






1.Mysql的基本操作

1、mysql服务的启动和停止 net stop mysql net start mysql 启动失败可按快捷键 win+R,输入 services.msc,找到MySQL服务器的名称启动 2、登陆mysql mysql (-h)-u 用户名 -p 用户密码 注意,如果是连接到另外的机器上,则需要加入一个参数-h机器IP 1 2 键入命令mysql -u root -p, 回车后提示你输入密码,然后回车即可进入到mysql中了 3、增加新用户 grant 权限 on 数据库.* to 用户名@登录主机 identified by "密码" 1 例:增加一个用户user密码为password,让其可以在本机上登录, 并对所有数据库有查询、插入、修改、删除的权限。首先用以root用户连入mysql,然后键入以下命令: grant select,insert,update,delete on . to user@localhost Identified by “password”; 如果希望该用户能够在任何机器上登陆mysql,则将localhost改为"%"。 4、 操作数据库 登录到mysql中,然后在mysql的提示符下运行下列命令,每个命令以分号结束。 选择你所创建的数据库 use 数据库名 1 导入.sql文件命令(例D:/mysql.sql): mysql>use 数据库名; mysql>source d:/mysql.sql; 1 2 Ⅰ、 显示数据库列表。 show databases; 1 缺省有两个数据库:mysql和test。 mysql库存放着mysql的系统和用户权限信息,我们改密码和新增用户,实际上就是对这个库进行操作。 Ⅱ、 显示库中的数据表: use 库名; tables; 1 2 Ⅲ、 显示数据表的结构: describe 表名; 1 Ⅳ、 建库与删库: create database 库名(character set utf8); drop database 库名; 1 2 Ⅴ、 建表与删表: use 库名; create table 表名(字段列表); drop table 表名; 1 2 3 Ⅵ、 清空表中记录: delete from 表名; 1 Ⅶ、 显示表中的记录: select * from 表名; 1 Ⅷ、 往表中加入记录: insert into 表名 values (字段列表); 1 Ⅹ、更新表中数据 mysql>update 表名 set 字段="值" where 子句 order by 子句 limit 子句 WHERE 子句:可选项。用于限定表中要修改的行。若不指定,则修改表中所有的行。 ORDER BY 子句:可选项。用于限定表中的行被修改的次序。 LIMIT 子句:可选项。用于限定被修改的行数。 1 2 3 4 5、导出和导入数据 Ⅰ. 导出数据: mysqldump --opt test > mysql.test 即将数据库test数据库导出到mysql.test文本文件 例:mysqldump -u root -p用户密码 --databases dbname > mysql.dbname 1 2 3 Ⅱ. 导入数据: mysqlimport -u root -p用户密码 < mysql.dbname。 1 Ⅲ. 将文本数据导入数据库: 文本数据的字段数据之间用tab键隔开。 use test; load data local infile "文件名" into table 表名; 1 2 3 6、退出MYSQL命令: exit (回车)

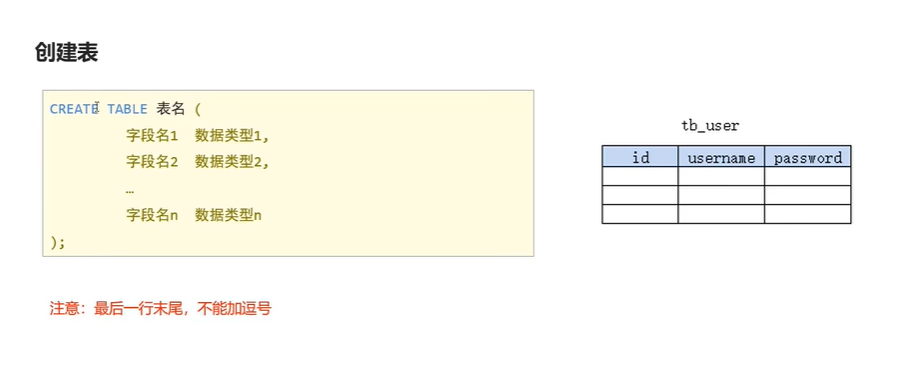
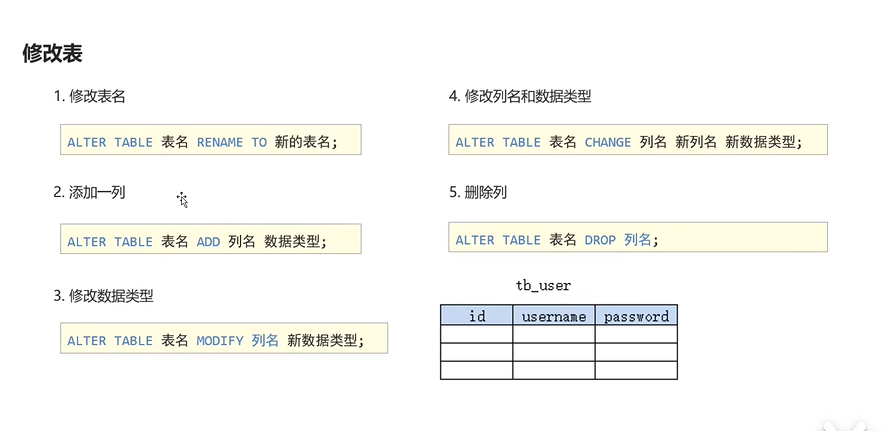
1.DDL--数据库操作语言


2.DML--数据操作语言
--添加数据:(insert)
--修改数据:(update)
--删除数据:(delete)
添加:


字符串和日期通常用单引号包含!!!
更新:

