的文字
- 一、JDBC技术概念
- 二、JDBC核心API
- 三、JDBC扩展提示
- 四、Druid连接池技术
- 五、JDBC使用优化以及工具类封装
- 六、基于CMS项目的JDBC实战练习
序言
请认真看代码块里的注释,这个是帮助理解代码和原理的最有用的文字
- 一些有关的jar包在我提供的压缩包里的”资料“文件夹里
- Bilibili视频网址:尚硅谷JDBC实战教程(一套掌握jdbc,JDK17+MySQL8)
- 课程笔记网址:尚硅谷全新8.x基本JDBC数据库连接技术
- 本人会基于视频的学习,在此之上加上自己的理解
- 编号优先级顺序:(从上到下 - 优先级逐渐降低)
- 一 、
- (一)
-
- (1)
- 1)
- A.
- a.
- I. / II. / III. / IV.
- …
一、JDBC技术概念
(零)从USB的角度来引入JDBC
1.USB技术介绍

2.USB技术演示

3.USB技术总结

(一)JDBC技术概念和理解
1.JDBC技术理解
(1)JDBC技术介绍
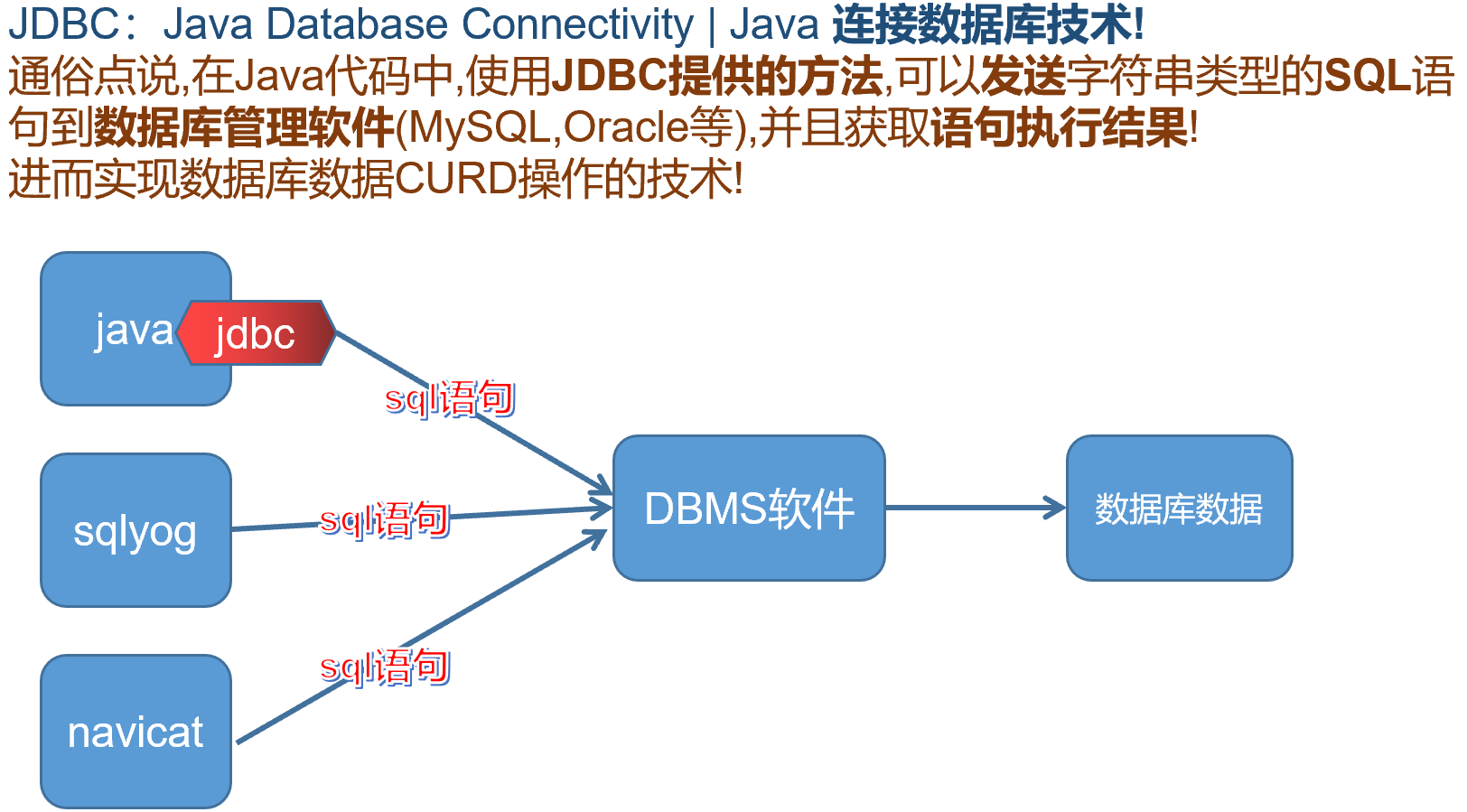
(2)JDBC技术演示
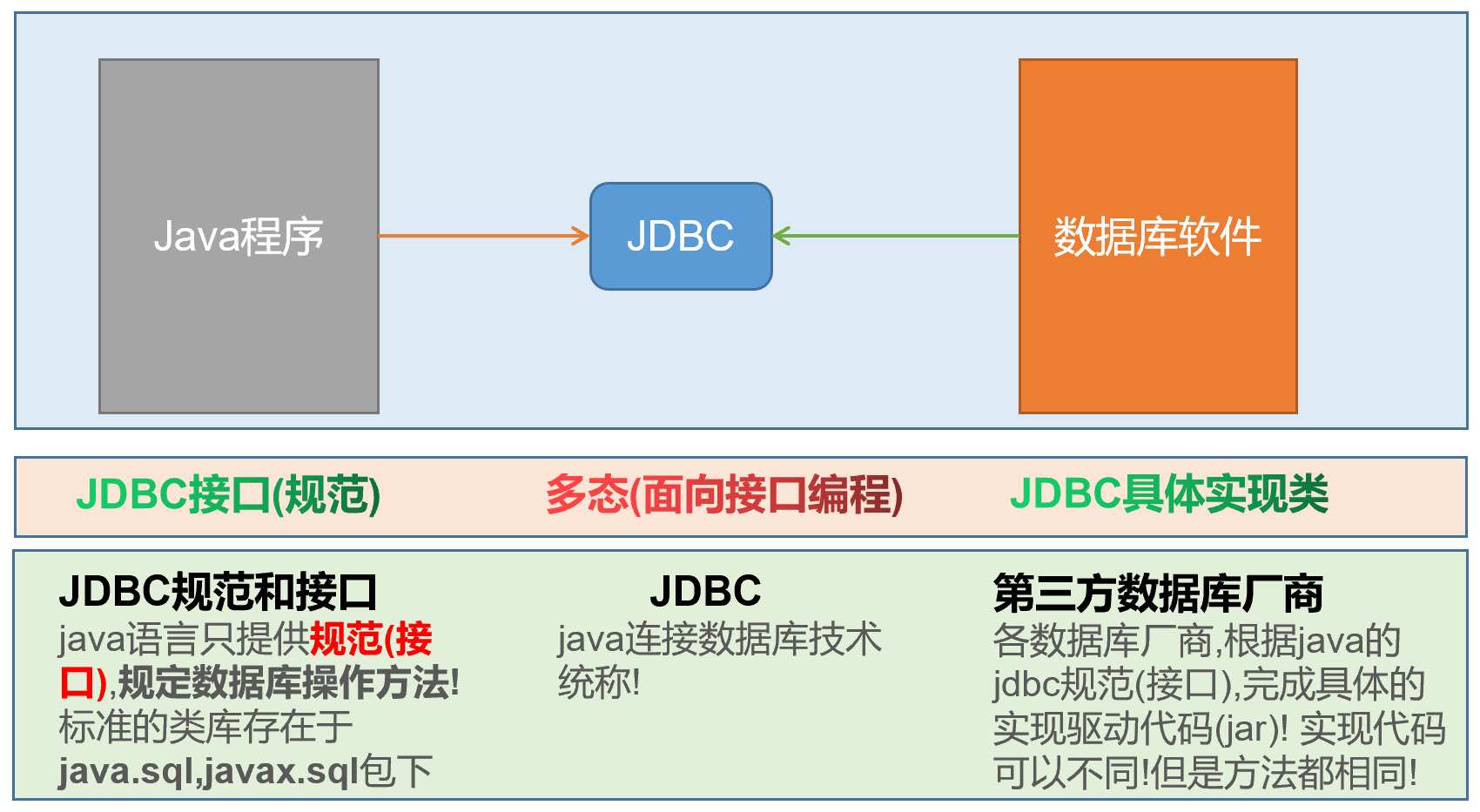
(3)JDBC本质理解
(4)JDBC总结
1)总结:
- JDBC是Java连接数据库技术的统称
- JDBC是由两部分组成的:
- Java提供的jdbc规范(接口)
- 各个数据库厂商实现的驱动jar包
- JDBC技术是一种典型的面向接口编程
2)优势:
- 我们只需要学习JDBC接口规定的方法,即可操作所有的数据库软件
- 项目中期如果需要切换数据库,那我们只需要更新第三方jar包,不用更改代码
2.JDBC概念总结
- JDBC是 Java DataBase Connectivity 的缩写,直译为 Java数据库连接
- JDBC是Java程序连接数据库的技术统称
- JDBC由 Java语言的规范(接口) 和各个数据库厂商的实现驱动(jar包)组成
(二)JDBC核心API和使用路线
1.JDBC技术组成
(1) JDK下的JDBC规范接口,存储在java.sql和javax.sql包中的API里
- 为了项目代码的可移植性和可维护性,SUN公司最初就制定了Java程序连接各种数据库的统一接口规范。这样的话,不管是连接哪一种DBMS(DataBase Management System)软件,Java代码都可以保持一致性
(2)各个数据库厂商提供的驱动jar包
- 因为各个数据库厂商的DBMS软件各有不同,那么内部如何通过sql,来实现增删改查等管理数据的操作,只有这个数据库厂商自己更清楚,因此把接口规范的实现交给各个数据库厂商自己实现。
(3)jar包是什么?
- 将Java程序打包成一种压缩包的格式,可以将这些jar包引入自己的Java项目中,然后就可以使用这个jar包里的类里面的方法和属性了
2.涉及的具体核心类以及接口
(1)连接过程
DriverManager获取连接 → 建立连接 → PreparedStatement(最常用) 发送SQL语句 →若是查询操作,则对应的查询结果放在Result类中
(2)DriverManager
- 1)将第三方数据库厂商实现的驱动jar包注册到自己的Java程序中
- 2)根据数据库连接信息来获取Connection
(3)Connection(建立连接)
- 1)和数据库建立连接,并且可以在连接的对象上多次执行数据库CURD操作
- 2)可以获取Statement,PreparedStatement,以及CallableStatement对象(Callable - 可调用的,可随时支取的)
(4)Statement,PreparedStatement,CallableStatement之间的异同
- Statement适用于静态的没有动态值的sql语句
- PreparedStatement适用于预编译的有动态值的sql语句
- CallableStatement适用于有 存储过程 要执行的sql语句
- 这三个都是用于发送sql语句到数据库管理软件的具体的实例化出来的对象
- PreparedStatement是主要使用的对象
(5)Result对象
- 只有通过查询语句才能产生的对象,用来接收从数据库中查询到的数据
- 是面对对象思维的查为奴(Result对象被抽象为数据库里查询结果的表)
- 存储DQL查询数据库结果的对象
- 需要我们进行解析,获取其具体的数据库数据
3.JDBC的API使用路线
(三)为什么选择MySQL8+版本的JDBC驱动
1.支持8.0+版本的MySQL数据管理软件
MySQL软件知名版本迭代时间
| 版本号 | 迭代时间 | 大小 |
|---|---|---|
| mysql-8.0.25 | 4,30,2021 | 435.7M |
| mysql-5.7.25 | 1,10,2019 | 387.7M |
| mysql-5.5.30 | 9,19,2012 | 201.5M |
2.MySQL8.x版本数据库性能提升介绍:
- 性能提升级。官方表示MySQL 8.0 的速度要比 MySQL 5.7 快 2 倍。
- MySQL 8.0 在读/写工作负载、IO 密集型工作负载、以及高竞争工作负载时相比MySQL5.7有更好的性能。
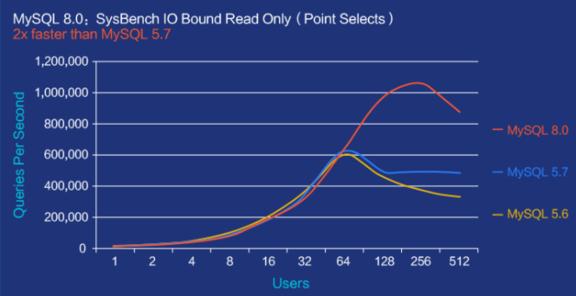
3.支持Java JDBC规范 4.2+版本的新特性
(1)Java JDBC规范驱动版本和更新时间
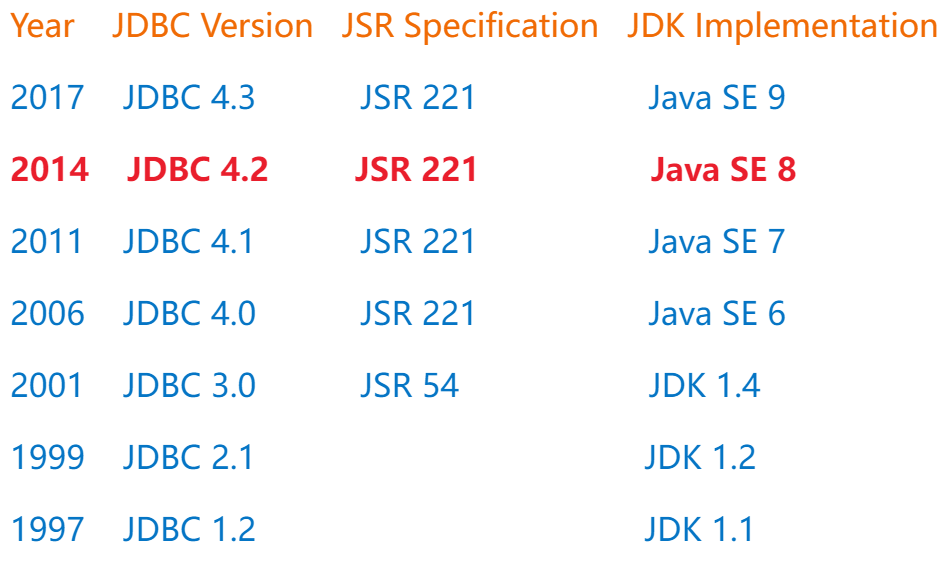
(2)JDBC规范版本更新内容(了解)

