






一、设计方案(不少于1200字)
1.1 课题概述
对课题的基本信息进行简要说明。
本课程设计的课题为“招聘信息可视化”,实现的功能为对特定职业的招聘信息进行采集、预处理和可视化展示。
选定“月嫂”为例,利用爬虫技术从多家招聘平台中获取相关信息,并经过数据预处理,数据清洗和统计分析的流程,将结果以柱状图、词云等形式可视化呈现,便于用户直观地了解“月嫂”的价格分布、城市分布、学历要求,经验要求等。
1.2 详细设计
1.2.1 总体方案
对课题的设计原则、运行流程、模块划分等进行说明。模块数量根据设计方案的实际情况进行增减。
本课程设计的总体方案分为以下步骤:
步骤一:爬取招聘信息。使用爬虫技术,从BOSS直聘、前程无忧、智联招聘等多家招聘平台中获取“月嫂”相关招聘信息。
步骤二:数据预处理。对采集到的原始数据进行清洗、去重、剔除虚假信息,对数据进行统一格式等操作,确保数据质量。
步骤三:统计分析。对经过清洗处理后的数据进行统计分析,价格分布、城市分布、学历要求,经验要求,以便从中提取有用的信息。
步骤四:可视化展示。以柱状图、折线图等形式,将统计分析后的数据可视化展示,让用户更加直观地了解“月嫂”相关信息,并且对“月嫂”职业进行深入分析。
1.2.2 模块1
爬取招聘信息
本模块通过爬虫技术,从多个招聘网站上爬取“月嫂”相关的招聘信息。具体实现的流程如下:
首先,需要分析和了解目标网站的页面结构和数据格式,确定需要采集的数据内容和数据存储方式。
然后,利用Python等编程语言编写爬虫程序,根据分析的内容,访问目标网站,并通过分析页面结构和数据格式,确定需要采集数据的xpath或CSS选择器等元素。
先对难度较低的智联招聘和前程无忧网站进行爬取,爬完后发现数据量太少,之后向BOSS直聘进行爬取,使用谷歌浏览器的自动点击脚本,实现搜索,选择地区等操作,由于BOSS只显示出10页数据,所以需要选择更小的范围,所以在爬取时耗费了较多时间。
最后,将采集到的数据存储到本地文件中,并将几个网站的数据合并,以备后续的数据预处理和统计分析使用。
1.2.3 模块2
数据预处理
本模块通过对采集到的招聘信息进行清洗、去重、剔除虚假信息等操作,确保获取的数据质量。
具体实现的流程如下:
首先,需要对数据进行去重处理,将每一列都一样的数据进行删除,以避免重复数据的影响。
然后,需要对数据进行薪资的格式统一化,使用正则表达式将列如8-10k,5千-1万等数据统一化为“5000-6000元/月”的形式。
最后,将少量不符合形式的数据进行删除,并且把每个地区的城市名提取出来,还有把薪资计算平均数提取出来,以便后续进行分析与可视化处理。
1.2.3 模块3
统计分析和可视化展示
本模块将经过预处理的数据进行统计分析,并以柱状图、词云等形式进行可视化展示,从而让用户更加直观地了解“月嫂”相关信息,具体实现的流程如下:
首先,通过数据分析,获取“月嫂”在不同城市和不同学历。不同经验的需求量和工资的高低。将图像与城市GDP对比进行分析,发现在GDP高的城市中对职位的需求量也较高,并且工资也更高。
然后,结合工资分布,将数据可视化展示,以柱状图、折线图等形式呈现价格变化趋势和不同,并且对图形进行更加深入的分析。
二、总结(不少于800字)
对课题的执行情况进行详细说明,包括但不限于已取得的经验、教训,以及今后努力的方向等等。
本次课程设计以“招聘信息可视化”为主题,对特定职业“月嫂”的相关信息进行数据采集、处理和展示。在实现过程中,我们经历了以下步骤:
1. 确定课题和技术要求。
2. 分析招聘网站,确定数据采集方式。
3. 编写爬虫程序,爬取相关招聘信息。
4. 对采集到的数据进行格式化和清洗处理。
5. 对处理后的数据进行了可视化展示,对图形进行深入的数据分析。
在完成课程设计过程中,收获了很多效益和体会:
首先,我们学习到了很多有关数据采集、数据处理和数据可视化的知识,加强了我们对这一方面的了解和实践能力。
其次,我们了解到了爬虫程序的运行原理和应用场景,掌握了Python编程技术,深入理解了XPath、CSS 选择器等爬虫技术的运用方式。
但是,我们也遇到了许多问题和挑战。其中最主要的问题是难以保证数据的准确性和全面性。我们通过反复清洗数据来尽可能保证数据质量,但是依旧有些数据仍无法得到完美的清洗,所以之后我直接将不符合格式的少量数据进行了删除。此外,计算机性能对程序的速度和效率都有很大影响,可以采取多线程来跑两个爬虫代码以此加快爬取速度。我们需要更加深入地学习计算机原理和编程技术。
从以上的经验和教训中,我们发现需要在以下方面加以改进:
1. 提高数据质量。除了清洗数据之外,我们还要强化对数据的验证和审核,最大程度地保证数据的准确性和全面性。