如:
更新id为1的员工的名字为itheima update employee set name ='itheima' where id=1;--- - 不写id=1会把所有name都修改为itheima,要注意!!
删除:
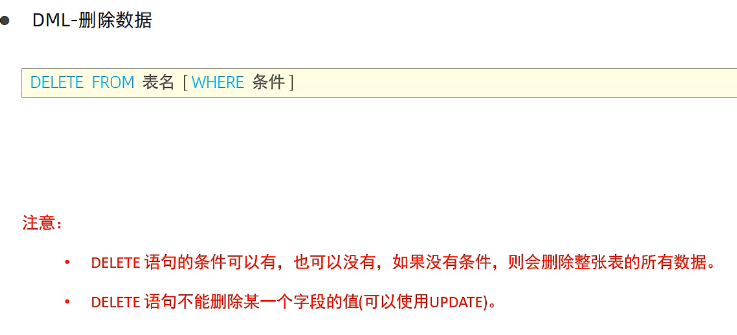
删除gender为女的员工: delete from employee where gender='女' 记得加条件,不然容易删除全部数据
3.DQL--数据查询语言

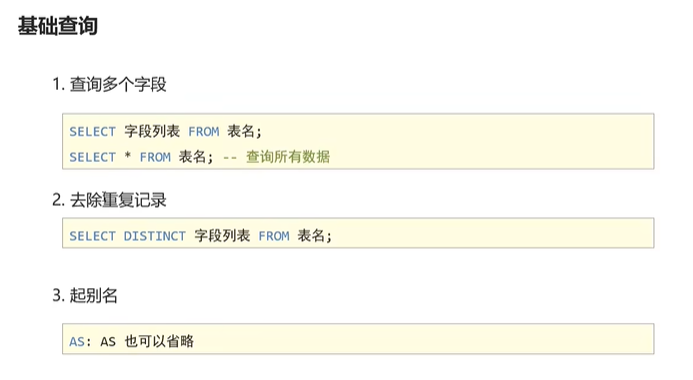
-- 基础查询======== select * from stu; -- 查询name,age两列(指定列) select name,age from stu; -- 查询所有列的数据,列名能用*代替;不要用!; select address from stu; -- 去除重复记录 select DISTINCT address from stu; -- 查询姓名,数学成绩,英语成绩; select name,math ,english from stu;
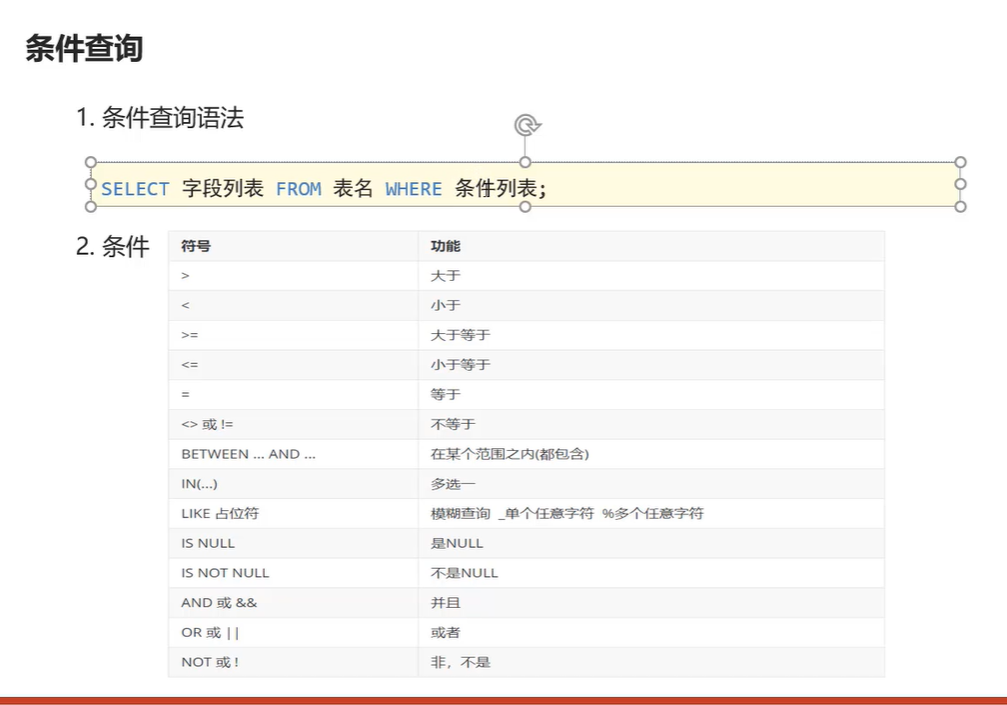
-- 条件差询======================= -- 1.查询年龄大于20岁的学员信息 select * from stu where age>20; -- 查询学员大于等于20 select * from stu where age>=20; -- 2.查询年龄大于18岁并小于30岁的学员信息 select * from stu where age>18 and age<=30; -- 3.查询入学日期在1998-9-01到1999-9-01建学院信息 select * from stu where hire_date between '1998-09-01'and '1999-09-01'; -- 4.查询年龄等于18岁的成员 select * from stu where age=18; -- 5,查询年龄不等于18岁的; select * from stu where age!=18; -- 6查询年龄为18或20或22; select * from stu where age=18 or age=20 or age=22; select * from stu where age in (18,20,22); -- 7查询英语为null; select * from stu where english is null;
模糊查询
-- ------ 模糊查询================================ -- 1查询姓马的学员; select * from stu where name like '马%'; -- 2查寻第二个字是'花'的学员信息 select * from stu where name like '_化%'; -- 3 查寻名字中含有德的学员信息; select * from stu where name like '%德%';

