







目录
一、安装下载
MySQl的安装以及环境的搭建博主已经在前面的博客有写过,所有大家点击链接就可看到相关步骤
链接: MySQL环境搭建
二、用户管理(三种权限,三个环境)
- 项目经理 数据库而言:增删改查,Create、drop等权限,一般具备所有权限
- 项目组长 数据库而言:只具备增删改查
3)开发人员:数据库而言:查询(select)- 对于系统开发而言,三个环境
线网、生产环境:系统开发完毕,客户使用的那个环境
测试环境:公司内部模拟客户现场,搭建而成的环境
开发环境:本地电脑
权限的划分,针对的是生产环境
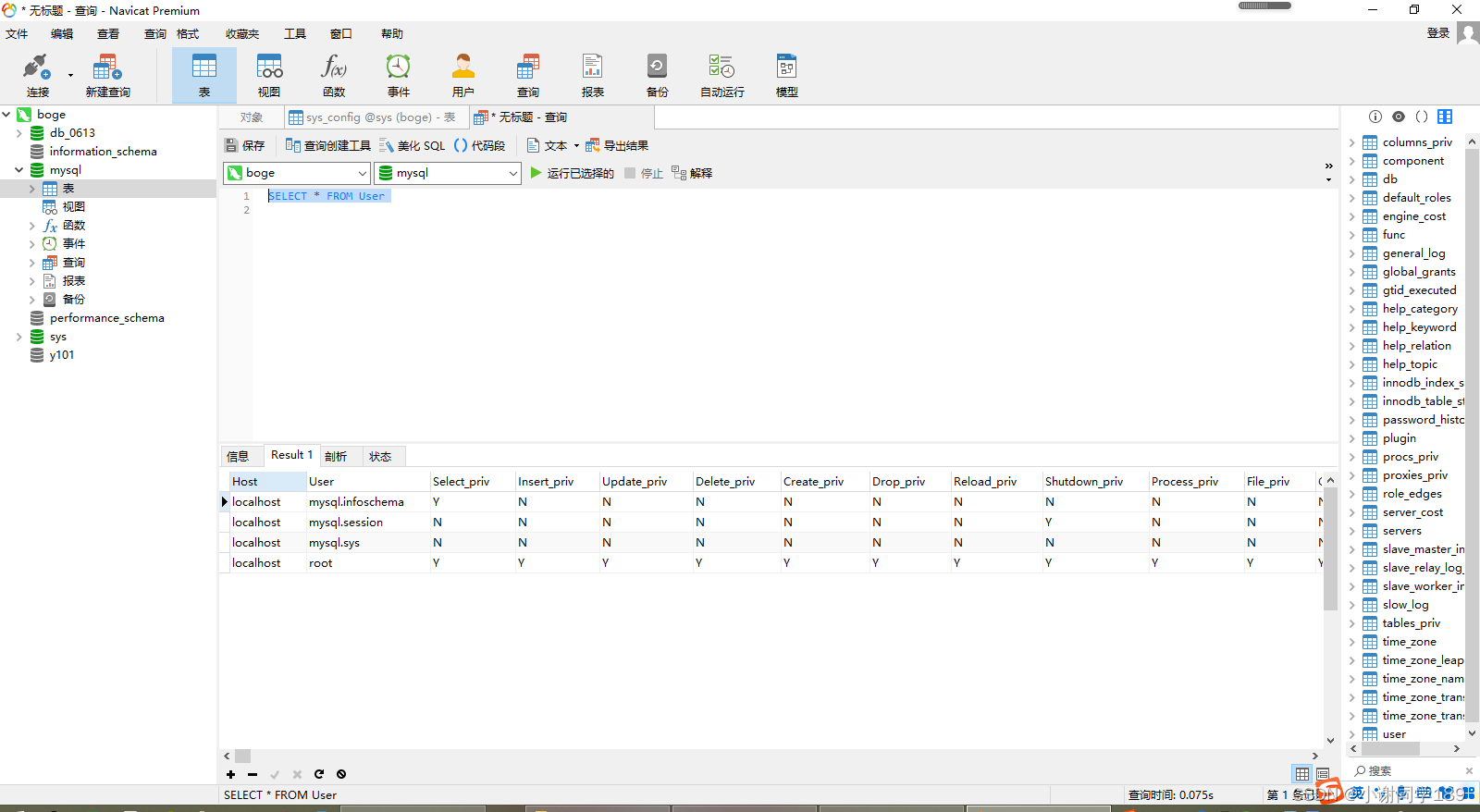
一、首先我们需要来看一下mysql默认数据库里面的四张表(user,db,tables_priv,columns_priv)。
1、user表(用户层权限)
因为字段太多,只截取了一部分。首先登陆的时候验证Host,User,Password(authentication_string)也就是ip,用户名,密码是否匹配,匹配登陆成功将会为登陆者分配权限,分配权限的顺序也是按照上面四张表的排列顺序进行的,举个例子,如果user表的Select_priv为Y说明他拥有所有表的查找权限,如果为N就需要到下一级db表中进行权限分配了。其中的%是通配符,代表任意的意思。
2、db表(数据库层权限)
来到db表之后会匹配Host,User然后会根据Db字段对应的表进行权限分配,像Select_priv这些字段对应的权限大家应该都能看出来是对应着什么权限了吧,这里不细说了(不偷懒,举个例子Select_priv,Insert_priv,Update_priv,Delete_priv,Create_priv,Drop_priv分别代表着查询,增加,更新,删除,创建,销毁)。其中Y代表这拥有此项权限,N则代表没有此项权限。
3、tables_priv表(表层权限)
与上面一样,这是通过Host,Db,User,Table来进行定位到表层的一个权限分配。不过它只有Table_priv和Column_priv两个字段来记录权限。
4、columns_priv表(字段层权限)
顾名思义,字段层权限,通过Host,Db,User,Table,Column来进行定位到字段层的一个权限分配,只有Column_priv来记录权限。
相关的SQL语句
0.查询用户
SELECT * from user;
1.创建用户并设置登录密码
#MySQL5.7
#命令:create user 用户名 identified by '密码';
#注:identified by会将纯文本密码加密作为散列值存储
create user ls identified by '123456';
#MySQL8
#用户名密码创建需要分开
#命令:create user 用户名;
create user ls;
2.查看用户信息
#MySQL5.7
select host,user,password from user;
#MySQL8
select host,user,authentication_string from user;
3.删除用户(慎用)
#命令:drop user 用户名;
#drop user ls;
4.修改用户密码
4.1 修改密码
#MySQL5.7
#命令:set password for 用户名=password('新密码');
set password for zs=password('123456');
#MySQL8
#ALTER USER 用户 IDENTIFIED WITH mysql_native_password BY '密码';
ALTER USER 'ls'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
4.2 刷新配置
#命令:flush privileges;
#MySQL5.7与MySQL8关于权限操作没有差异性
5.设置权限(Grant)
#语法:grant privileges on databasename.tablename to username@'host';
#给 zs用户 赋予 数据库db_xiaoli中的表t_p1_user 查询权限
grant SELECT on db_xiaoli.t_p1_user to zs@'%';
#给 zs用户 赋予 数据库db_xiaoli中的表t_p1_user 修改权限
grant UPDATE on db_xiaoli.t_p1_user to zs@'%';
#给 zs用户 赋予 数据库db_xiaoli中所有表 查询权限
grant SELECT on db_xiaoli.* to zs@'%';
#给 zs用户 赋予 数据库db_xiaoli中所有表 所有权限
grant ALL on db_xiaoli.* to zs@'%';
6.撤销权限(Revoke)
#语法:revoke privileges on databasename.tablename from username@'host';
#啥也不能回收,不会对GRANT ALL PRIVILEGES ON `db_xiaoli`.* TO `zs`@`%`有任何影响
revoke DELETE on db_xiaoli.t_p1_user from zs@'%';
#可以回收GRANT SELECT, UPDATE ON `db_xiaoli`.`t_p1_user` TO `zs`@`%`这条权限语句
revoke all on db_xiaoli.t_p1_user from zs@'%';
#可以回收GRANT ALL PRIVILEGES ON `db_xiaoli`.* TO `zs`@`%`这条赋权语句带来的权限