4.支持JDK1.8版本语法变更的新特性
- Connector/J 8.0是专门为了在Java8平台上允许而创建的
- 众所周知,Java8与早期的Java版本高度兼容
- 但是还是存在少量的不兼容性,所有驱动技术版本尽量选择支持JDK8.0+
5.支持全新的驱动API,增加自动时区和默认UTF-8编码格式等配置
二、JDBC核心API
(一)引入mysql-jdbc驱动的jar包
1.驱动jar包的版本选择
- 我们选择8.0.27的版本
| mysql版本 | 推荐驱动版本 | 备注 |
|---|---|---|
| mysql 5.5.x | 5.0.x | com.mysql.jdbc.Driver |
| mysql 5.7.x | 5.1.x | com.mysql.jdbc.Driver |
| mysql 8.x | 8.0.x | 建议8.0.25+,能够省略时区设置 com.mysql.jdbc.Driver |
2.Java工程导入依赖
(1)项目创建lib文件夹

(2)导入驱动依赖jar包

(3)对jar包右键 - 添加为项目依赖

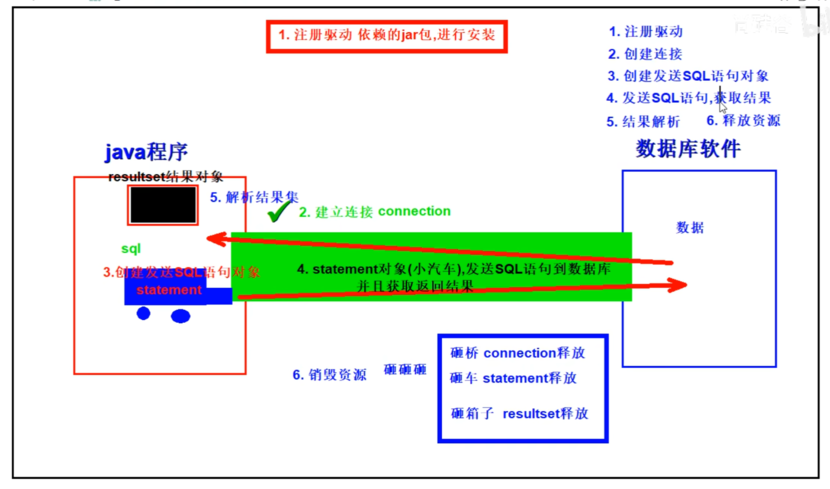
(二)JDBC基本使用步骤分析(6步)

(三)基于statement演示查询
1.准备数据库数据
CREATE DATABASE atguigu;
USE atguigu;
CREATE TABLE t_user(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '用户主键',
account VARCHAR(20) NOT NULL UNIQUE COMMENT '账号',
PASSWORD VARCHAR(64) NOT NULL COMMENT '密码',
nickname VARCHAR(20) NOT NULL COMMENT '昵称');
INSERT INTO t_user(account,PASSWORD,nickname) VALUES
('root','123456','经理'),('admin','666666','管理员');
2.查询目标
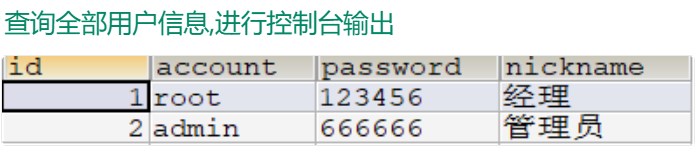
3.基于statement实现查询(演示步骤)
package com.atguigu.api.Statement;
import com.mysql.cj.jdbc.Driver;
import java.sql.*;
/**
* Description: 使用statement查询t_user表下,全部的数据
* <p>
* TODO: 步骤总结 (6步)
* 1. 注册驱动
* 2. 获取连接
* 3. 创建statement
* 4. 发送SQL语句,并获取结果
* 5. 结果集解析
* 6. 关闭资源
*/
public class StatementQueryPart {
public static void main(String[] args) throws SQLException {
//1.注册驱动
/**
* 依赖:
* 驱动版本 MySQL 8+ -> com.mysql.cj.jdbc.Driver
* 驱动版本 MySQL 5+ -> com.mysql.jdbc.Driver
*/
DriverManager.registerDriver(new Driver());//该方法是静态方法
//2.获取连接
/**
* Java程序要和数据库创建连接!
* Java程序连接数据库,肯定是要调用某个方法,方法也需要填入连接数据库的基本信息
* 本电脑MySQL数据库的基本信息:
* 数据库ip地址 127.0.0.1(或localhost) 注:127.0.0.1/localhost都是默认的本机数据库ip地址
* 数据库端口号:3306(默认)
* 账号:root
* 密码:root
* 连接数据库的名称:atguigu
*/
/**
* .getConnection()的第一个参数:url - Uniform Resource Locator
* url的书写格式 - jdbc:数据库厂商名://ip地址:port/数据库名
* 举例 - jdbc:mysql://127.0.0.1:3306/atguigu
*/
//java.sql的接口 = 实现类
Connection connection = DriverManager.getConnection
("jdbc:mysql://127.0.0.1:3306/atguigu",
"root",
"root");//静态方法
//3.创建发送sql语句对象 - 创建statement
Statement statement = connection.createStatement();
//4.发送sql语句,并且获取返回结果
String sql = "select * from t_user";
ResultSet resultSet = statement.executeQuery(sql);
//5.进行结果集解析
//.next()的作用:看看有没有下一行数据,有的话就可以获取
while (resultSet.next()) {
int id = resultSet.getInt("id");
String account = resultSet.getString("account");
String password = resultSet.getString("password");
String nickname = resultSet.getString("nickname");
System.out.println(id + "--" + account + "--" + password + "--" + nickname);
}
//6.关闭(释放)资源
resultSet.close();
statement.close();
connection.close();
}
}
(四)基于statement方式的问题
0.本案例目标

1.准备数据库数据
- 与上个案例(基于statement演示查询)相同的数据库
CREATE DATABASE atguigu;
USE atguigu;
CREATE TABLE t_user(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '用户主键',
account VARCHAR(20) NOT NULL UNIQUE COMMENT '账号',
PASSWORD VARCHAR(64) NOT NULL COMMENT '密码',
nickname VARCHAR(20) NOT NULL COMMENT '昵称');
INSERT INTO t_user(account,PASSWORD,nickname) VALUES
('root','123456','经理'),('admin','666666','管理员');
2.演示目标

