







User-Agent 请求头(搜狗搜索爬虫实例)
json
1.User-Agent请求头
User-Agent 即用户代理,简称“UA”,它是一个特殊字符串头。网站服务器通过识别 “UA”来确定用户所使用的操作系统版本、CPU 类型、浏览器版本等信息。而网站服务器则通过判断 UA 来给客户端发送不同的页面。
所以捏,当你用python爬虫的时候,Python文件就给网页发送一个消息啦,告诉他,我是爬虫,我来找你了,现在很多网站有自己的反爬机制,自然不会,让你进去,所以就会拒绝访问,让你填验证码什么啦。这个时候呢,咱们就需要伪装一下,获取,网页直接访问的用户代理信息,把他封装到一个请求头(headers)字典里。
如何查看请求头信息呢?
常规操作,右键然后点击检查,或者直接F12,在上面点击网络
将页面重新刷新一下,这样你就相当于向页面重新发送了一个请求。
点开一个包,在标头那里下拉,找到请求标头,在这里你就可以看到User-Agent的具体值啦。将这个值以字典的格式存进去,然后做为发送请求时的参数。
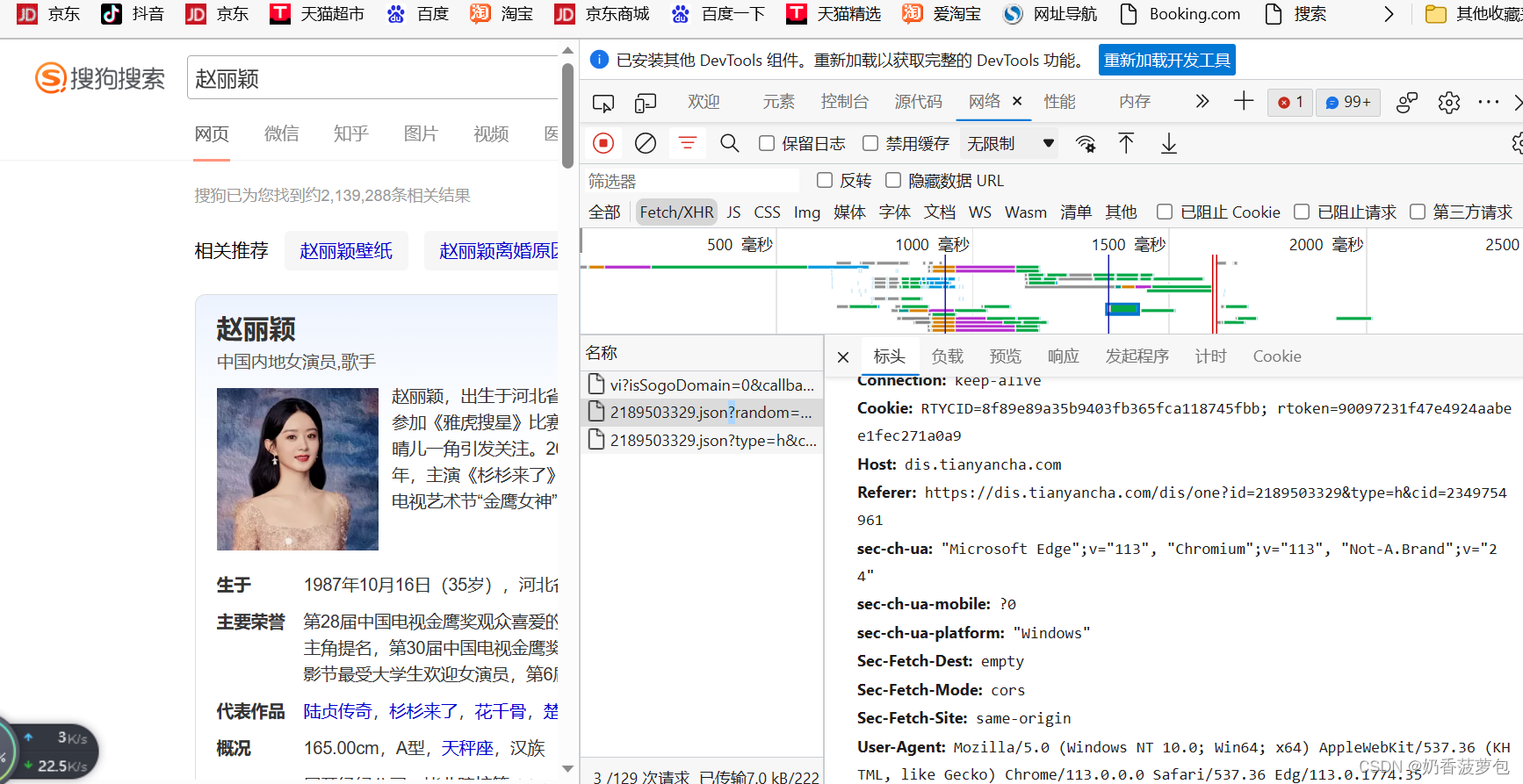
下面是一个爬取搜狗搜索页面的代码
import requests
# if __name__=="main":
url="https://sogou.com/web"
kw=input("搜索内容")
prama={
"query" :kw
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.68'
}
resp=requests.get(url=url,params = prama,headers=headers)
resp.encoding='utf-8'
page_text=resp.text
filename=kw+'.html'
with open(filename,'w',encoding = 'utf-8') as f:
f.write(page_text)
print(filename,"文件保存完整")
但是,一个 IP 超过规定时间内的访问次数, 也会将在一段时间内禁止其再次访问网站的啦。
2.json
开始用爬虫的小伙伴一定会看见json这个啦。