revoke all on db_xiaoli.* from zs@'%';
#注:revoke只能回收grants列表中更小的权限;
设置权限(Grant)和撤销权限(Revoke)的参数说明:
1) privileges: 用户的操作权限,如SELECT,INSERT,UPDATE,DELETE等,如果要授予所有权限直接使用:all;
2) databasename:数据库名;
3) tablename: 表名,如果要授予用户对所有数据库和表的操作权限直接使用:*.*;
7.查看用户权限
#命令:show grants for 用户名;
show grants for 'zs'@'%';
user表中host列的值的意义
% 匹配所有主机
localhost localhost不会被解析成IP地址,直接通过UNIXsocket连接
127.0.0.1 会通过TCP/IP协议连接,并且只能在本机访问;
::1 ::1就是兼容支持ipv6的,表示同ipv4的127.0.0.1
案例:
我们现在创建一个项目经理(zs),一个项目组长(ls),一个开发人员(ww),项对应的权限也一并划分
目前我们数据库的用户
我们创建项目经理zs
添加用户
CREATE user zs;
给创建的用户设置密码
ALTER USER 'zs'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
查询用户的密码等信息
select host,user,authentication_string from user;
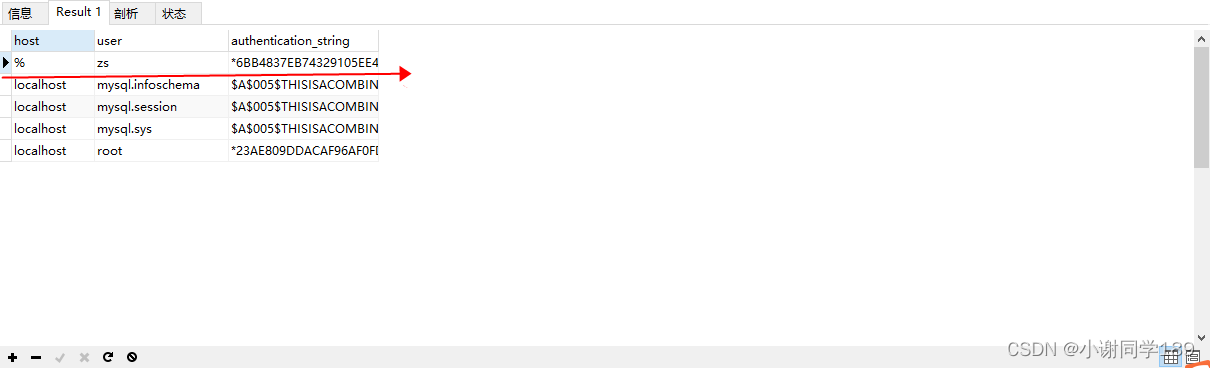
现在我们用zs登录连接数据库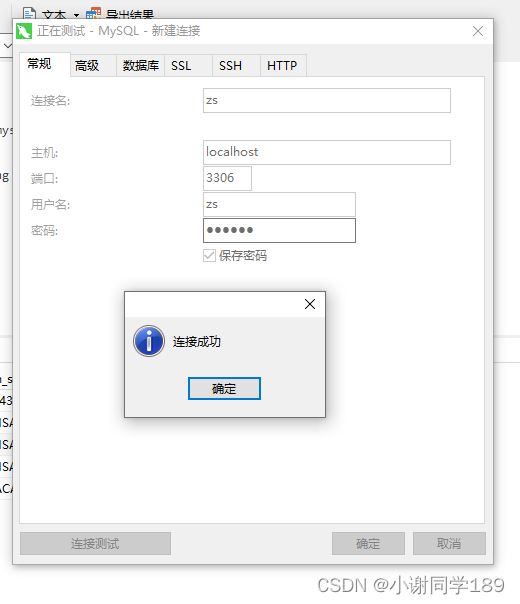
点击确定即可
赋予权限,博主用博主数据库的db_0613这个库的tb_like这个表来操作
赋予权限给用户 grant to
grant all privileges on db_0613.* to zs@'%';

那么现在对于zs来言就拥有了所有权限
现在我们创建一个项目组长ls
添加用户
CREATE user ls;
给创建的用户设置密码
ALTER USER 'ls'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
赋予权限给用户 grant to
grant select,delete on db_0613.tb_like to ls@'%';
连接成功后我们可以对比一下项目经理和项目组长的权限
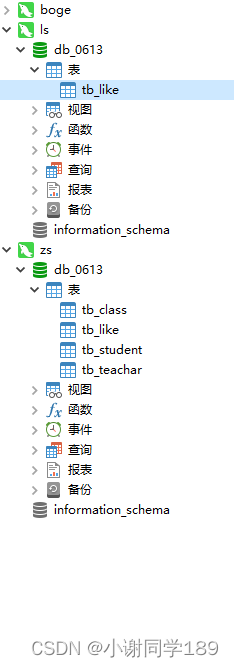
项目经理是整个库进行操作,而项目组长只能操作其中一张表
而且且项目组长不具有修改权限(这边打比方)
表数据
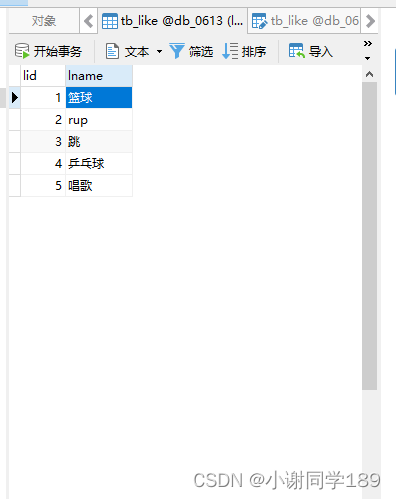
如果我们修改成跳1那么就会报错
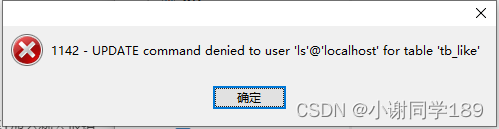
但是有删除的权限
然后我们想要收回权限,那么该人员就不能具备以前的权限
先查看所有权限
show grants for 'zs'@'%';

第一个是登录权限,第二个是其他权限
现在我们撤回权限
收回该用户的权限
revoke DELETE on db_0613.* from zs@'%';
删除用户
删除用户
#drop user ls;
#DROP user zs;
三、建库建表
1) 表字段类型
MySQL中定义数据字段的类型对你数据库的优化是非常重要的。
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
1)字符类型:char varchar text blob
2)数值类型:int bigint float decimal
int -> int
bigint -> long
float -> 成绩
decimal -> 货币类型(精度,小数)
3)日期类型:date time datetime timestamp
date -> yyyy:MM:dd HH:mm:ss
time -> HH:mm:ss
datetime -> yyyy:MM:dd
timestamp(时间戳) -> 长整数
2) 约束
/*
含义:一种限制,用于限制表中的数据,为了保证表中的数据的准确和可靠性
分类:六大约束
NOT NULL:非空,用于保证该字段的值不能为空
比如姓名、学号等
DEFAULT:默认,用于保证该字段有默认值
比如性别
PRIMARY KEY:主键,用于保证该字段的值具有唯一性,并且非空
比如学号、员工编号等
UNIQUE:唯一,用于保证该字段的值具有唯一性,可以为空
比如座位号
CHECK:检查约束【mysql中不支持】
比如年龄、性别
FOREIGN KEY:外键,用于限制两个表的关系,用于保证该字段的值必须来自于主表的关联列的值
在从表添加外键约束,用于引用主表中某列的值
比如学生表的专业编号,员工表的部门编号,员工表的工种编号
添加约束的时机:
1.创建表时
2.修改表时
约束的添加分类:
列级约束:
六大约束语法上都支持,但外键约束没有效果
表级约束:
除了非空、默认,其他的都支持
主键和唯一的大对比:
保证唯一性 是否允许为空 一个表中可以有多少个 是否允许组合
主键√×至多有1个 √,但不推荐
唯一√√可以有多个 √,但不推荐
外键:
1、要求在从表设置外键关系
2、从表的外键列的类型和主表的关联列的类型要求一致或兼容,名称无要求
3、主表的关联列必须是一个key(一般是主键或唯一)
4、插入数据时,先插入主表,再插入从表
删除数据时,先删除从表,再删除主表
*/
CREATE TABLE 表名(
字段名 字段类型 列级约束,
字段名 字段类型,
表级约束
)
CREATE DATABASE students;
#一、创建表时添加约束
