









AUTHOR:闫小雨
TIME:2024-05-11
目录
一、正则表达式
1、什么是正则表达式
正则表达式是用于描述字符排列和匹配模式的一种语法规则. 它主要用于字符串的模式分割、匹配、查找及替换操作。
- 匹配有规律的东西:手机号、身份证、匹配日志
- 正则表达式:regular expression(RE)
- 使用一些符号表达重复出现、大小写、开头/结尾含义
2、应用场景
| 正则表达式 | Linux三剑客支持、开发语言(python,vue等) |
| 应用场景 | 过滤有规律的内容,尤其是日志 |
3、正则表达式与通配符
正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配。grep、awk、sed 等命令可以支持正则表达式。
通配符用来匹配符合条件的文件名,通配符是完全匹配。ls、find、cp 这些命令不支持正则表达式,所以只能使用 shell 自己的通配符来进行匹配了。
*:匹配任意内容?:匹配任意一个内容[]:匹配中括号中的一个字符
[root@yanxy502 ~] touch abc.txt adc.txt
[root@yanxy502 ~] ls
aaa.sh abc.txt adc.txt a.txt for.sh stimate.sh Test test2.sh while.sh
[root@yanxy502 ~] ls a*
aaa.sh abc.txt adc.txt a.txt
[root@yanxy502 ~] ls a?c.txt
abc.txt adc.txt
[root@yanxy502 ~] ls a[bd]c.txt
abc.txt adc.txt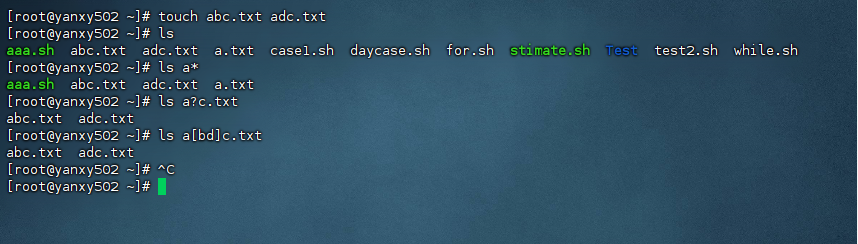
4、正则表达式符号
| 分类 | 具体符号 |
| 基础正则 |
|
| 扩展正则 |
|
5、基础正则
^以…开头的行
grep '^yanxy.com' test.txt
$以…结尾的行
grep 'yanxy.com$' test.txtcat -A可以显示文件中隐藏的字符
^$空行
- 这一行中没有任何内容(空格也是内容)
grep -v排除grep -n显示行号grep -o可以显示过程grep -nv '^$' yanxy.txt
.(点)表示任意一个字符
- 注意:
.(点)不匹配空行 grep '.' yanxy.txt
\转义字符
- \n 回车换行符
- \t tab键制表符
- 特殊符号需要使用转义字符
*前一个字符连续出现0次或0次以上
- 连续出现:0(0出现一次) 00(0出现2次) 00000(0出现5次) yanxy(字母出现了5次)
[root@yanxy502 ~] grep 's*' backup.sh
#!/bin/bash
# TIME 2024-5-11
# AUTHOR "闫小雨"
ftpserver="ip_address"
user="user"
passwd="passwd"
Wpath="path"
ftp -n -v $ftpserver << EOF
user $user $passwd
bin
put /opt/1.txt $Wpath/1.txt
bye
EOF
.*所有内容,任何内容,任意内容
grep '.*' backup.sh
grep '^.*t' backup.sh
- 正则表达式的贪婪性:表示所有或连续出现的时候,表现尽可能的贪婪匹配
- [] [abc] 1次匹配一个字符,匹配任何一个字符(a或b或c)
grep -o可以显示匹配过程grep -i不区分大小写
[root@yanxy502 ~] grep '[awc]' backup.sh
#!/bin/bash
ftpserver="ip_address"
passwd="passwd"
Wpath="path"
user $user $passwd
put /opt/1.txt $Wpath/1.txt
[root@yanxy502 ~] grep -o '[awc]' backup.sh
a
a
a
w
a
w
a
a
a
w
a
[root@yanxy502 ~] grep '[A-Z]' backup.sh
# TIME 2024-5-11
# AUTHOR "闫小雨"
Wpath="path"
ftp -n -v $ftpserver << EOF
put /opt/1.txt $Wpath/1.txt
EOF