3.类加载知识补充
- 类加载:就是将类的class文件读入内存,并创建一个Java.lang.class对象。
- 类在运行期第一次使用时,首先会被类加载器动态加载至JVM
- 类在运行期过程又分为了五个阶段:加载、验证、准备、解析、初始化。
- 类的生命周期被分为了七个阶段:加载、验证、准备、解析、初始化、使用、限载
4.基于statement实现模拟登录
package com.atguigu.api.Statement;
import java.sql.*;
import java.util.Properties;
import java.util.Scanner;
/**
* Description:
* 输入账号,实现模拟用户登录
* <p>
* TODO:
* 1.明确JDBC的使用流程 和 详细讲解内部设计api方法
* 2.发现问题,引出preparedStatement
* TODO:
* 输入账号和密码
* 进行数据库信息查询(t_user)
* 反馈登录成功还是登陆失败
* TODO:
* 1.键盘输入事件,收集账号和密码信息
* 2.注册驱动
* 3.获取连接
* 4.创建statement
* 5.发送查询SQL语句,并获取返回结果
* 6.结果判断,显示登录成功还是失败
* 7.关闭资源
*/
public class StatementUserLoginPart {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
//1.键入信息
Scanner scanner = new Scanner(System.in);
System.out.print("请输入账号:");
String account = scanner.nextLine();
System.out.print("请输入密码:");
String password = scanner.nextLine();
//2.注册驱动
/**
* 方案1:
* DriverManager.registerDriver(new com.mysql.cj.jdbc.Driver())
* 问题:注册了两次驱动
* 第一次 - DriverManager.registerDriver() 该方法本身会注册一次
* 第二次 - Driver.static{ static{... DriverManager.registerDriver() ...}静态代码块也会注册一次
* 想法:只想注册一次驱动来减少系统开销
* 解决方法:只触发Driver类里的 静态代码块 即可
* 触发静态代码块 -> 使用类加载机制:(类加载的时刻,会触发静态代码块)
* 1.加载 [class 文件 -> jvm虚拟机的class对象]
* 2.连接 [验证(检查文件类型) -> 准备(静态变量默认值)-> 解析(触发静态代码块)]
* 3.初始化 [静态属性赋上真实值]
* 触发类加载的方式:
* 1.new 关键字
* 2.调用静态方法
* 3.调用静态属性
* 4.接口 JDK版本1.8以上 用default默认值实现
* 5.反射
* 6.子类触发父类
* 7.程序的入口main
*/
//方案1:
// DriverManager.registerDriver(new Driver());
//方案2:
//不推荐,不雅,而且 如果mysql要改成oracle的话要改代码的
// new Driver();
//推荐 - 利用反射,解决实现代码不用更改的需求 - 更加灵活地完成数据库的切换
Class.forName("com.mysql.cj.jdbc.Driver");
//3.获取数据库连接
/**
* getConnection(1,2,3)方法,是一个重载方法
* 允许开发者用不同的形式传入数据库连接的核心参数
*
* 核心属性:
* 1.数据库软件所在的主机的ip地址: localhost 或 127.0.0.1
* 2.数据库软件所在的主机的端口号: 3306
* 3.连接的具体数据库(的名字): atguigu
* 4.连接的账号: root
* 5.连接的密码: root
* 6.可选的信息 没有
*
* 三个参数的getConnection(url,user,password):
* 1.String url 包括:数据库软件所在的信息,连接的数据库,以及其它可选信息
* 语法: jdbc:数据库管理软件[mysql/oracle/等]://ip地址
* 或
* 主机名:port(端口号)/数据库名?key=value&key=value&...
* 举例: jdbc:mysql://127.0.0.1:3306/atguigu
* jdbc:mysql://localhost:3306/atguigu?user=root&password=root
*
* 本机的省略写法:
* 如果数据库软件安装到了本机,则可以进行一些省略:
* jdbc:mysql://127.0.0.1:3306/atguigu = jdbc:mysql:///atguigu
* 省略了[本机地址]和[3306(默认端口号)]
* 强调:必须是本机并且端口号是3306才可省略并用///来代替
*
* 2.String user 数据库的账号 root
* 3.String password 数据库的密码 root
*
* 两个参数的getConnection(url,info):
* 1.String url:此url和 三个参数 的url的作用一样,即数据库ip,端口号,具体的数据库和可选信息
* 2.Properties info:存储账号和密码
* (Properties类似于Map只不过”key=value“都是字符串形式的)
* key user:账号信息
* key password:密码信息
*
* 一个参数的getConnection(url):
* String url: 数据库ip,端口号,具体的数据库,可选信息(账号密码等)
* 语法: jdbc:数据库软件名://ip:port/数据库?key=value&key=value&...
* 具体: jdbc:mysql:///atguigu?user=root&password=root
* 规定: 可选信息中,一定要携带固定的参数名 user,password 传递账号和密码信息
*
* url的路径属性里的可选信息:
* url?user=账号&password=密码 ->可选信息: 1.user=账号 2.password=密码
*
* 8.0.27的驱动版本中,可选属性如下:
* serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&usrSSL=true
* - useUnicode=true
* - characterEncoding=utf8
* - usrSSL=true
* (8.0.25以后,会自动识别时区,因此"serverTimezone=Asia/Shanghai"不用添加,
* 如果是8.0.25之前的版本,"serverTimezone=Asia/Shanghai"还是要添加的)
*
* 8版本以后,
* 默认使用的就是uft-8格式,那"useUnicode=true&characterEncoding=uft8&useSSL=true"这东西就可以省略了
*/
//三个参数
Connection connection = DriverManager.getConnection("jdbc:mysql:///atguigu", "root", "root");
//两个参数
Properties info = new Properties();
info.put("user", "root");
info.put("password", "root");
Connection connection2 = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/atguigu", info);
//一个参数
Connection connection3 = DriverManager.getConnection("jdbc:mysql://localhost:3306/atguigu?user=root&password=root");
//4.创建statement
//statement可以发送SQL语句到数据库,并且获取返回结果
Statement statement = connection.createStatement();
//5.发送SQL语句(5.1编写SQL语句 5.2发送SQL语句)
String sql = "select * from t_user where account = '" + account + "' and password = '" + password + "';";
/**
* SQL分类:DDL(容器创建,修改,删除) DML(插入,修改,删除) DQL(查询) DCL(权限控制) TPL(事务控制语言)
*
* .executeQuery(sql)里的sql分两种状况:
* 参数:sql 是 非DQL
* 返回:int
* 情况1:DML 返回影响的行数,例如:删除了3条数据就return 3,插入了2条数据就return 2,修改了0条数据就return 0
* 情况2:非DML return 0
*
* 参数:sql 是 DQL
* 返回:resultSet 结果封装对象
* ResultSet resultset = executeQuery(sql);
*/
//非DQL
// int i = statement.executeUpdate(sql);
//DQL
ResultSet resultSet = statement.executeQuery(sql);
//6.查询结果集解析 resultSet
/**
* Java是一种面向对象的思维,将查询结果封装成了resultSet对象,我们应该理解,内部一定也是有行和列的
*
* resultSet -> 逐行获取数据 -> 行和列的数据
*
* A ResultSet object maintains a cursor pointing to its current row of data.
* Initially the cursor is positioned before the first row.
* The next method moves the cursor to the next row, and
* because it returns false when there are no more rows in the ResultSet object,
* it can be used in a while loop to iterate through the result set.
* 译文:
* ResultSet对象保持一个指向当前数据行的光标。最初,光标位于第一行之前。next 方法会将光标移动到下一行,
* 当 ResultSet 对象中没有更多行时,该方法会返回 false,因此可以在 while 循环中使用该方法遍历结果集。
*
* 想要进行数据解析,我们需要进行两件事情: 1.移动游标指定获取数据行 2.获取指定数据行的列数据
* 1.游标移动问题
* resultSet内部包含一个游标,指定当前数据
* 默认游标指定的是第一行数据之前
* 我们可以调用next方法向后移动一行游标
* 如果我们有很多行数据,我们可以使用while(next){获取每一行数据}
* boolean = next() 返回 true:有更多行数据,并且向下移动一行
* 返回 false:没有更多行数据,但不一定
*
* 移动游标的方法有很多,只需要记next()即可,配合while循环获取全部数据!
* 真正要改的不是如何移动游标,而是要改你查询的SQL语句,让你查询的数据都是正确的,而不是让游标来回跳
*
* 2.获取列的数据问题(获取游标指定的那一行里列的数据)
* resultSet.get类型(String columnLabel 或 int columnIndex);
* columnLable: 列名 如果起别名了就 写别名 select * ...
* select id as aid, account as ac ...
*
* columnIndex: 列的下角标 从左向右 从1开始
*/
//遍历ResultSet里的数据
// while (resultSet.next()){
// //第一次的resultSet.next()使游标指向第一行数据
// int id = resultSet.getInt(1);
// String account1 = resultSet.getString("account");
// String password1 = resultSet.getString(3);
// String nickname = resultSet.getString("nickname");
// System.out.println(id+"--"+account1+"--"+password1+"--"+nickname);
// }
//移动一次游标,只要有数据,就代表登陆成功
if (resultSet.next()) {
System.out.println("登陆成功!");
} else {
System.out.println("登陆失败!");
}
//7.关闭(释放)资源
resultSet.close();
statement.close();
connection.close();
return;
}
}
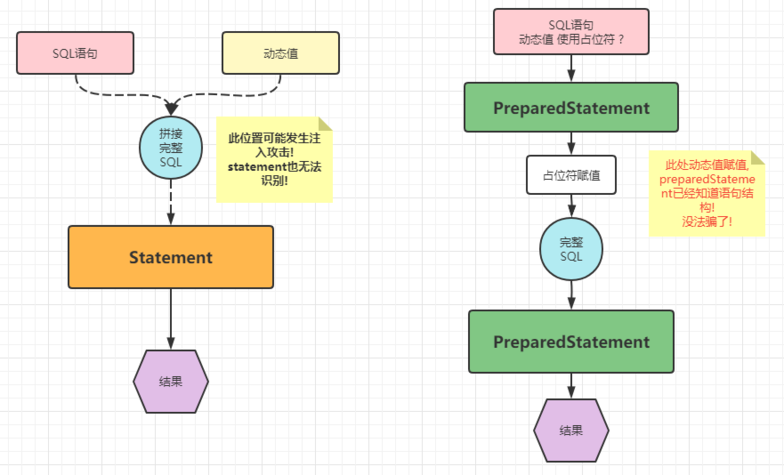
5.存在问题
- SQL语句需要字符串拼接的时候,会比较麻烦
- 在执行动态SQL语句时,需要字符串拼接
- 只能拼接字符串类型,其它的数据库里包含的数据类型无法处理
- 可能发生注入攻击
- 注入攻击:动态值充当了SQL语句结果,影响力原有的查询结构
(五)基于preparedStatement方式进行优化
- 重点掌握:
- 利用PreparedStatement解决上述案例的注入攻击和SQL语句的拼接问题
package com.atguigu.api.PreparedStatement;
import java.sql.*;
import java.util.Scanner;
/**
* Description:
* 使用预编译statement完成用户登录
* <p>
* 防止注入攻击 并 演示ps的使用流程
*/
public class PSUserLoginPart {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
//1.键入信息
Scanner scanner = new Scanner(System.in);
System.out.print("请输入账号:");
String account = scanner.nextLine();
System.out.print("请输入密码:");
String password = scanner.nextLine();
//2.preparedStatement的数据库流程
//2.1注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2.2获取连接
Connection connection = DriverManager.getConnection("jdbc:mysql:///atguigu?user=root&password=root");
/**
*
* statement
* 1.创建statement
* 2.拼接SQL语句
* 3.发送SQL语句,并且获取返回结果
*
* preparedstatement
* 1.编写SQL语句结果 - 不包含动态值部分的语句,动态值部分使用占位符'?'来代替。 -> '?'只能代替动态值
* 2.创建preparedstatement,并且传入动态值
* 3.发送SQL语句即可,并获取返回结果
* 注:? 只能替代值,不能替代关键字和容器名
*/
//3.编写SQL语句结果
String sql = "select * from t_user where account = ? and password = ? ;";
//4.创建预编译statement并且设置SQL语句结果
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//5.对单独的占位符进行赋值
/**
* .setObject(parameterindex, Object x):
* 参数1:parameterindex - 占位符的位置 从左向右 从1开始
* 例: String sql = "select * from t_user where account = ? and password = ? ;"
* 参数2:object 占位符的(动态)值 可以设置任何类型的数据,避免了我们拼接,并且让类型更加丰富
*/
//account的要占的是第1个占位符的位置
preparedStatement.setObject(1, account);
//password的要占的是第2个占位符的位置
preparedStatement.setObject(2, password);
//6.发送SQL语句,并获取返回结果
//TODO:此时系统已经知道语句和语句的动态值
//preparedStatement.executeUpdate() / preparedStatement.executeQuery();
ResultSet resultSet = preparedStatement.executeQuery();
//7.结果集解析
if (resultSet.next()) {
System.out.println("登陆成功!");
} else {
System.out.println("登陆失败!");
}
//8.关闭(释放)资源
resultSet.close();
preparedStatement.close();
connection.close();
return;
}
}
(六)基于preparedStatement演示CURD
- 记得先创建一个测试类
/**
* ClassName: PS_CURD_Part
* Package: com.atguigu.api.PreparedStatement
* Description:
* 使用preparedStatement进行t_user表的CURD操作 - Create Update Read Delete
*/
public class PS_CURD_Part {
}
1.数据库数据插入
//测试方法需要导入junit的测试包
/**
* 向t_user表中插入一条数据
*/
@Test
public void testInsert() throws ClassNotFoundException, SQLException {
//1.注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取连接
Connection connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/atguigu", "root", "root");
//3.编写SQL语句结果,动态值的部分用'?'代替
String sql = "insert into t_user(account,password,nickname) values(?,?,?);";
//4.创建preparedStatement,并且传入SQL语句结果
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//5.占位符赋值
preparedStatement.setObject(1, "test");
preparedStatement.setObject(2, "test");
preparedStatement.setObject(3, "二狗子");
//6.发送SQL语句
//DML类型的操作
int rows = preparedStatement.executeUpdate();
//7.输出结果
if (rows > 0) {
System.out.println("数据插入成功!");
} else {
System.out.println("数据插入失败!");
}
//8.关闭(释放)资源
preparedStatement.close();
connection.close();
}
2.数据库数据修改
/**
* 修改 id=3 的用户nickname为三狗子
*/
@Test
public void testUpdate() throws ClassNotFoundException, SQLException {
//1.注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取连接
Connection connection = DriverManager.getConnection("jdbc:mysql:///atguigu?user=root&password=root");
//3.编写SQL语句结果,动态值的部分用'?'代替
String sql = "update t_user set nickname = ? where id = ?;";
//4.创建preparedStatement,并且传入SQL语句结果
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//5.占位符赋值
preparedStatement.setObject(1, "三狗子");
preparedStatement.setObject(2, 3);
//6.发送SQL语句
int rows = preparedStatement.executeUpdate();
//7.输出结果
if (rows > 0) {
System.out.println("修改成功!");
} else {
System.out.println("修改失败!");
}
//8.关闭(释放)资源
preparedStatement.close();
connection.close();
}
3.数据库数据删除
- 一样的逻辑,就不写注释了
/**
* 删除 id = 3 的用户
*/
@Test
public void testDelete() throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql:///atguigu", "root", "root");
String sql = "delete from t_user where id = ?;";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setObject(1, 3);
int i = preparedStatement.executeUpdate();
if (i > 0) {
System.out.println("删除成功!");
} else {
System.out.println("删除失败!");
}
preparedStatement.close();
connection.close();
}
4.数据库数据查询
/**
* 目标:查询所有用户数据,并且封装到List<Map>中
* <p>
* 实现目标的流程:
* 数据库 -> resultSet -> java -> 一行 -> map(key=别名,value=列的内容) -> List<Map> list
* 什么是一行?
* 答:
* 行 id account password nickname
* 行 id account password nickname
* ......
* <p>
* 实现思路:
* 遍历数据,一行对应一个map,获取一行的列名和对应的列的属性,装配即可,最后将map装到一个List里就可以了
* <p>
* 难点:如何获取表中每一个列的名称?
*/
@Test
public void testSelect() throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/atguigu", "root", "root");
String sql = "select id,account as AC from t_user";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//这里不需要占位符,因为是查询操作而非其它的操作
ResultSet resultSet = preparedStatement.executeQuery();
//结果集解析
/**
* 回顾
* resultSet: 有行和有列
* 获取数据的时候,一行一行数据来获取
* 我们可以利用next()方法移动游标,来指向数据行,并获取行中的列的数据
