






ElasticSearch集群环境
1、Linux单机
下载地址:LINUX X86_64 (elastic.co)
下载之后进行解压
tar -zxf elasticsearch-7.8.0-linux-x86_64.tar.gz
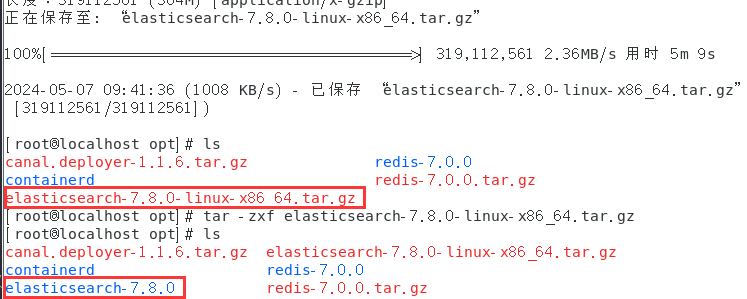
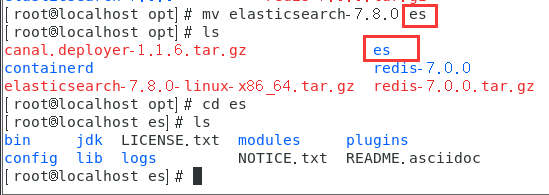
名字太长了改个名字改成es
mv elasticsearch-7.8.0 es
因为安全问题,Elasticsearch 不允许 root 用户直接运行,所以要在每个节点中创建新用户es
useradd es
password es
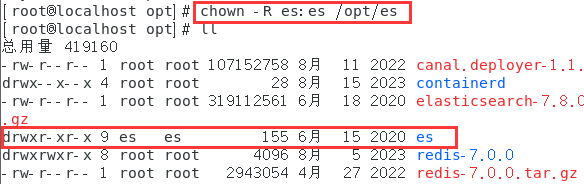
修改es文件的所有者为es
chown -R es:es /opt/es
修改配置文件
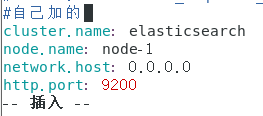
修改/es/config/elasticsearch.yml 文件,添加以下配置
cluster.name: elasticsearch
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
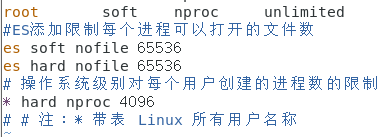
修改/etc/security/limits.conf,在文件的尾行增加每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536

修改/etc/security/limits.d/20-nproc.conf,和上面的限制一样还是限制每个进程可以打开的文件数以及操作系统级别对每一个用户创建的进程数的限制。
es soft nofile 65536
es hard nofile 65536
# 操作系统级别对每个用户创建的进程数的限制
* hard nproc 4096
# 注:* 带表 Linux 所有用户名称
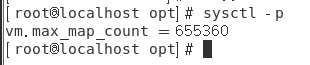
修改/etc/sysctl.conf
# 一个进程可以拥有的 VMA(虚拟内存区域)的数量,默认值为 65536
vm.max_map_count=655360

重新加载一下系统配置文件
sysctl -p
先切换为es用户然后到es目录下启动es
su es
bin/elasticsearch
现在虚拟机中的浏览器访问一下9200端口,出现node-1节点的相关信息访问成功
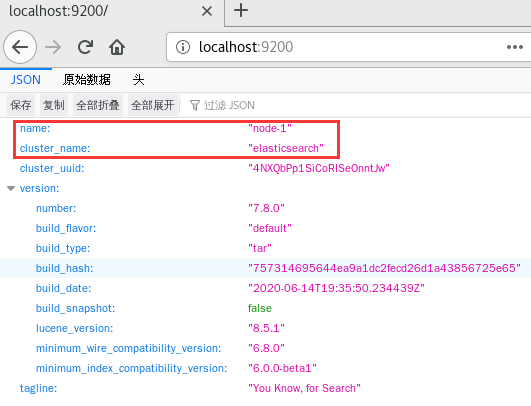
把防火墙关闭之后使用本地的浏览器访问也能显示json串
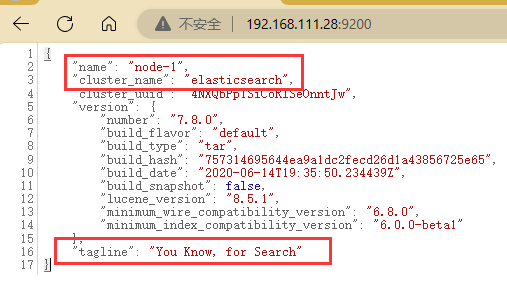
linux单机的就这样结束
2、Linux集群
linux中开几个文件把端口信息改掉就好
这里因为要重复三次一样的解压、改名、赋予权限的操作太麻烦,直接写一个脚本自动执行。
#!/bin/bash
#注意:解压缩和命名操作均在当前文件夹下执行
# 检查是否存在要解压的文件
if [ ! -f "elasticsearch-7.8.0-linux-x86_64.tar.gz" ]; then
echo "elasticsearch-7.8.0-linux-x86_64.tar.gz 文件不存在,请检查文件路径。"
exit 1
fi
# 设置目标用户和组(这里es用户和组已经存在)
TARGET_USER="es"
TARGET_GROUP="es"
# 循环两次以创建esnode2和esnode3
for i in {1..2}; do