- 匹配文件中的大小写字母和数字[root@nas01 ~]#
grep '[a-Z0-9]' backup.sh []中的内容会被去掉特殊含义
[^abc]取反,排除 排除a或b或c的内容,匹配a或b或c以外的内容
6、基础正则表达式
正则表达式分为:
- 基础正则表达式
- 扩展正则表达式
主要使用基础正则表达式,扩展正则表达式这里不介绍
| 元字符 | 作用 |
| * | 前一个字符连续出现(重复)0次或者0次以上 |
| . | 匹配除了换行符外 任意一个字符 |
| ^ | 匹配行首. 例如:^hello 会匹配以 hello 开头的行 |
| $ | 匹配行尾. 例如:hello& 会匹配以 hello 结尾的行 |
| [] | 匹配中括号中指定的任意一个字符,制匹配一个字符 |
| [^] | 匹配除中括号的字符以外的任意一个字符 |
| \ | 转义符. 用于取消特殊符号的含义 |
| \{n\} | 表示其前面的字符恰好出现 n 次 |
| \{n,\} | 表示其前面的字符出现不小于 n 次 |
| \{n,m\} | 表示其前面的字符至少出现 n 次,最多出现 m 次 |
| 贪婪性 | .*或连续出现 |
[]例如:[aoeiu] 匹配任意一个元音字母,[0-9] 匹配任意一位数字,[a-z][0-9]匹配小写字母和一位数字构成的两位字符.
[^]例如:[^0-9] 匹配任意一位非数字字符,[^a-z] 表示任意一位非小写字母.
\{n\}例如:[0-9]\{4\} 匹配 4 位数字,[1][3-8][0-9]\{9\} 匹配手机号码.
\{n,\}例如:[0-9]\{2,\}表示两位及以上的数字.
\{n,m\}例如:[a-z]\{6,8\} 匹配6到8位的小写字母.
?和 < >是扩展正则表达式.
"a*"
# 匹配所有内容,包括空白行
“aa*”
# 匹配至少包含一个a的行
“aaa*”
# 匹配最少包含两个连续a的字符串
“aaaaa*”
# 匹配最少包含四个连续a的字符串7、 扩展正则
扩展正则需要egrep或者grep -E
| 符号 | |
| + | 前一个字符连续出现了1次或1次以上 |
| | | 或者 |
| () | 一个整体.sed反向引用 |
| {} | 连续出现 o(n,m)前一个字母o至少连续出现n次,至多连续出现m次 |
| ? | 连续出现 前一个字符出现0次或者1次 |
+前一个字符连续出现了1次或1次以上
[root@yanxy502 ~] grep 'y+' backup.sh
[root@yanxy502 ~] grep -E 'y+' backup.sh
bye
[root@yanxy502 ~] egrep 'y+' backup.sh
bye
|或者
[root@yanxy502 ~] egrep 'ft|us' backup.sh
ftpserver="ip_address"
user="user"
ftp -n -v $ftpserver << EOF
user $user $passwd
()被括起来的内容,表示一个整体(一个字符)反向引用(反向引用sed)
[root@yanxy502 ~] egrep 'pa(s|th)' backup.sh
passwd="passwd"
Wpath="path"
user $user $passwd
put /opt/1.txt $Wpath/1.txt
{}连续出现 o(n,m)前一个字母o至少连续出现n次,至多连续出现m次
| 符号 | 含义 | |
| o(n,m) | 前一个字母o至少连续出现n次,至多连续出现m次 | >=n <=m |
| o(n) | 前一个字母o连续出现n次 | ==n |
| o(n,) | 前一个字母o至少连续出现n次 | >=n |
| o(,m) | 前一个字母o最多连续出现m次 | <=m |
?连续出现 前一个字符出现0次或者1次
[root@yanxy502 ~] cat yy.txt
goooood
good
god
gd
gooood
[root@yanxy502 ~] egrep 'go?d' yy.txt
god
gd
二、sed文本处理工具
1、Sed简介
sed定义:
-
- sed是一种流编辑器,用于对输入数据(文件或管道)进行基本的文本转换。
- 它按行读取输入,将每一行存储在称为“模式空间”的临时缓冲区中。
- 在模式空间中,sed命令可以对文本进行编辑,然后将结果输出到标准输出(或文件,如果使用重定向)。
sed的工作流程:
-
- 读取一行文本到模式空间。