-- 排序查寻 -- select * from stu order by age; -- 数学一样时看英语; select * from stu order by math desc ,english asc ; -- 聚合函数 select count(english)from stu;-- count 不能统计null; select max(math)from stu; select min(math)from stu; select sum(math)from stu; select avg(math)from stu; select min(english)from stu;
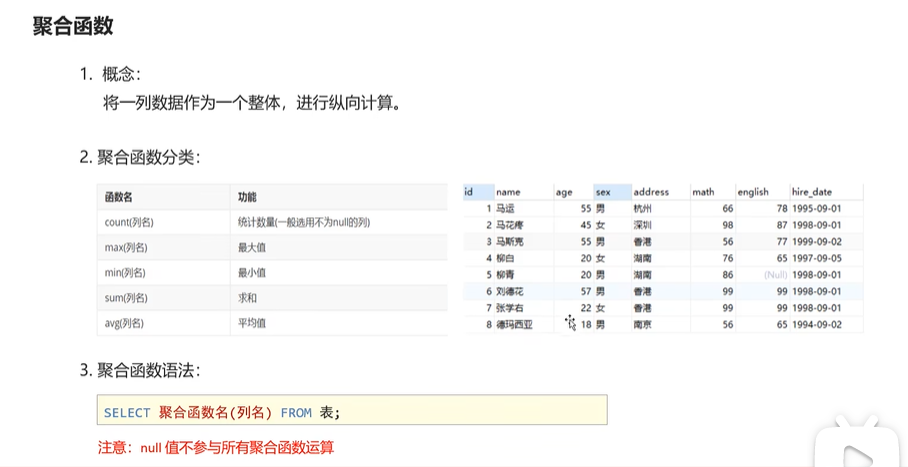

-- 分组查寻 -- 查寻男女同学各自数学平均分; select sex,avg(math) from stu group by sex; -- 查寻男女同学各自数学平均分和各自人数; select sex,avg(math),count(*) from stu group by sex; -- 查寻男女同学各自数学平均分和各自人数,70分一下不参与分组; select sex,avg(math),count(*) from stu where math>70 group by sex; -- 查寻男女同学各自数学平均分和各自人数,70分以下不参与分组,分组后人数大于2 select sex,avg(math),count(*) from stu where math>70 group by sex having count(*)>2;

-- 分页查询=========================== -- 语法:select 字段列表 from 表名 limit 起始索引, 查询条目数;(起始索引从0开始) -- 1从0开始查询,查寻三条数据; select * from stu limit 0,3; -- 2每页显示3条数据,查寻第一页数据 select * from stu limit 0,3; -- 3每页显示三条数据,查询第二页数据 select * from stu limit 3,3; -- 4每页显示3条数据,查寻第三页数据; select * from stu limit 6,3; -- 起始索引=(当前页码-1)*每页显示的条数;
查询语句真正的内部执行顺序:
FROM <表名> # 笛卡尔积 ON <筛选条件> # 对笛卡尔积的虚表进行筛选 JOIN <join, left join, right join...> <join表> # 指定join,用于添加数据到on之后的虚表中,例如left join会将左表的剩余数据添加到虚表中 WHERE <where条件> # 对上述虚表进行筛选 GROUP BY <分组条件> # 分组 <SUM()等聚合函数> # 用于having子句进行判断,在书写上这类聚合函数是写在having判断里面的 HAVING <分组筛选> # 对分组后的结果进行聚合筛选 SELECT <返回数据列表> # 返回的单列必须在group by子句中,聚合函数除外 DISTINCT
数据除重
ORDER BY <排序条件> # 排序 LIMIT <行数限制>
4.DCL用户管理语言

