






 StreamTokenizer是一个用于解析文本流的类,它可以识别数字、单词、行结束符和文件结束符。nval和sval字段分别存储数字和单词值,ttype记录token类型。可以通过wordChars和whitespaceChars方法自定义词和空白字符。构造器默认设置了字母和某些特殊字符的规则,nextToken方法用于解析下一个token。在处理键盘输入时,需将
设置为ordinary字符以避免死循环。
StreamTokenizer是一个用于解析文本流的类,它可以识别数字、单词、行结束符和文件结束符。nval和sval字段分别存储数字和单词值,ttype记录token类型。可以通过wordChars和whitespaceChars方法自定义词和空白字符。构造器默认设置了字母和某些特殊字符的规则,nextToken方法用于解析下一个token。在处理键盘输入时,需将
设置为ordinary字符以避免死循环。
Tokenizer: n. 分词器
所以StreamTokenizer是流令牌化?(雾)
- Field (public):
nval: double //number value
If the current token is a number, this field contains the value of that number.
如果当前分析的token是数字,则nval会包含这个数字的值
sval: :String //string value
If the current token is a word token, this field contains a string giving the characters of the word token.
如果当前分析的token是word,则nval会包含这个数字的值
TT_EOF: static int //token type end of file
A constant indicating that the end of the stream has been read.
public static final int TT_EOF = -1; //stream读到文件末尾也是返回-1
TT_EOL: static int //token type end of line
A constant indicating that the end of the line has been read.
public static final int TT_EOL = '\n';
TT_NUMBER : static int
A constant indicating that a number token has been read.
public static final int TT_NUMBER = -2;
TT_WORD: static int
A constant indicating that a word token has been read.
public static final int TT_WORD = -3;
ttype: int
After a call to the nextToken method, this field contains the type of the token just read.
调用nextToken()后,该token的token类型会保存在ttype中
小总结:
token的类型有4种,number,word,行结束,文件结束
nval保存着当前token的number值(如果是的话)
sval保存着当前token的word值(如果是的话)
tips:
number类型 0123 可以被分析为nval=123.0 ,即0开头会自动忽略//感觉写算法中有用(喜
2.其实还有一个private的类型:private static final int TT_NOTHING = -4;
3.在声明ttype时默认赋值为TT_NOTHING: public int ttype = TT_NOTHING;
实际上这些public的Field是与private的Field对应
private byte ctype[] = new byte[256];
private static final byte CT_WHITESPACE = 1; //分割符(包括结束符)类型(类似string.split("reg") 里的那个reg)
private static final byte CT_DIGIT = 2; //用于判断number类型
private static final byte CT_ALPHA = 4; //用于判断word类型
private static final byte CT_QUOTE = 8;
private static final byte CT_COMMENT = 16;
这些赋值保证了数值位只有一位非0,便于后面位运算判断是否想等
其实应该还有一个ordinary,默认值应该是0,在nextToken最下面写着return ttype = c;
个人理解ordinary是游离于以上类型之外的类型,就类似switch里的default,当所有类型都不匹配时就是ordinary
当分析的token是ordinary时,nval和sval都不能得到这个值,这个值会以char对应的ASCII值保存在ttype中
如:streamTokenizer.ordinaryChar('1');
此时调用System.out.println("i = " + streamTokenizer.nextToken()); //输出49,因为ASCII中1对应49
nextToken()返回值是(?)ttype
这些愿意深究的同学建议去分析源码😘
- Constructors (public):
StreamTokenizer(InputStream is)
参数是一个InputStream,现官方不建议用(Deprecated),建议使用下一个
StreamTokenizer(Reader r)
参数是一个Reader
//用键盘输入-> ... -> StreamTokenizer
tips: StreamTokenizer应该不是修饰流,它只是对里面的流数据进行分割,它没有close方法,自然不能关闭里面的流,所以个人建议将BufferedReader声明在StreamTokenizer外并手动关闭
//System.in 标准输入流,从键盘读取数据
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StreamTokenizer in = new StreamTokenizer(br);
br.close();//自带异常需要处理tips:上面两个public的构造器其实都调用了private的构造器
private StreamTokenizer() {
wordChars('a', 'z');
wordChars('A', 'Z');
wordChars(128 + 32, 255);
whitespaceChars(0, ' ');
commentChar('/');
quoteChar('"');
quoteChar('\'');
parseNumbers();
}实现默认的StreamTokenizer语法规则:
All byte values 'A' through 'Z', 'a' through 'z', and '\u00A0' through '\u00FF' are considered to be alphabetic.
a-z, A-Z, 中文以及中文标点(英文的标点属于ordinaryChar),以及字母开头后跟数字都认为是word类型
其实输入字符转为数字只要是大于256的都认为是word?