#1.添加列级约束
/*
语法:
直接在字段名和类型后面追加 约束类型即可。
只支持:默认、非空、主键、唯一
*/
USE students;
DROP TABLE stuinfo;
CREATE TABLE stuinfo(
id INT PRIMARY KEY,#主键
stuName VARCHAR(20) NOT NULL UNIQUE,#非空
gender CHAR(1) CHECK(gender='男' OR gender ='女'),#检查
seat INT UNIQUE,#唯一
age INT DEFAULT 18,#默认约束
majorId INT REFERENCES major(id)#外键
);
CREATE TABLE major(
id INT PRIMARY KEY,
majorName VARCHAR(20)
);
#查看stuinfo中的所有索引,包括主键、外键、唯一
SHOW INDEX FROM stuinfo;
#2.添加表级约束
/*
语法:在各个字段的最下面
【constraint 约束名】 约束类型(字段名)
*/
DROP TABLE IF EXISTS stuinfo;
CREATE TABLE stuinfo(
id INT,
stuname VARCHAR(20),
gender CHAR(1),
seat INT,
age INT,
majorid INT,
CONSTRAINT pk PRIMARY KEY(id),#主键
CONSTRAINT uq UNIQUE(seat),#唯一键
CONSTRAINT ck CHECK(gender ='男' OR gender = '女'),#检查
CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id)#外键
);
SHOW INDEX FROM stuinfo;
#通用的写法:★
CREATE TABLE IF NOT EXISTS stuinfo(
id INT PRIMARY KEY,
stuname VARCHAR(20),
sex CHAR(1),
age INT DEFAULT 18,
seat INT UNIQUE,
majorid INT,
CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id)
);
#二、修改表时添加约束
/*
1、添加列级约束
alter table 表名 modify column 字段名 字段类型 新约束;
2、添加表级约束
alter table 表名 add 【constraint 约束名】 约束类型(字段名) 【外键的引用】;
*/
DROP TABLE IF EXISTS stuinfo;
CREATE TABLE stuinfo(
id INT,
stuname VARCHAR(20),
gender CHAR(1),
seat INT,
age INT,
majorid INT
)
DESC stuinfo;
#1.添加非空约束
ALTER TABLE stuinfo MODIFY COLUMN stuname VARCHAR(20) NOT NULL;
#2.添加默认约束
ALTER TABLE stuinfo MODIFY COLUMN age INT DEFAULT 18;
#3.添加主键
#①列级约束
ALTER TABLE stuinfo MODIFY COLUMN id INT PRIMARY KEY;
#②表级约束
ALTER TABLE stuinfo ADD PRIMARY KEY(id);
#4.添加唯一
#①列级约束
ALTER TABLE stuinfo MODIFY COLUMN seat INT UNIQUE;
#②表级约束
ALTER TABLE stuinfo ADD UNIQUE(seat);
#5.添加外键
ALTER TABLE stuinfo ADD CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id);
#三、修改表时删除约束
#1.删除非空约束
ALTER TABLE stuinfo MODIFY COLUMN stuname VARCHAR(20) NULL;
#2.删除默认约束
ALTER TABLE stuinfo MODIFY COLUMN age INT ;
#3.删除主键
ALTER TABLE stuinfo DROP PRIMARY KEY;
#4.删除唯一
ALTER TABLE stuinfo DROP INDEX seat;
#5.删除外键
ALTER TABLE stuinfo DROP FOREIGN KEY fk_stuinfo_major;
SHOW INDEX FROM stuinfo;
3) 建库建表SQL语句
#1.表的创建 ★
/*
语法:
create table 表名(
列名 列的类型【(长度) 约束】,
列名 列的类型【(长度) 约束】,
列名 列的类型【(长度) 约束】,
...
列名 列的类型【(长度) 约束】
)
*/
#案例:创建表Book
CREATE TABLE book(
id INT,#编号
bName VARCHAR(20),#图书名
price DOUBLE,#价格
authorId INT,#作者编号
publishDate DATETIME#出版日期
);
DESC book;
#案例:创建表author
CREATE TABLE IF NOT EXISTS author(
id INT,
au_name VARCHAR(20),
nation VARCHAR(10)
)
DESC author;
#2.表的修改
/*
语法
alter table 表名 add|drop|modify|change column 列名 【列类型 约束】;