2. 加强计算机基础知识的学习。通过学习机器学习、算法设计与分析、操作系统等课程,进一步理解和熟练掌握计算机原理和技术。
3. 拓展应用场景。不仅局限于对招聘信息的采集和分析,还可以将所学知识应用到更广泛的领域中,如商业数据分析、社交媒体数据挖掘等。
总之,本次课程设计给我们提供了实践机会,让我们理解到数据采集、处理和可视化的重要性,掌握了许多实用技能。在今后的学习和工作中,我们将不断提高自身技能和能力,不断创新、勇于尝试,不断追求更高质量和更好的效果,最终取得更大的成功和成就。
部分代码
爬虫代码:
BOSS招聘:
import csv
import random
import time
from lxml import etree
from selenium import webdriver
# 实现规避检测
from selenium.webdriver import ChromeOptions
# 实现无可视化界面的
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver import Edge
# 实现规避检测
from selenium.webdriver import EdgeOptions
# 去除浏览器识别,去除Edge正在受到自动检测软件的控制
# edge_options = EdgeOptions()
# edge_options.add_experimental_option('excludeSwitches', ['enable-automation'])
# edge_options.add_experimental_option('detach', True)
# edge_options.add_argument("'user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'")
# 设置代理,如果需要的话
# edge_options.add_argument("--proxy-server=http://ip:port")
# web = Edge( options=edge_options)
chrome_options = ChromeOptions()
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
chrome_options.add_experimental_option('detach', True)
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
options = Options()
options.add_argument('--headless') # 设置为无头
options.add_argument('--disable-gpu') # 设置没有使用gpu
options.add_argument(
'user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
# 实例化一个浏览器对象(传入浏览器的驱动程序)
web = webdriver.Chrome(chrome_options=chrome_options, options=options)
# cookie_dict = {
# 'name': 'YD00951578218230%3AWM_NIKE',
# 'value': '9ca17ae2e6ffcda170e2e6eea4ea59b6ad8d94e83bb1a88fa7c45f879e8f82d46195b1a294cf59a593aebbae2af0fea7c3b92a819bba97d442b2b88995c279838b8db5e125a6868ad3f259b48bbaa9e1449b8ffd96f564f399a68db180a39afeb7f04386b88797db6386a6008cdc4fb2eaaf94b86b82f1bad9c679a5ba8b8aef6fac8aacacf17083ad99d2c63da5edb785b752a9b3bad3d7549bada2a8c768869f8aa4f425bbefbfb9cf59f1b089adb121f4989d8ce237e2a3',
# 'domain': 'www.zhipin.com'
# }
# web.add_cookie(cookie_dict)
with open('./stealth.min.js') as f:
