










 本文详细介绍了数据库分表分库的原因、垂直分表和水平分表的方法,以及各自的优势和缺点。此外,还涵盖了分库分表后的常见问题及其解决方案,包括数据一致性、数据迁移、查询性能提升和分布式事务管理等。
本文详细介绍了数据库分表分库的原因、垂直分表和水平分表的方法,以及各自的优势和缺点。此外,还涵盖了分库分表后的常见问题及其解决方案,包括数据一致性、数据迁移、查询性能提升和分布式事务管理等。
目录
为什么会分表分库?
数据库数据会随着业务的发展而不断增多,因此数据操作,如增删改查的开销也会越来越大。
再加上物理服务器的资源有限(CPU、磁盘、内存、IO 等)。最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
换句话说需要合理的数据库架构来存放不断增长的数据,这个就是分库分表的设计初衷。目的就是为了缓解数据库的压力,最大限度提高数据操作的效率。
数据分表
如果单表的数据量过大,例如千万级甚至更多,那么在操作表的时候就会加大系统的开销。
每次查询会消耗数据库大量资源,如果需要多表的联合查询,这种劣势就更加明显了。
以 MySQL 为例,在插入数据的时候,会对表进行加锁,分为表锁定和行锁定。
无论是哪种锁定方式,都意味着前面一条数据在操作表或者行的时候,后面的请求都在排队,当访问量增加的时候,都会影响数据库的效率。
那么既然一定要分表,那么每张表分配多大的数据量比较合适呢?这里建议根据业务场景和实际情况具体分析。
一般来说 MySQL 数据库单表记录最好控制在 500 万条(这是个经验数字)。既然需要将数据从一个表分别存放到多个表中,那么来看看下面两种分表方式吧。
怎么分表?
垂直分表
直分表是一种将大型表按列进行拆分,将不同的列分离出来形成多个表的分表方案。通过垂直分表,可以将冗余的数据和低频使用的列从主表中分离出来,提高查询性能和减少存储空间的占用。
垂直分表通常基于数据的逻辑关系进行划分,可以按照以下方式进行:
垂直拆分(Vertical Splitting):将原始表中的列按照功能或使用频率进行拆分,形成多个表。例如,将经常变更的列和不经常使用的列从主表中分离出来,形成一个或多个辅助表。这样可以减少主表的数据量,提高查询性能。
冷热数据分离(Hot and Cold Data Separation):将热数据(经常被查询的数据)和冷数据(不经常被查询的数据)分离到不同的表中。将热数据存储在主表中,而将冷数据存储在单独的表中,可以提高主表的查询性能。
稀疏列拆分(Sparse Column Splitting):对于具有大量稀疏列的表,可以将这些列拆分成一个或多个表。这种方式可以减少表的宽度,提高查询效率。
好处:
- 提高查询性能:通过将数据划分到多个表中,减少每个表的数据量,可以加快查询速度。
- 减少存储空间的占用:将冗余的数据和低频使用的列从主表中分离出来,可以减少存储空间的占用。
- 简化数据管理和维护:将不同的列划分到不同的表中,可以更加灵活地进行数据管理和维护。
- 解决业务系统层面的耦合,业务清晰。
缺点:
- 部分表无法join,只能通过接口聚合方式解决,提升了开发的复杂度。
- 分布式事务处理复杂。
- 依然存在单表数据量过多的问题(需要水平切分)
水平分表
将一个表中的数据,按照关键字(例如:ID)(或取 Hash 之后)对一个具体的数字取模,得到的余数就是需要存放到的新表的位置。
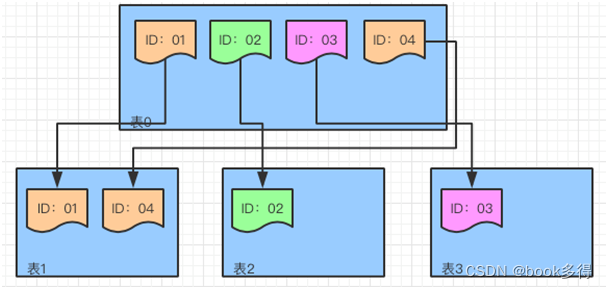