函数
指一段可以直接被另一段程序调用的程序或代码
字符串函数

select concat('Hello',' Mysql');
Hello Mysql
数值函数
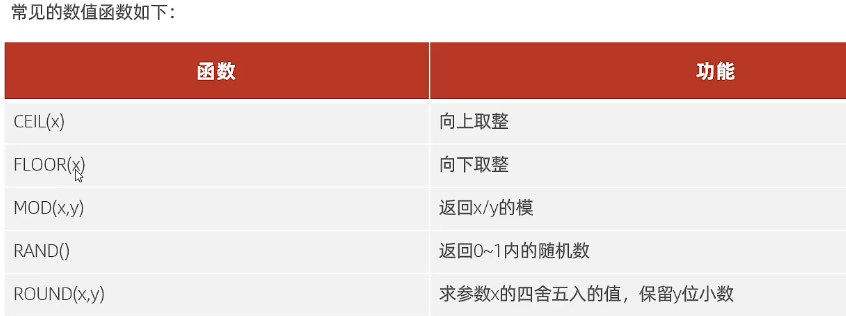
select ceil(1.1); 2 select floor(1.9); 1 select mod(6,4)------ 模是余数 2 round(2.34,1) 2.3
实例:
通过数据库函数,生成一个6位数的随机验证码
select lpad(round(rand()*1000000,0),9,'0'); ====使用了三个函数lpad(左填充),round(四舍五入,保留0位小数),rand(返回0-1随机数)
日期函数
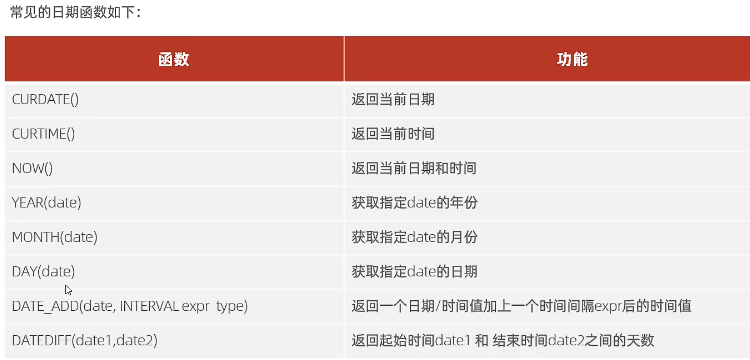
select curdata(); 2023-9-20 select now(); 2023-9-20 16:24:34
流程函数
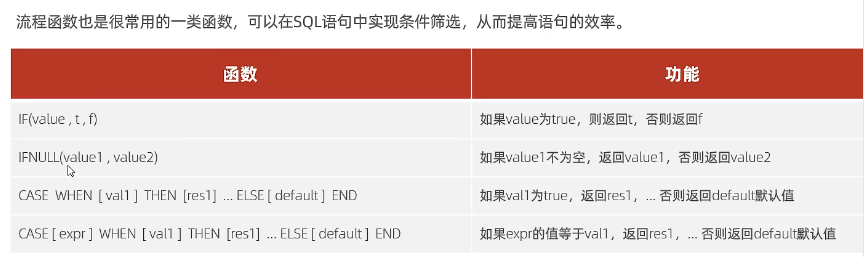
查询emp表的员工姓名和工作地址(北京,上海显示一线城市,其他显示二线城市) select name, (case workaddress when '北京' then '一线城市' when '上海' then '一线城市',else '二线城市' end) as '工作地址' from emp;
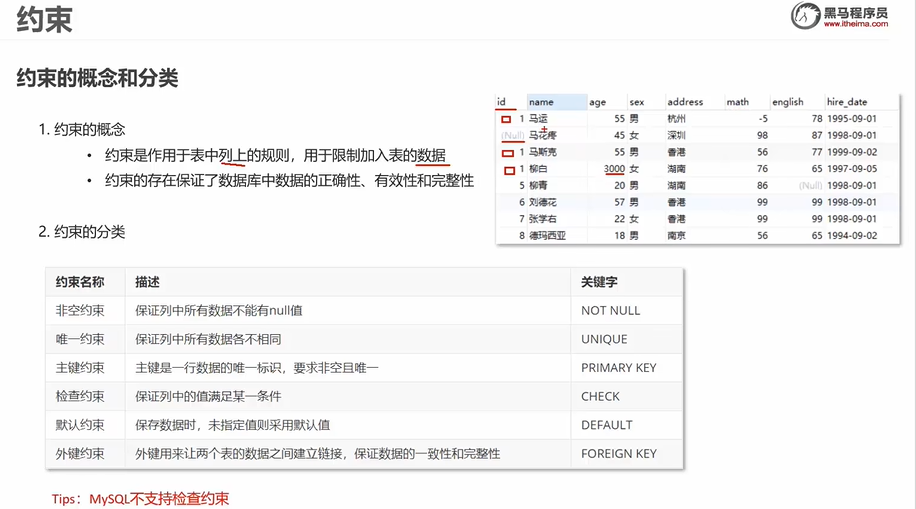
约束

drop table if exists emp; -- 员工表---- create table emp( id int primary key auto_increment, -- 员工id,主键且自增长 ename varchar(50) not null unique ,-- 员工姓名,非空并且唯一 joindate date not null ,-- 入职时间,非空 salary double(7,2) not null ,-- 工资,非空 bonus double(7,2) default 0-- 奖金,如果没有奖金,默认为0; );

外键约束

例:有员工表和部门表,给员工表添加外键
有员工表和部门表,给员工表添加外键,与部门表关联 alter table emp add constraint fk_emp_dept_id foreign key (dept_id) reference dept(id);
好处:(mysql默认)当要删除部门表时,若部门表中还有员工则不能删除,可以保证数据的完整性和一致性;可以改成其他模式:
cascade:理解为株连,改部门表的编号,员工表外键会跟着改变,删掉部门表的一个编号,员工表中对应外键的数据跟着全部删除;
set null 是删掉或修改主表外键,附表外键对应数据致为空
alter table emp drop foreign key fk_emp_dept_id; ----------删除外键
多表查询
多表关系
一对多
例:员工和部门的关系,建立外键就是一对多的实现。不清楚查看上边的外键;
多对多
需要建立中间表,例:学生表和课程表的关系,建新表,设自增主键,设学生id,课程id,并将两者设为外键,关联对应表,
一对一
任意一方加外键关联另一方主键,并设置外键唯一
应用
还是例子:同时查询员工的信息和所属部门就需要
将外键的值=部门id,可以将部门id引入员工表中 select *from emp,dept where dept_id=dept.id;
概述
内连接:
(显式的更好一些,隐式在某些情况下会出现笛卡尔积)

演示:
查询每个员工的姓名,以及关联的部门的名称(隐式) 连接条件:emp.dept_id=dept.id; //即外键id=部门主键id select emp.name,dept.name from emp,dept where emp.dept_id=dept.id; 查询每个员工的姓名,以及关联的部门的名称(显式) select emp.name,dept.name from emp (inner:可省) join dept on emp.dept.id=dept.id;
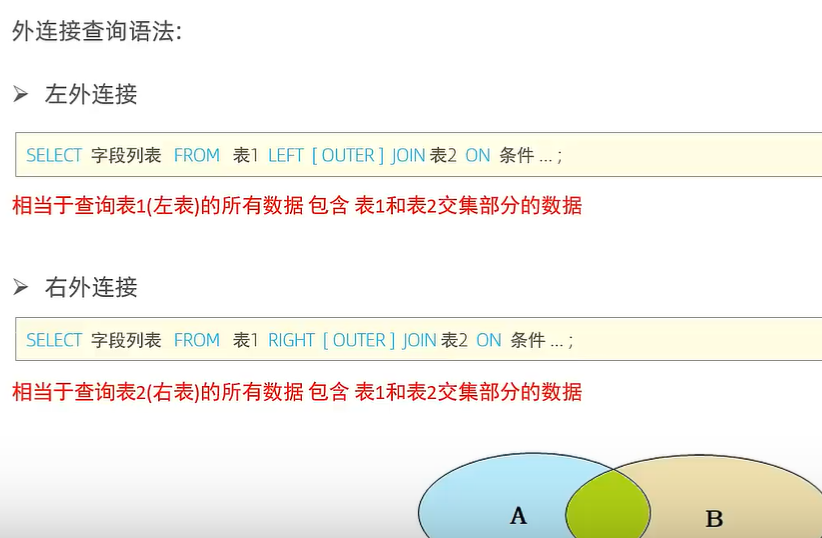
外连接
语法代码和内连接的隐式很像。