源码:int ctype = c < 256 ? ct[c] : CT_ALPHA;
默认格式都是ordinaryChar,没显示写成的都是ordinaryChar
All byte values '\u0000' through '\u0020' are considered to be white space.
'/' is a comment character.
Single quote '\'' and double quote '"' are string quote characters.
Numbers are parsed.
Ends of lines are treated as white space, not as separate tokens.
C-style and C++-style comments are not recognized.
注:以下只介绍几个目前常用的4个方法: nextToken(), wordChars(int low, int hi),
whitespaceChars(int low, int hi),ordinaryChar(int ch)/ordinaryChars(int low, int hi)
其它的不常用。
- Method (public):
nextToken(): int
Parses the next token from the input stream of this tokenizer.
分析token值,返回值是ttype(可以这么理解),对应那几个全局常量
如果是StreamTokenizer.TT_WORD ,其值会保存在sval中
如果是StreamTokenizer.TT_NUMBER ,其值会保存在nval中
使用举例:
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StreamTokenizer in = new StreamTokenizer(br);
PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out)), true);
in.ordinaryChar('\n');//这个是必要的!
int type;
while ((type = in.nextToken()) != StreamTokenizer.TT_EOL) {//从键盘读取,回车后结束输入
System.out.println("type = " + type);//数字: -2,字符串: -3, ordinary是ASCII码
switch (type) {
case StreamTokenizer.TT_NUMBER:
System.out.println("nval = " + in.nval);
break;
case StreamTokenizer.TT_WORD:
System.out.println("sval = " + in.sval);
break;
default: //这里排除EOL和EOF,其实就ordinary
System.out.println("char = " + (char) type);
break;
}
}
out.close();
br.close();
}ordinaryChar(int ch): void
Specifies that the character argument is "ordinary" in this tokenizer.
ordinaryChars(int low, int hi): void
Specifies that all characters c in the range low <= c <= high are "ordinary" in this tokenizer.
这两个方法都是将传入的字符设置为普通类型,参数是int类型,但实际上我们只要以'\n'
这样char型传入即可,即可将'\n'设置为ordinary字符
那么何谓ordinary呢?
对于这种概念性的问题可能是作者才解释的问题,作为使用者,我想我们只要了解区别于其他类型的特性即可。
以区别于其它类型值的特性表示为:
类型不同,故调用nextToken()后,其token值不会保存在nval和sval中,而是以char对应ASCII值的形式保存在ttpye中,也可以看作以nextToken()返回值的形式返回。
不同于number类型和word类型,每次调用nextToken只读取一个ordinary字符
调用nextToken()分析ordinary字符后,nval置为0.0,sval置为null(不是字符串"null",故由于ordinary类型的字符存在,不加区分的调用sval并使用可能导致空指针异常)
源码里ordinary类型对应的byte[]每个值都是0
whitespaceChars(int low, int hi): void
Specifies that all characters c in the range low <= c <= high are white space characters.
将传入的参数范围内的字符(char的ASCII码对应值),设置为分割符类型
利用这个方法可以实现指定哪些字符为分割符不考虑,
如 a:=1; 我只想取有效的a和1,可以调用此方法
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StreamTokenizer in = new StreamTokenizer(br);
PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out)), true);
in.ordinaryChar('\n');
in.whitespaceChars(':', ':');
in.whitespaceChars('=', '=');
int type;
while ((type = in.nextToken()) != StreamTokenizer.TT_EOL) {
System.out.println("type = " + type);//数字: -2,字符串: -3, ordinary是ASCII码
switch (type) {
case StreamTokenizer.TT_NUMBER:
System.out.println("nval = " + in.nval);
break;
case StreamTokenizer.TT_WORD:
System.out.println("sval = " + in.sval);
break;
default: //这里排除EOL和EOF,其实就ordinary
System.out.println("char = " + (char) type);
break;
}
}
out.close();
br.close();
}
wordChars(int low, int hi): void
Specifies that all characters c in the range low <= c <= high are word constituents.