用 ID 取模的分表方式分配记录
ID 分别为 01-04 的四条记录,如果分配到 3 个表中,那么对 3 取模得到的余数分别是:
- ID:01 对 3 取模余数为 1 ,存到“表 1”。
- ID:02 对 3 取模余数为 2 ,存到“表 2”。
- ID:03 对 3 取模余数为 3 ,存到“表 3”。
- ID:04 对 3 取模余数为 1 ,存到“表 1”。
当然这里只是一个例子,实际情况需要对 ID 做 Hash 之后再计算。同时还可以针对不同表所在的不同的数据库的资源来设置存储数据的多少。针对每个表所在的库的资源设置权值。
用这种方式存放数据以后,在访问具体数据的时候需要通过一个 Mapping Table 获取对应要响应的数据来自哪个数据表。目前比较流行的数据库中间件已经帮助我们实现了这部分的功能。
也就是说不用大家自己去建立这个 Mapping Table,在做查询的时候中间件帮助你实现了 Mapping Table 的功能。所以,我们这里只需要了解其实现原理就可以了。
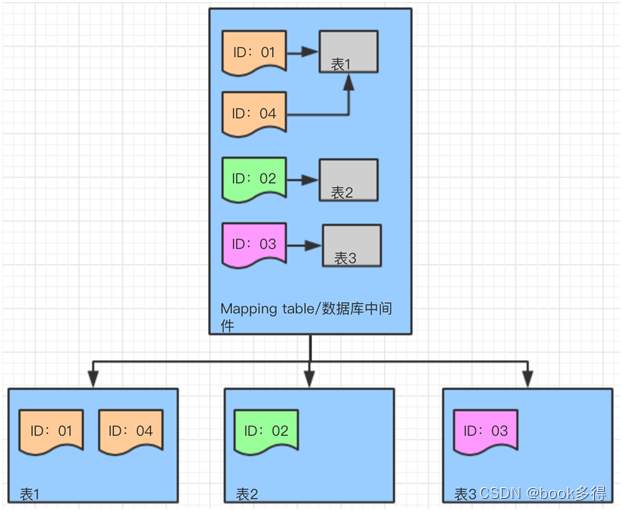
Mapping Table 协助分表
水平拆分还有一种情况是根据数据产生的前后顺序来拆分存放。例如,主表只存放最近 2 个月的信息,其他比较老旧的信息拆分到其他的表中。通过时间来做数据区分。更有甚者是通过服务的地域来做数据区分的。
按照时间做的数据分表
需要注意的是由于分表造成一系列记录级别的问题,例如 Join 和 ID 生成,事务处理,同时存在这些表需要跨数据库的可能性:
- Join:需要做两次查询,把两次查询的结果在应用层做合并。这种做法是最简单的,在应用层设计的时候需要考虑。
- ID:可以使用 UUID,或者用一张表来存放生成的 Sequence,不过效率都不算高。UUID 实现起来比较方便,但是占用的空间比较大。 Sequence 表的方式节省了空间,但是所有的 ID 都依赖于单表。这里介绍一个大厂用的 Snowflake 的方式。
排序/分页:数据分配到水平的几个表中的时候,做排序和分页或者一些集合操作是不容易的。
这里根据经验介绍两种方法。对分表的数据先进行排序/分页/聚合,再进行合并。对分表的数据先进行合并再做排序/分页/聚合。
事务:存在分布式事务的可能,需要考虑补偿事务或者用 TCC(Try Confirm Cancel)协助完成。
优点:
提高查询性能:通过将数据行分散存储在多个表中,可以提高查询性能。当查询条件涉及到分表键时,MySQL可以仅扫描相关分表,而不需要扫描整个表,从而减少了IO开销和查询时间。
管理简化:对于大型表,水平分表可以简化数据管理。可以针对某个分表执行备份、恢复、优化等操作,而不需要对整个表进行操作。同时,也方便进行数据迁移和维护。
分布式处理:水平分表可以支持分布式处理,允许将数据分布在多台服务器上,以提高系统的并发性和扩展性。
缺点:
连接操作复杂:当需要跨多个分表进行连接查询时,会增加查询的复杂性。需要使用特殊的语法或合并结果集来获取完整的查询结果。
数据一致性难以保证:在水平分表的情况下,某些操作(如跨分表事务)可能难以保证数据的一致性。
分布式事务问题:当使用分片技术进行水平分表时,可能会涉及到分布式事务的处理,这增加了系统的复杂性和开发成本。
数据分库
每个物理数据库支持数据都是有限的,每一次的数据库请求都会产生一次数据库链接,当一个库无法支持更多访问的时候,我们会把原来的单个数据库分成多个,帮助分担压力。
怎么分库?