- 对模式空间中的文本应用sed命令。
- 将处理后的文本输出到标准输出或文件。
- 读取下一行文本,重复上述过程,直到输入结束。
sed的用途:
-
- 自动编辑文件:可以编写sed脚本来自动执行文本替换、删除、插入等任务。
- 简化重复操作:对于需要对文件执行多次相同操作的情况,sed可以大大简化工作流程。
- 编写转换程序:由于sed的强大文本处理能力,它可以用于编写各种文本转换和处理程序。
2、 sed定址
- 可以通过定址来定位你所希望编辑的行,该地址用数字构成,用逗号分隔的两个行数表示以这两行为起止的行的范围(包括行数表示的那两行)。 如1,3表示1,2,3行,
$表示最后一行。范围可以通过数据,正则表达式或者二者结合的方式确定 。
- 单个行号:
可以直接指定一个行号来编辑那一行。例如,sed '2s/foo/bar/'file 会将file中的第二行中的foo替换为bar。 - 行号范围:
使用逗号分隔两个行号可以指定一个范围。例如,sed '1,3s/foo/bar/'file 会将file中第1到第3行中的foo替换为bar。 $符号:
代表文件的最后一行。例如,sed '$s/foo/bar/' file 会将file中最后一行中的foo替换为bar`。
- 正则表达式:
除了行号,还可以使用正则表达式来匹配行。例如,sed '/^pattern/s/foo/bar/'file 会将匹配以pattern开头的行中的foo替换为bar。 - 组合使用:
可以组合使用行号和正则表达式。例如,sed '1,/^pattern/s/foo/bar/'file 会从第一行开始,直到第一个匹配以pattern开头的行为止,将这些行中的foo替换为bar。 - 空地址(即无地址):
如果不指定地址,sed命令将应用于所有行。例如,sed 's/foo/bar/'file 会将file中所有行的foo替换为bar。 !符号:
在地址表达式后加上!会选择不匹配该地址的行。例如,sed '1,3!s/foo/bar/'file 会将第1到第3行之外的所有行中的foo替换为bar。- 多个地址或地址范围:
可以在一个sed命令中指定多个地址或地址范围,并使用分号;分隔它们。例如,sed '1,3s/foo/bar/; 5s/baz/qux/'file 会将第1到第3行中的foo替换为bar,并将第5行中的baz替换为qux。
3、Sed命令
调用sed命令有两种形式:
sed [options] 'command' file(s)
sed [选项] '操作' 参数
sed [options] -f scriptfile file(s)
sed [选项] -f 脚本文件 参数| 命令 | 描述 |
|
| 在当前行下面增加一行指定内容 |
|
| 将选定行替换为指定内容 |
|
| 从模板块位置删除行 |
|
| 删除模板块的第一行 |
|
| 在当前行上面插入文本 |
|
| 拷贝模板块的内容到内存中的缓冲区 |
|
| 追加模板块的内容到内存中的缓冲区 |
|
| s/re/string将re替换为string |
|
| 获得内存缓冲区的内容,并替代当前模板块中的文本 |
|
| 获得内存缓冲区的内容,并追加到当前模板块文本的后面。 |
|
| 列表,列出不能打印字符的清单。 |
|
| 打印模板块的行。 |
|
| 打印模板块的第一行。 |
|
| 退出Sed。 |
|
| 从文本中读行。 |
|
| 写入并追加模板块到file末尾。 |
|
| 打印当前行号码。 |
|
| 把注释扩展到下一个换行符以前。 |
以下的是替换标记
g表示行内全面替换。p表示打印行。w表示把行写入一个文件。x表示互换模板块中的文本和缓冲区中的文本。y表示把一个字符翻译为另外的字符(但是不用于正则表达式)
4、选项
| 命令 | 描述 | |
| -e或者--expression= | 指定命令或脚本来处理输入的文件 | |
| -h或者--help | 显示帮助 | |
| -n、--quiet或silent | 表示仅显示处理后的结果,取消默认输出 | |
| -f或者--file= | 指定脚本文件来处理输入的文件 | |
| -V或者–version | 打印版本和版权信息。 | |
| -i | 直接编辑文本文件 | 表示仅显示处理后的结果 |
5、可使用的元字符集
| 命令 | 描述 | 举例 |
|
| 锚定行的开始 | /^sed/匹配所有以sed开头的行。 |
|
| 锚定行的结束 | /sed$/匹配所有以sed结尾的行。 |