将传入的参数范围内的字符(char的ASCII码对应值),设置为word类型
public void wordChars(int low, int hi) {
if (low < 0)
low = 0;
if (hi >= ctype.length)
hi = ctype.length - 1;
while (low <= hi)
ctype[low++] |= CT_ALPHA;
}重点:不是直接赋值,而是有一个按位或的操作
ctype[low++] |= CT_ALPHA;可见,只有ordinary类型的字符才能直接word化,因为只有ordinary类型字符所有位才全是0
数字类型ctype: CT_DIGIT = 2(D) = 0000 0010(B) 与 CT_ALPHA = 4(D) = 0000 0100(B)
按位或最终的到的字符类型啥也不是,故想将数字直接word是不行的!
tips: 只有word化字符是 |= 赋值,其他whitespaceChars,ordinaryChar,commentChar,quoteChar都是直接=赋值,可以直接转
利用这个方法可以将其它类型的字符转换为字符串,进而使用String丰富的方法
如:有时我们就想将数字以字符串的形式接收,可以利用此方法和ordinaryChar()来实现
默认分割符是[0, ' '],要获得一句话,空格也包含在内,也可以利用此方法去除空格符的分割属性
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StreamTokenizer in = new StreamTokenizer(br);
PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out)), true);
in.ordinaryChars('\n', '\n');
in.ordinaryChars('0', '9');
in.wordChars('0', '9');
//下面的含 空格 ! " # 等,直到 /
in.wordChars(' ','/');
int type;
while ((type = in.nextToken()) != StreamTokenizer.TT_EOL) {
//数字: -2,字符串: -3, ordinary是ASCII码
System.out.println("type = " + type);
switch (type) {
case StreamTokenizer.TT_NUMBER:
System.out.println("nval = " + in.nval);
break;
case StreamTokenizer.TT_WORD:
System.out.println("sval = " + in.sval);
break;
default: //这里排除EOL和EOF,其实就ordinary
System.out.println("char = " + (char) type);
break;
}
}
out.close();
br.close();
}
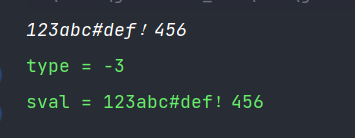

以数字开头但不会认为是字符串
注:数字必须先设置为普通字符类型,不能直接转为word类型
即in.ordinaryChars('0', '9');是必要的!
将这个注释调则数字开头不会认为是word,而是认为是number
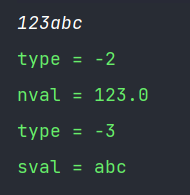
这是因为在private的构造器中,有parseNumbers(); 优先以数字类型分析,同样的如果我们在设置完in.ordinaryChars('0', '9')和in.wordChars('0', '9')后又调用parseNumbers(),还是数字开头,就不会以认为是字符串,而是看作是数字。
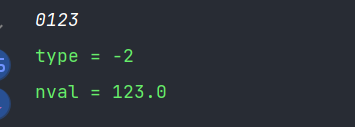
此外,以负号-开头也会导致认为是数字,想解决这个问题,也需要将-先设置为ordinaryChars再wordChars
in.ordinaryChars('-','-');
in.wordChars('-','-');如果没有把0设置为ordinaryChars和wordChars开头也会认为是数字
in.ordinaryChars('1', '9'); in.wordChars('1', '9');
小数点开头其实也会导致认为是数字,但没人会这么写小数吧~
非要考虑极端条件可以这么写
in.ordinaryChars('-','9');
in.wordChars('-','9');或
in.ordinaryChars('-','/' - 1);
in.ordinaryChars('/' + 1,'9');
in.wordChars('-','/' - 1);
in.wordChars('/' + 1,'9');注:['-', '9']这个区间多加了一个 /,而/是注释符号,在/之后的所有字符都将被忽略
注:只有关系到数字的才要先调用ordinaryChars(),其它的字符可以直接调wordChars()转的
将ASCII表中所有可见字符转为word类型
in.ordinaryChars('-', '/' - 1);
in.ordinaryChars('/' + 1,'9');
in.wordChars(' ', 'A' - 1);
in.wordChars('Z' + 1, 'a' - 1);
in.wordChars('z' + 1, 126);不那么最求效率,便于记忆就将'/'一并ordinary化
in.ordinaryChars('-','9');
in.wordChars(' ', 'A' - 1);
in.wordChars('Z' + 1, 'a' - 1);
in.wordChars('z' + 1, 126);tips: 这个循环中'\n'必须设置为ordinary,否则token分析不到EOL,不将'\n'ordinary化会导致死循环
in.ordinaryChars('\n', '\n');
while ((type = in.nextToken()) != StreamTokenizer.TT_EOL) {
//...
}以上是本文的重点,赶时间的同学可以划走了,下面的方法不用看,也不常用(我也没仔细看hhh)
toString(): String
Returns the string representation of the current stream token and the line number it occurs on.
返回当前流标记的字符串表示形式和它所在的行号。
就是这个格式,感觉debug时用?
Token['a'], line 10
lineno(): int
Return the current line number.
返回当前行号。
用System.in一般都是行结束输入结束,这个用在文件输入的场景下才有意义
quoteChar(int ch) : void
Specifies that matching pairs of this character delimit string constants in this tokenizer.