左外连接(用的更多):
select 字段列表 from 表1 left[outer:可以省略] join 表2 on 条件...;
例子:
查询每个员工的所有数据,以及关联的部门的名称(左外连接) select emp.*,dept.name from emp left join dept on emp.dept_id=dept.id;
右外连接:
查询dept表的所有数据,和对应的员工信息(右外连接) select emp.*,dept.* from emp dept join emp on emp.dept_id=dept.id;
(右外连接可以改成左外连接,把关键词一改再把1,2表顺序换了)
自连接查询
:在同一个表中查数据(思路,把一个表看成两个表,并起别名)
比如:在所有员工的员工表中(一个表),查询小员工的领导大员工

例:查询员工和其领导的名字 select a.name,b.name from emp a,emp b where a.mangerid=b.id; 查询 a,b的名字,从emp中,条件是a的领导id=b的员工id
联合查询

例:将emp1中薪资低于5000和emp2中年龄大于50的员工全查询出来 select * from emp1 where salary<5000 union【all】 union是将两个结果合并并去重,union all是不去重 select * from emp2 where age>50 适合两个不同的表查询,在同一个表中可以用where or来代替

前提条件太多了。。实战应该用的很少
子查询

标量子查询
:用的还是比较多的,就是嵌套查询,对一个查询的结果当做查询条件
例子: 查询销售部的所有员工信息;(两张表) a:查询销售部部门id; 返回的是一个数字; select id from dept where name='销售部'; b:根据销售部部门id,查询员工信息; select * from emp where dept.id=(select id from dept where name='销售部')
列子查询
例字: 查询销售部和市场部的叟有员工信息 a.查询部门id select id from dept where name='销售部' or name='市场部'; b.根据部门id查询员工信息 select * from emp where dept.id in (select id from dept where name='销售部' or name='市场部') 区别:因为第一次查询返回一列,所以把=改成in,就完事了
行子查询
例子: 查询与张无忌的薪资和直属领导相同的员工信息; a.查询张无忌的薪资和直属领导 select salary,mangerid from emp where name='张无忌'; b.根据张无忌薪资和领导id查询员工信息; select * from emp where (salary,managerid) =(select salary,mangerid from emp where name='张无忌'); 区别:第一次查询会有多个列名,所以把换成in换成(列1,列2,..)=();
表子查询
例子: 查询和鹿杖客或宋远桥职位和薪资都相同的员工 a.查询鹿杖客,宋远桥的薪资和职位 select job,salary from emp where name='鹿杖客'or name='宋远桥'; b.查询与其相同的员工信息; select * from emp where (job,salary) in (select job,salary from emp where name='鹿杖客'or name='宋远桥';) 区别:行和列的合体,因为第一次查询返回表,所以换成(列1,列2,。。)in(),即可;
事务
定义:事务整体是一组操作的集合,所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。(若事务只有一句,往下看)
注意点:mysql事务默认自动提交, 这意味着每个SQL语句都被视为一个独立的事务,并且会立即执行和更改数据库,若想要改变就需要设置事务提交方式设置autocommit=0;
当执行完这个多行事务后需要set autocommit=1;使原来的自动提交开启;
SELECT @@autocommit ;查看 SET @@autocommit = 0 ;更改关闭 每句自动提交 start begin/transaction 开启事务 commit 手动提交事务 rollback 回滚事务,回滚到start begin的位置重新运行;
例:
张三给李四转钱,转1000元, 张三减少1000,李四增加1000 若在张三减1000和李四加1000语句中间出现了错误就会导致张三少钱,李四没有多钱 修改方式: 在代码前加start begin 代码后加commit; rollback;
事务四大特性
1.原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。 2.一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。 3.隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。 4.持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。 上述就是事务的四大特性,简称ACID。
并发事务问题及解决方法:
-
丢失更新问题:
-
问题描述:两个事务同时读取同一行数据并尝试更新它,其中一个事务的更新将覆盖另一个事务的更新,导致数据的部分丢失。
-
解决方法
-
使用锁定机制,如行级锁或表级锁,以确保只有一个事务可以同时更新数据。
-
使用乐观并发控制,通过在更新操作中检查行的版本号或时间戳来检测冲突,并在冲突发生时阻止更新。
-
-
-
脏读问题:
-
问题描述:一个事务读取了另一个事务尚未提交的数据,然后后者回滚,导致前者读取了无效或不一致的数据。
-
解决方法
-
使用事务隔离级别,如可重复读或串行化,以防止脏读。这可以通过设置数据库的隔离级别来实现。
-
显式锁定数据,以确保只有一个事务可以修改它,从而防止脏读。
-
-
-
不可重复读问题:
-
问题描述:在一个事务内,相同的查询多次返回不同的结果,因为其他事务在两次查询之间修改了数据。
-
解决方法
-
使用事务隔离级别,如可重复读或串行化,以防止不可重复读。
-
使用行级锁或范围锁来锁定所需的数据,以确保在事务内查询期间数据的一致性。
-
-
-
幻读问题:
-
问题描述:在一个事务内,相同的查询多次返回不同的行数,因为其他事务在两次查询之间插入或删除了数据。
-
解决方法
-
使用事务隔离级别,如可重复读或串行化,以防止幻读。
-
使用锁定机制,如范围锁,来锁定所需的数据范围,以确保查询期间数据的一致性。
-
-
-
死锁问题:
-
问题描述:多个事务相互等待对方释放锁资源,导致所有事务都无法继续执行。
-
解决方法
-
使用事务超时设置,以便当事务等待锁资源超过一定时间时,自动回滚事务。
-
编写应用程序逻辑,避免事务之间的循环依赖,从而减少死锁的发生。
-
-
存储引擎