js = f.read()
web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
s_time = time.time()
# # 利用xpath和css选择器提取数据
f = open('112.csv', mode='a', encoding='utf-8', newline='')
csv_write = csv.DictWriter(f, fieldnames=[
'岗位名称',
'工作地点',
'薪资',
'公司名称',
'学历要求',
'经验要求',
# '发布日期',
])
# with open('cookies1.txt', 'r') as f:
# cookie_str = f.read()
# cookies = eval(cookie_str)
# csv_write.writeheader() # 写入表头
# web.get("https://www.zhipin.com")
#
# for name, value in cookies.items():
# cookie_dict = {'name': name, 'value': value}
# web.add_cookie(cookie_dict)
web.execute_cdp_cmd('Network.setExtraHTTPHeaders', {'headers': {'Referer': 'https://www.baidu.com'}})
time.sleep(1)
for page in range(1, 10):
print(f'==============正在爬取{page}页信息==================')
url = "https://www.zhipin.com/web/geek/job?query=%E6%9C%88%E5%AB%82&city=101240100&page={}".format(page)
web.get(url)
time.sleep(13)
if page==1:
jobData = web.find_elements(By.XPATH,'//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[2]/ul/li')
else:
jobData = web.find_elements(By.XPATH,'//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/ul/li')
# print(jobData)
time.sleep(3)
# 详情页面工作职责和任职资格划分
for job in jobData:
jobName = job.find_element(By.CLASS_NAME, 'job-name').text # 职位名称
time.sleep(0.5)
jobSalary = job.find_element(By.CLASS_NAME, 'salary').text # 工作薪资
time.sleep(0.5)
jobCompany = job.find_element(By.CLASS_NAME, 'company-name').text # 公司名称
time.sleep(0.5)
address = job.find_element(By.CLASS_NAME, 'job-area').text # 地点
time.sleep(0.5)
xueli = job.find_element(By.CLASS_NAME, 'tag-list').text[:4] # 学历
time.sleep(0.5)
jingyan = job.find_element(By.CLASS_NAME, 'tag-list').text[-4:] # 经验
time.sleep(0.5)
dit = {
"岗位名称": jobName,
"工作地点": address,
"薪资": jobSalary,
"公司名称": jobCompany,
"学历要求": xueli,
"经验要求": jingyan,
}
print(jobName, address, jobSalary, jobCompany,xueli,jingyan)
csv_write.writerow(dit)
time.sleep(3)
e_time = time.time()
print('用时:%f秒' % (e_time - s_time))
web.quit()注意这里使用的是脚本进行模拟点击页面进行数据爬取,速度较慢但是比较稳定,使用前注意做好前期浏览器配置等工作。