*/
#①修改列名
ALTER TABLE book CHANGE COLUMN publishdate pubDate DATETIME;
#②修改列的类型或约束
ALTER TABLE book MODIFY COLUMN pubdate TIMESTAMP;
#③添加新列
ALTER TABLE author ADD COLUMN annual DOUBLE;
#④删除列
ALTER TABLE book_author DROP COLUMN annual;
#⑤修改表名
ALTER TABLE author RENAME TO book_author;
DESC book;
#3.表的删除
DROP TABLE IF EXISTS book_author;
SHOW TABLES;
#通用的写法:
DROP DATABASE IF EXISTS 旧库名;
CREATE DATABASE 新库名;
DROP TABLE IF EXISTS 旧表名;
CREATE TABLE 表名();
#4.表的复制
INSERT INTO author VALUES
(1,'村上春树','日本'),
(2,'莫言','中国'),
(3,'冯唐','中国'),
(4,'金庸','中国');
SELECT * FROM Author;
SELECT * FROM copy2;
#1.仅仅复制表的结构
CREATE TABLE copy LIKE author;
#2.复制表的结构+数据
CREATE TABLE copy2
SELECT * FROM author;
#只复制部分数据
CREATE TABLE copy3
SELECT id,au_name
FROM author
WHERE nation='中国';
#仅仅复制某些字段
CREATE TABLE copy4
SELECT id,au_name
FROM author
WHERE 0;
四、查询
1)基础查询
/*
语法:
select 查询列表 from 表名;
类似于:System.out.println(打印东西);
特点:
1、查询列表可以是:表中的字段、常量值、表达式、函数
2、查询的结果是一个虚拟的表格
*/
# USE myemployees;
#1.查询表中的单个字段
SELECT last_name FROM t_mysql_employees;
#2.查询表中的多个字段
SELECT last_name,salary,email FROM t_mysql_employees;
#3.查询表中的所有字段
#方式一:
SELECT
`employee_id`,
`first_name`,
`last_name`,
`phone_number`,
`last_name`,
`job_id`,
`phone_number`,
`job_id`,
`salary`,
`commission_pct`,
`manager_id`,
`department_id`,
`hiredate`
FROM
t_mysql_employees ;
#方式二:
SELECT * FROM t_mysql_employees;
#4.查询常量值
SELECT 100;
SELECT 'john';
#5.查询表达式
SELECT 100%98;
#6.查询函数
SELECT VERSION();
#7.起别名
/*
①便于理解
②如果要查询的字段有重名的情况,使用别名可以区分开来
*/
#方式一:使用as
SELECT 100%98 AS 结果;
SELECT last_name AS 姓,first_name AS 名 FROM t_mysql_employees;
#方式二:使用空格
SELECT last_name 姓,first_name 名 FROM t_mysql_employees;
#案例:查询salary,显示结果为 out put
SELECT salary AS "out put" FROM t_mysql_employees;
#8.去重
#案例:查询员工表中涉及到的所有的部门编号
SELECT DISTINCT department_id FROM t_mysql_employees;
#9.+号的作用
/*
java中的+号:
①运算符,两个操作数都为数值型
②连接符,只要有一个操作数为字符串
mysql中的+号:
仅仅只有一个功能:运算符
select 100+90; 两个操作数都为数值型,则做加法运算
select '123'+90;只要其中一方为字符型,试图将字符型数值转换成数值型
如果转换成功,则继续做加法运算
select 'john'+90;如果转换失败,则将字符型数值转换成0
select null+10; 只要其中一方为null,则结果肯定为null
*/
#案例:查询员工名和姓连接成一个字段,并显示为 姓名
SELECT CONCAT('a','b','c') AS 结果;
SELECT
CONCAT(last_name,first_name) AS 姓名
FROM
t_mysql_employees;
2)过滤查询
/*
语法:
select
查询列表
from
表名
where
筛选条件;
分类:
一、按条件表达式筛选
简单条件运算符:> < = != <> >= <=
二、按逻辑表达式筛选
逻辑运算符:
作用:用于连接条件表达式
&& || !
and or not
&&和and:两个条件都为true,结果为true,反之为false
||或or: 只要有一个条件为true,结果为true,反之为false
!或not: 如果连接的条件本身为false,结果为true,反之为false
三、模糊查询
like
between and
in
is null
*/
#一、按条件表达式筛选
#案例1:查询工资>12000的员工信息