|
| 匹配一个非换行符的字符 | /s.d/匹配s后接一个任意字符,然后是d。 |
|
| 匹配零或多个字符 | /*sed/匹配所有模板是一个或多个空格后紧跟sed的行。 |
|
| 匹配一个指定范围内的字符 | /[Ss]ed/匹配sed和Sed |
|
| 匹配一个不在指定范围内的字符 | /[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。 |
|
| 保存匹配的字符 | s/(love)able/\1rs,loveable被替换成lovers。 |
|
| 保存搜索字符用来替换其他字符 | s/love/&/,love这成love。 |
|
| 锚定单词的开始 | /<love/匹配包含以love开头的单词的行 |
|
| 锚定单词的结束 | /love>/匹配包含以love结尾的单词的行。 |
|
| 重复字符x,m次 | /0{5}/匹配包含5个o的行 |
|
| 重复字符x,至少m次 | /o{5,}/匹配至少有5个o的行。 |
|
| 重复字符x,至少m次,不多于n次 | /o{5,10}/匹配5–10个o的行。 |
6、示例
1.1. 删除:d命令
sed '2d' example #删除example文件的第二行。
sed '2,$d' example #删除example文件的第二行到末尾所有行。
sed '$d' example #删除example文件的最后一行。
sed '/test/'d example #删除example文件所有包含test的行。1.2. 替换:s命令
sed 's/test/mytest/g' example #在整行范围内把test替换为mytest。如果没有g标记,则只有每行第一个匹配的test被替换成mytest。
sed -n 's/^test/mytest/p' example #(-n)选项和p标志一起使用表示只打印那些发生替换的行。也就是说,如果某一行开头的test被替换成mytest,就打印它。
sed 's/^192.168.0.1/&localhost/' example #&符号表示替换换字符串中被找到的部份。所有以192.168.0.1开头的行都会被替换成它自已加localhost,变成192.168.0.1localhost。
sed -n 's/\(love\)able/\1rs/p' example #love被标记为1,所有loveable会被替换成lovers,而且替换的行会被打印出来。
sed 's#10#100#g' example #不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,“#”在这里是分隔符,代替了默认的“/”分隔符。表示把所有10替换成100。1.3. 选定行的范围:逗号
sed -n '/test/,/check/p' example #所有在模板test和check所确定的范围内的行都被打印。
sed -n '5,/^test/p' example #打印从第五行开始到第一个包含以test开始的行之间的所有行。
sed '/test/,/check/s/$/sed test/' example #对于模板test和west之间的行,每行的末尾用字符串sed test替换。1.4. 多点编辑:e命令
sed -e '1,5d' -e 's/test/check/' example #(-e)选项允许在同一行里执行多条命令。如例子所示,第一条命令删除1至5行;第二条命令用check替换test。命令的执行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。
sed --expression='s/test/check/' --expression='/love/d' example #一个比-e更好的命令是--expression。它能给sed表达式赋值。1.5. 从文件读入:r命令
sed '/test/r file' example #file里的内容被读进来,显示在与test匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面。1.6. 写入文件:w命令
sed -n '/test/w file' example #在example中所有包含test的行都被写入file里。1.7. 追加命令:a命令