前程无忧:
import csv
import random
import time
from lxml import etree
from selenium import webdriver
# 实现规避检测
from selenium.webdriver import ChromeOptions
# 实现无可视化界面的
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
# 去除浏览器识别,去除Chrome正在受到自动检测软件的控制
chrome_options = ChromeOptions()
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
chrome_options.add_experimental_option('detach', True)
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
options = Options()
options.add_argument('--headless') # 设置为无头
options.add_argument('--disable-gpu') # 设置没有使用gpu
options.add_argument(
'user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
# 实例化一个浏览器对象(传入浏览器的驱动程序)
web = webdriver.Chrome(chrome_options=chrome_options, options=options)
with open('./stealth.min.js') as f:
js = f.read()
web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
# 利用xpath和css选择器提取数据
f = open('11.csv', mode='a', encoding='utf-8', newline='')
csv_write = csv.DictWriter(f, fieldnames=[
'岗位名称',
'工作地点',
'薪资',
'公司名称',
'工作经验',
'学历要求',
'发布日期',
])
csv_write.writeheader() # 写入表头
# 找到职位框,输入搜索的内容
job_names = ['月嫂']
for j in job_names:
# 定位输入框并查找相关职位
# 发起请求
web.get("https://www.51job.com/")
time.sleep(3) # 防止加载缓慢,休眠2秒
web.find_element(By.XPATH, '//*[@id="kwdselectid"]').click()
web.find_element(By.XPATH, '//*[@id="kwdselectid"]').clear()
# 输入招聘岗位名称
web.find_element(By.XPATH, '//*[@id="kwdselectid"]').send_keys(j)
web.find_element(By.XPATH, '/html/body/div[3]/div/div[1]/div/button').click() # 点击搜索
# #切换城市
time.sleep(3)
web.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/div/div[1]/div[2]/div[1]/div[1]/div[2]/div[2]').click()
time.sleep(3)
# web.find_element(By.XPATH, '//*[@id="pane-0"]/div/div/div[1]/span').click()
# time.sleep(1)
web.find_element(By.XPATH, '//*[@id="tab-10"]/div/div[2]').click()
time.sleep(0.4)
web.find_element(By.XPATH, '//*[@id="pane-10"]/div/div/div[2]/div[17]/span').click()
time.sleep(0.4)
web.find_element(By.XPATH, '//*[@id="pane-10"]/div/div/div[2]/div[18]/span').click()