这里有几类分库的原则,可以根据具体场景进行选择:
- 根据业务不同分库,这种情况都会把主营业务和其他功能分开。例如可以分为订单数据库,核算数据库,评论数据库。
- 根据冷热数据进行分库,用数据访问频率来划分,例如:近一个月的交易数据属于高频数据,2-6 个月的交易数据属于中频数据,大于 6 个月的数据属于低频数据。
- 根据访问数据的地域/时间范围进行分库。
水平分库
适用场景:
当单个数据库中的表过多时,可以根据业务逻辑将不同类型或功能相关的表分散到不同的数据库中,以减轻单个数据库的负担和提高数据库性能。
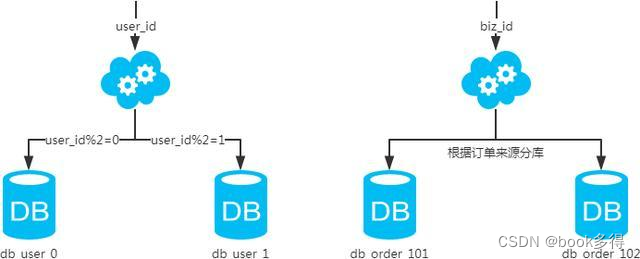
概念:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。 结果:
- 每个库的结构都一样;
- 每个库的数据都不一样,没有交集;
- 所有库的并集是全量数据;
优点:
可以根据业务需求和访问模式灵活地划分数据库,降低单个数据库的数据量和提高数据库性能。
注意事项:
不同的数据库应该存放在不同的服务器上,需要考虑数据库之间的数据一致性和跨库事务管理。
垂直分库
适用场景:
当单个数据库的性能达到瓶颈时,可以根据某种规则将数据划分到多个数据库中,每个数据库负责存储部分数据,以提高数据库的扩展性和性能。
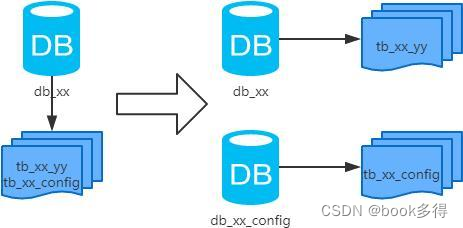
概念:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。 结果:
- 每个库的结构都不一样;
- 每个库的数据也不一样,没有交集;
- 所有库的并集是全量数据;
优点:
可以将数据分散存储在多个数据库中,有效缓解单库的性能瓶颈和压力,提高系统的并发处理能力。
注意事项:
需要考虑数据库之间的数据同步和一致性、跨库事务管理、数据路由和负载均衡等问题,选择合适的分库规则和策略。
分库分表之后的常见问题
1.数据一致性问题:
问题描述:
分库分表后,跨库、跨表的事务管理和数据同步变得复杂。需要考虑如何确保数据的一致性,以及在分布式环境下如何处理跨库事务和并发访问。
解决方案:
使用分布式事务管理框架,如Seata、XA协议等,来确保分布式事务的一致性。
采用消息队列等异步处理机制,将跨库事务拆分成本地事务,并通过消息队列来实现最终一致性。
设计合适的数据同步方案,定期或实时地将数据同步到各个库中,确保数据的一致性。
2.数据迁移和扩容:
问题描述:
随着业务的增长,可能需要对分库分表进行扩容或迁移。这涉及到数据的迁移、重新分片和负载均衡等问题,需要谨慎规划和执行,以避免数据丢失或服务中断。
解决方案:
使用分库分表中间件,如MyCAT、ShardingSphere等,可以简化数据迁移和扩容的过程,自动进行数据的重新分片和负载均衡。
采用数据迁移工具,如阿里巴巴的DataX,可以实现数据的快速迁移和同步,避免数据丢失或服务中断。
3.跨表查询性能:
问题描述:
分表后,跨表查询的性能可能会受到影响,特别是涉及到大量表的联合查询或聚合操作。需要设计合适的查询方案,尽量减少跨表查询的频率和数据量。
解决方案:
设计合适的数据模型,尽量减少跨表查询的频率和数据量,避免在大规模数据表上进行联合查询或聚合操作。
使用数据库索引来优化查询性能,确保查询语句能够有效地利用索引进行快速检索。
4.分布式事务管理:
问题描述:
分库分表后,事务管理变得更加复杂,需要考虑分布式事务的实现和一致性保证。通常会采用两阶段提交(2PC)、补偿事务(TCC)、最终一致性等分布式事务处理方案。
解决方案:
结合分布式事务管理框架,设计合适的分布式事务方案,确保事务的一致性和可靠性。
考虑使用柔性事务模型,如TCC(Try-Confirm-Cancel)模式,来处理分布式事务中的异常情况。
5.业务逻辑调整:
问题描述:
分库分表可能需要对原有的业务逻辑进行调整和优化,以适应新的数据分布和访问模式。需要重新评估业务需求,并根据实际情况做出相应的调整。
解决方案:
根据新的数据分布和访问模式,调整业务逻辑和流程,优化系统性能和用户体验。
对于需要大规模重构的业务逻辑,可以采用分阶段、分模块的方式进行调整,以降低风险和成本。


















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









