






需要导入的pom文件,resources文档
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.11</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty</artifactId>
</exclusion>
</exclusions>
<version>2.3.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.8.1</version>
</dependency>
idea中的测试代码
package spark
import org.apache.spark.sql.{DataFrame, SparkSession}
object Test {
def main(args: Array[String]): Unit = {
// 设置连接hive元数据库
System.setProperty("HADOOP_USER_HOME","root")
val spark = SparkSession.builder()
.master("local[*]")
.appName("mysql to hive")
.enableHiveSupport()
.config("hive.metastore.uris","thrift://192.168.88.142:9083")
.config("hive.metastore.warehouse.dir","/usr/hive/warehouse")
.getOrCreate()
// 设置需要访问的数据库名
val df: DataFrame = spark.read.format("jdbc")
.option("url","jdbc:mysql://192.168.88.142:3306/ds_db01")
.option("driver","com.mysql.jdbc.Driver")
.option("dbtable","table1")
.option("user", "root")
.option("password", "123")
.load()
// 创建视图
df.createOrReplaceTempView("temp")
// 输出语句
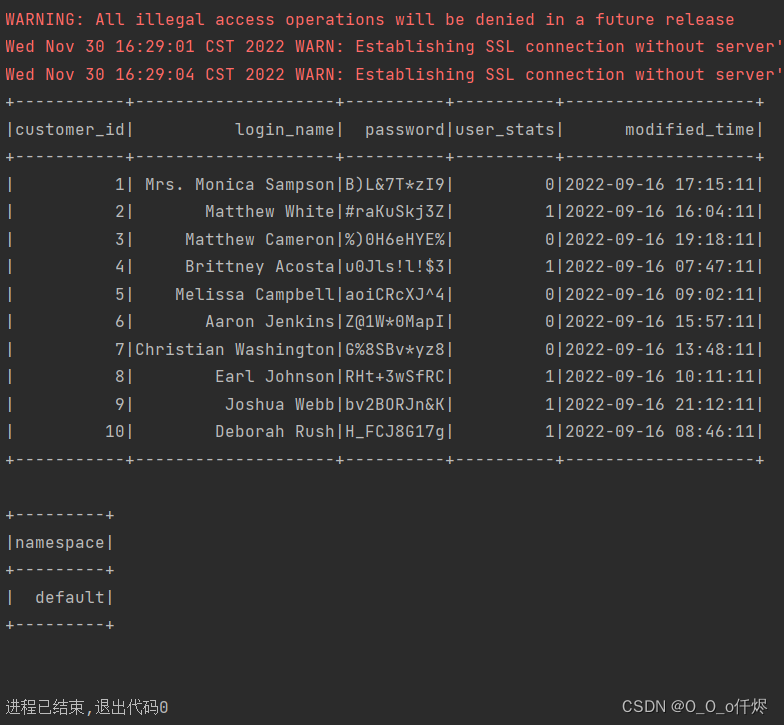
spark.sql("select * from temp limit 10").show()
spark.sql("show databases;").show()
// 结束
spark.stop()
}
}
在虚拟机中hive启动server服务
# 启动 server 服务
hive --service metastore &
运行结果
















 1568
1568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