首先了解mysql的体系结构
连接层:最上层是一些客户端和链接服务,包含本地sock 通信和大多数基于客户端/服务端工具实现的类似于 TCP/IP的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程 池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务 器也会为安全接入的每个客户端验证它所具有的操作权限
服务层:第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,部 分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如 过程、函数等。在该层,服务器会解 析查询并创建相应的内部解析树,并对其完成相应的优化如确定表的查询的顺序,是否利用索引等, 最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存,如果缓存空间足够大, 这样在解决大量读操作的环境中能够很好的提升系统的性能。
引擎层:存储引擎层, 存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通 信。不同的存储引擎具有不同的功能,这样我们可以根据自己的需要,来选取合适的存储引擎。数据库 中的索引是在存储引擎层实现的。
存储层:数据存储层, 主要是将数据(如: redolog、undolog、数据、索引、二进制日志、错误日志、查询 日志、慢查询日志等)存储在文件系统之上,并完成与存储引擎的交互。
演示:
查询建表语句
默认存储引擎: InnoDB
创建表 my_memory , 指定Memory存储引擎 create table my_memory( id int, name varchar(10) ) engine = Memory ; 、、就是在建表语句后加engine=所用的引擎;
各种存储引擎的特点
InnoDB:
-
特点
-
支持事务,具有ACID(原子性、一致性、隔离性、持久性)特性,适用于要求数据完整性和一致性的应用。
-
支持行级锁,可以提供高并发性能。
-
支持外键约束。
-
支持热备份和恢复。
-
具有自动崩溃恢复功能。
-
-
适用场景:适用于大多数OLTP(联机事务处理)应用,特别是需要事务支持和数据完整性的应用。
-
将表存储在idb文件中,一个文件就是一个表。
逻辑存储结构:
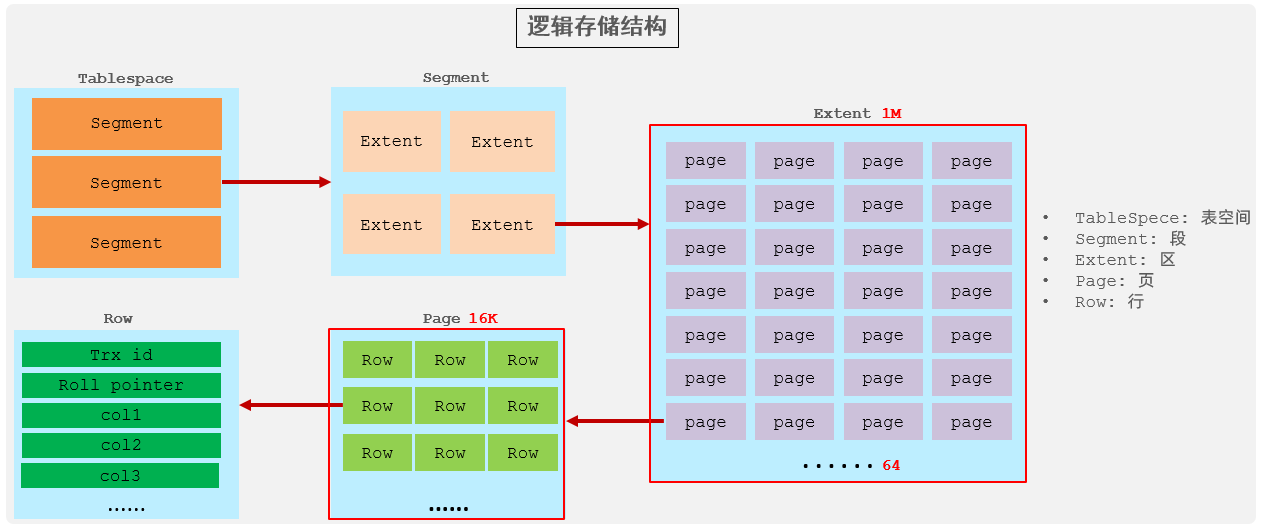
表空间 : InnoDB存储引擎逻辑结构的最高层,ibd文件其实就是表空间文件,在表空间中可以 包含多个Segment段。 段 : 表空间是由各个段组成的, 常见的段有数据段、索引段、回滚段等。InnoDB中对于段的管 理,都是引擎自身完成,不需要人为对其控制,一个段中包含多个区。 区 : 区是表空间的单元结构,每个区的大小为1M。 默认情况下, InnoDB存储引擎页大小为 16K, 即一个区中一共有64个连续的页。 页 : 页是组成区的最小单元,页也是InnoDB 存储引擎磁盘管理的最小单元,每个页的大小默 认为 16KB。为了保证页的连续性,InnoDB 存储引擎每次从磁盘申请 4-5 个区。 行 : InnoDB 存储引擎是面向行的,也就是说数据是按行进行存放的,在每一行中除了定义表时 所指定的字段以外,还包含两个隐藏字段(后面会详细介绍)。
MyISAM:
-
特点
-
不支持事务,不具备ACID属性。
-
支持表级锁,不支持行锁,对于读密集型工作负载效果较好。
-
不支持外键约束。
-
支持全文本搜索。
-
更适合于读取频繁、写入不频繁的应用。
-
-
适用场景:适用于读取密集型应用,如博客、新闻网站等,不适合需要事务支持和数据完整性的应用。
-
文件 xxx.sdi:存储表结构信息 xxx.MYD: 存储数据 xxx.MYI: 存储索引
MEMORY(也称为HEAP):
-
特点
-
将数据存储在内存中,因此读取速度非常快。(hash索引默认)
-
不支持事务。
-
数据在服务器重启时丢失。
-
适用于临时表、缓存和需要快速访问的数据。
-
文件 xxx.sdi:存储表结构信息
-
索引
由于没有索引时操作性能很低,所以引入了索引(实现了特定高级算法的数据结构)
优势 1.提高数据检索的效率,降低数据库 的IO成本 2.通过索引列对数据进行排序,降低 数据排序的成本,降低CPU的消 耗。
劣势 索引列也是要占用空间的。 索引大大提高了查询效率,同时却也降低更新表的速度, 如对表进行INSERT、UPDATE、DELETE时,效率降低。
几种索引结构:
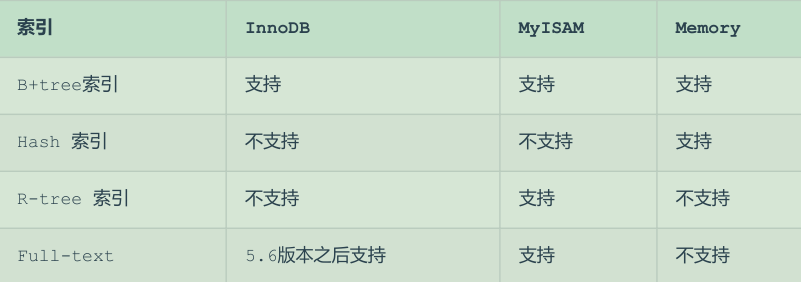