指定此字符的匹配对在此标记器中分隔字符串常量。
默认的引号是单引号' 和双引号 " , 作用是引号内的东西认为是分割符,但同时这个引号会ordinary化,且被读取到,而使用whitespaceChars(int low, int hi)可以分割并自身被忽略,感觉用whitespaceChars更好
in.quoteChar('1');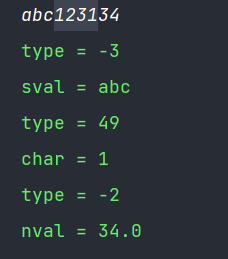
这里 //in.ordinaryChars('-','9'); //in.wordChars('-','9');数字1被认为是ordinary
而且只有半边引号,则相当于注释

slashSlashComments(boolean flag) : void
Determines whether or not the tokenizer recognizes C++-style comments.
// 是C++系注释
slashStarComments(boolean flag) : void
Determines whether or not the tokenizer recognizes C-style comments.
/开始是C系注释(包括/ // /* )
测试两个方法无论是置为双false和双true,注释符号/后面都的内容都会被忽略???看不懂





???
commentChar(int ch) : void
Specified that the character argument starts a single-line comment.
自定义注释字符
默认的都没搞懂(汗
pushBack() : void
Causes the next call to the nextToken method of this tokenizer to return the current value in the ttype field, and not to modify the value in the nval or sval field.
调用nextToken()会ttpye和nval和sval不变
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StreamTokenizer in = new StreamTokenizer(br);
PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out)), true);
in.ordinaryChars('\n', '\n');
int type;
for (int i = 0; i < 2; i++) {
type = in.nextToken();
System.out.println("type = " + type);
in.pushBack();
switch (type) {
case StreamTokenizer.TT_NUMBER:
System.out.println("nval = " + in.nval);
break;
case StreamTokenizer.TT_WORD:
System.out.println("sval = " + in.sval);
break;
default: //这里排除EOL和EOF,其实就ordinary
System.out.println("char = " + (char) type);
break;
}
}
out.close();
br.close();
}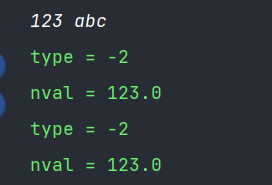
pushBack和nextToken在源码中的实现关系,就是直接返回上一个token
public int nextToken() throws IOException {
if (pushedBack) {//一进来就判断是不是要pushBack
pushedBack = false;
return ttype;
}
//...
}parseNumbers(): void
Specifies that numbers should be parsed by this tokenizer. The syntax table of this tokenizer is modified so that each of the twelve characters:
0 1 2 3 4 5 6 7 8 9 . -
has the "numeric" attribute.
使 0 1 2 3 4 5 6 7 8 9 . - 这12个字符具有数值性,所以以这个开头的都会被分析为数字
lowerCaseMode(boolean fl) : void
Determines whether or not word token are automatically lowercased.
字符转小写
resetSyntax() : void
Resets this tokenizer's syntax table so that all characters are "ordinary." See the ordinaryChar method for more information on a character being ordinary.
重置语法表,把所有的类型都置为ordinary
那自己写一套咯。。。
Method重点总结
1.实现键盘输入,回车结束输入,依据分割符获取每一个token
显然需要循环,而循环条件是while ((type = in.nextToken()) != StreamTokenizer.TT_EOL)
文件读取循环调节只要while ((type = in.nextToken()) != StreamTokenizer.TT_EOF)即可
使用前提是要将结束符'\n' ordinary化,否则死循环
in.ordinaryChars('\n', '\n');
int type;
while ((type = in.nextToken()) != StreamTokenizer.TT_EOL) {
//...
}2.数字word化,要先ordinary化,再word化
in.ordinaryChars('-', '/' - 1);
in.ordinaryChars('/' + 1,'9');
in.wordChars('-','/' - 1);
in.wordChars('/' + 1,'9');或
in.ordinaryChars('-','9');
in.wordChars('-','9');3.ASCII表中所有可见字符word化
in.ordinaryChars('-', '/' - 1);
in.ordinaryChars('/' + 1,'9');
in.wordChars(' ', 'A' - 1);
in.wordChars('Z' + 1, 'a' - 1);
in.wordChars('z' + 1, 126);或
in.ordinaryChars('-','9');
in.wordChars(' ', 'A' - 1);
in.wordChars('Z' + 1, 'a' - 1);
in.wordChars('z' + 1, 126);至此结束
本人也是小白,欢迎讨论补充😋😋😋

















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