*/
//先定义出来一个装Map的List
List<Map> list = new ArrayList<>();
// 获取列的信息的对象
// TODO: metaData里装的是 当前结果集中的列的信息对象。 它可以根据下角标获取列的名称,也可以获取列的数量
ResultSetMetaData metaData = resultSet.getMetaData();
// 有了该对象以后,我们可以水平(方向)地来遍历列
//获取该表的总列数
int columnCount = metaData.getColumnCount();
while (resultSet.next()) {
Map map = new HashMap();
//一行数据 对应一个map
//不推荐
//纯手动取值(纯手动拿数据)
// map.put("id", resultSet.getInt("id"));
// map.put("account", resultSet.getString("account"));
// map.put("password", resultSet.getString("password"));
// map.put("nickname", resultSet.getString("nickname"));
//推荐
// 获取列的信息对象(在该循环语句的的上面书写) - ResultSetMetaData metaData = resultSet.getMetaData();
// 自动遍历列 - 注意:要从i=1开始遍历,循环条件要小于等于总列数
for (int i = 1; i <= columnCount; i++) {
//获取指定列下角标的值 resultSet
Object value = resultSet.getObject(i);
//获取指定列的下角标的列名! ResultSetMetaData
//不要使用getColumnName 因为它只会获取列的名称,不会获取别名
//getColumnLabel会获取别名 如果没有写别名才是列的名称
String columnLabel = metaData.getColumnLabel(i);
map.put(columnLabel, value);
}
//程序执行到这里时,一行数据的所有列就全部存到了map中
//将map存储到集合中即可
list.add(map);
}
System.out.println("List = " + list);
resultSet.close();
preparedStatement.close();
connection.close();
}
(七)preparedStatement使用方式总结
1.使用步骤总结
//1.注册驱动
//2.获取连接
//3.编写SQL语句
//4.创建preparedstatement并且传入SQL语句结构
//5.占位符赋值
//6.发送SQL语句,并且获取结果
//7.结果集解析
//8.关闭资源
2.使用API总结
//1.注册驱动
方案1: 调用静态方法,但是会注册两次
DriverManager.registerDriver(new com.mysql.cj.jdbc.Driver());
方案2: 反射触发 - 注册一次
Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取连接
Connection connection = DriverManager.getConnection();
3 (String url,String user,String password)
2 (String url,Properties info(user password))
1 (String url?user=账号&password=密码 )
//3.创建statement
//静态
Statement statement = connection.createStatement();
//预编译
PreparedStatement preparedstatement = connection.preparedStatement(sql语句结构);
//4.占位符赋值
preparedstatement.setObject(?的位置从左向右从1开始,?的值)
//5.发送sql语句获取结果
int rows = executeUpdate(); //非DQL
Resultset = executeQuery(); //DQL
//6.查询结果集解析
//移动光标指向行数据 next(); if(next()) while(next())
//获取列的数据即可 get类型(列的下标 从1开始 | 别名或列名)
//获取列的信息 getMetadata(); ResultsetMetaData对象 包含的就是列的信息
getColumnCount(); //列的数量
getCloumnLebal(index); //列的别名,没有别名直接取列名
//7.关闭资源
close();
三、JDBC扩展提示
(一)自增长主键回显的实现
1.功能需求
- 主键回显
- 定义:在数据库里的表中插入一条记录时,如果该表设置了适当的参数,那么数据库会在插入操作完成后返回生成的主键值。
- 这个主键可以是有数据库自动生成的,也可以是由开发人员明确指定的。
- 作用:主键回显能够允许开发者在执行数据库中表的插入操作后,立即在Java后端中获取到新插入记录的主键(值),方便后续的操作和数据管理
- 定义:在数据库里的表中插入一条记录时,如果该表设置了适当的参数,那么数据库会在插入操作完成后返回生成的主键值。
- 这里要解决的问题:
- 主表默认增长,但是从表不知道值,所以要主键回显,让从表知道主表的主键增长了
- 解决思路:
- 在多表关联插入数据时,一般主表的主键都是自动生成的,因此在插入数据之前我们无法知道这条数据的主键,但是从表需要在插入数据之前就绑定主表的主键,这时可以使用主键回显技术
2.功能实现
- 继续沿用之前的数据库里的表的数据
/**
* TODO:
* t_user插入一条数据,并且 -- 获取数据库自增长的主键 --
* <p>
* 使用总结:
* 1.创建prepareStatement的时候,在.prepareStatement()的参数列表中加入一个参数,
* 来告知数据库,返回数据的时候记得携带数据库自增长的主键。
* 加入的参数:Statement.RETURN_GENERATED_KEYS
* <p>
* 2.获取 插入数据之后,其主键值也已经更新完后的 结果集对象,
* 获取对应的数据即可 - ResultSet generatedKeys = preparedStatement.getGeneratedKeys();
*/
@Test
//主键回显 和 主键值获取
public void returnPrimaryKey() throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1/atguigu", "root", "root");
String sql = "insert into t_user(account,password,nickname) value(?,?,?)";
//创建preparedStatement
//注意:"PreparedStatement.Statement.RETURN_GENERATED_KEYS"的目的:要数据库返回数据时把KEYS的内容也带回来
PreparedStatement preparedStatement = connection.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);
preparedStatement.setObject(1, "test1");
preparedStatement.setObject(2, 123456);
preparedStatement.setObject(3, "驴蛋蛋");
int i = preparedStatement.executeUpdate();
//结果分析
if (i > 0) {
System.out.println("插入成功!");
//可以获取回显的主键
//获取搞完主键后的结果集对象,一行 一列 ,id = 值
ResultSet generatedKeys = preparedStatement.getGeneratedKeys();
generatedKeys.next();
int id = generatedKeys.getInt(1);
System.out.println("id = " + id);
} else {
System.out.println("插入失败!");
}
preparedStatement.close();
connection.close();
}
(二)批量数据插入的性能提升
1.功能需求
- 批量数据插入优化
- 提升大量数据插入效率
2.功能实现
(1)使用普通的方式插入10000条数据所需的时间
@Test
//使用普通的方式插入10000条数据所需的时间
public void testInsert() throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1/atguigu", "root", "root");
String sql = "insert into t_user(account,password,nickname) value(?,?,?)";
//创建preparedStatement
//注意:"PreparedStatement.Statement.RETURN_GENERATED_KEYS"的目的:要数据库返回数据时把KEYS的内容也带回来
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//占位符赋值
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
preparedStatement.setObject(1, "dd" + i);
preparedStatement.setObject(2, "dd" + i);
preparedStatement.setObject(3, "驴蛋蛋" + i);
//TODO: 占位符赋值之后,发送SQL语句,并返回结果
preparedStatement.executeUpdate();
}
long end = System.currentTimeMillis();
//结果分析
System.out.println("执行10000次数据插入消耗的时间: " + (end - start));//26816毫秒
preparedStatement.close();
connection.close();
}
(2)优化:使用 批量插入 的方式插入10000条数
@Test
//批量插入数据优化
//使用 批量插入 的方式插入10000条数据所需的时间
/**
* 总结
* 批量输入
* 1.路径后面添加 ?rewriteBatchedStatements=true 允许批量输入
* 2.insert into values[必须要写被插入数据的列] 且 SQL语句的最后不能添加';'
* 3.不是执行每条语句,而是利用addBatch()来批量添加数据到SQL语句中的values后面
* 4.遍历添加数据完以后,统一执行executeBatch()来执行SQL语句
*/
public void testBatchInsert() throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
//TODO:这里添加了一个url的路径属性里的可选信息 - "rewriteBatchedStatements=true"
Connection connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1/atguigu?rewriteBatchedStatements=true", "root", "root");
//TODO:这里不能写value,要写values,一直写values就行,记住
//TODO: 这里SQL语句最后不能加上 ';' 否则会执行失败。
// 原因:不加';'是因为 - 批量插入的原理是在原来的sql语句后面继续追加相应的sql语句
String sql = "insert into t_user(account,password,nickname) values(?,?,?)";
//创建preparedStatement,TODO:注意"com.atguigu.api.PreparedStatement.Statement.RETURN_GENERATED_KEYS"的目的是要数据库返回数据时把KEYS的内容也带回来
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//测试发送的时间
long start = System.currentTimeMillis();
//占位符赋值
for (int i = 0; i < 10000; i++) {
preparedStatement.setObject(1, "ddd" + i);
preparedStatement.setObject(2, "ddd" + i);
preparedStatement.setObject(3, "驴蛋蛋d" + i);
//TODO: 占位符赋值之后,发送SQL语句,并返回结果
//TODO:删去preparedStatement.executeUpdate();
//TODO:赋值一次就传给数据库一次的想法就不用了
//TODO:而是用 addBatch() 把赋值后的数据直接追加到SQL语句中的values后面
preparedStatement.addBatch();
}
//TODO:最后执行批量操作
preparedStatement.executeBatch();
long end = System.currentTimeMillis();
//结果分析
System.out.println("执行10000次数据插入消耗的时间: " + (end - start));//310毫秒
preparedStatement.close();
connection.close();
}
(三)JDBC中数据库事务的实现
1.章节目标
- 使用JDBC代码,添加数据库事务动作
- 开启事务
- 事务提交 / 事务回滚
2.事务概念回顾
// 事务概念
数据库事务就是一种SQL语句执行的缓存机制,不会单条执行完毕就更新数据库数据,最终根据缓
存内的多条语句执行结果统一判定!
一个事务内所有语句都成功及事务成功,我们可以触发commit提交事务来结束事务,更新数据!
一个事务内任意一条语句失败,及事务失败,我们可以触发rollback回滚结束事务,
数据回到事务之前状态!
举个例子:
临近高考,你好吃懒做,偶尔还瞎花钱,父母也只会说'你等着!',待到高考完毕!
成绩600+,翻篇,庆祝!
成绩200+,翻旧账,男女混合双打!
//优势
允许我们在失败情况下,数据回归到业务之前的状态!
//场景
一个业务涉及多条修改数据库语句!
例如: 经典的转账案例,转账业务(加钱和减钱)
批量删除(涉及多个删除)
批量添加(涉及多个插入)
// 事务特性
1. 原子性(Atomicity)原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,
要么都不发生。
2. 一致性(Consistency)事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
3. 隔离性(Isolation)事务的隔离性是指一个事务的执行不能被其他事务干扰,
即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
4. 持久性(Durability)持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,
接下来的其他操作和数据库故障不应该对其有任何影响
// 事务类型
自动提交 : 每条语句自动存储到一个事务中,执行成功自动提交,执行失败自动回滚! (MySQL)
手动提交: 手动开启事务,添加语句,手动提交或者手动回滚即可!
// sql开启事务方式【事务都在一个连接中】
推荐 - 针对自动提交: 关闭自动提交即可,多条语句添加以后,最终手动提交或者回滚!
SET autocommit = off; //关闭当前连接connection自动事务提交方式
# 只有当前连接有效
# 编写SQL语句即可
SQL
SQL
SQL
#手动提交或者回滚 【结束当前的事务】
COMMIT / ROLLBACK ;
不推荐 - 手动开启事务: 开启事务代码,添加SQL语句,事务提交或者事务回滚!
// 呼应jdbc技术
try{
connection.setAutoCommit(false); //关闭自动提交了
//connection.setAutoCommit(false)也就类型于SET autocommit = off
//注意,只要当前connection对象,进行数据库操作,都不会自动提交事务
//JDBC中XxxxStatement和Connection对于数据库的操作:
// XxxxStatement - 单一的数据库操作:C U R D
// Connection - 操作事务
connection.commit();
}catch(Execption e){
connection.rollback();
}
3.数据库表的数据
-- 继续在atguigu的库中创建银行表
CREATE TABLE t_bank(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '账号主键',
account VARCHAR(20) NOT NULL UNIQUE COMMENT '账号',
money INT UNSIGNED COMMENT '金额,不能为负值') ;
INSERT INTO t_bank(account,money) VALUES
('ergouzi',1000),('lvdandan',1000);
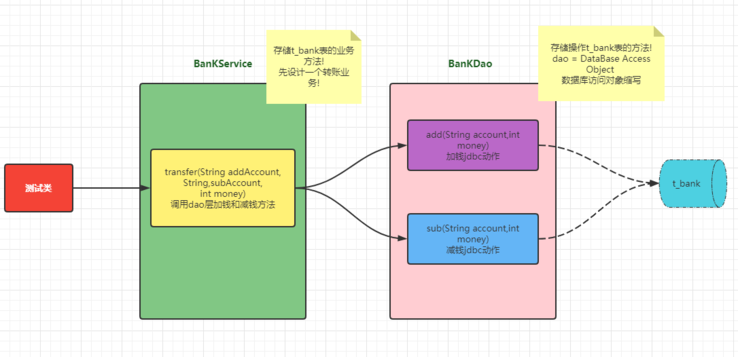
4.代码结构设计图
5.JDBC事务实现
(1)测试类
public class BankTest {
@Test
public void testBank() throws Exception {
BankService bankService = new BankService();
bankService.transfer("ergouzi", "lvdandan",
500);
}
}
(2)数据库表对应的实体类
package com.atguigu.api;
/**
* ClassName: User
* Package: com.atguigu.api.PreparedStatement
* Description:
* 数据库表t_bank对应的实体类
*/
public class T_Bank {
public int id;
public String account;
public int money;
}
(3)BankService
package com.atguigu.api.TransAction;
import org.testng.annotations.Test;
import java.sql.Connection;
import java.sql.DriverManager;
/**
* ClassName: BankService
* Package: com.atguigu.api.PreparedStatement.TransAction
* Description:
* 银行卡业务方法,调用dao方法
*/
public class BankService {
@Test
public void testStart() throws Exception {
//二狗子给驴蛋蛋转500
transfer("lvdandan", "ergouzi", 500);
}
/**
* TODO:
* 事务的添加要在业务方法(Service层)中!
* 利用try-catch-finally代码块,来开启事务和提交事务,以及事务回滚!
* 将connection传入dao层即可!
* dao层只负责使用,不要把connection给.close()掉,finally最后会关闭回收的
*
* @param addAccount
* @param subAccount
* @param money
* @throws Exception
*/
public void transfer(String addAccount, String subAccount, int money) throws Exception {
BankDao bankDao = new BankDao();
//一个事务的最基本要求,必须是同一个连接对象connection
//一个转账方法 属于一个事务(加钱、减钱)
//注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//获取连接
Connection connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/atguigu", "root", "root");
try {
//开启事务
//关闭事务提交!
connection.setAutoCommit(false);
//执行数据库动作
bankDao.add(addAccount, money, connection);
System.out.println("-------------------");
bankDao.sub(subAccount, money, connection);
//事务提交
connection.commit();
} catch (Exception e) {
//如果报错了,就事务回滚
connection.rollback();
//抛出异常
throw e;
} finally {
//关闭(释放)连接
connection.close();
}
}
}
(4)BankDao:具体操作方法
package com.atguigu.api.TransAction;
import java.sql.Connection;
import java.sql.PreparedStatement;
/**
* ClassName: BankDao
* Package: com.atguigu.api.PreparedStatement.TransAction
* Description:
* bank表的数据库操作方法存储类
*/
public class BankDao {
/**
* 加钱的数据库操作方法 (JDBC)
*
* @param account 加钱的行号
* @param money 加钱的金额
*/
public void add(String account, double money, Connection connection) throws Exception {
String sql = "update t_bank set money = money + ? where account = ?;";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setObject(1, money);
preparedStatement.setObject(2, account);
int i = preparedStatement.executeUpdate();
preparedStatement.close();
System.out.println("加钱成功!");
}
/**
* 减钱的数据库操作方法 (JDBC)
*
* @param account 减钱的行号
* @param money 减钱的金额
*/
public void sub(String account, double money, Connection connection) throws Exception {
String sql = "update t_bank set money = money - ? where account = ?;";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setObject(1, money);
preparedStatement.setObject(2, account);
int i = preparedStatement.executeUpdate();
preparedStatement.close();
System.out.println("减钱成功!");
}
}
6.代码结构设计