SELECT
*
FROM
t_mysql_employees
WHERE
salary>12000;
#案例2:查询部门编号不等于90号的员工名和部门编号
SELECT
last_name,
department_id
FROM
t_mysql_employees
WHERE
department_id<>90;
#二、按逻辑表达式筛选
#案例1:查询工资z在10000到20000之间的员工名、工资以及奖金
SELECT
last_name,
salary,
commission_pct
FROM
t_mysql_employees
WHERE
salary>=10000 AND salary<=20000;
#案例2:查询部门编号不是在90到110之间,或者工资高于15000的员工信息
SELECT
*
FROM
t_mysql_employees
WHERE
NOT(department_id>=90 AND department_id<=110) OR salary>15000;
#三、模糊查询
/*
like
between and
in
is null|is not null
*/
#1.like
/*
特点:
①一般和通配符搭配使用
通配符:
% 任意多个字符,包含0个字符
_ 任意单个字符
*、
#案例1:查询员工名中包含字符a的员工信息
select
*
from
employees
where
last_name like '%a%';#abc
#案例2:查询员工名中第三个字符为e,第五个字符为a的员工名和工资
select
last_name,
salary
FROM
t_mysql_employees
WHERE
last_name LIKE '__n_l%';
#案例3:查询员工名中第二个字符为_的员工名
SELECT
last_name
FROM
t_mysql_employees
WHERE
last_name LIKE '_$_%' ESCAPE '$';
#2.between and
/*
①使用between and 可以提高语句的简洁度
②包含临界值
③两个临界值不要调换顺序
*/
#案例1:查询员工编号在100到120之间的员工信息
SELECT
*
FROM
t_mysql_employees
WHERE
employee_id <= 120 AND employee_id>=100;
#----------------------
SELECT
*
FROM
t_mysql_employees
WHERE
employee_id BETWEEN 100 AND 120;
#3.in
/*
含义:判断某字段的值是否属于in列表中的某一项
特点:
①使用in提高语句简洁度
②in列表的值类型必须一致或兼容
③in列表中不支持通配符
*/
#案例:查询员工的工种编号是 IT_PROG、AD_VP、AD_PRES中的一个员工名和工种编号
SELECT
last_name,
job_id
FROM
t_mysql_employees
WHERE
job_id = 'IT_PROT' OR job_id = 'AD_VP' OR JOB_ID ='AD_PRES';
#------------------
SELECT
last_name,
job_id
FROM
t_mysql_employees
WHERE
job_id IN( 'IT_PROT' ,'AD_VP','AD_PRES');
#4、is null
/*
=或<>不能用于判断null值
is null或is not null 可以判断null值
*/
#案例1:查询没有奖金的员工名和奖金率
SELECT
last_name,
commission_pct
FROM
t_mysql_employees
WHERE
commission_pct IS NULL;
#案例1:查询有奖金的员工名和奖金率
SELECT
last_name,
commission_pct
FROM
t_mysql_employees
WHERE
commission_pct IS NOT NULL;
#----------以下为×
SELECT
last_name,
commission_pct
FROM
t_mysql_employees
WHERE
salary IS 12000;
#安全等于 <=>
#案例1:查询没有奖金的员工名和奖金率
SELECT
last_name,
commission_pct
FROM
t_mysql_employees
WHERE
commission_pct <=>NULL;
#案例2:查询工资为12000的员工信息
SELECT
last_name,
salary
FROM
t_mysql_employees
WHERE
salary <=> 12000;
#is null pk <=>
IS NULL:仅仅可以判断NULL值,可读性较高,建议使用
<=> :既可以判断NULL值,又可以判断普通的数值,可读性较低
3) order by字句查询
#进阶3:排序查询
/*
语法:
select 查询列表
from 表名
【where 筛选条件】
order by 排序的字段或表达式;
特点:
1、asc代表的是升序,可以省略
desc代表的是降序
2、order by子句可以支持 单个字段、别名、表达式、函数、多个字段
3、order by子句在查询语句的最后面,除了limit子句
*/
#1、按单个字段排序
SELECT * FROM t_mysql_employees ORDER BY salary DESC;
#2、添加筛选条件再排序
#案例:查询部门编号>=90的员工信息,并按员工编号降序
SELECT *
FROM t_mysql_employees
WHERE department_id>=90