sed '/^test/a\\--->this is a example' example #'this is a example'被追加到以test开头的行后面,sed要求命令a后面有一个反斜杠。1.8. 插入:i命令
$ sed '/test/i\\
new line
-------------------------' example #如果test被匹配,则把反斜杠后面的文本插入到匹配行的前面。1.9. 下一个:n命令
sed '/test/{ n; s/aa/bb/; }' example #如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续。1.10. 变形:y命令
sed '1,10y/abcde/ABCDE/' example #把1--10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令。1.11. 退出:q命令
sed '10q' example #打印完第10行后,退出sed。1.12. 保持和获取:h命令和G命令
sed -e '/test/h' -e '$G example
#在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中。
除非行被删除或者输出被取消,否则所有被处理的行都将打印在屏幕上。
接着模式空间被清空,并存入新的一行等待处理。在这个例子里,匹配test的行被找到后,
将存入模式空间,h命令将其复制并存入一个称为保持缓存区的特殊缓冲区内。
第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,
且追加到现在已经存在于模式空间中的行的末尾。在这个例子中就是追加到最后一行。
简单来说,任何包含test的行都被复制并追加到该文件的末尾。1.13. 保持和互换:h命令和x命令
sed -e '/test/h' -e '/check/x' example #互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换。7、 脚本
Sed脚本是一个sed的命令清单,启动Sed时以-f选项引导脚本文件名。 Sed对于脚本中输入的命令非常挑剔,在命令的末尾不能有任何空白或文本, 如果在一行中有多个命令,要用分号分隔。以#开头的行为注释行,且不能跨行。
注意:
在sed的命令行中引用shell变量时要使用双引号,而不是通常所用的单引号。 下面是一个根据name变量的内容来删除named.conf文件中zone段的脚本:
name='zone\ "localhost"'
sed "/$name/,/};/d" named.conf三、awk文本处理工具
1、简介
awk 是一种编程语言,用于文本和数据进⾏行处理。 数据可以来自标准输入、⼀个或多个文件,或其它命令的输出。 它⽀持⽤户自定义函数和动态正则表达式等先进功能。 它在命令行中使用,但更多是作为脚本来使用。 awk 的处理文本和数据的方式是逐行扫描⽂文件,从第一行到最后⼀行,寻找匹配的特定模式的行,并在这些行上进行想要的操作。 如果没有指定处理动作,则把匹配的行显示到标准输出(屏幕),如果没有指定模式,则所有被操作所指定的行都被处理。
2、 awk的语法有两种形式
awk [options] 'script' { var=value } file(s)
awk [选项] '条件或模式' { 编辑指令 } 文件
awk [options] -f scriptfile file(s)
awk [选项] -f 脚本文件 文件3、模式和操作
awk脚本是由模式和操作组成的:
pattern {action} 如$ awk '/root/' test,或$ awk '$3 < 100' test。两者是可选的,如果没有模式,则 action 应用到全部记录,如果没有 action,则输出匹配全部记录。 默认情况下,每一个输入行都是一条记录,但用户可通过RS变量指定不同的分隔符进行分隔。
1. 模式
模式可以是以下任意一个:
- /正则表达式/:使用通配符的扩展集。
- 关系表达式:可以用下面运算符表中的关系运算符进行操作,可以是字符串或数字的比较,如$2>%1选择第二个字段比第一个字段长的行。
- 模式匹配表达式:用运算符(匹配)和!(不匹配)。
- 模式,模式:指定一个行的范围。该语法不能包括BEGIN和END模式。
- BEGIN:让用户指定在第一条输入记录被处理之前所发生的动作,通常可在这里设置全局变量。
- END:让用户在最后一条输入记录被读取之后发生的动作。