time.sleep(0.4)
web.find_element(By.XPATH, '//*[@id="pane-10"]/div/div/div[2]/div[19]/span').click()
time.sleep(0.4)
web.find_element(By.XPATH, '//*[@id="pane-10"]/div/div/div[2]/div[20]/span').click()
time.sleep(0.4)
web.find_element(By.XPATH, '//*[@id="pane-10"]/div/div/div[2]/div[21]/span').click()
# time.sleep(1)
# web.find_element(By.XPATH, '//*[@id="pane-0"]/div/div/div[5]/span').click()
time.sleep(1)
web.find_element(By.XPATH, '//*[@id="dilog"]/div/div[3]/span/button').click()
time.sleep(3)
for page in range(1, 10):
print(f'==============正在爬取{page}页信息==================')
time.sleep(5)
web.find_element(By.XPATH, '//*[@id="jump_page"]').click()
time.sleep(random.randint(10, 30) * 0.1)
web.find_element(By.XPATH, '//*[@id="jump_page"]').clear()
time.sleep(random.randint(10, 40) * 0.1)
web.find_element(By.XPATH, '//*[@id="jump_page"]').send_keys(page)
time.sleep(random.randint(10, 30) * 0.1)
web.find_element(By.XPATH,
'//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[2]/div/div[3]/div/div/span[3]').click()
# 定位招聘页面所有招聘公司
time.sleep(3)
jobData = web.find_elements(By.XPATH,
'//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[2]/div/div[2]/div[1]/div')
# print(jobData)
# 详情页面工作职责和任职资格划分
for job in jobData:
jobName = job.find_element(By.CLASS_NAME, 'jname.at').text # 职位名称
time.sleep(random.randint(5, 15) * 0.1)
jobSalary = job.find_element(By.CLASS_NAME, 'sal').text # 工作薪资
time.sleep(random.randint(5, 15) * 0.1)
jobCompany = job.find_element(By.CLASS_NAME, 'cname.at').text # 公司名称
time.sleep(random.randint(5, 15) * 0.1)
# company_type_size = job.find_element(By.CLASS_NAME, 'dc.at').text # 公司规模
# time.sleep(random.randint(5, 15) * 0.1)
# company_status = job.find_element(By.CLASS_NAME, 'int.at').text # 所属行业
# time.sleep(random.randint(5, 15) * 0.1)
address_experience_education = job.find_element(By.CLASS_NAME, 'd.at').text # 地点_经验_学历
print(address_experience_education)
length = len(address_experience_education.split('|'))