ORDER BY employee_id DESC;
#3、按表达式排序
#案例:查询员工信息 按年薪降序
SELECT *,salary*12*(1+IFNULL(commission_pct,0))
FROM t_mysql_employees
ORDER BY salary*12*(1+IFNULL(commission_pct,0)) DESC;
#4、按别名排序
#案例:查询员工信息 按年薪升序
SELECT *,salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM t_mysql_employees
ORDER BY 年薪 ASC;
#5、按函数排序
#案例:查询员工名,并且按名字的长度降序
SELECT LENGTH(last_name),last_name
FROM t_mysql_employees
ORDER BY LENGTH(last_name) DESC;
#6、按多个字段排序
#案例:查询员工信息,要求先按工资降序,再按employee_id升序
SELECT *
FROM t_mysql_employees
ORDER BY salary DESC,employee_id ASC;
排序练习
#1.查询员工的姓名和部门号和年薪,按年薪降序 按姓名升序
SELECT last_name,department_id,salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM t_mysql_employees
ORDER BY 年薪 DESC,last_name ASC;
#2.选择工资不在8000到17000的员工的姓名和工资,按工资降序
SELECT last_name,salary
FROM t_mysql_employees
WHERE salary NOT BETWEEN 8000 AND 17000
ORDER BY salary DESC;
#3.查询邮箱中包含e的员工信息,并先按邮箱的字节数降序,再按部门号升序
SELECT *,LENGTH(email)
FROM t_mysql_employees
WHERE email LIKE '%e%'
ORDER BY LENGTH(email) DESC,department_id ASC;
4)分组查询
/*
功能:用作统计使用,又称为聚合函数或统计函数或组函数
分类:
sum 求和、avg 平均值、max 最大值 、min 最小值 、count 计算个数
特点:
1、sum、avg一般用于处理数值型
max、min、count可以处理任何类型
2、以上分组函数都忽略null值
3、可以和distinct搭配实现去重的运算
4、count函数的单独介绍
一般使用count(*)用作统计行数
5、和分组函数一同查询的字段要求是group by后的字段
*/
#1、简单 的使用
SELECT SUM(salary) FROM t_mysql_employees;
SELECT AVG(salary) FROM t_mysql_employees;
SELECT MIN(salary) FROM t_mysql_employees;
SELECT MAX(salary) FROM t_mysql_employees;
SELECT COUNT(salary) FROM t_mysql_employees;
SELECT SUM(salary) 和,AVG(salary) 平均,MAX(salary) 最高,MIN(salary) 最低,COUNT(salary) 个数
FROM t_mysql_employees;
SELECT SUM(salary) 和,ROUND(AVG(salary),2) 平均,MAX(salary) 最高,MIN(salary) 最低,COUNT(salary) 个数
FROM t_mysql_employees;
#2、参数支持哪些类型
SELECT SUM(last_name) ,AVG(last_name) FROM t_mysql_employees;
SELECT SUM(hiredate) ,AVG(hiredate) FROM t_mysql_employees;
SELECT MAX(last_name),MIN(last_name) FROM t_mysql_employees;
SELECT MAX(hiredate),MIN(hiredate) FROM t_mysql_employees;
SELECT COUNT(commission_pct) FROM t_mysql_employees;
SELECT COUNT(last_name) FROM t_mysql_employees;
#3、是否忽略null
SELECT SUM(commission_pct) ,AVG(commission_pct),SUM(commission_pct)/35,SUM(commission_pct)/107 FROM t_mysql_employees;
SELECT MAX(commission_pct) ,MIN(commission_pct) FROM t_mysql_employees;
SELECT COUNT(commission_pct) FROM t_mysql_employees;
SELECT commission_pct FROM t_mysql_employees;
#4、和distinct搭配
SELECT SUM(DISTINCT salary),SUM(salary) FROM t_mysql_employees;
SELECT COUNT(DISTINCT salary),COUNT(salary) FROM t_mysql_employees;
#5、count函数的详细介绍