2. 操作
操作由一人或多个命令、函数、表达式组成,之间由换行符或分号隔开,并位于大括号内。主要有四部份:
- 变量或数组赋值
- 输出命令
- 内置函数
- 控制流命令
4、awk的内建变量
| 变量 | 描述 |
|
| 当前记录的第n个字段,字段间由FS分隔。 |
|
| 顺序表示行(记录)中不同字段 |
|
| 整个行(记录) |
|
| 字段分隔符(默认是任何空格)。 |
|
| 当前记录中的字段数。 |
|
| 当前记录数。(一个计数器,每处理完一条记录,NR的值就增加1) |
|
| 同NR,但相对于当前文件。 |
|
| 记录分隔符(默认是一个换行符)。 |
|
| 输出记录分隔符(默认值是一个换行符)。 |
|
| 命令行参数的数目。 |
|
| 命令行中当前文件的位置(从0开始算)。 |
|
| 包含命令行参数的数组。 |
5、awk运算符
- 赋值运算符
| 运算符 | 名称 | 描述 | 举例 |
|
| 基本的赋值运算符 | 它将右侧的值或表达式的结果赋给左侧的变量 | x = 5 ;x 的值现在是 5 |
|
| 加等于运算符 | 它将右侧的值加到左侧的变量上,并将结果存回左侧的变量中 | x = 5,x += 3;相当于 x = x + 3,x 的值现在是 8 |
|
| 减等于运算符 | 它从左侧的变量中减去右侧的值,并将结果存回左侧的变量中 | x = 8,x -= 3;相当于 x = x - 3,x 的值现在是 5 |
|
| 乘等于运算符 | 它将左侧的变量与右侧的值相乘,并将结果存回左侧的变量中 | x = 5,x *= 3;相当于 x = x * 3,x 的值现在是 15 |
|
| 除等于运算符 | 它将左侧的变量除以右侧的值,并将结果(通常是浮点数)存回左侧的变量中 | x = 15,x /= 3;相当于 x = x / 3,x 的值现在是 5.0 |
|
| 取模等于运算符 | 它计算左侧的变量除以右侧的值后的余数,并将结果存回左侧的变量中 | x = 10,x %= 3;相当于 x = x % 3,x 的值现在是 1 |
- 常规运算符
| 运算符 | 描述 |
|
| 条件表达式 |
|
| 逻辑或 |
|
| 逻辑与 |
|
| 匹配正则表达式和不匹配正则表达式 |
|
| 关系运算符 |
| 空格 | 连接 |
|
| 加,减 |
|
| 乘,除 |
|
| 逻辑非、求余 |
|
| 求幂 |
|
| 自增和自减运算符,作为前缀或后缀 |
|
| 字段引用 |
|
| 数组成员 |
6、匹配操作符(~)
用来在记录或者域内匹配正则表达式。
awk '$1 ~/^root/' test #将显示test文件第一列中以root开头的行。7、比较表达式
conditional expression1 ? expression2: expression3awk '{max = ($1 > $3) ? $1: $3; print max}' test #如果第一个域大于第三个域,$1就赋值给max,否则$3就赋值给max。
awk '$1 + $2 < 100' test #如果第一和第二个域相加大于100,则打印这些行。
awk '$1 > 5 && $2 < 10' test #如果第一个域大于5,并且第二个域小于10,则打印这些行。8、示例
$ awk '/^(no|so)/' test #打印所有以模式no或so开头的行。
$ awk '/^[ns]/{print $1}' test #如果记录以n或s开头,就打印这个记录。
$ awk '$1 ~/[0-9][0-9]$/(print $1}' test #如果第一个域以两个数字结束就打印这个记录。
$ awk '$1 == 100 || $2 < 50' test #如果第一个或等于100或者第二个域小于50,则打印该行。
$ awk '$1 != 10' test #如果第一个域不等于10就打印该行。
$ awk '/test/{print $1 + 10}' test #如果记录包含正则表达式test,则第一个域加10并打印出来。
$ awk '{print ($1 > 5 ? "ok "$1: "error"$1)}' test #如果第一个域大于5则打印问号后面的表达式值,否则打印冒号后面的表达式值。















 7160
7160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