在业务类中创建连接

四、Druid连接池技术
(一)连接性能消耗问题的分析

(二)数据库连接池的作用
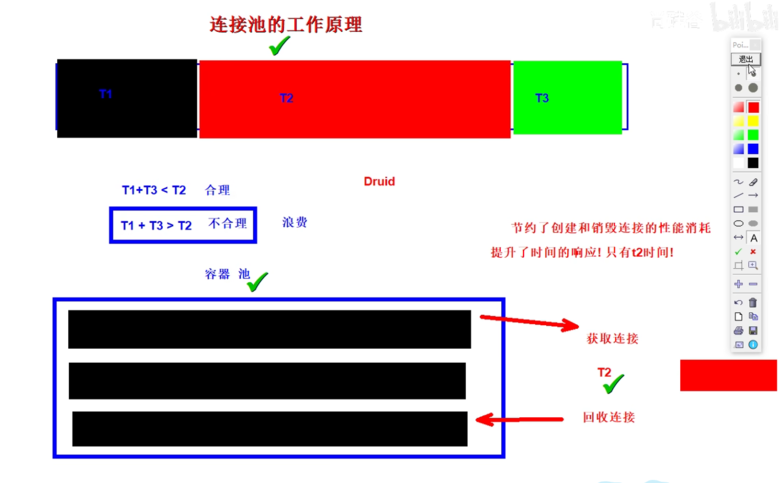

(三)市面上常见的连接池产品及其对比
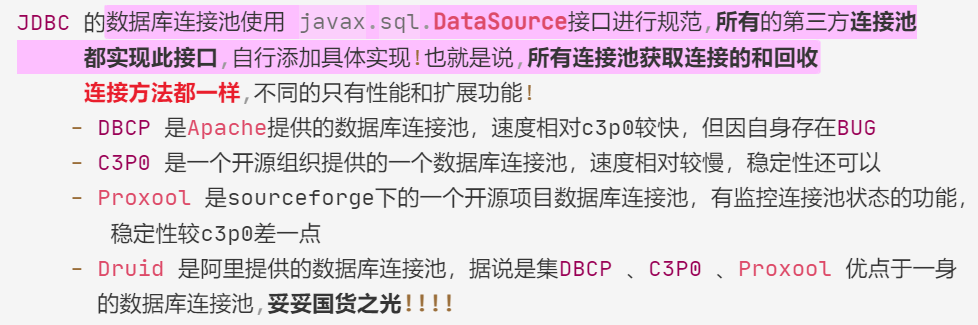
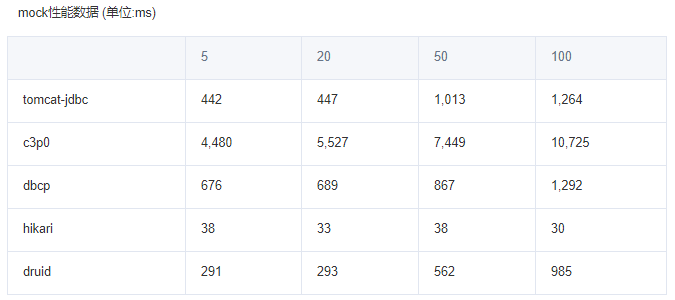