SELECT COUNT(salary) FROM t_mysql_employees;
SELECT COUNT(*) FROM t_mysql_employees;
SELECT COUNT(1) FROM t_mysql_employees;
效率:
MYISAM存储引擎下 ,COUNT(*)的效率高
INNODB存储引擎下,COUNT(*)和COUNT(1)的效率差不多,比COUNT(字段)要高一些
#6、和分组函数一同查询的字段有限制,employee_id是最小的那个
SELECT AVG(salary),employee_id FROM t_mysql_employees;
分组函数练习
#1.查询公司员工工资的最大值,最小值,平均值,总和
SELECT MAX(salary) 最大值,MIN(salary) 最小值,AVG(salary) 平均值,SUM(salary) 和
FROM t_mysql_employees;
#2.查询员工表中的最大入职时间和最小入职时间的相差天数 (DIFFRENCE)
SELECT MAX(hiredate) 最大,MIN(hiredate) 最小,(MAX(hiredate)-MIN(hiredate))/1000/3600/24 DIFFRENCE
FROM t_mysql_employees;
SELECT DATEDIFF(MAX(hiredate),MIN(hiredate)) DIFFRENCE
FROM t_mysql_employees;
SELECT DATEDIFF('1995-2-7','1995-2-6');
#3.查询部门编号为90的员工个数
SELECT COUNT(*) FROM t_mysql_employees WHERE department_id = 90;
五、视图
含义:虚拟表,和普通表一样使用
mysql5.1版本出现的新特性,是通过表动态生成的数据
比如:舞蹈班和普通班级的对比
创建语法的关键字是否实际占用物理空间使用
视图create view只是保存了sql逻辑增删改查,只是一般不能增删改
表create table保存了数据增删改查
#案例:查询姓张的学生名和专业名
SELECT stuname,majorname
FROM stuinfo s
INNER JOIN major m ON s.`majorid`= m.`id`
WHERE s.`stuname` LIKE '张%';
CREATE VIEW v1
AS
SELECT stuname,majorname
FROM stuinfo s
INNER JOIN major m ON s.`majorid`= m.`id`;
SELECT * FROM v1 WHERE stuname LIKE '张%';
#一、创建视图
/*
语法:
create view 视图名
as
查询语句;
*/
USE myemployees;
#1.查询姓名中包含a字符的员工名、部门名和工种信息
#①创建
CREATE VIEW myv1
AS
SELECT last_name,department_name,job_title
FROM employees e
JOIN departments d ON e.department_id = d.department_id
JOIN jobs j ON j.job_id = e.job_id;
#②使用
SELECT * FROM myv1 WHERE last_name LIKE '%a%';
#2.查询各部门的平均工资级别
#①创建视图查看每个部门的平均工资
CREATE VIEW myv2
AS
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id;
#②使用
SELECT myv2.`ag`,g.grade_level
FROM myv2
JOIN job_grades g
ON myv2.`ag` BETWEEN g.`lowest_sal` AND g.`highest_sal`;
#3.查询平均工资最低的部门信息
SELECT * FROM myv2 ORDER BY ag LIMIT 1;
#4.查询平均工资最低的部门名和工资
CREATE VIEW myv3
AS
SELECT * FROM myv2 ORDER BY ag LIMIT 1;
SELECT d.*,m.ag
FROM myv3 m
JOIN departments d
ON m.`department_id`=d.`department_id`;
#二、视图的修改
#方式一:
/*
create or replace view 视图名
as
查询语句;
*/
SELECT * FROM myv3
CREATE OR REPLACE VIEW myv3
AS
SELECT AVG(salary),job_id
FROM employees
GROUP BY job_id;
#方式二:
/*
语法:
alter view 视图名
as
查询语句;
*/
ALTER VIEW myv3
AS
SELECT * FROM employees;
#三、删除视图
/*
语法:drop view 视图名,视图名,...;
*/
DROP VIEW emp_v1,emp_v2,myv3;
#四、查看视图
DESC myv3;
SHOW CREATE VIEW myv3;
#五、视图的更新
CREATE OR REPLACE VIEW myv1
AS
SELECT last_name,email,salary*12*(1+IFNULL(commission_pct,0)) "annual salary"
FROM employees;
CREATE OR REPLACE VIEW myv1
AS
SELECT last_name,email