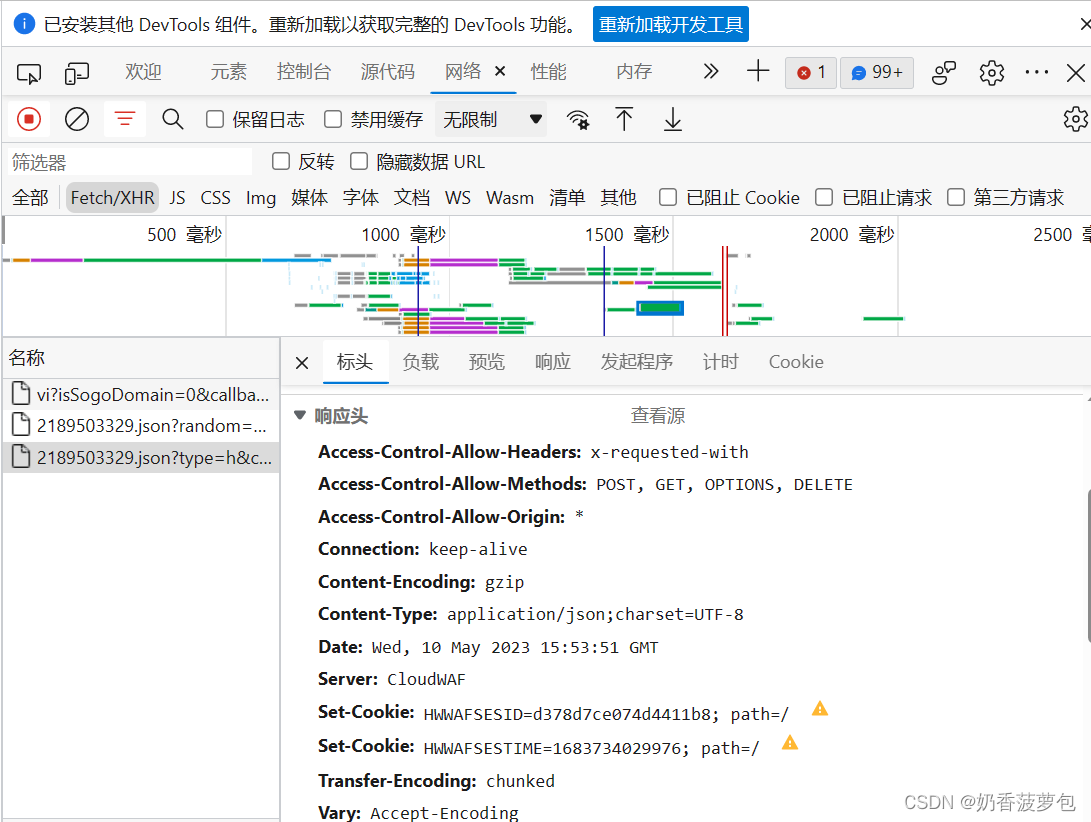
还是在刚才的这个网络工具这里,在响应头中,你会看见,content-Type类型也就是文本类型为json,这是个什么?怎么保存呢?
JSON: JavaScript Object Notation(JavaScript 对象表示法)
JSON 是存储和交换文本信息的语法,类似 XML。
JSON 比 XML 更小、更快,更易解析。
我们通过任何传输协议 (当前 用的比较多的是 http协议) 传送信息,传输的都是 好的字符串。
而且 不同的客户端、服务端程序可能使用不同的语言。为了方便 不同的编程语言 处理, 这个序列化后的 格式 应该是各种语言都 方便 处理的。
使用什么样的序列化 格式 这是 一个 重要问题。
最近的主流方案 就是使用 : JSON 格式
Python中内置了json这个库,可以 方便的把内置的数据对象 序列化为json格式文本的字符串。
就会用到 json.dumps():对数据进行编码
json.dumps 方法发现将字符串中如果有非ascii码字符,比如中文, 缺省就用该字符的unicode数字来表示。
如果你不想这样,可以给参数 ensure_ascii 赋值为 False,如下所示
json.dumps(text,ensure_ascii=False,indent=4)#text是被转化的文件接收方如果也是Python开发的,可以使用 json库中的 loads方法,把json格式的字符串变为 Python中的数据对象json.loads(): 对数据进行解码。
如果你要处理的是文件而不是字符串,你可以使用 json.dump() 和 json.load() 来编码和解码JSON数据。例如:
# 在文件中写入 JSON 数据
with open('data.json', 'w') as f:
json.dump(data, f)
# 从文件中读取数据
with open('data.json', 'r') as f:
data = json.load(f)














 7935
7935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