(四)国货之光Druid连接池的使用
- 记得导入Druid工具类的jar包
- 记得创建一个学习Druid的测试类
/**
* ClassName: DruidUsePar
* Package: com.atguigu.api.druid
* Description:
* druid连接池使用类
*/
public class DruidUsePart {
}
1.硬编码方式(了解,不推荐)
/**
* 硬编码实现
* <p>
* 1.创建一个druid连接池对象
* 2.设置连接池参数[必须 | 非必须]
* 3.获取连接[通用方法,所有连接池都一样]
* 4.回收连接[通用方法,所有连接池都一样] TODO:这里不是 “关闭(释放)连接” 而是 “回收连接”
*/
@Test
public void testHard() throws SQLException {
//连接池对象
//DruidDataSource实现了Java规定标准的的DataSource接口
DruidDataSource druidDataSource = new DruidDataSource();
//设置参数
//必须: 连接数据库驱动类的全限定符[注册驱动] | url | user | password
druidDataSource.setUrl("jdbc:myql://127.0.0.1:3306/atguigu");
druidDataSource.setUsername("root");
druidDataSource.setPassword("root");
druidDataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");//帮助我们进行驱动注册和获取连接
//非必须:初始化连接数量 , 最大的连接数量 , ......
druidDataSource.setInitialSize(5);//初始化连接数量
druidDataSource.setMaxActive(10);//最大的连接数量
//获取连接
//DruidPooledConnection实现了Java规定标准的Connection接口
//因此现在 用Connection类 来 实例化druidPooledConnection对象后,
//TODO:当调用.close()方法时,已经 不是关闭(释放)连接 ,而是 回收连接 了
Connection druidPooledConnection = druidDataSource.getConnection();
//数据库CURD
//回收连接
druidPooledConnection.close();//连接池提供的连接的.close()就是回收连接
}
2.软编码方式
(1)外部配置
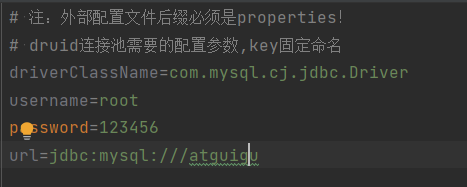
- 存放位置:src/druid.properties
# 注:外部配置文件后缀必须是properties!
# druid连接池需要的配置参数,key固定命名
driverClassName=com.mysql.cj.jdbc.Driver
username=root
password=root
url=jdbc:mysql:///atguigu
(2)Druid声明代码
/**
* 软编码实现
* 通过读取外部配置文件的方法,实例化druid连接池对象
*/
@Test
public void testSoft() throws Exception {
//1.读取外部配置文件 Properties
Properties properties = new Properties();
//src下的文件,可以使用类加载器提供的方法实现装载(properties.load(param))
InputStream inputPropertiesStream = DruidUsePart.class.getClassLoader().getResourceAsStream("druid.properties");
properties.load(inputPropertiesStream);
//2.使用连接池的工具类的工厂模式(DruidDataSourceFactory)来创建连接池
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
Connection connection = dataSource.getConnection();
//数据库CURD
//......
//回收连接
connection.close();
}
3.Druid配置(了解)
| 配置 | 缺省 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。 如果没有配置,将会生成一个名字,格式是:”DataSource-” + System.identityHashCode(this) | |
| jdbcUrl | 连接数据库的url,不同数据库不一样。例如:mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter | |
| driverClassName | 根据url自动识别 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName(建议配置下) | |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 有两个含义: 1)Destroy线程会检测连接的间隔时间2)testWhileIdle的判断依据,详细看testWhileIdle属性的说明 | |
| numTestsPerEvictionRun | 不再使用,一个DruidDataSource只支持一个EvictionRun | |
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 当数据库抛出一些不可恢复的异常时,抛弃连接 | |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall | |
| proxyFilters | 类型是List,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
4.笔记

- 连接池帮我们进行注册驱动、创建链接
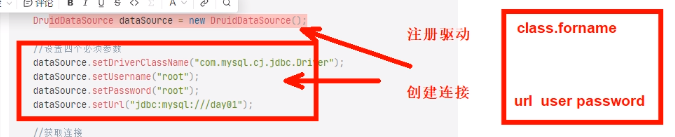
- 关于外部配置文件


五、JDBC使用优化以及工具类封装
- 过程:
- 1.注册驱动
- 2.获取连接
- 3.编写SQL语句
- 4.创建XxxxxStatement
- 5.占位符赋值
- 6.发送SQL语句
- 7.结果解析
- 8.回收资源
- 下面v1.0和v2.0针对 “1.注册驱动”,“2.获取连接”,“8.回收资源” 进行封装
- BaseDao针对 “3.编写SQL语句”,“4.创建statement”,“5.占位符赋值”,“6.发送SQL语句”,“7.结果解析” 进行封装,进行增删改查

(一)JDBC工具类封装version1.0

1.外部配置文件
位置: src/druid.properties
# druid连接池需要的配置参数,key固定命名
driverClassName=com.mysql.cj.jdbc.Driver
username=root
password=root
url=jdbc:mysql:///atguigu
2.工具类代码
package com.atguigu.api.utils;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
/**
* ClassName: JDBC_Utils
* Package: com.atguigu.api.utils
* Description:
* v1.0版本工具类
* 内部包含一个连接池对象,并且对外提供获取连接和回收连接的方法
* <p>
* 小建议:
* 工具类的方法推荐写成静态方法,这样的话外部调用会更加方便
* <p>
* 实现:
* 属性 连接池对象[实例化一次]
* <p>
* 实例化一次的方法:
* 1.单例模式
* 2.static{全局调用一次} (静态代码块)
* <p>
* 方法:
* 1.对外提供连接的方法
* 2.回收外部传入的连接的方法
*/
public class JDBC_Utils {
private static DataSource dataSource = null;//连接池对象
//初始化连接池对象
static {
Properties properties = new Properties();
InputStream ips = JDBC_Utils.class.getClassLoader().getResourceAsStream("druid.properties");
try {
properties.load(ips);
} catch (IOException e) {
throw new RuntimeException(e);
}
try {
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 对外提供连接的方法
*/
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
/**
* 回收连接
*/
public static void RecycleConnection(Connection connection) throws SQLException {
connection.close();//连接池的连接,调用close()就是回收
}
}
(二)JDBC工具类封装version2.0
- 对工具类v1.0版本的进一步优化
- 在考虑事务的情况下,如何从一个线程里的不同方法中获取同一个连接


- 在考虑事务的情况下,如何从一个线程里的不同方法中获取同一个连接
1. 工具类v2.0
package com.atguigu.api.utils;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
/**
* ClassName: JDBC_Utils
* Package: com.atguigu.api.utils
* Description:
* v2.0版本工具类
* 内部包含一个连接池对象,并且对外提供获取连接和回收连接的方法
* TODO:
* 利用线程本地变量(ThreadLocal)来存储连接信息!确保一个线程的多个方法可以获取同一个connection!
* 优势: 事务操作的时候 service 和 dao 属于同一个线程,不用再传递connection的参数了
* 大家都可以调用getConnection()自动获取相同的连接池
*/
public class JDBC_Utils_V2 {
private static DataSource dataSource = null;//连接池对象
//TODO:线程本地变量
private static ThreadLocal<Connection> threadLocal = new ThreadLocal<>();
//初始化连接池对象
static {
//方法一 v1.0
// Properties properties = new Properties();
// InputStream ips = JDBC_Utils_V2.class.getClassLoader().getResourceAsStream("druid.properties");
// try {
// properties.load(ips);
// } catch (IOException e) {
// throw new RuntimeException(e);
// }
//
// try {
// dataSource = DruidDataSourceFactory.createDataSource(properties);
// } catch (Exception e) {
// throw new RuntimeException(e);
// }
//方法二 v2.0
try {
Properties properties = new Properties();
properties.load(ClassLoader.getSystemResourceAsStream("druid.properties"));
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 对外提供连接的方法
*/
public static Connection getConnection() throws SQLException {
//线程本地变量是否存在连接
Connection connection = threadLocal.get();
//第一次没有
if (connection == null) {
//线程本地变量没有,从连接池中获取连接
connection = dataSource.getConnection();
threadLocal.set(connection);
}
return connection;
}
/**
* 回收连接
*/
public static void RecycleConnection() throws SQLException {
Connection connection = threadLocal.get();
if (connection != null) {
threadLocal.remove();//清空线程本地变量的数据
connection.setAutoCommit(true);//把BankService里面,修改过的事务提交状态给恢复一下(false -> true)
connection.close();//将拿出来的连接回收到连接池即可
}
}
}
2. BankService v2.0
package com.atguigu.api.TransActionV2;
import com.atguigu.api.utils.JDBC_Utils_V2;
import org.testng.annotations.Test;
import java.sql.Connection;
/**
* ClassName: BankService
* Package: com.atguigu.api.PreparedStatement.TransAction
* Description:
* 银行卡业务方法,调用dao方法
*/
public class BankService {
@Test
public void testStart() throws Exception {
//二狗子给驴蛋蛋转500
transfer("lvdandan", "ergouzi", 500);
}
/**
* TODO:
* 事务的添加要在业务方法(Service层)中!
* 利用try-catch-finally代码块,来开启事务和提交事务,以及事务回滚!
* 将connection传入dao层即可!
* dao层只负责使用,不要把connetion给.close()掉,finally最后会关闭回收的
*
* @param addAccount
* @param subAccount
* @param money
* @throws Exception
*/
public void transfer(String addAccount, String subAccount, int money) throws Exception {
BankDao bankDao = new BankDao();
Connection connection = JDBC_Utils_V2.getConnection();
try {
//开启事务
//关闭事务提交!
connection.setAutoCommit(false);
//执行数据库动作
bankDao.add(addAccount, money);
System.out.println("-------------------");
bankDao.sub(subAccount, money);
//事务提交
connection.commit();
} catch (Exception e) {
//如果报错了,就事务回滚
connection.rollback();
//抛出异常
throw e;
} finally {
//关闭(释放)连接
JDBC_Utils_V2.RecycleConnection();
}
}
}
3.BankDao v2.0
package com.atguigu.api.TransActionV2;
import com.atguigu.api.utils.JDBC_Utils_V2;
import java.sql.Connection;
import java.sql.PreparedStatement;
/**
* ClassName: BankDao
* Package: com.atguigu.api.PreparedStatement.TransAction
* Description:
* bank表的数据库操作方法存储类
*/
public class BankDao {
/**
* 加钱的数据库操作方法 (JDBC)
*
* @param account 加钱的行号
* @param money 加钱的金额
*/
public void add(String account, double money) throws Exception {
Connection connection = JDBC_Utils_V2.getConnection();
String sql = "update t_bank set money = money + ? where account = ?;";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setObject(1, money);
preparedStatement.setObject(2, account);
int i = preparedStatement.executeUpdate();
preparedStatement.close();
System.out.println("加钱成功!");
}
/**
* 减钱的数据库操作方法 (JDBC)
*
* @param account 减钱的行号
* @param money 减钱的金额
*/
public void sub(String account, double money) throws Exception {
Connection connection = JDBC_Utils_V2.getConnection();
String sql = "update t_bank set money = money - ? where account = ?;";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setObject(1, money);
preparedStatement.setObject(2, account);
int i = preparedStatement.executeUpdate();
preparedStatement.close();
System.out.println("减钱成功!");
}
}
(三)高级应用封装BaseDao