更详细内容可到百度云的黑马pdf查看
此次仅解释B+tree
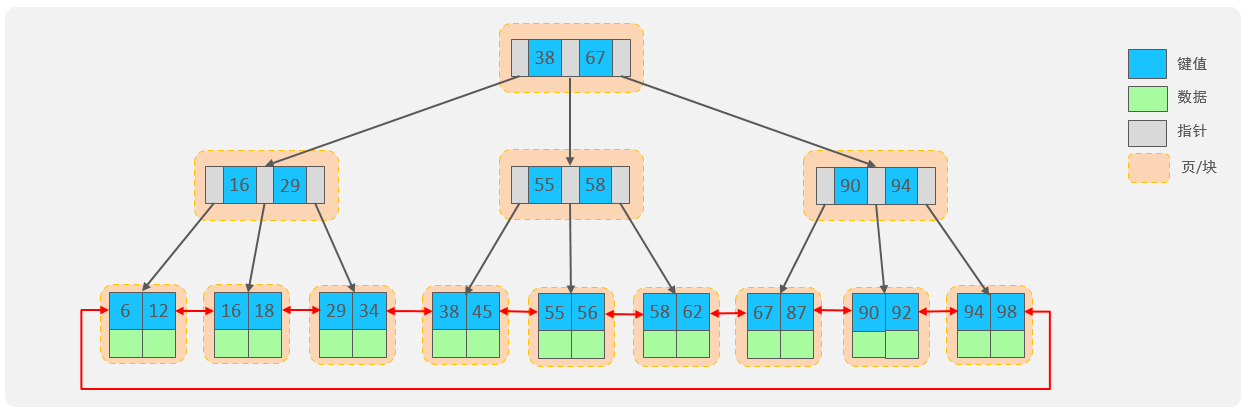
解说:
所有的数据都会出现在叶子节点。 叶子节点形成一个单向链表。 非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的。
mysql优化后的B+tree:
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点 的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能,利于排序。

优点:
-
平衡树结构:B+树是一种平衡树结构,每个节点的子树高度相同或相差不超过1,这保证了在插入和删除数据时树的高度始终保持相对平衡,从而保持了检索性能的稳定性。
-
有序性:B+树的叶子节点形成有序链表,这使得范围查询非常高效,因为在有序链表上的范围查询可以快速定位起始点和结束点。
-
高度浅:B+树的高度相对较浅,通常比其他树结构(如红黑树)更浅,因此在查找特定数据时需要较少的磁盘I/O操作,提高了查询性能。
-
支持等值查找和范围查询:B+树支持等值查找(通过索引快速定位到具体值)和范围查询(通过遍历有序叶子节点链表来查找范围内的值),因此适用于各种查询需求。
-
高扇出性:每个节点可以包含多个子节点和数据项,这使得B+树的分支因子较高,减少了树的深度,进一步提高了检索性能。
-
适用于大数据量:B+树适用于存储大量数据的情况,因为它的高扇出性和平衡性使得在大数据集上的查询效率仍然高。
-
支持多列索引:MySQL支持在表上创建多列组合索引,这允许使用B+树索引来优化多列查询,提高查询性能。
内部运行:
InnoDb中索引存储形式分两类
聚集索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 必须有,而且只有一个 二级索引:将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 可以存在多个