if length == 3:
address = address_experience_education.split('|')[0] # 工作地点
experience = address_experience_education.split('|')[1] # 工作经验
edu = address_experience_education.split('|')[2] # 学历要求
else:
address = address_experience_education.split('|')[0] # 工作地点
experience = '无需经验'
edu = '学历不限'
time.sleep(random.randint(5, 15) * 0.1)
update_date = job.find_element(By.CLASS_NAME, 'time').text # 发布日期
time.sleep(random.randint(5, 15) * 0.1)
dit = {
"岗位名称": jobName,
"工作地点": address,
"薪资": jobSalary,
"公司名称": jobCompany,
"工作经验": experience,
"学历要求": edu,
# "关键词": job_welf,
"发布日期": update_date,
}
# print(f'正在爬取{jobCompany}公司')
print(jobName,address, jobSalary, jobCompany, update_date,experience,edu)
csv_write.writerow(dit)
time.sleep(5)招聘需求最多的前十个城市的平均工资排行:
import pandas as pd
import seaborn as sns
import matplotlib as mpl
#配置之后便可使用
mpl.rcParams['font.family']='SimHei'
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False # 正常显示负号
#可使用该例子查看效果
from matplotlib import pyplot as plt
# 读取数据集
data = pd.read_csv('66.csv', encoding='utf-8')
# 找到出现次数最多的十个城市
top_cities = data['城市'].value_counts()[:10].index.tolist()
# 将列表转换为DataFrame对象
top_cities_df = pd.DataFrame({'城市': top_cities})
# 合并这些城市的数据,并计算它们的平均工资
city_mean = pd.merge(data[data['城市'].isin(top_cities)], top_cities_df, on='城市').groupby(by="城市")["工资"].mean().round(2).reset_index()
# 按工资大小对城市平均工资进行排序
city_mean = city_mean.sort_values('工资', ascending=False)
# 绘制出现次数最多的十个城市的平均工资柱状图
plt.figure(figsize=(8,6))
ax = sns.barplot(x='城市', y='工资', data=city_mean)
plt.xticks(rotation=45)
plt.title('出现次数最多的十个城市的平均工资')
# 在每一列工资上显示数值
for p in ax.patches:
ax.annotate("%.2f" % p.get_height(), (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', fontsize=10, color='gray', xytext=(0, 8), textcoords='offset points')
plt.show()部分效果截图:
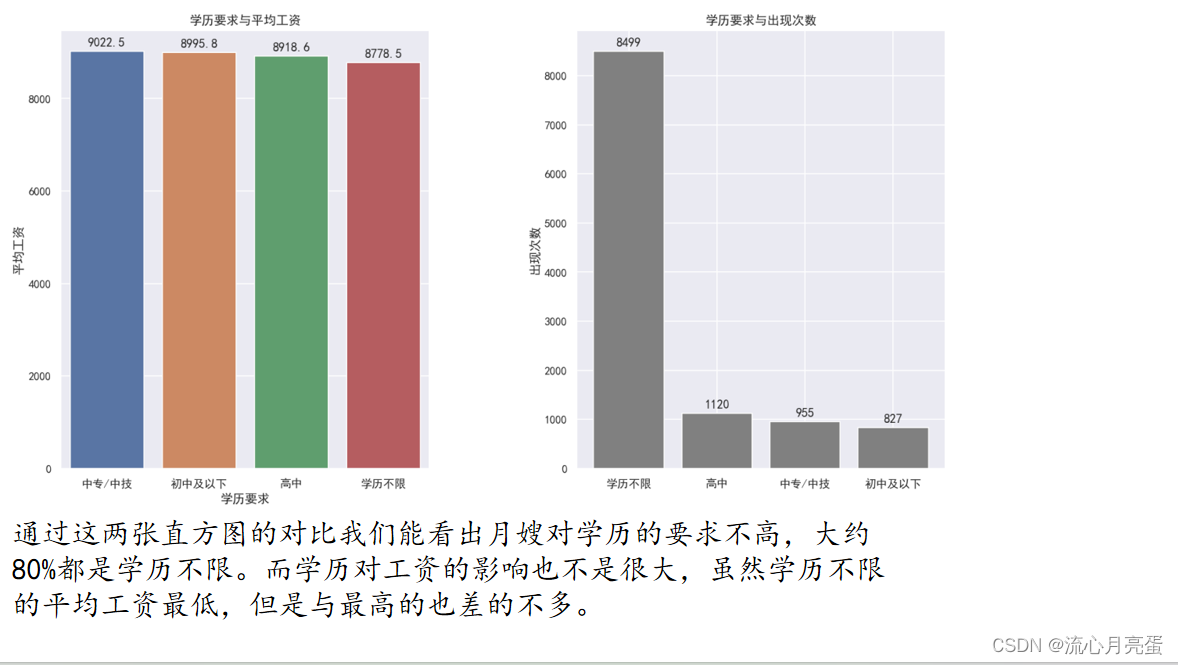
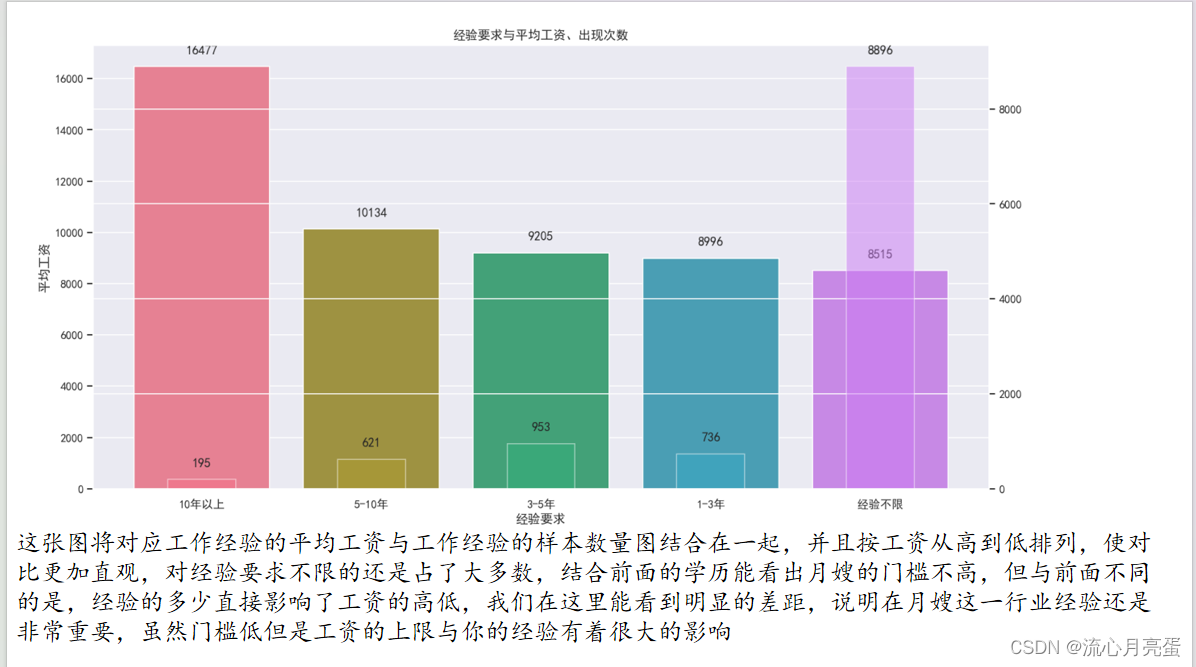
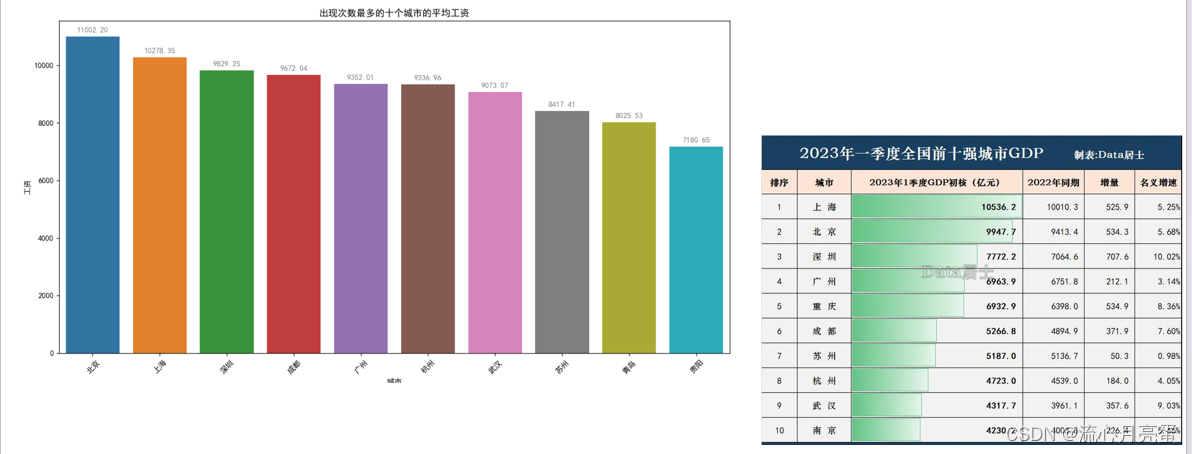


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