针对DQL查询和非DQL查询,分成两类(即,定义两个方法)
(1)老师(笔记里)给的代码
public abstract class BaseDao {
/*
通用的增、删、改的方法
String sql:sql
Object... args:给sql中的?设置的值列表,可以是0~n
*/
protected int update(String sql,Object... args) throws SQLException {
// 创建PreparedStatement对象,对sql预编译
Connection connection = JDBCTools.getConnection();
PreparedStatement ps = connection.prepareStatement(sql);
//设置?的值
if(args != null && args.length>0){
for(int i=0; i<args.length; i++) {
ps.setObject(i+1, args[i]);//?的编号从1开始,不是从0开始,数组的下标是从0开始
}
}
//执行sql
int len = ps.executeUpdate();
ps.close();
//这里检查下是否开启事务,开启不关闭连接,业务方法关闭!
//connection.getAutoCommit()为false,不要在这里回收connection,由开启事务的地方回收
//connection.getAutoCommit()为true,正常回收连接
//没有开启事务的话,直接回收关闭即可!
if (connection.getAutoCommit()) {
//回收
JDBCTools.free();
}
return len;
}
/*
通用的查询多个Javabean对象的方法,例如:多个员工对象,多个部门对象等
这里的clazz接收的是T类型的Class对象,
如果查询员工信息,clazz代表Employee.class,
如果查询部门信息,clazz代表Department.class,
返回List<T> list
*/
protected <T> ArrayList<T> query(Class<T> clazz,String sql, Object... args) throws Exception {
// 创建PreparedStatement对象,对sql预编译
Connection connection = JDBCTools.getConnection();
PreparedStatement ps = connection.prepareStatement(sql);
//设置?的值
if(args != null && args.length>0){
for(int i=0; i<args.length; i++) {
ps.setObject(i+1, args[i]);//?的编号从1开始,不是从0开始,数组的下标是从0开始
}
}
ArrayList<T> list = new ArrayList<>();
ResultSet res = ps.executeQuery();
/*
获取结果集的元数据对象。
元数据对象中有该结果集一共有几列、列名称是什么等信息
*/
ResultSetMetaData metaData = res.getMetaData();
int columnCount = metaData.getColumnCount();//获取结果集列数
//遍历结果集ResultSet,把查询结果中的一条一条记录,变成一个一个T 对象,放到list中。
while(res.next()){
//循环一次代表有一行,代表有一个T对象
T t = clazz.newInstance();//要求这个类型必须有公共的无参构造
//把这条记录的每一个单元格的值取出来,设置到t对象对应的属性中。
for(int i=1; i<=columnCount; i++){
//for循环一次,代表取某一行的1个单元格的值
Object value = res.getObject(i);
//这个值应该是t对象的某个属性值
//获取该属性对应的Field对象
//String columnName = metaData.getColumnName(i);//获取第i列的字段名
//这里再取别名可能没办法对应上
String columnName = metaData.getColumnLabel(i);//获取第i列的字段名或字段的别名
Field field = clazz.getDeclaredField(columnName);
field.setAccessible(true);//这么做可以操作private的属性
field.set(t, value);
}
list.add(t);
}
res.close();
ps.close();
//这里检查下是否开启事务,开启不关闭连接,业务方法关闭!
//没有开启事务的话,直接回收关闭即可!
if (connection.getAutoCommit()) {
//回收
JDBCTools.free();
}
return list;
}
//目的主要是安全保障,提高代码的健壮性
protected <T> T queryBean(Class<T> clazz,String sql, Object... args) throws Exception {
ArrayList<T> list = query(clazz, sql, args);
if(list == null || list.size() == 0){
return null;
}
return list.get(0);
}
}
(2)我自己写的,该代码主要看注释,促进理解
* 这个代码可能会有问题
* 如果是为了运行成功,那就用老师给的代码
package com.atguigu.api.utils;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
/**
* ClassName: BaseDao
* Package: com.atguigu.api.utils
* Description:
* 封装dao层重复的代码!
* TODO:
* 封装两个方法: 1.简化非DQL 2.简化DQL
*/
public abstract class BaseDao {
/**
* 封装简化非DQL语句
* 非DQL语句封装方法 -> 返回值 固定为int
* @param sql 带占位符的SQL语句
* @param params 占位符的值 注意:传入占位符的值,必须和SQL语句中'?'的位置相一致
* @return 返回执行影响的行数
*/
public int executeUpdate(String sql, Object... params) throws SQLException {
//获取连接
Connection connection = JDBC_Utils_V2.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//占位符赋值
//可变参数可以当作数组使用
for (int i = 1; i <= params.length; i++) {
preparedStatement.setObject(i, params[i - 1]);
}
//发送SQL语句
//DML类型
int rows = preparedStatement.executeUpdate();
//释放与回收
preparedStatement.close();
//是否回收连接,需要考虑是不是事务!
if (connection.getAutoCommit()) {
//结果为true,说明没有开启事务(说明没有关闭自动提交-autoCommit),正常回收
JDBC_Utils_V2.RecycleConnection();
}
//结果为false,开启事务的话就不要管连接,让业务层(Service)处理事务提交的开启和关闭!
//connection.setAutoCommit(false);
return rows;
}
/**
* DQL语句封装方法 -> 该方法的返回值是什么类型? 是List<T>类型。即,返回的是某个类型的实体类集合,而不是List<map>
* 虽然 map的 优点是: key和value自定义,不用先设定好!
* 但是缺点是: 没有数据校验机制
* 不支持反射操作
* 数据库类型 对应着 java的实体类
* 例: 数据库中table是t_user 表中列名有 - id account password nickname
* 那么 java中就会对应着有 User类 类中属性包含 id account password nickname
* 即,表中的一行 -> jav实体类的一个对象 ,表中多行 -> java中List<Java实体类> list
*
*
* <T>表示的是声明一个泛型,即不确定类型。好处:
* - 反射的时候,可以确定泛型的类型 User.class T = User
* - 要使用反射技术为属性赋值
* public <T> List<T> executeQuery(Class<T> clazz, String sql, Object... params)
*/
/**
* 将查询结果封装到一个实体类集合
*
* @param clazz 要接收返回值类型是实体类集合的模板对象
* @param sql 查询语句,要求列名或者别名 对应上 实体类的属性名 例: mysql: u_Id as uId <=> java: uId
* @param params 占位符的值要和'?'的位置相对应
* @param <T> 声明的结果的泛型
* @return 返回查询的实体类集合
* @throws SQLException
* @throws InstantiationException
* @throws IllegalAccessException
* @throws NoSuchMethodException
* @throws InvocationTargetException
* @throws NoSuchFieldException
*/
public <T> List<T> executeQuery(Class<T> clazz, String sql, Object... params) throws SQLException, InstantiationException, IllegalAccessException, NoSuchMethodException, InvocationTargetException, NoSuchFieldException {
Connection connection = JDBC_Utils_V2.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//占位符赋值
if (params != null && params.length > 0) {
for (int i = 1; i <= params.length; i++) {
preparedStatement.setObject(i, params[i - 1]);
}
}
//发送SQL语句
ResultSet resultSet = preparedStatement.executeQuery();
//结果集解析
ArrayList<T> list = new ArrayList<>();
//获取列的信息对象
ResultSetMetaData metaData = resultSet.getMetaData();
int columnCount = metaData.getColumnCount();
while (resultSet.next()) {
//调用类的无参构造函数来实例化对象
T t = clazz.getDeclaredConstructor().newInstance();
//自动遍历列 注意:要从1开始,并且小于等于总列数
for (int i = 1; i <= columnCount; i++) {
//获取对象的属性值
Object value = resultSet.getObject(i);
//TODO:根据索引下标(1,2,......)来获取与之相对应的列的列名
String propertyName = metaData.getColumnLabel(i);
//反射,给对象的属性值赋值
Field field = clazz.getDeclaredField(propertyName);
field.setAccessible(true);//属性可以设置成打破private的修饰限制
/**
* field.set(param1,param2)
* 参数1: 要赋值的对象 如果属性是静态,那么第一个参数可以为null
* 参数2: 具体的属性值
*/
field.set(t, value);
}
//把实体类对象放到集合中
list.add(t);
}
//关闭资源
resultSet.close();
preparedStatement.close();
if (connection.getAutoCommit()) {
//如果没有开启事务 则可以关闭
JDBC_Utils_V2.RecycleConnection();
}
return list;
}
protected <T> ArrayList<T> query(Class<T> clazz, String sql, Object... args) throws Exception {
//创建PreparedStatement对象,对sql预编译
Connection connection = JDBC_Utils_V2.getConnection();
PreparedStatement ps = connection.prepareStatement(sql);
//设置?的值
if (args != null && args.length > 0) {
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);//?的编号从1开始,不是从0开始,数组的下标是从0开始
}
};
/*
获取结果集的元数据对象。
元数据对象中有该结果集的信息,例如:一共有几列、列名称是什么,等等
*/
ResultSet res = ps.executeQuery();
ResultSetMetaData metaData = res.getMetaData();
int columnCount = metaData.getColumnCount();//获取结果集列数
//遍历结果集ResultSet,把查询结果中的一条一条记录,变成一个一个 T对象 ,放到list中。
ArrayList<T> list = new ArrayList<>();
while (res.next()) {
//循环一次代表遍历了表中的一行,代表获取了一个T对象
T t = clazz.newInstance();//要求这个类型必须有公共的无参构造
//把这条记录的每一个单元格的值取出来,设置到t对象对应的属性中。
for (int i = 1; i <= columnCount; i++) {
//for循环一次,则根据 索引值从小到大(1,2,……) 取表的某一行数据中的1个单元格的值
Object value = res.getObject(i);
//这个值应该是t对象的某个属性值
//获取该属性对应的Field对象。 例: 类里的一个name属性 对应 其一个name属性的Field对象
// String columnName = metaData.getColumnName(i);//获取第i列的字段名
String columnName = metaData.getColumnLabel(i);//获取第i列的字段名或字段的别名
Field field = clazz.getDeclaredField(columnName);
field.setAccessible(true);//这么做可以操作private的属性
field.set(t, value);
}
list.add(t);
}
res.close();
ps.close();
//这里检查下是否开启事务,开启不关闭连接,业务方法关闭!
//没有开启事务的话,直接回收关闭即可!
if (connection.getAutoCommit()) {
//回收
JDBC_Utils_V2.RecycleConnection();
}
return list;
}
}
六、基于CMS项目的JDBC实战练习
(一)CMS项目介绍和导入
1.项目介绍