# 解压缩文件(如果目录已存在,则先删除)
if [ -d "elasticsearch-7.8.0" ]; then
rm -rf elasticsearch-7.8.0
fi
tar -zxf elasticsearch-7.8.0-linux-x86_64.tar.gz
# 重命名目录
NEW_NAME="esnode$(($i+1))"
mv elasticsearch-7.8.0 "$NEW_NAME"
# 更改目录的所属用户和组
chown -R "$TARGET_USER:$TARGET_GROUP" "$NEW_NAME"
echo "已成功创建并设置 $NEW_NAME 的所属用户和组为 $TARGET_USER:$TARGET_GROUP"
done
echo "所有操作已完成。"
修改/esnode1/config/elasticsearch.yml文件
#集群名称
cluster.name: my-cluster
#节点名称
node.name: "es-node-1"
#定义1为主节点
node.master: true
#定义节点2节点3为数据节点
node.data: true
#访问的IP地址,0.0.0.0表示不限制
network.host: 0.0.0.0
#访问端口号
http.port: 9201
#集群通讯端口号
transport.tcp.port: 9300
#所有节点的ip地址
discovery.zen.ping.unicast.hosts: ["192.168.73.66:9300", "192.168.73.66:9301", "192.168.73.66:9302"]
修改/esnode2/config/elasticsearch.yml文件
#集群名称
cluster.name: my-cluster
#节点名称
node.name: "es-node-2"
#定义1为主节点
node.master: true
#定义节点2节点3为数据节点
node.data: true
#访问的IP地址,0.0.0.0表示不限制
network.host: 0.0.0.0
#访问端口号
http.port: 9202
#集群通讯端口号
transport.tcp.port: 9301
#所有节点的ip地址
discovery.zen.ping.unicast.hosts: ["192.168.73.66:9300", "192.168.73.66:9301", "192.168.73.66:9302"]
修改/esnode3/config/elasticsearch.yml文件
#集群名称
cluster.name: my-cluster
#节点名称
node.name: "es-node-3"
#定义1为主节点
node.master: true
#定义节点2节点3为数据节点
node.data: true
#访问的IP地址,0.0.0.0表示不限制
network.host: 0.0.0.0
#访问端口号
http.port: 9203
#集群通讯端口号
transport.tcp.port: 9302
#所有节点的ip地址
discovery.zen.ping.unicast.hosts: ["192.168.73.66:9300", "192.168.73.66:9301", "192.168.73.66:9302"]
注意: Elasticsearch 默认的 JVM 堆大小是最小/最大 1 GB,所以我使用的虚拟机的内存必须是4G因为你启动了三个服务要确保它们能各分1G正常启动,否则就会报错内存不足无法启动。
分别用es用户身份启动它们