通俗的说:聚集索引就是将一个和主键类似的拥有唯一标识的列作为b+树的节点,在最后一层将对应的值填入,查找时,先找(以id为例)id位置,再对应找数据
例:select * from user where id = 10 ;最能代表聚集索引的运行过程。
(将user的所有值都填到对应的id下,有id就能找到user)
而二级索引呢,是反过来先找对应值的唯一标识(以id为例),最能代表的案例
select id from user where name = 'Arm' ;,直接根据name找到id。
但对于,select * from user where name = 'Arm' ;这样的,就需要二表联合(回表查询),
因为二级索引根据值查找到的是唯一标识(id),并没有办法找到“*”,
而聚集索引又刚好是根据唯一标识找值,内部会把二级索引找到的id传给聚集,聚集根据id找齐所有的值,轻轻松松。
所以:
A. select * from user where id = 10 ; B. select * from user where name = 'Arm' ;‘ 明显A效率高于B,A知道id,直接在聚集中找就行; B还需要在二级中先找到id=10,再传进聚集;
语法
1).创建索引 CREATE INDEX index_name ON table_name (column_name1);单个的 CREATE INDEX index_name ON table_name (column_name1,。。。);多个的 index_name:指定索引的名称,应该是唯一的。 table_name:指定要在哪个表上创建索引。 column_name:指定要在哪个列上创建索引。 2). 查看索引 SHOW INDEX FROM table_name ; 3). 删除索引 DROP INDEX index_name ON table_name ; !!!注意:创建多次单个索引和一次创建多个索引是不一样的!后者叫做复合索引,使用时必须全部使用不然后边的会失效(按表中列的顺序)
索引并不是全都要加的,需要权衡索引带来的好处和弊端
而这就需要对性能进行分析;
通过 show [session|global] status... 、、session是当前对话,global是全局数据; 可以查询 Com_delete: 删除次数 Com_insert: 插入次数 Com_select: 查询次数 Com_update: 更新次数
查询为主就建立索引。增删改为主就不建立。
查看和优化性能的方法
慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。
如果要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
开启MySQL慢日志查询开关 slow_query_log=1 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录到慢查询日志中 long_query_time=2
慢查询日志中就会记载,从而针对性的提升性能
profile的使用(查询执行语句花费的时间)
-
启用
PROFILE:在执行查询之前,需要启用PROFILE功能。可以使用以下语句启用PROFILE:
SET profiling = 1;
-
执行查询:执行要分析的SQL查询语句。
3.查看性能分析信息:执行完查询后,可以使用以下语句查看性能分析信息:
show profile;/// 查看每一条SQL的耗时基本情况 show profile for query query_id;-- 查看指定query_id(语句)的SQL语句各个阶段的耗时情况 show profile cpu for query query_id;-- 查看指定query_id的SQL语句CPU的使用情况
explain/desc
EXPLAIN是一个用于分析SQL查询执行计划的关键字,它允许你查看MySQL数据库中查询语句的执行方式以及如何访问表和索引。EXPLAIN语句不会执行查询,而是返回查询的执行计划,以帮助你了解查询的性能和优化潜力。
(查询到的东西有点多,真正用到的时候再看吧)
索引的使用:
不确定时,可以试一试不建索引和建索引的时间比较,用profile或explain分别查询时间。
最左前缀法则
:只针对联合索引,查询时从左往右,若其中一个没写,那么他之后的列索引全都失效;
范围查询
同样是针对联合索引,出现范围查询(>,<),范围查询右侧的列索引会失效
所以当使用联合索引和范围查询时,使用>= 或 <= 这类的范围查询;
索引失效情况
使用了函数或运算符:如果在查询条件中使用了函数、运算符或类型转换,可能会导致索引失效。这是因为索引通常无法直接应用于这些操作,而需要对每个行执行操作以获得查询结果。
模糊查询和通配符:模糊查询(如LIKE操作符)和通配符查询(如%)通常会导致索引失效,如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
列顺序不匹配:对于复合索引,查询条件的列顺序应与索引的列顺序匹配。如果查询条件的列顺序与索引不匹配,索引可能不会被使用。 (上边讲的)
字符串不加引号:字符串类型字段使用时,不加引号,索引将失效。
(所依要养成字符串加单引号的好习惯,虽然对查询结果无影响,但索引已经失效了)
or连接条件:用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
mysql内部也有索引评估系统:认定索引更慢,即使符合规范也会不使用索引
总结:索引设计的原则
-
1). 针对于数据量较大,且查询比较频繁的表建立索引。
-
2). 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。 3). 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。 4). 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。 5). 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间, 避免回表,提高查询效率。 6). 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。 create unique index idx_user_phone_name on tb_user(phone,name); 1 7). 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
sql优化:
这部分内容图片太多,移步到网盘查看吧
插入数据-insert
三个方面优化:
1.批量插入数据: Insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry'); 2.手动控制事务 start transaction; insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry'); insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'Jerry'); insert into tb_test values(7,'Tom'),(8,'Cat'),(9,'Jerry'); commit; 3.主键顺序插入 主键乱序插入 : 8 1 9 21 88 2 4 15 89 5 7 3 主键顺序插入 : 1 2 3 4 5 7 8 9 15 21 88 89 ps(所以三个一起用优化最好?)
一次性大批量插入数据用load比insert性能高得多,就不写语法了,知道有这个东西就好,用到的时候想到,100w个数据17s就能完成。(遵循主键顺序插入性能会较高)
主键优化:
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表,行数据,都是存储在聚集索引的叶子节点上的。在InnoDB引擎中,数据行是记录在逻辑结构 page 页中的,而每一个页的大小是固定的,默认16K。那也就意味着, 一个页中所存储的行也是有限的,如果插入的数据行row在该页存储不了,将会存储到下一个页中,页与页之间会通过指针连接。
order by优化:
group by优化:
内容还有很多,知识是无穷尽的,大部分内容都来自黑马视频截图和动手的代码
这里给大家一个建议,学习以笔记为主,操作为辅,搭配gpt解答各种疑问,
视频学习效率是最低的,一定要动手















 1264
1264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