2.项目导入
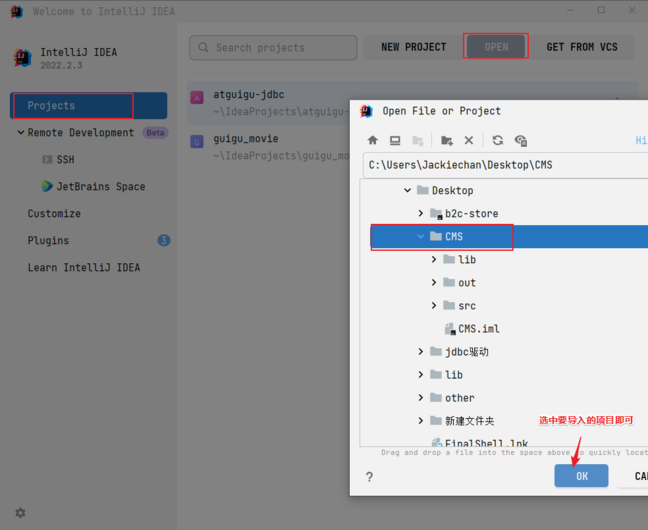
(1)打开项目
(2)配置JDK
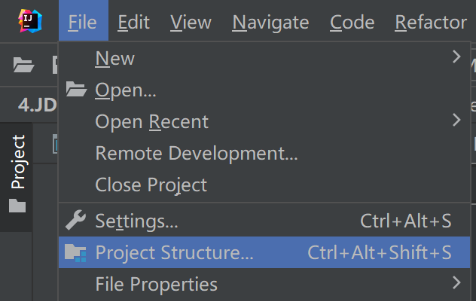
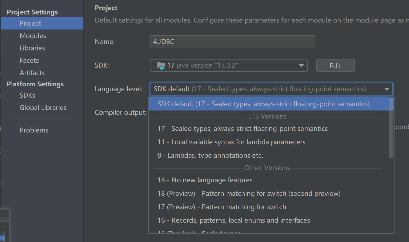
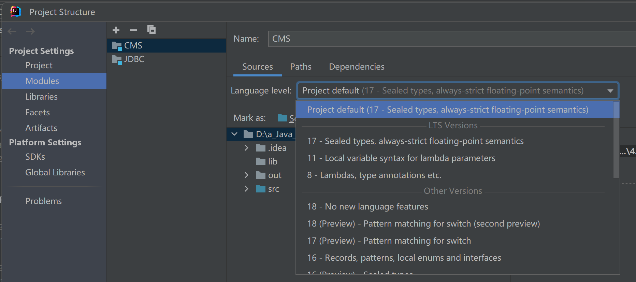
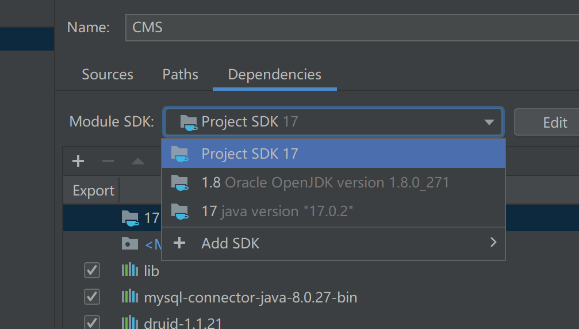
- 统一配置成17的

(二)基于CMS项目添加数据库相关配置
1.准备数据库脚本
-- 员工表
CREATE TABLE t_customer(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '客户主键',
NAME VARCHAR(20) COMMENT '客户名称',
gender VARCHAR(4) COMMENT '客户性别',
age INT COMMENT '客户年龄',
salary DOUBLE(8,1) COMMENT '客户工资',
phone VARCHAR(11) COMMENT '客户电话')
2.添加配置文件

# druid连接池需要的配置参数,key固定命名
driverClassName=com.mysql.cj.jdbc.Driver
username=root
password=root
url=jdbc:mysql:///atguigu
3.导入jdbcv2.0工具类
package com.atguigu.cms.utils;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
/*
这个工具类的作用就是用来给所有的SQL操作 提供“连接” 和 释放连接 。
这里使用ThreadLocal的目的是为了让同一个线程,在多个地方getConnection得到的是同一个连接。
这里使用DataSource的目的: (1)限制服务器的连接的上限 (2)连接的重用性等
*/
public class JDBCTools {
private static DataSource ds;
private static ThreadLocal<Connection> tl = new ThreadLocal<>();
static {//静态代码块,JDBCToolsVersion1类初始化执行
try {
Properties pro = new Properties();
pro.load(ClassLoader.getSystemResourceAsStream("druid.properties"));
ds = DruidDataSourceFactory.createDataSource(pro);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection() throws SQLException {
Connection connection = tl.get();
if (connection == null) {//当前线程还没有拿过连接,就给它从数据库连接池拿一个
connection = ds.getConnection();
tl.set(connection);
}
return connection;
}
public static void free() throws SQLException {
Connection connection = tl.get();
if (connection != null) {
tl.remove();
connection.setAutoCommit(true);//避免还给数据库连接池的连接不是自动提交模式(建议)
connection.close();
}
}
}
4.导入baseDao工具类
package com.atguigu.cms.utils;
import java.lang.reflect.Field;
import java.sql.*;
import java.util.ArrayList;
public abstract class BaseDao {
/*
通用的增、删、改的方法
String sql:sql
Object... args:给sql中的?设置的值列表,可以是0~n
*/
protected int update(String sql, Object... args) throws SQLException {
// 创建PreparedStatement对象,对sql预编译
Connection connection = JDBCTools.getConnection();
PreparedStatement ps = connection.prepareStatement(sql);
//设置?的值
if (args != null && args.length > 0) {
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);//?的编号从1开始,不是从0开始,数组的下标是从0开始
}
}
//执行sql
int len = ps.executeUpdate();
ps.close();
//这里检查下是否开启事务,开启不关闭连接,业务方法关闭!
//没有开启事务的话,直接回收关闭即可!
if (connection.getAutoCommit()) {
//回收
JDBCTools.free();
}
return len;
}
/*
通用的查询多个Javabean对象的方法,例如:多个员工对象,多个部门对象等
这里的clazz接收的是T类型的Class对象,
如果查询员工信息,clazz代表Employee.class,
如果查询部门信息,clazz代表Department.class,
*/
protected <T> ArrayList<T> query(Class<T> clazz, String sql, Object... args) throws Exception {
// 创建PreparedStatement对象,对sql预编译
Connection connection = JDBCTools.getConnection();
PreparedStatement ps = connection.prepareStatement(sql);
//设置?的值
if (args != null && args.length > 0) {
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);//?的编号从1开始,不是从0开始,数组的下标是从0开始
}
}
ArrayList<T> list = new ArrayList<>();
ResultSet res = ps.executeQuery();
/*
获取结果集的元数据对象。
元数据对象中有该结果集一共有几列、列名称是什么等信息
*/
ResultSetMetaData metaData = res.getMetaData();
int columnCount = metaData.getColumnCount();//获取结果集列数
//遍历结果集ResultSet,把查询结果中的一条一条记录,变成一个一个T 对象,放到list中。
while (res.next()) {
//循环一次代表有一行,代表有一个T对象
T t = clazz.newInstance();//要求这个类型必须有公共的无参构造
//把这条记录的每一个单元格的值取出来,设置到t对象对应的属性中。
for (int i = 1; i <= columnCount; i++) {
//for循环一次,代表取某一行的1个单元格的值
Object value = res.getObject(i);
//这个值应该是t对象的某个属性值
//获取该属性对应的Field对象
// String columnName = metaData.getColumnName(i);//获取第i列的字段名
String columnName = metaData.getColumnLabel(i);//获取第i列的字段名或字段的别名
Field field = clazz.getDeclaredField(columnName);
field.setAccessible(true);//这么做可以操作private的属性
field.set(t, value);
}
list.add(t);
}
res.close();
ps.close();
//这里检查下是否开启事务,开启不关闭连接,业务方法关闭!
//没有开启事务的话,直接回收关闭即可!
if (connection.getAutoCommit()) {
//回收
JDBCTools.free();
}
return list;
}
protected <T> T queryBean(Class<T> clazz, String sql, Object... args) throws Exception {
ArrayList<T> list = query(clazz, sql, args);
if (list == null || list.size() == 0) {
return null;
}
return list.get(0);
}
}
(三)基于CMS项目实战
1.CustomerService
package com.atguigu.cms.service;
import com.atguigu.cms.dao.CustomerDao;
import com.atguigu.cms.javabean.Customer;
import java.sql.SQLException;
import java.util.List;
/**
* 这是一个具有管理功能的功能类. 内部数据不允许外部随意修改, 具有更好的封装性.
*/
public class CustomerService {
private CustomerDao customerDao = new CustomerDao();
/**
* 用途:返回所有客户对象
* 返回:集合
*/
public List<Customer> getList() {
try {
return customerDao.queryList();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 用途:添加新客户
* 参数:customer指定要添加的客户对象
*/
public void addCustomer(Customer customer) {
try {
customerDao.insertCustomer(customer);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
/**
* 用途:返回指定id的客户对象记录
* 参数: id 就是要获取的客户的id号.
* 返回:封装了客户信息的Customer对象
*/
public Customer getCustomer(int id) {
try {
return customerDao.queryById(id);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 用途:修改指定id号的客户对象的信息
*
* @param id 客户id
* @param cust 对象
* @return 修改成功返回true, false表明指定id的客户未找到
*/
public boolean modifyCustomer(int id, Customer cust) {
int rows = 0;
try {
rows = customerDao.updateCustomer(cust);
} catch (SQLException e) {
throw new RuntimeException(e);
}
return rows > 0;
}
/**
* 用途:删除指定id号的的客户对象记录
* 参数: id 要删除的客户的id号
* 返回:删除成功返回true;false表示没有找到
*/
public boolean removeCustomer(int id) {
int rows = 0;
try {
rows = customerDao.deleteCustomer(id);
} catch (SQLException e) {
throw new RuntimeException(e);
}
return rows > 0;
}
}
2.CustomerDao
package com.atguigu.cms.dao;
import com.atguigu.cms.javabean.Customer;
import com.atguigu.cms.utils.BaseDao;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
/**
* Description: 客户进行数据库操作的类
*/
public class CustomerDao extends BaseDao {
public List<Customer> queryList() throws Exception {
ArrayList<Customer> list = query(Customer.class, "select * from t_customer");
return list;
}
public void insertCustomer(Customer customer) throws SQLException {
int rows = update("insert into t_customer(name,gender,age,salary,phone) values (?,?,?,?,?)",
customer.getName(), customer.getGender(), customer.getAge(), customer.getSalary(), customer.getPhone());
}
public Customer queryById(int id) throws Exception {
Customer customer = queryBean(Customer.class, "select * from t_customer where id = ?", id);
return customer;
}
public int deleteCustomer(int id) throws SQLException {
return update("delete from t_customer where id =?", id);
}
public int updateCustomer(Customer cust) throws SQLException {
return update("update t_customer set name = ? , gender = ? , age = ? ," +
"salary = ? , phone = ? where id = ? ;", cust.getName(), cust.getGender(),
cust.getAge(), cust.getSalary(), cust.getPhone(), cust.getId());
}
}















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