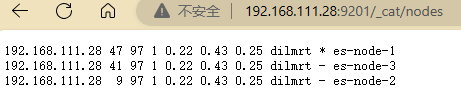
获取每个节点的信息
主节点es-node-1
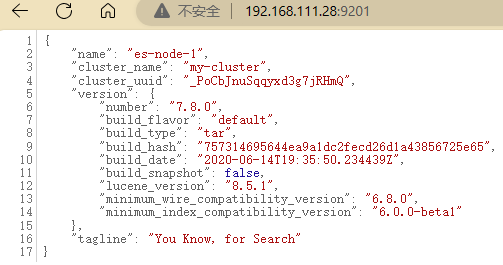
es-node-2
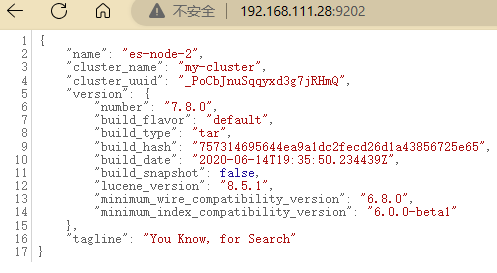
es-node-3
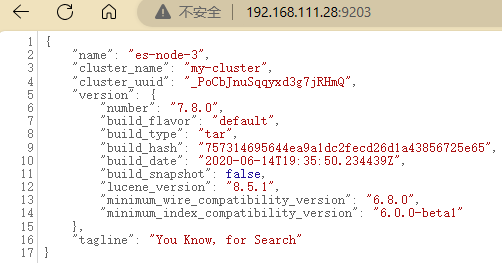
3、windows集群
创建 elasticsearch-cluster 文件夹,在内部复制三个 elasticsearch 服务
修改集群文件目录中每个节点的 config/elasticsearch.yml 配置文件
node-1001 节点:
#节点 1 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node-1001
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1001
#tcp 监听端口
transport.tcp.port: 9301
#discovery.seed_hosts: ["localhost:9301", "localhost:9302","localhost:9303"]
#discovery.zen.fd.ping_timeout: 1m
#discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
node-1002 节点:
#节点 2 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node-1002
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1002
#tcp 监听端口
transport.tcp.port: 9302
discovery.seed_hosts: ["localhost:9301"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
node-1003 节点:
#节点 3 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node-1003
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1003
#tcp 监听端口
transport.tcp.port: 9303
#候选主节点的地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9301", "localhost:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
如果节点中有data目录需要先删除再逐一启动。
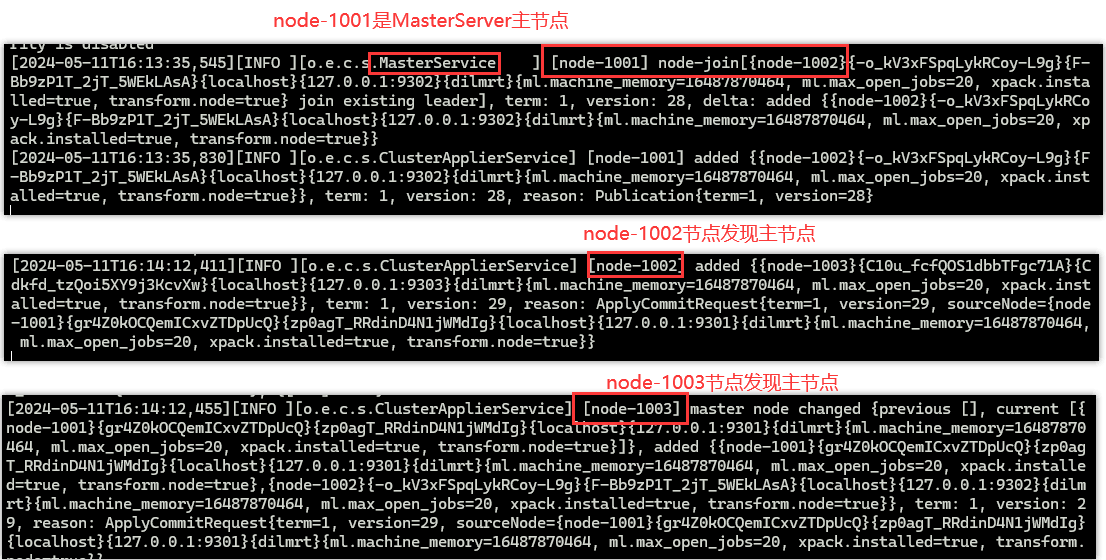
查看一下集群
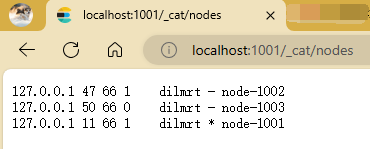
localhost:1001/_cluster/health
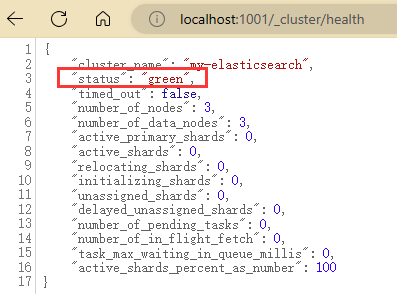
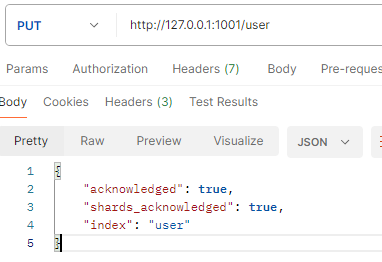
向主节点中添加一个索引user
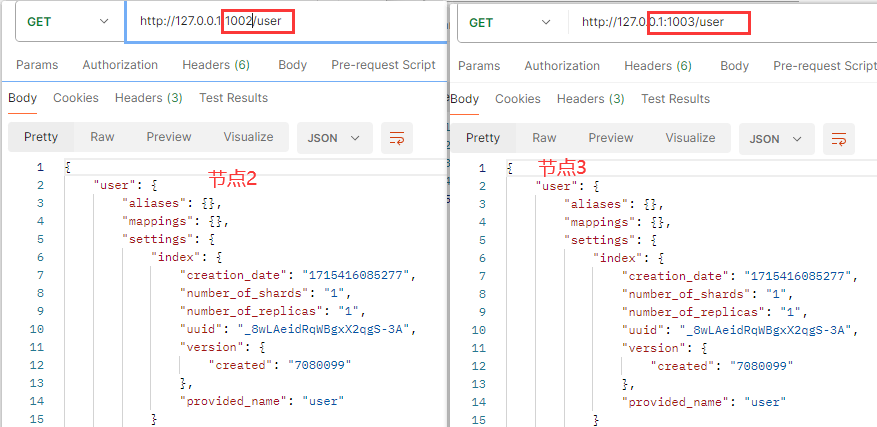
分别在节点2和3中查询一下















 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