FROM employees;
SELECT * FROM myv1;
SELECT * FROM employees;
#1.插入
INSERT INTO myv1 VALUES('张飞','zf@qq.com');
#2.修改
UPDATE myv1 SET last_name = '张无忌' WHERE last_name='张飞';
#3.删除
DELETE FROM myv1 WHERE last_name = '张无忌';
#具备以下特点的视图不允许更新
#①包含以下关键字的sql语句:分组函数、distinct、group by、having、union或者union all
CREATE OR REPLACE VIEW myv1
AS
SELECT MAX(salary) m,department_id
FROM employees
GROUP BY department_id;
SELECT * FROM myv1;
#更新
UPDATE myv1 SET m=9000 WHERE department_id=10;
#②常量视图
CREATE OR REPLACE VIEW myv2
AS
SELECT 'john' NAME;
SELECT * FROM myv2;
#更新
UPDATE myv2 SET NAME='lucy';
#③Select中包含子查询
CREATE OR REPLACE VIEW myv3
AS
SELECT department_id,(SELECT MAX(salary) FROM employees) 最高工资
FROM departments;
#更新
SELECT * FROM myv3;
UPDATE myv3 SET 最高工资=100000;
#④join
CREATE OR REPLACE VIEW myv4
AS
SELECT last_name,department_name
FROM employees e
JOIN departments d
ON e.department_id = d.department_id;
#更新
SELECT * FROM myv4;
UPDATE myv4 SET last_name = '张飞' WHERE last_name='Whalen';
INSERT INTO myv4 VALUES('陈真','xxxx');
#⑤from一个不能更新的视图
CREATE OR REPLACE VIEW myv5
AS
SELECT * FROM myv3;
#更新
SELECT * FROM myv5;
UPDATE myv5 SET 最高工资=10000 WHERE department_id=60;
#⑥where子句的子查询引用了from子句中的表
CREATE OR REPLACE VIEW myv6
AS
SELECT last_name,email,salary
FROM employees
WHERE employee_id IN(
SELECT manager_id
FROM employees
WHERE manager_id IS NOT NULL
);
#更新
SELECT * FROM myv6;
UPDATE myv6 SET salary=10000 WHERE last_name = 'k_ing';
视图练习
#一、创建视图emp_v1,要求查询电话号码以‘011’开头的员工姓名和工资、邮箱
CREATE OR REPLACE VIEW emp_v1
AS
SELECT last_name,salary,email
FROM employees
WHERE phone_number LIKE '011%';
#二、创建视图emp_v2,要求查询部门的最高工资高于12000的部门信息
CREATE OR REPLACE VIEW emp_v2
AS
SELECT MAX(salary) mx_dep,department_id
FROM employees
GROUP BY department_id
HAVING MAX(salary)>12000;
SELECT d.*,m.mx_dep
FROM departments d
JOIN emp_v2 m
ON m.department_id = d.`department_id`;
六、案例
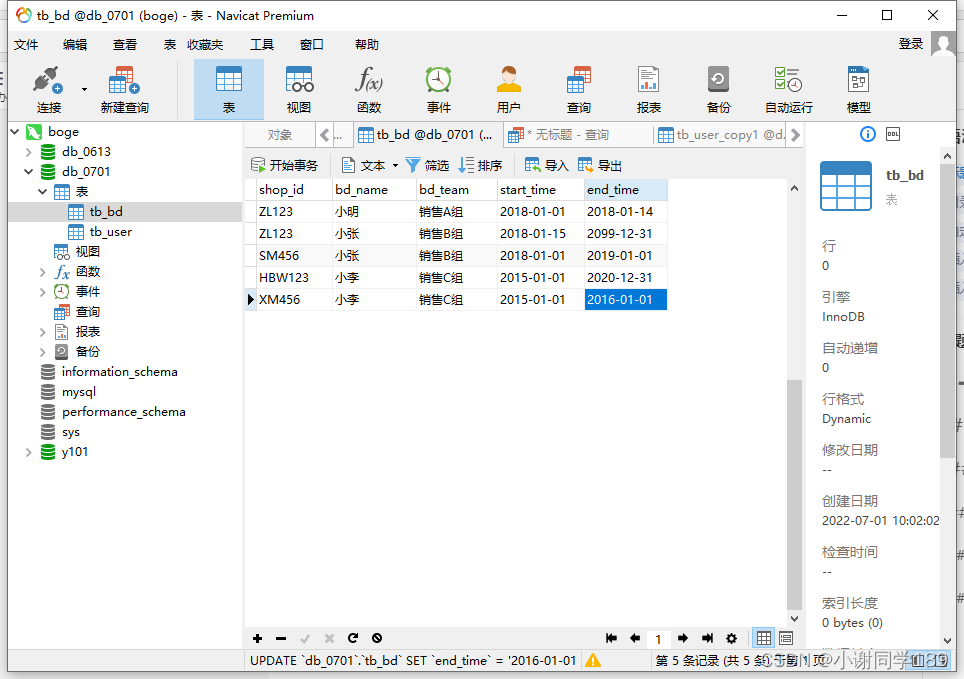
一个库有两个表,表tb_db 和 tb_user

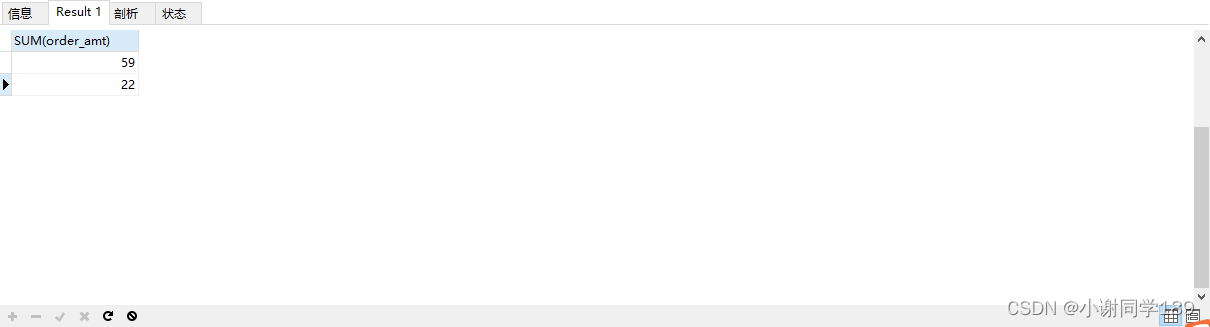
问题①:一月份笔消费均大于20元的用户的消费金额
SELECT SUM(order_amt) FROM tb_user WHERE order_time BETWEEN '2018-01-01' and '2018-01-31' and order_amt > 20 GROUP BY user_id
结果
问题②:一月只吃了麻辣烫和汉堡的人数
SELECT count(*) FROM tb_user WHERE order_time BETWEEN '2018-01-01' and '2018-01-31' and order_category = '麻辣烫' or order_category = '汉堡' GROUP BY user_id
结果

问题③:计算每个bd_time的bd对应门店的销售额
select SUM(b.order_amt) from tb_bd as a,tb_user as b where a.shop_id = b.shop_id GROUP BY a.bd_team
结果
















 572
572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









